概要
DataEditorでは、DataEditor上のデータを使った機械学習のモデル作成と予測が行えます。
DataEditorでサポートしている機械学習モデルは、以下のとおりです。
| モデルの種類 | モデル | 特徴 | ユースケース |
|---|---|---|---|
| 回帰 | 線形回帰(回帰) | あるものの価格や気温など、数字で表されるものを予測。 | 住宅価格の予測や売上予測など、連続値の予測。 |
| AutoML(回帰) | いろいろな方法を自動で試して、最適な数字予測方法を自動検出。 | データサイエンスの専門知識が限られている状況や、迅速なプロトタイピングが必要な場合。 | |
| XGBoost(回帰) | 複雑なデータから、正確な数字を予測。 | 需要予測やエネルギー消費予測など、精度が重視される連続値の予測。 | |
| Deep Neural Network(回帰) | 非常に多くのデータや複雑なパターンから、数字を予測。 | 自動運転車のセンサーデータ解析や気候変動の予測など、高度な分析。 | |
| モデルジェネレーター(回帰) | 非推奨。作成済みのモデルは利用可。他モデルでの再作成を推奨。 | ||
| 分類 | ロジスティック回帰(分類) | 何かが起こるかどうか、はいかいいえで答える問題を予測。 | メールのスパム分類や疾患の有無の予測。 |
| AutoML(分類) | いろいろな方法を自動で試して、物事を分類する最適な方法を自動検出。 | データサイエンスの専門知識が限られている状況や、迅速なプロトタイピングが必要な場合。 | |
| XGBoost(分類) | 複雑なデータから、正確に物事を分類。 | 顧客セグメンテーションやクレジットスコアリングなど、精度が重視される予測。 | |
| Deep Neural Network(分類) | 非常に多くのデータや文章から、物事を分類。 | テキスト分析での感情分析や商品レビューからポジティブ/ネガティブの予測。 | |
| モデルジェネレーター(分類) | 非推奨。作成済みのモデルは利用可。他モデルでの再作成を推奨。 | ||
| クラスタリング | k-平均法 | 似たようなデータをグループに分類。 | 顧客セグメンテーションや市場分析など。 |
| 時系列 | ARIMA+(時系列)【限定公開】 | 過去のデータを基に、未来の数値の推移を予測。 | 株価予測や販売量の予測、気象データなどの分析。 |
警告
モデルジェネレーターモデルは、2024年2月1日以降、非推奨となりました。2024年2月1日のMAGELLAN BLOCKSのリリース以降、このモデルの作成はできません。作成済みのこのモデルについては、他のモデルで再作成してください。
重要
限定公開モデルの利用にあたっては、ライセンス購入申請が必要です。限定公開のモデルを利用したい場合は、MAGELLAN BLOCKSのお問い合わせ機能からライセンス購入申請をお願いします。
線形回帰(回帰)の例
モデル作成
- ホーム画面からモデル作成用のトレーニングデータをクリック
- [
モデル作成]タブをクリック - [
線形回帰(回帰)]をクリック - 名前を必要に応じて変更
- [
詳細設定]をクリック
トレーニングデータ設定が編集できます。 - [
モデル作成]ボタンをクリック
- [
閉じる]ボタンをクリック
以上で、モデルの作成は完了です。
モデルの確認
モデルの作成が完了したら、そのモデルの内容を確認して評価できます。
- ホーム画面から[
モデル]タブをクリック - 確認したい線形回帰(回帰)モデルの名前をクリック
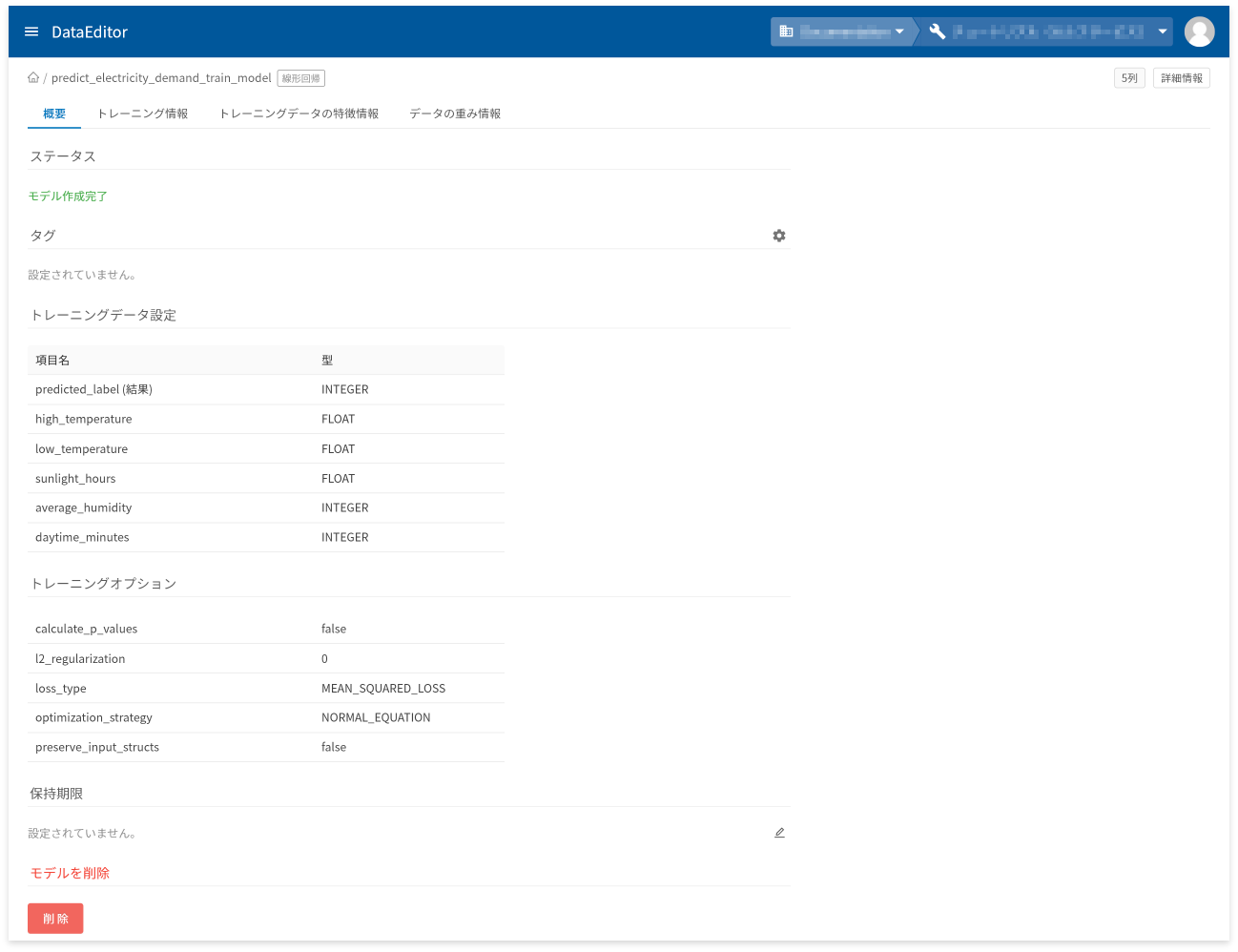
モデル詳細画面の[概要]タブでは、以下に挙げる情報の確認と操作ができます。
- モデル作成状況を表すステータスの確認
- タグの設定と確認
- トレーニングデータの項目と型の確認
- トレーニングオプションの確認
- 保存期限の設定と確認
- モデルの削除
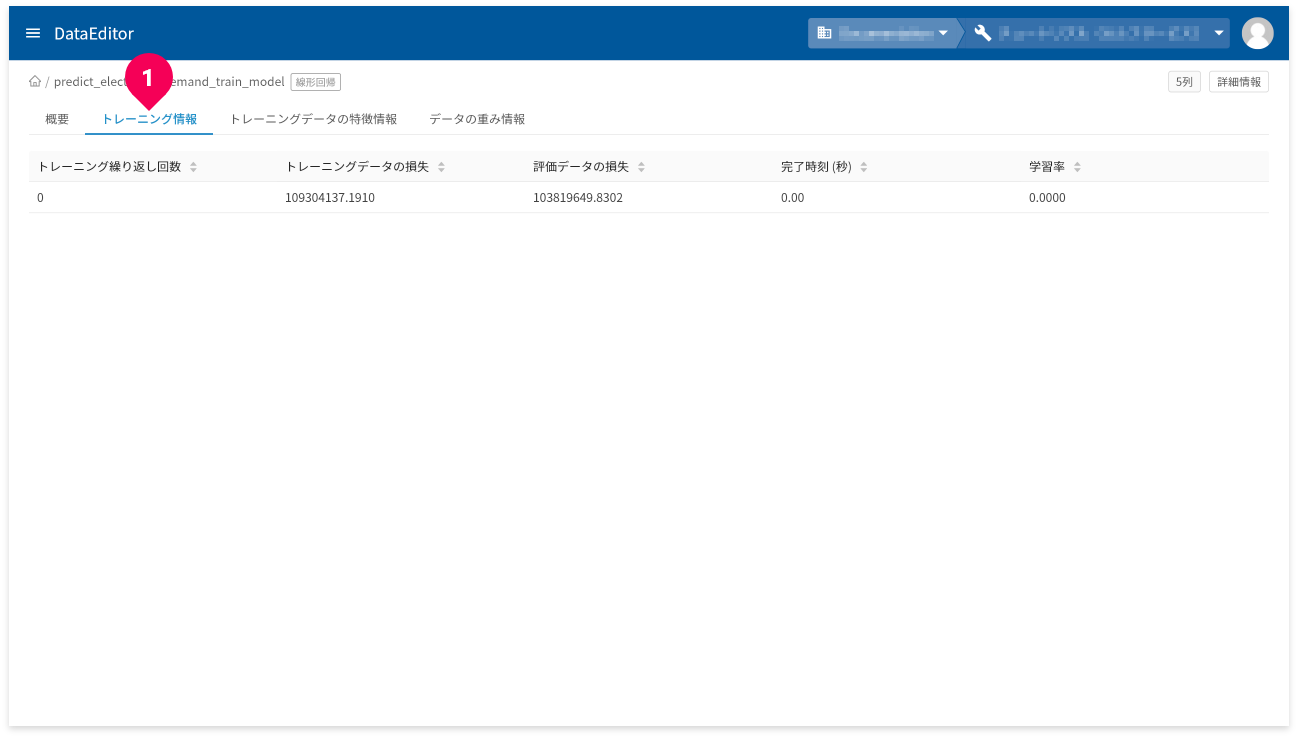
[トレーニング情報]タブ(❶)をクリックすると、トレーニング(学習)の情報が確認できます。
- トレーニング繰り返し回数:トレーニングの繰返し回数です。
- トレーニングデータの損失:トレーニングデータの繰り返し後に計算された損失指標(平均二乗誤差)です。
- 評価データの損失:評価の損失指標です。
- 完了時刻:各トレーニングの時間
- 学習率:各トレーニングの学習率
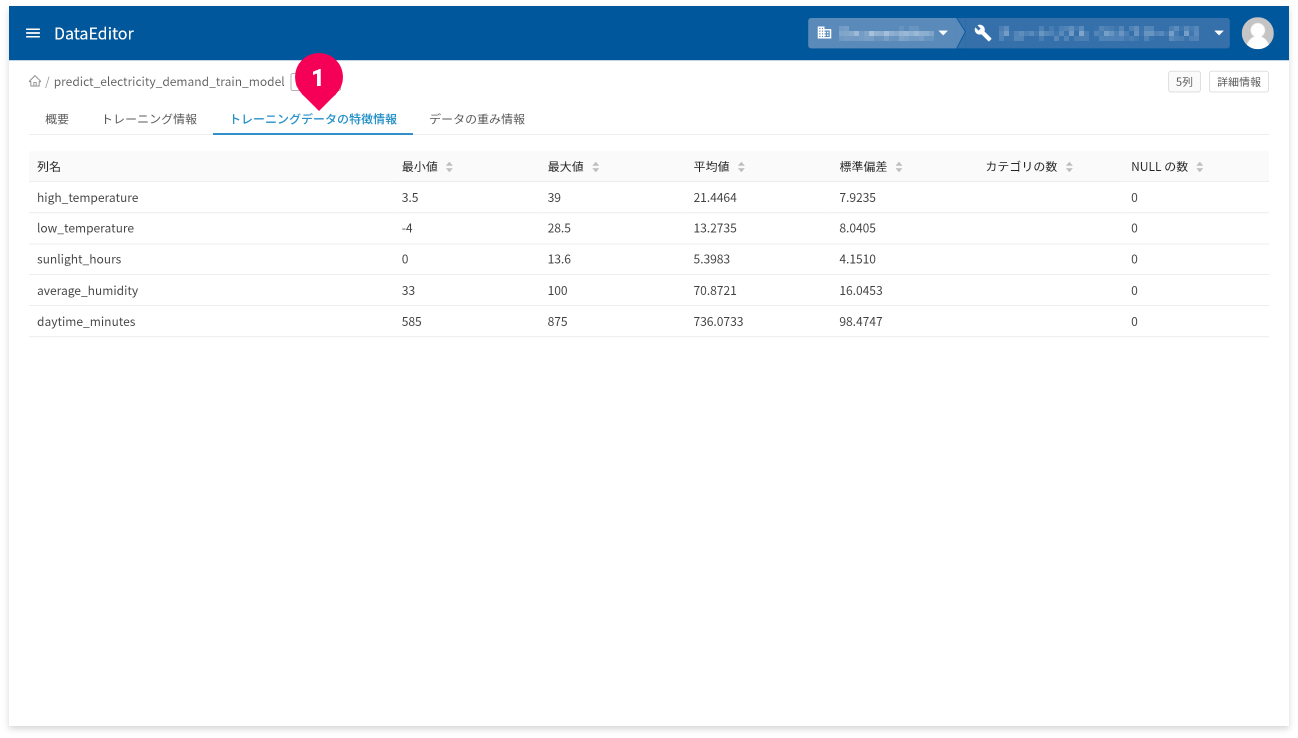
[トレーニングデータの特徴情報]タブ(❶)をクリックすると、トレーニングデータの特徴情報が確認できます。
- 列名:トレーニングデータの列名
- 最小値:トレーニングデータの最小値。数値以外の場合はNULL。
- 最大値:トレーニングデータの最大値。数値以外の場合はNULL。
- 平均値:トレーニングデータの平均値。数値以外の場合はNULL。
- 標準偏差:トレーニングデータの標準偏差。数値以外の場合はNULL。
- カテゴリの数:カテゴリの数。カテゴリ以外の列の場合はNULL。
- NULLの数:NULL値の数
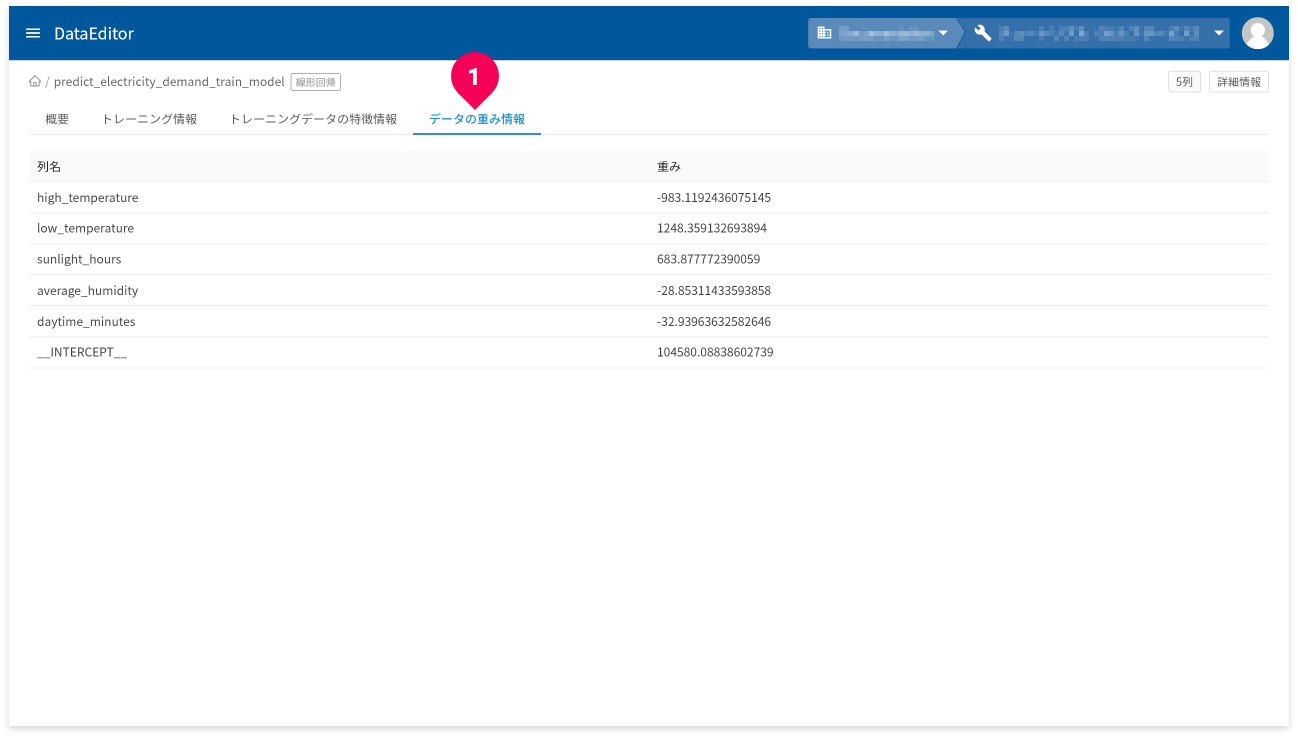
[データの重み情報]タブ(❶)をクリックすると、トレーニングデータ各列ごとの重み情報が確認できます。
モデルを評価した結果が悪ければ、トレーニングデータの因子(列)を見直して、モデルを作り直し再度評価します。このサイクルを良い結果が得られるまで繰り返します。
予測
作成したモデルと予測用のデータを使って、簡単に予測ができます。
- ホーム画面から予測用のデータをクリック
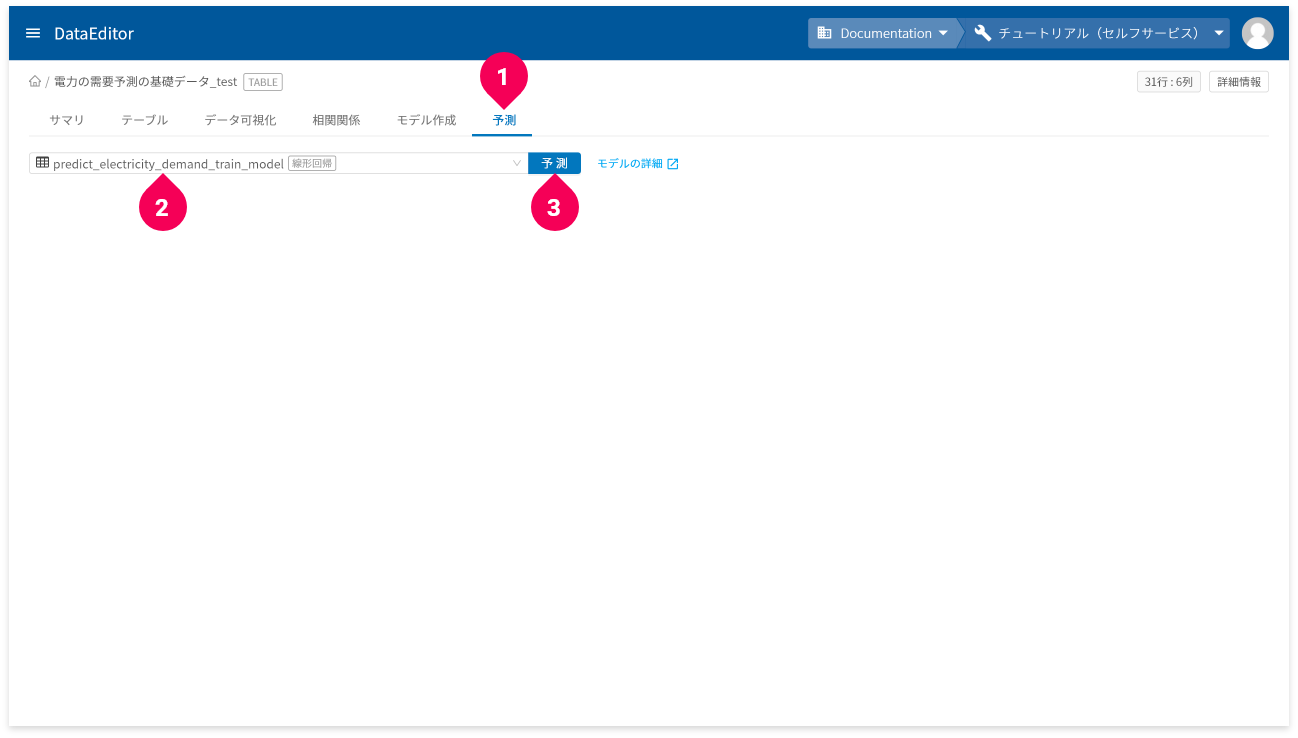
- [
予測]タブをクリック - 予測に使用する線形回帰(回帰)モデルをクリック
- [
予測]ボタンをクリック
予測が完了すると、結果が表示されます。
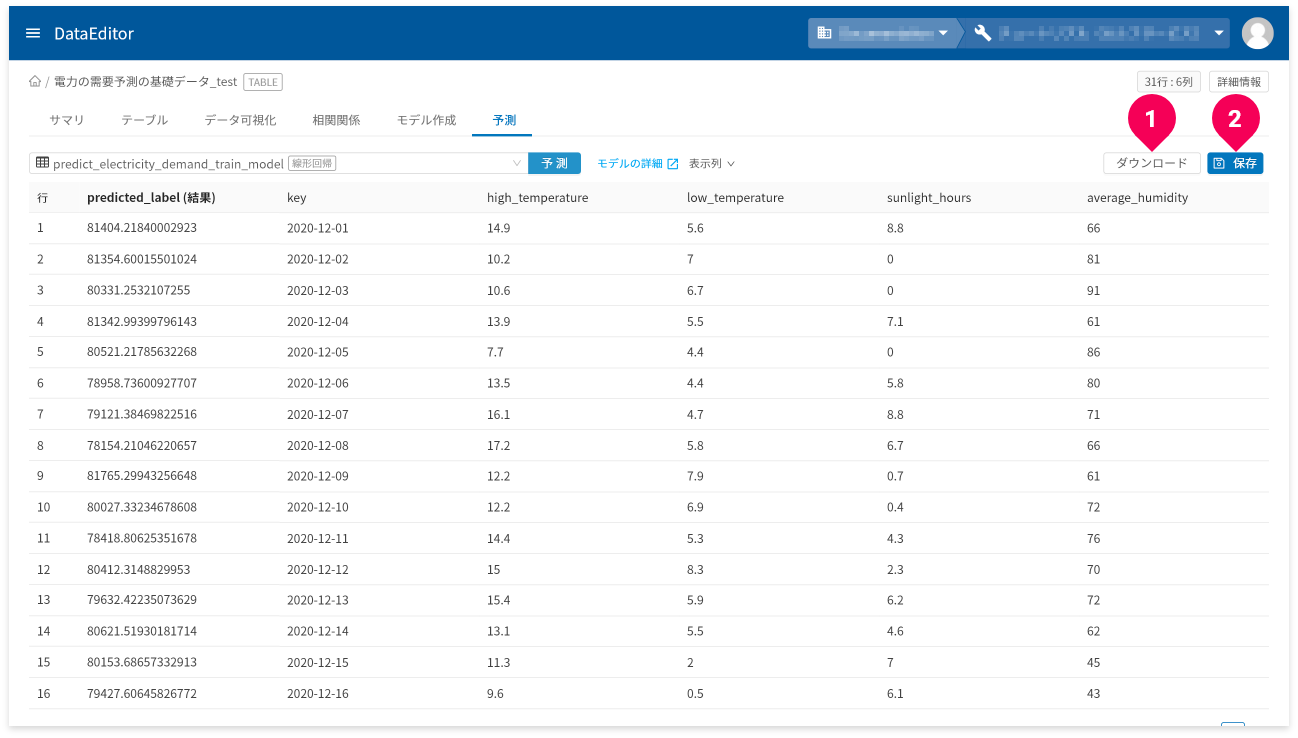
[ダウンロード]ボタン(❶)をクリックすると、予測結果の表をCSV形式のデータでダウンロードできます。
- 予測結果の画面が複数ページにまたがる場合は、一度表示したページ数分のデータをダウンロード
予測結果が3ページ分あり、2ページまで画面上で確認し[
ダウンロード]ボタンをクリックした場合、2ページ分のデータがダウンロードされます。
[保存]ボタン(❷)をクリックすると、予測結果をDataEditorに登録できます。これにより、データ可視化の機能を使って視覚的に予測結果の評価ができます。
AutoML(回帰)の例
モデル作成
- ホーム画面からモデル作成用のトレーニングデータをクリック
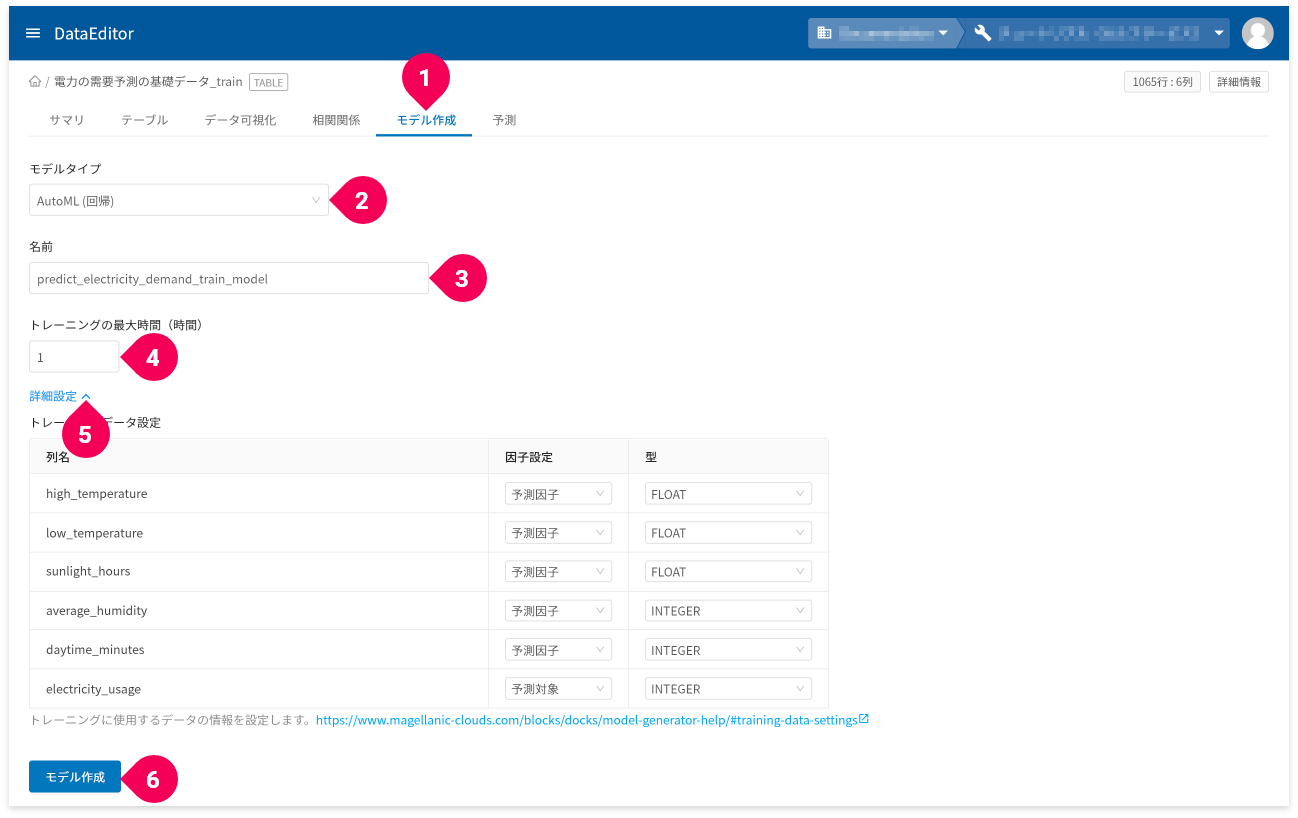
- [
モデル作成]タブをクリック - [
AutoML(回帰)]をクリック - 名前を必要に応じて変更
- トレーニングの最大時間を時間単位で設定
- [
詳細設定]をクリック
トレーニングデータ設定が編集できます。 - [
モデル作成]ボタンをクリック
- [
閉じる]ボタンをクリック
以上で、モデルの作成は完了です。
モデル確認
モデルの作成が完了したら、そのモデルの内容を確認して評価できます。
- ホーム画面から[
モデル]タブをクリック - 確認したいAutoML(回帰)モデルの名前をクリック
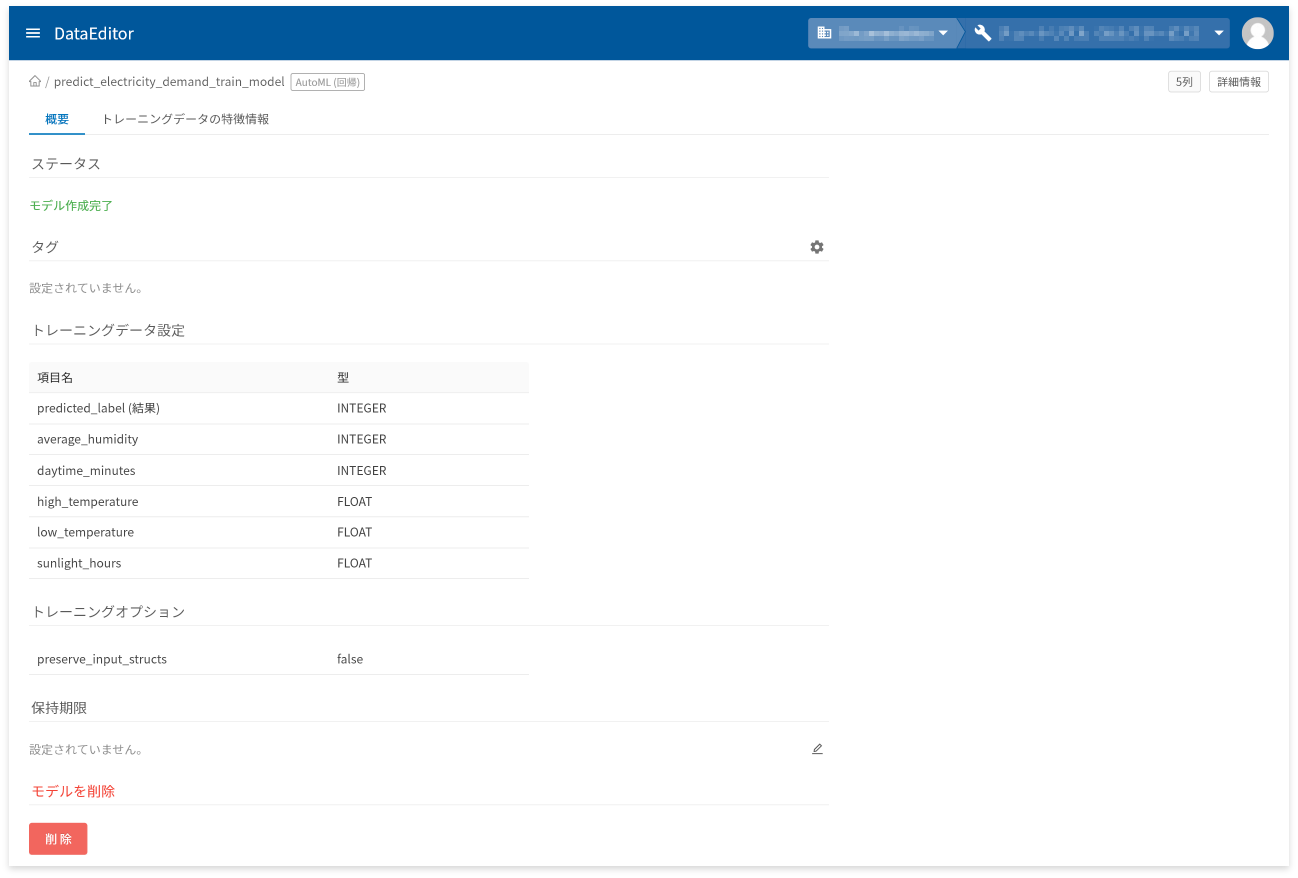
モデル詳細画面の[概要]タブでは、以下に挙げる情報の確認と操作ができます。
- モデル作成状況を表すステータスの確認
- タグの設定と確認
- トレーニングデータの項目と型の確認
- トレーニングオプションの確認
- 保存期限の設定と確認
- モデルの削除
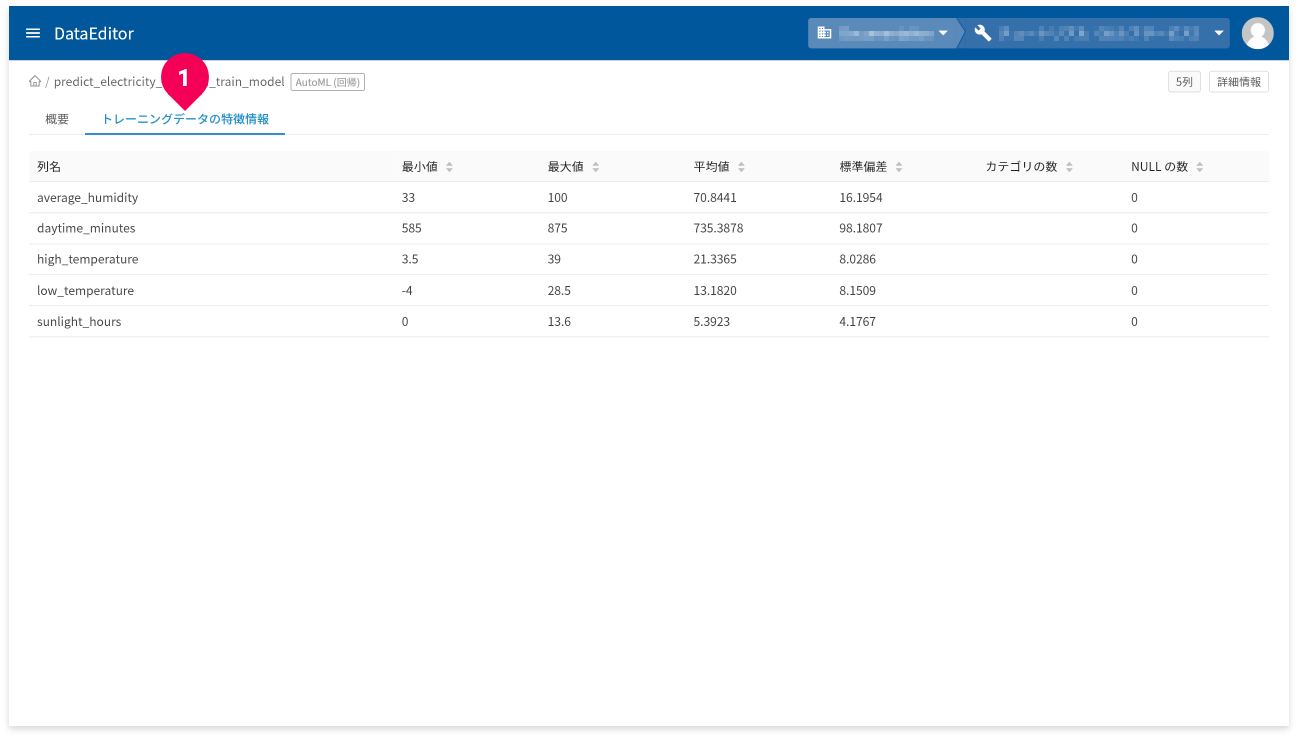
[トレーニングデータの特徴情報]タブ(❶)をクリックすると、トレーニングデータの特徴情報が確認できます。
- 列名:トレーニングデータの列名
- 最小値:トレーニングデータの最小値
- 最大値:トレーニングデータの最大値
- 平均値:トレーニングデータの平均値
- 標準偏差:トレーニングデータの標準偏差
- カテゴリの数:カテゴリの数
- NULLの数:NULL値の数
予測
作成したモデルと予測用のデータを使って、簡単に予測ができます。
- ホーム画面から予測用のデータをクリック
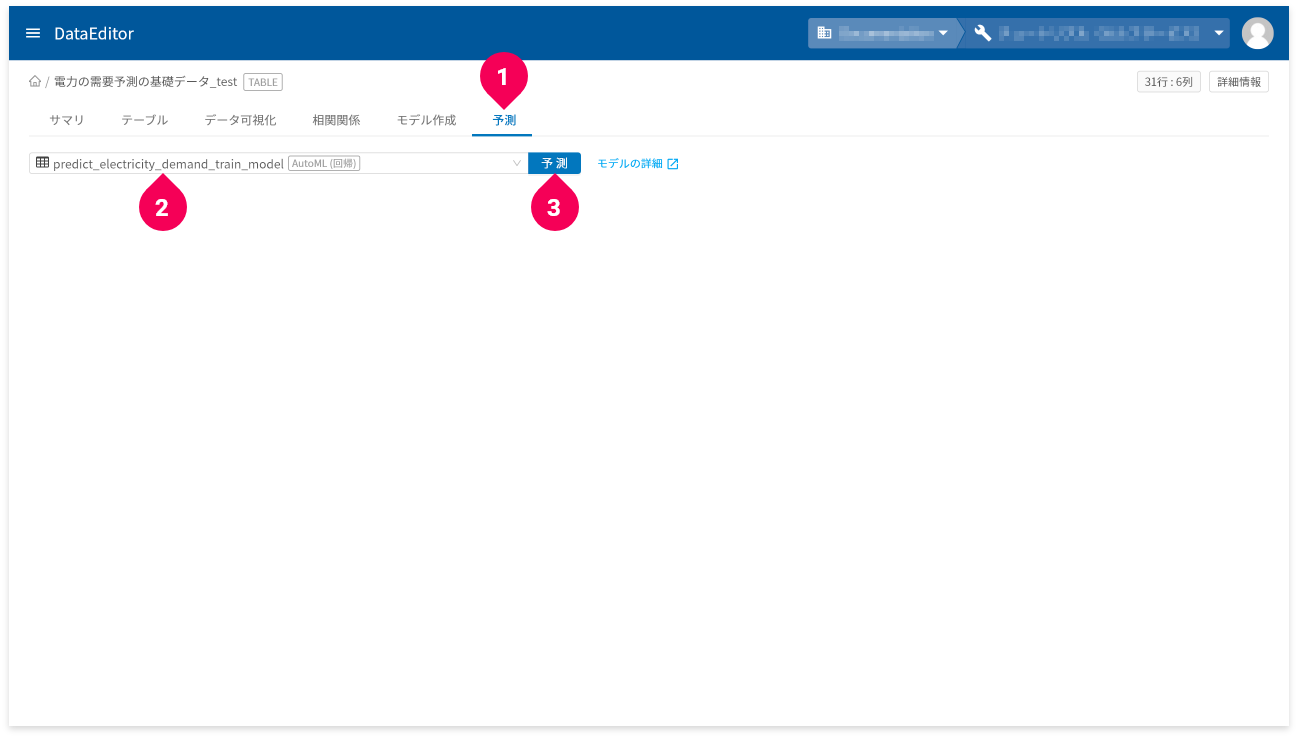
- [
予測]タブをクリック - 予測に使用するAutoML(回帰)モデルをクリック
- [
予測]ボタンをクリック
予測が完了すると、結果が表示されます。
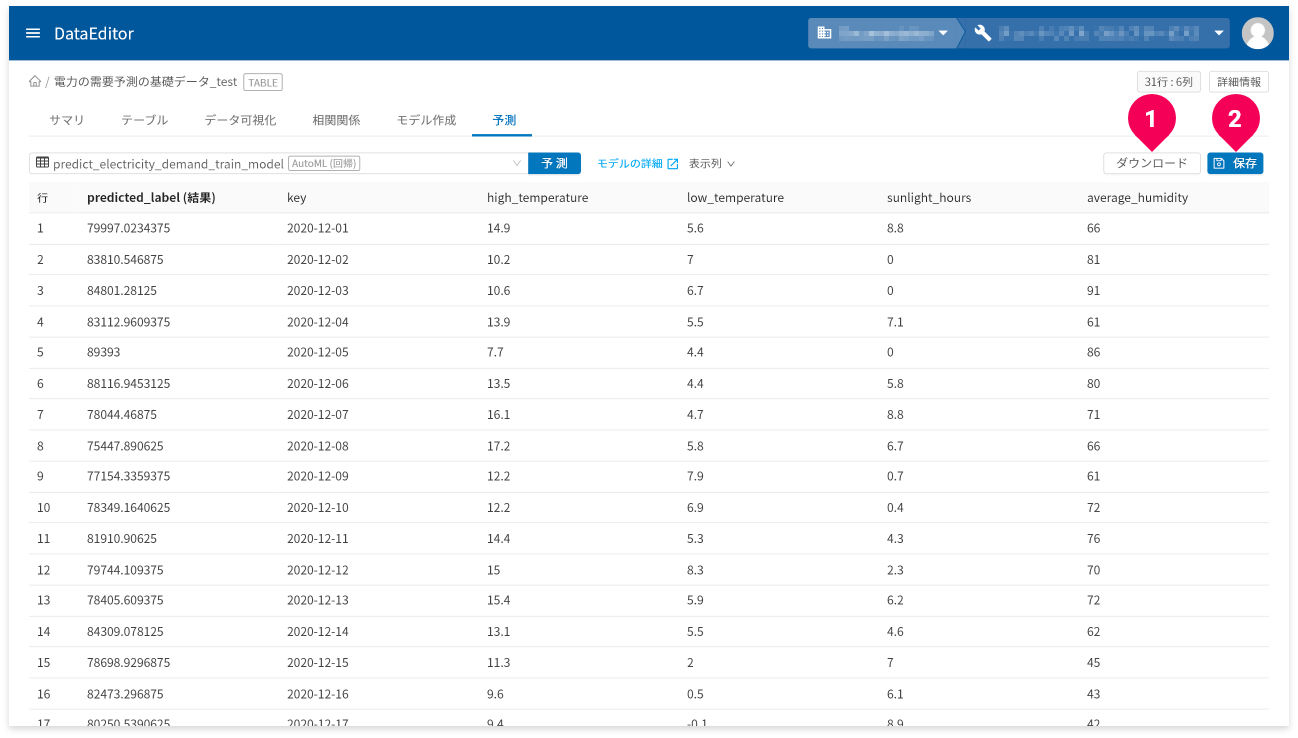
[ダウンロード]ボタン(❶)をクリックすると、予測結果の表をCSV形式のデータでダウンロードできます。
- 予測結果の画面が複数ページにまたがる場合は、一度表示したページ数分のデータをダウンロード
予測結果が3ページ分あり、2ページまで画面上で確認し[
ダウンロード]ボタンをクリックした場合、2ページ分のデータがダウンロードされます。 - ラベル(predicted_label_probs)欄は出力から除外
[保存]ボタン(❷)をクリックすると、予測結果をDataEditorに登録できます。これにより、データ可視化の機能を使って視覚的に予測結果の評価ができます。
XGBoost(回帰)の例
モデル作成
- ホーム画面からモデル作成用のトレーニングデータをクリック
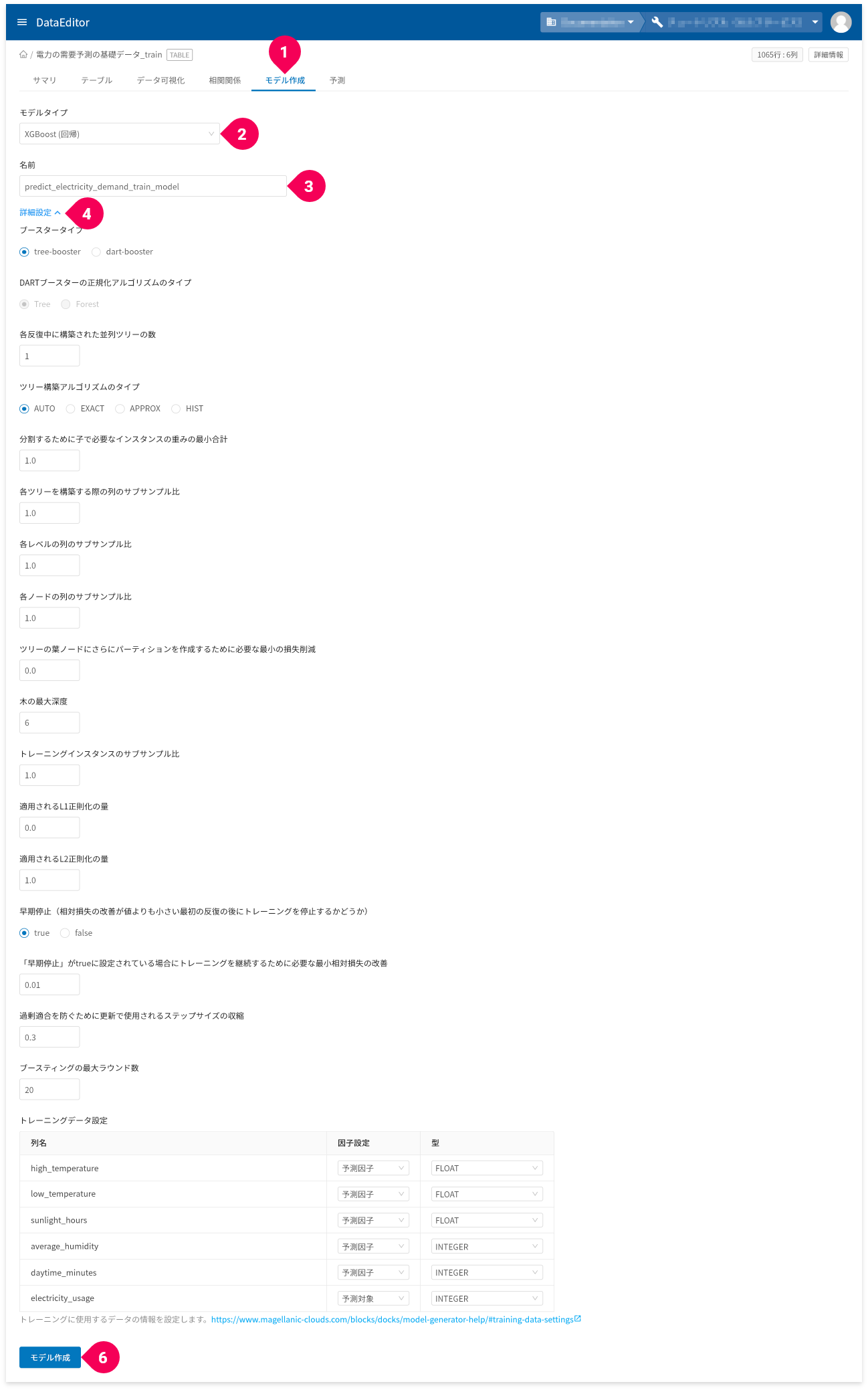
- [
モデル作成]タブをクリック - [
XGBoost(回帰)]をクリック - 名前を必要に応じて変更
- [
詳細設定]をクリック
各種パラメーターの設定とトレーニングデータの設定ができます。パラメーター 説明 ブースタータイプ 使用するブースターのタイプを指定します。
DARTブースターの正規化アルゴリズムのタイプ DARTブースターの正規化アルゴリズムのタイプを指定します。
- Tree
- Forest
各反復中に構築された並列ツリーの数 各反復の間に構築される並列ツリーの数。デフォルト値は1です。ブーストされたランダムフォレストを学習するには、この値を1よりも大きく設定してください。
ツリー構築アルゴリズムのタイプ ツリー構築アルゴリズムの種類を指定します。
- AUTO
- EXACT
- APPROX
- HIST
分割するために子で必要なインスタンスの重みの最小合計 さらなるパーティショニングに必要な子ノードのインスタンスの重みの最小値を指定します。
ツリーの分割ステップの結果、インスタンス重みの合計が指定した値よりも小さいリーフノードが得られた場合、構築プロセスはそれ以上の分割を停止します。指定した値が大きいほど、アルゴリズムはより保守的になります。
値は必ず0以上を指定します。
各ツリーを構築する際の列のサブサンプル比 各ツリーを構築する際の列のサブサンプル率を指定します。
サブサンプリングは、構築されたツリーごとに1回行われます。
値は0から1の間で指定します。
各レベルの列のサブサンプル比 各レベルの列のサブサンプル率を指定します。
サブサンプリングは、ツリー内の新しい深さレベルへ到達するごとに1回行われます。列は、現在のツリーで選択された列のセットからサブサンプリングされます。
値は0から1の間で指定します。
各ノードの列のサブサンプル比 各ノード(スプリット)の列のサブサンプル率を指定します。
サブサンプリングは、新しいスプリットが評価されるたびに1回発生します。
列は、現在のレベルで選択された列のセットからサブサンプリングされます。
値は0から1の間で指定します。
ツリーの葉ノードにさらにパーティションを作成するために必要な最小の損失削減 ツリーのリーフノードでさらに分割するのに必要な損失の最小値を指定します。
指定した値が大きいほど、アルゴリズムはより保守的になります。
木の最大深度 ツリーの最大深度を指定します。
トレーニングインスタンスのサブサンプル比 トレーニングインスタンスのサブサンプル率を指定します。
この値を0.5に設定すると、ツリーを成長させる前にトレーニングがトレーニングデータの半分をランダムにサンプリングすることになり、オーバーフィットを防ぐことができます。
サブサンプリングは、各反復ごとに1回行われます。
値は0から1の間で指定します。
適用されるL1正則化の量 L1正則化の適用量を指定します。
適用されるL2正則化の量 L2正則化の適用量を指定します。
早期停止(相対損失の改善が値よりも小さい最初の反復の後にトレーニングを停止するかどうか) 最初の反復の後で、「
「早期停止」がtrueに設定されている場合にトレーニングを継続するために必要な最小相対損失の改善」パラメーターで指定された値よりも小さいときに、トレーニングを停止するかどうかを指定します。- true:停止する
- false:停止しない
「早期停止」がtrueに設定されている場合にトレーニングを継続するために必要な最小相対損失の改善 「
早期停止」パラメーターにtrueを指定した場合、トレーニングを継続するために必要な相対的な損失の最小改善量を指定します。たとえば、0.01の値を指定すると、トレーニングを継続するためには、各反復で損失を1%減少させる必要があります。
過剰適合を防ぐために更新で使用されるステップサイズの収縮 学習率を指定します。
ブースティングの最大ラウンド数 ブースティング時の最大ラウンド数を指定します。
- [
モデル作成]ボタンをクリック
- [
閉じる]ボタンをクリック
以上で、モデルの作成は完了です。
モデル確認
モデルの作成が完了したら、そのモデルの内容を確認して評価できます。
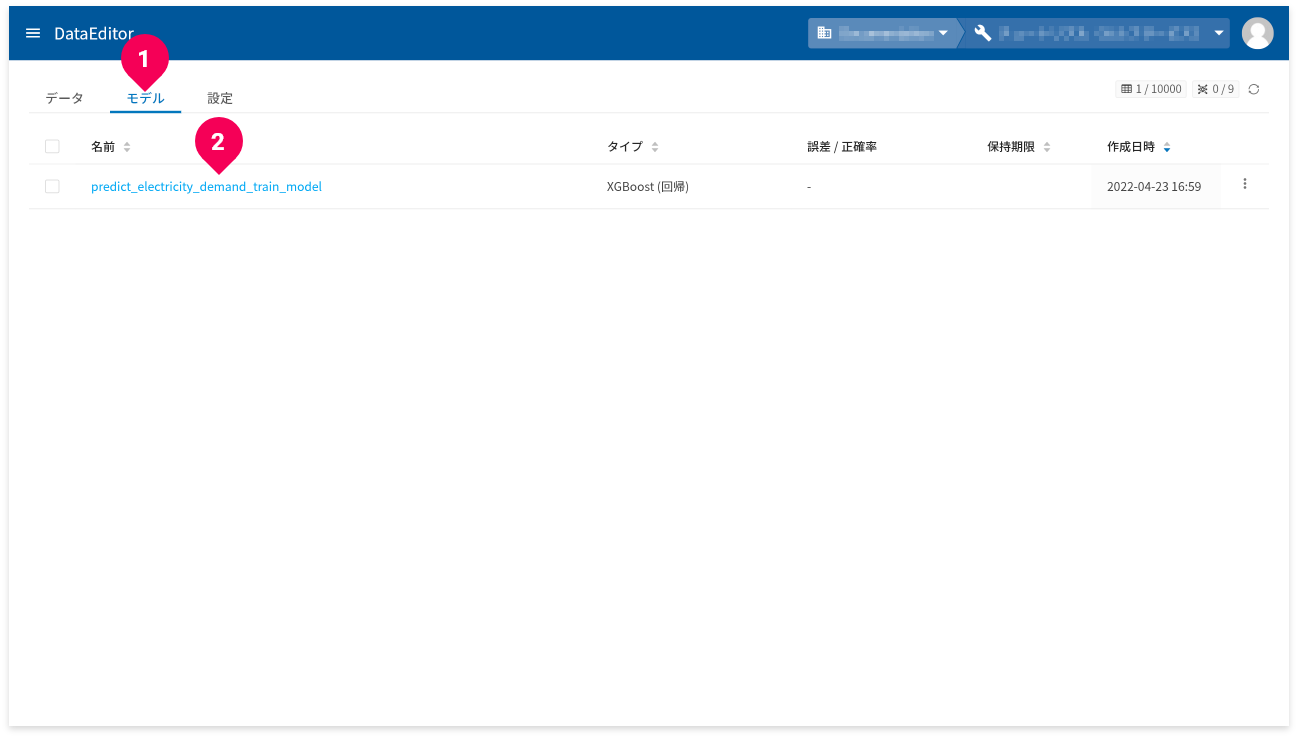
- ホーム画面から[
モデル]タブをクリック - 確認したいXGBoost(回帰)モデルの名前をクリック
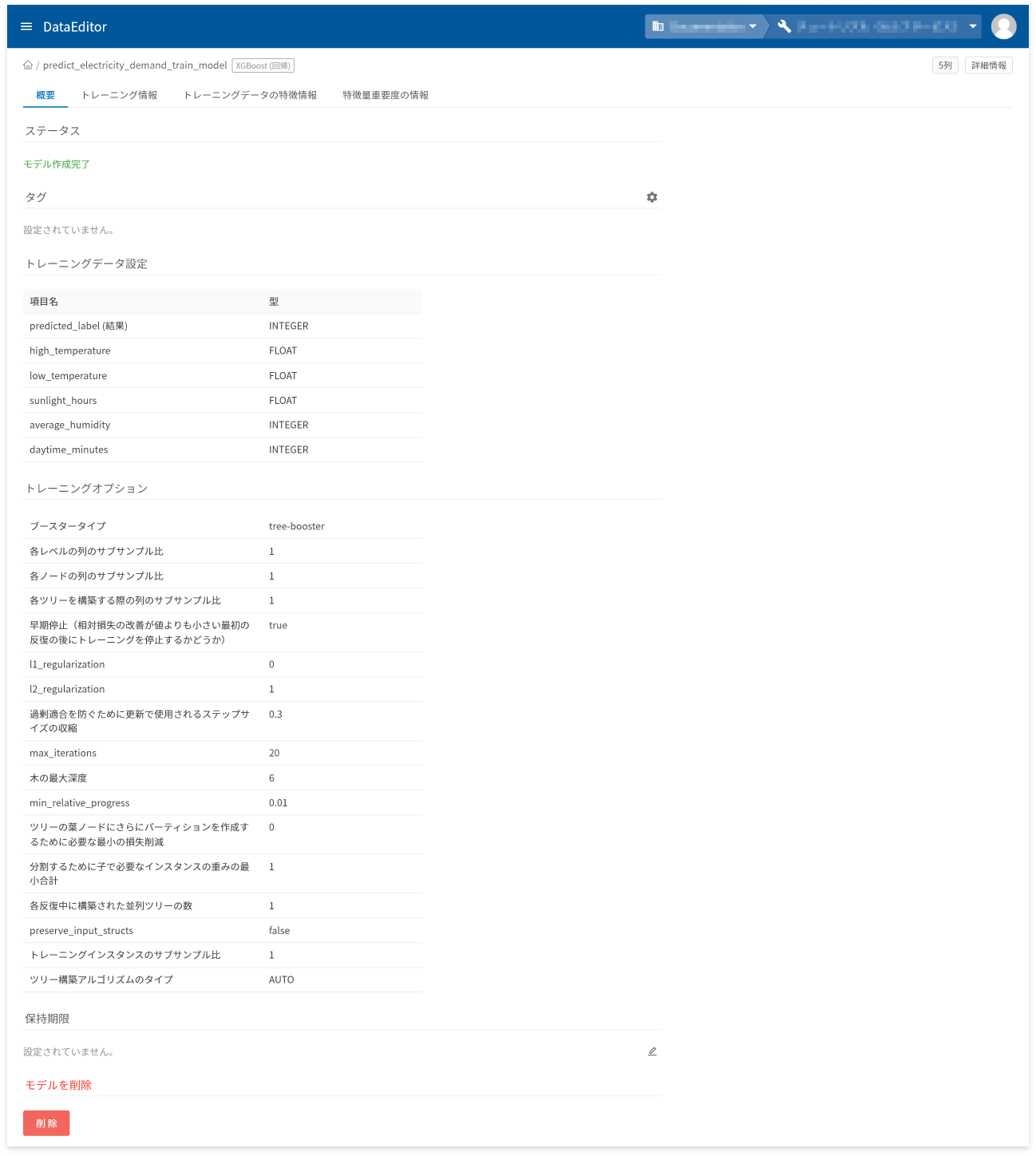
モデル詳細画面の[概要]タブでは、以下に挙げる情報の確認と操作ができます。
- モデル作成状況を表すステータスの確認
- タグの設定と確認
- トレーニングデータの項目と型の確認
- トレーニングオプションの確認
- 保存期限の設定と確認
- モデルの削除
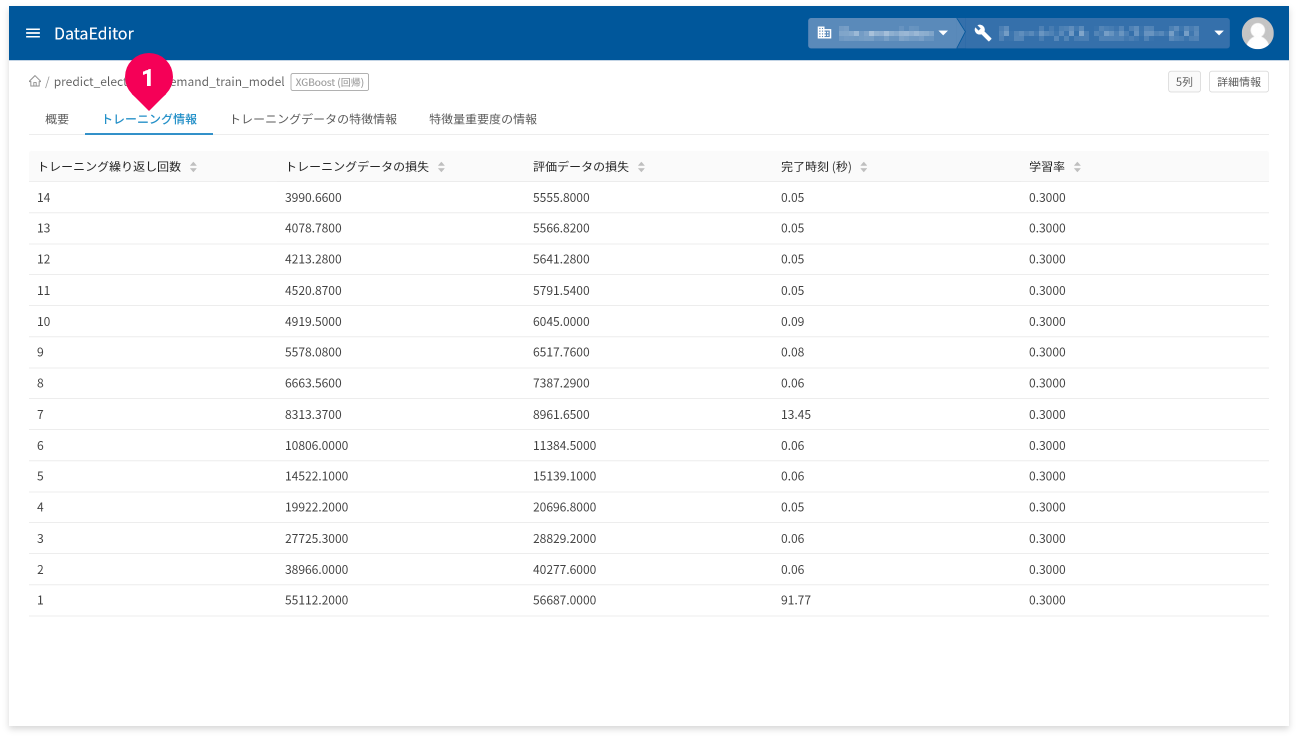
[トレーニング情報]タブ(❶)をクリックすると、トレーニング情報が確認できます。
- トレーニング繰り返し回数:トレーニングの繰返し回数
- トレーニングデータの損失:トレーニングデータの繰り返し後に計算された損失指標(平均二乗誤差)
- 評価データの損失:評価の損失指標
- 完了時刻:各トレーニングの時間
- 学習率:各トレーニングの学習率
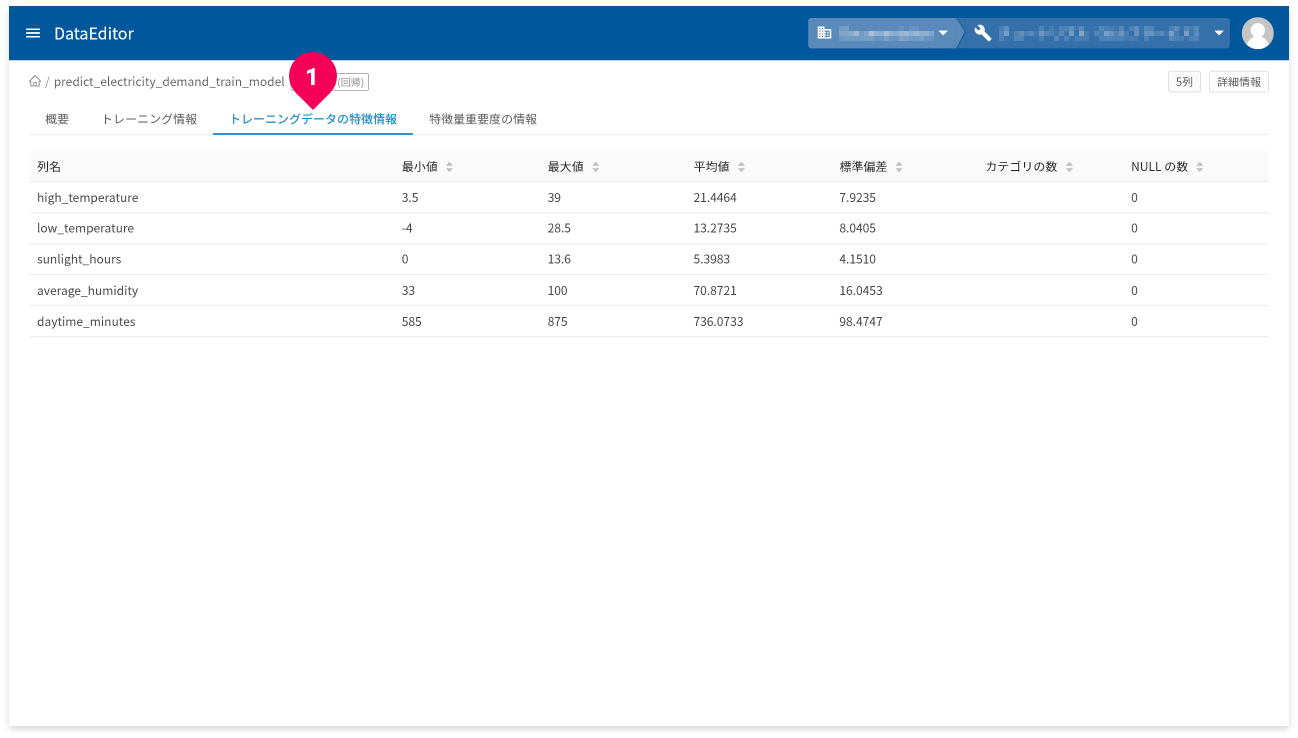
[トレーニングデータの特徴情報]タブ(❶)をクリックすると、トレーニングデータの特徴情報が確認できます。
- 列名:トレーニングデータの列名
- 最小値:トレーニングデータの最小値。数値以外の場合はNULL。
- 最大値:トレーニングデータの最大値。数値以外の場合はNULL。
- 平均値:トレーニングデータの平均値。数値以外の場合はNULL。
- 標準偏差:トレーニングデータの標準偏差。数値以外の場合はNULL。
- カテゴリの数:カテゴリの数。カテゴリ以外の列の場合はNULL。
- NULLの数:NULL値の数
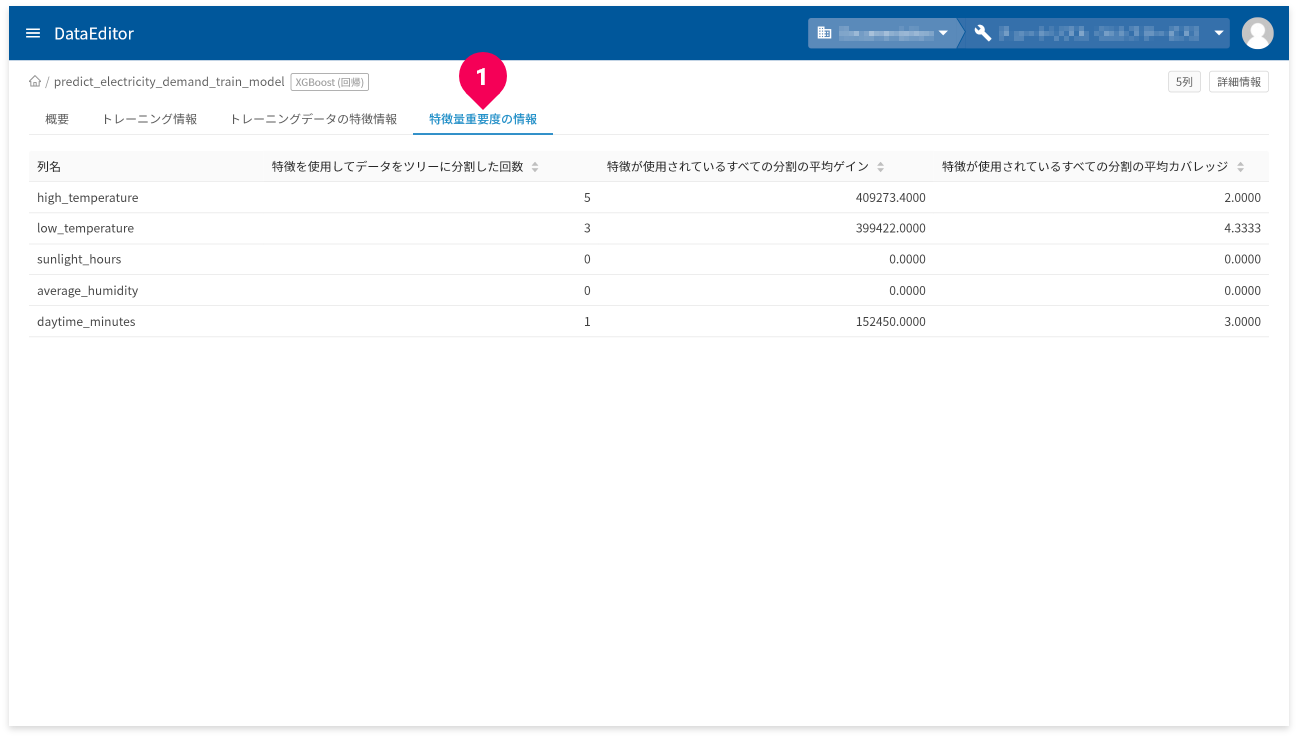
[特徴量重要度の情報]タブ(❶)をクリックすると、どの列が予測結果に与える影響が大きいのかを示す指標が確認できます。値が大きいほど、その列が予測結果に重要であることを意味します。
ここでは、以下3種類の指標が確認できます。
| 指標の種類 | 説明 |
|---|---|
| 特徴を使用してデータをツリーに分割した回数 |
ウェイト(weight)と呼ばれる指標です。 ツリーの分岐に、各列が何回用いられたかを表します。 |
| 特徴が使用されているすべての分割の平均ゲイン |
ゲイン(gain)と呼ばれる指標です。 ゲインは、各ツリーに対して、各列の寄与度を取ることで算出されます。これは、各列のモデルへの相対的な寄与度を意味します。 |
| 特徴が使用されているすべての分割の平均カバレッジ |
カバー(cover)と呼ばれる指標です。 ツリーの分岐に、到達する各列のトレーニングデータ数の平均値を表します。 |
この指標の中で、「特徴が使用されているすべての分割の平均ゲイン」が、各列の相対的な重要性を解釈する上で最も良い指標です。
予測
作成したモデルと予測用のデータを使って、簡単に予測ができます。
- ホーム画面から予測用のデータをクリック
- [
予測]タブをクリック - 予測に使用するXGBoost(回帰)モデルをクリック
- [
予測]ボタンをクリック
予測が完了すると、結果が表示されます。
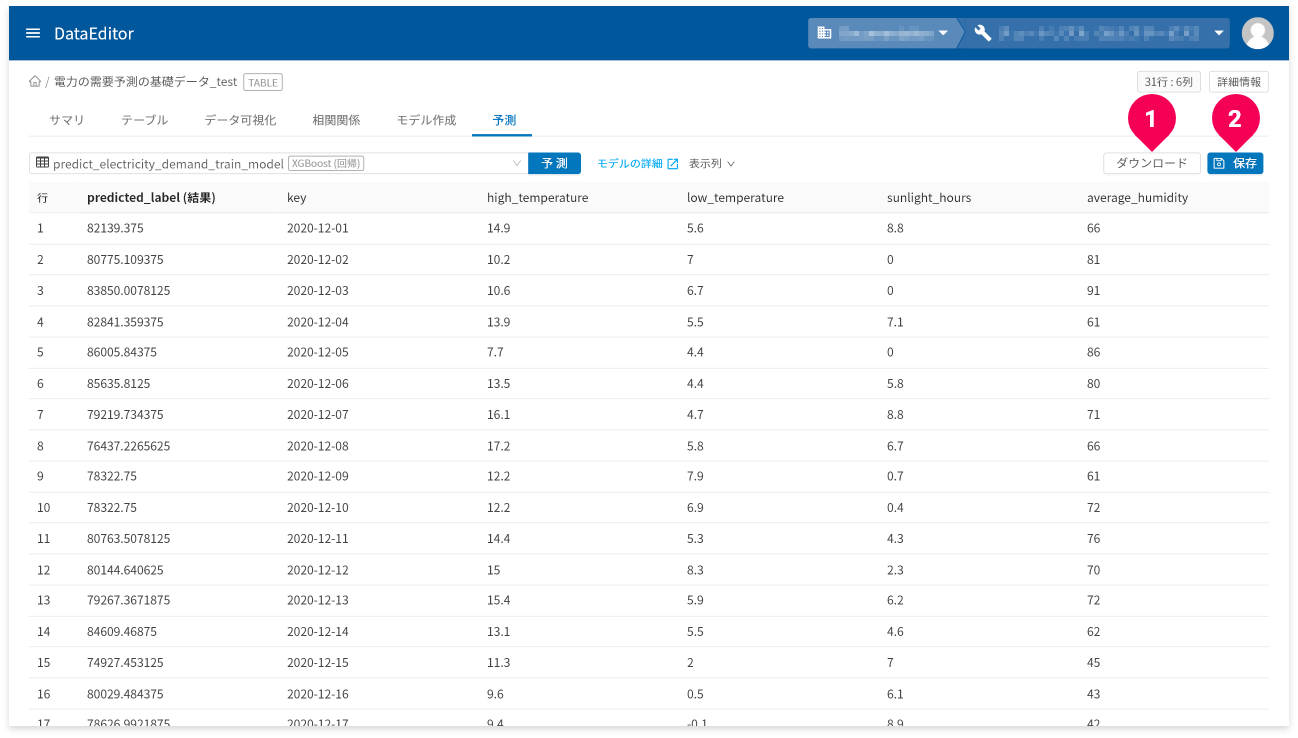
[ダウンロード]ボタン(❶)をクリックすると、予測結果の表を
CSV形式のデータでダウンロードできます。
- 予測結果の画面が複数ページにまたがる場合は、一度表示したページ数分のデータをダウンロード
予測結果が3ページ分あり、2ページまで画面上で確認し[
ダウンロード]ボタンをクリックした場合、2ページ分のデータがダウンロードされます。 - ラベル(predicted_label_probs)欄は出力から除外
[保存]ボタン(❷)をクリックすると、予測結果をDataEditorに登録できます。これにより、データ可視化の機能を使って視覚的に予測結果の評価ができます。
Deep Neural Network(回帰)の例
モデル作成
- ホーム画面からモデル作成用のトレーニングデータをクリック
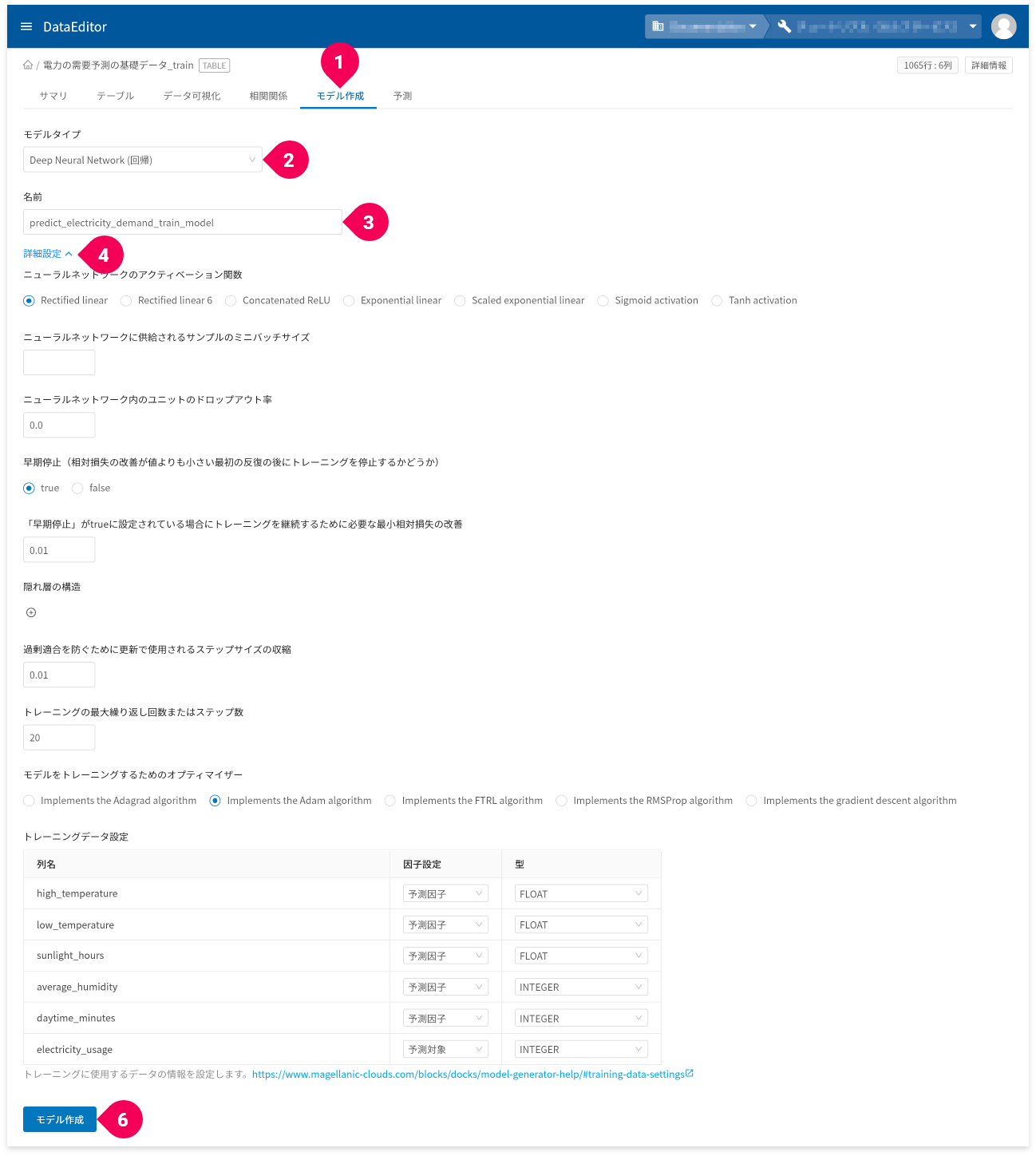
- [
モデル作成]タブをクリック - [
Deep Neural Network(回帰)]をクリック - 名前を必要に応じて変更
- [
詳細設定]をクリック
各種パラメーターの設定とトレーニングデータの設定ができます。パラメーター 説明 ニューラルネットワークのアクティベーション関数 ニューラルネットワークの活性化関数(ニューロンへの入力値から出力値を求める関数)を指定します。
ニューラルネットワークに供給されるサンプルのミニバッチサイズ データをいくつかのサブセットに分割するミニバッチサイズを8192以下の正の数で指定します。
慣習的には、1024や2048などの2のn乗値が使われます。
ニューラルネットワーク内のユニットのドロップアウト率 ニューラルネットワークのユニットのドロップアウト率を指定します。
指定可能な値は、0.0から1.0です。
早期停止(相対損失の改善が値よりも小さい最初の反復の後にトレーニングを停止するかどうか) トレーニングの結果に改善が見られなかったとき、学習を停止するかしないかを指定します。
- true:トレーニングを停止する(過学習防止)
- false:トレーニングを停止しない
「早期停止」がtrueに設定されている場合にトレーニングを継続するために必要な最小相対損失の改善 上記「
早期停止」パラメーターをtrueに指定したとき、トレーニングを継続するために必要な相対的な損失の最小改善量を指定します。例えば、0.01の値を指定すると、イテレーションごとに損失が1%減少すると、トレーニングが継続します。
隠れ層の構造 隠れ層の数と、隠れ層ごとのユニット数を指定します。
過剰適合を防ぐために更新で使用されるステップサイズの収縮 トレーニングごとに重み付けパラメーターを更新する率を指定します。
トレーニングの最大繰り返し回数またはステップ数 イテレーション回数の最大値を指定します。
モデルをトレーニングするためのオプティマイザー モデルをトレーニングするためのオプティマイザーを指定します。
- Implements the Adagrad algorithm:Adagradアルゴリズム
- Implements the Adam algorithm:Adamアルゴリズム
- Implements the FTRL algorithm:FTRLアルゴリズム
- Implements the RMSProp algorithm:RMSPropアルゴリズム
- Implements the gradient descent algorithm:勾配降下アルゴリズム
- [
モデル作成]ボタンをクリック
- [
閉じる]ボタンをクリック
以上で、モデルの作成は完了です。
モデル確認
モデルの作成が完了したら、そのモデルの内容を確認して評価できます。
- ホーム画面から[
モデル]タブをクリック - 確認したいDeep Neural Network(回帰)モデルの名前をクリック
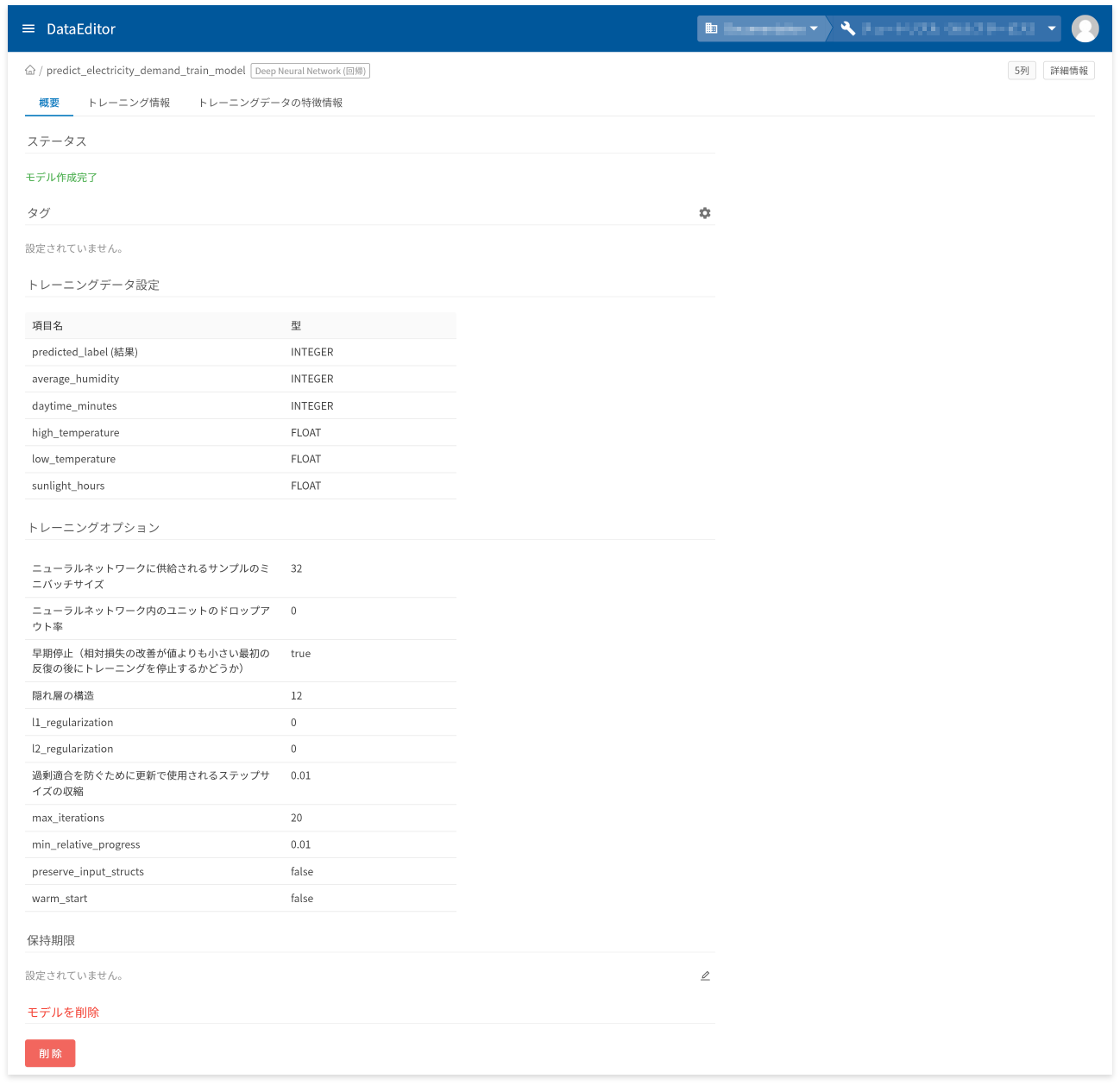
モデル詳細画面の[概要]タブでは、以下に挙げる情報の確認と操作ができます。
- モデル作成状況を表すステータスの確認
- タグの設定と確認
- トレーニングデータの項目と型の確認
- トレーニングオプションの確認
- 保存期限の設定と確認
- モデルの削除
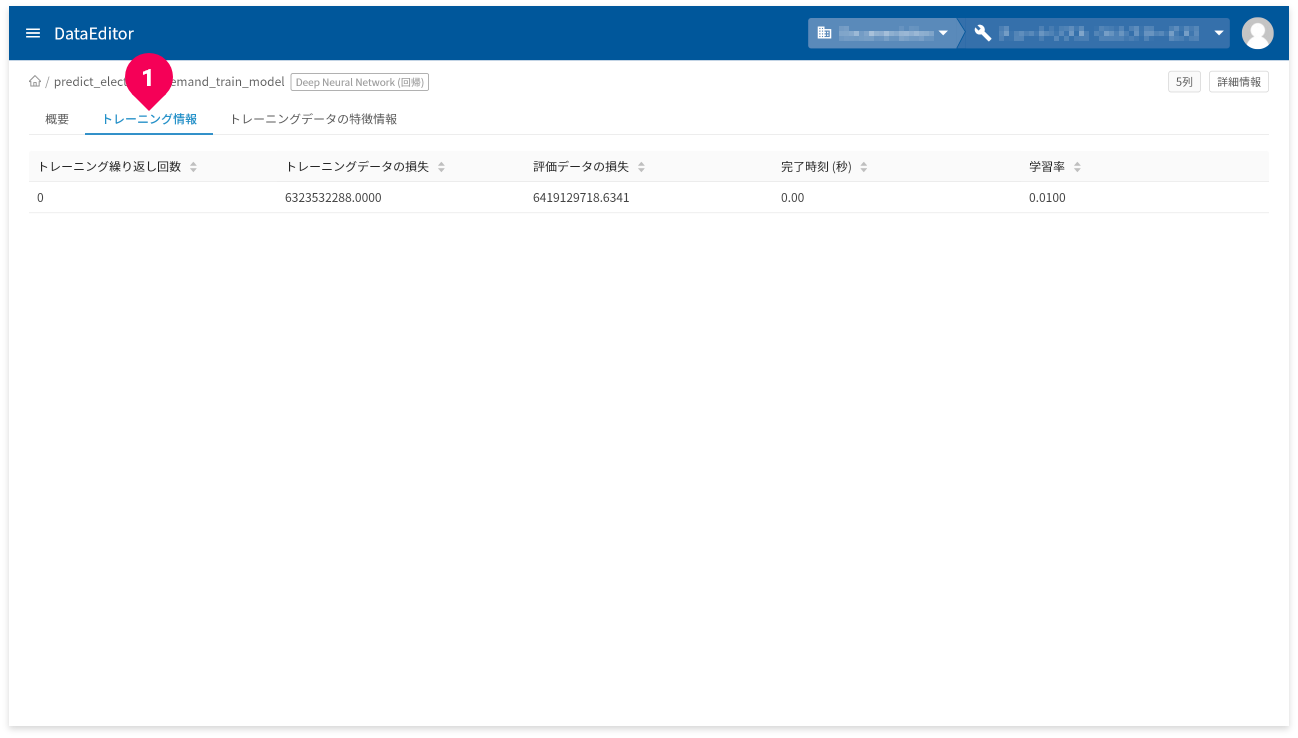
[トレーニング情報]タブ(❶)をクリックすると、トレーニング情報が確認できます。
- トレーニング繰り返し回数:トレーニングの繰返し回数
- トレーニングデータの損失:トレーニングデータの繰り返し後に計算された損失指標(平均二乗誤差)
- 評価データの損失:評価の損失指標
- 完了時刻:各トレーニングの時間
- 学習率:各トレーニングの学習率
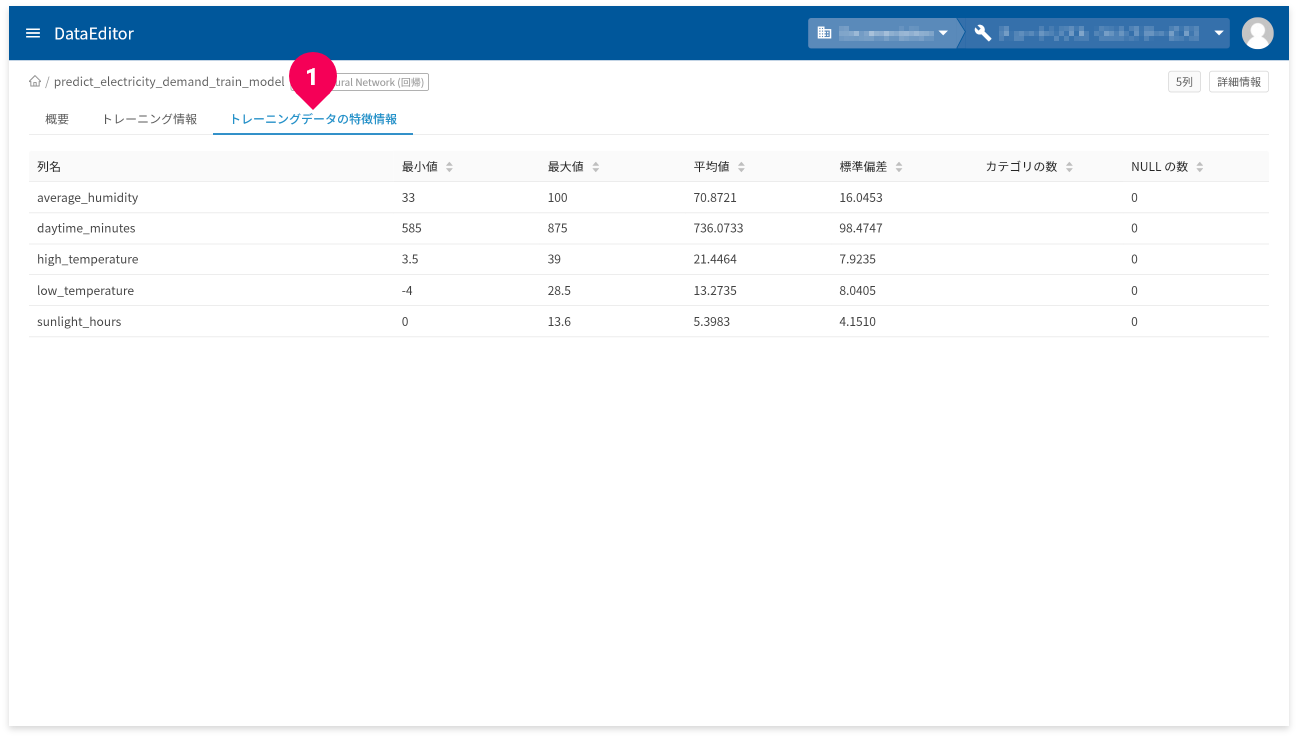
[トレーニングデータの特徴情報]タブ(❶)をクリックすると、トレーニングデータの特徴情報が確認できます。
- 列名:トレーニングデータの列名
- 最小値:トレーニングデータの最小値。数値以外の場合はNULL。
- 最大値:トレーニングデータの最大値。数値以外の場合はNULL。
- 平均値:トレーニングデータの平均値。数値以外の場合はNULL。
- 標準偏差:トレーニングデータの標準偏差。数値以外の場合はNULL。
- カテゴリの数:カテゴリの数。カテゴリ以外の列の場合はNULL。
- NULLの数:NULL値の数
予測
作成したモデルと予測用のデータを使って、簡単に予測ができます。
- ホーム画面から予測用のデータをクリック
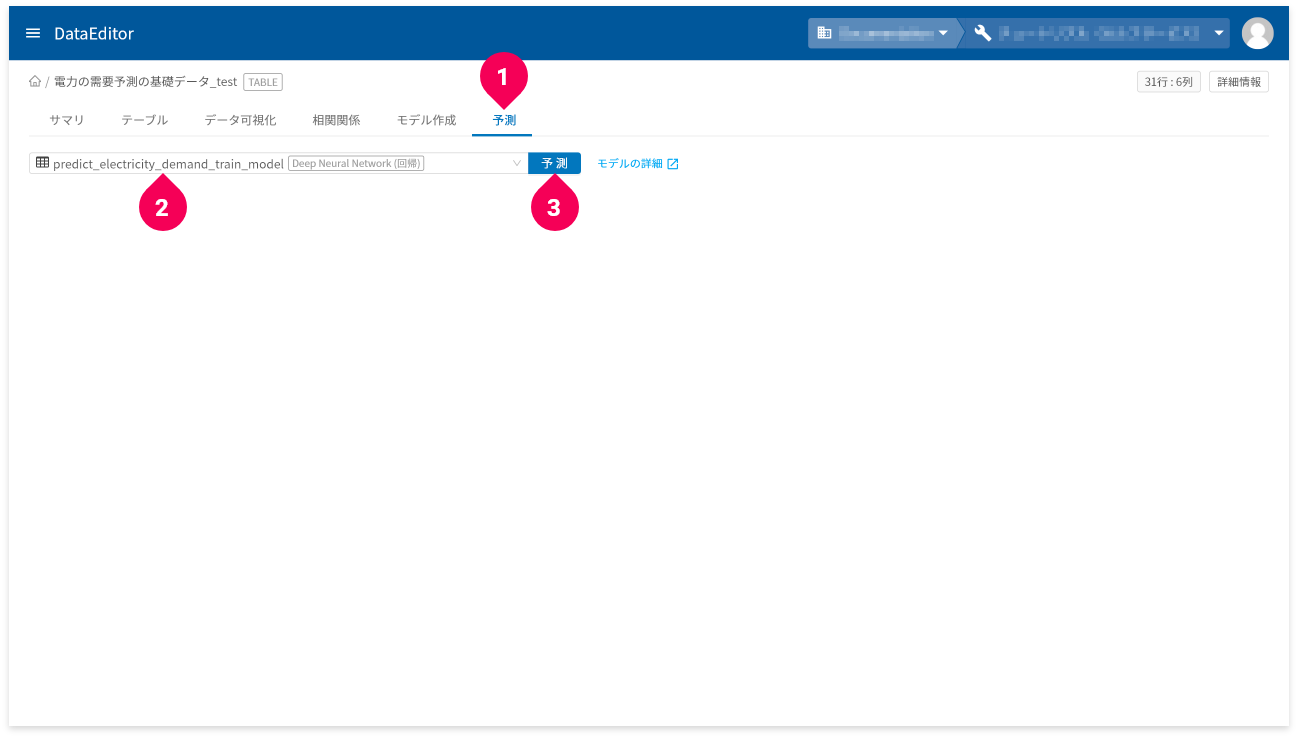
- [
予測]タブをクリック - 予測に使用するDeep Neural Network(回帰)モデルをクリック
- [
予測]ボタンをクリック
予測が完了すると、結果が表示されます。
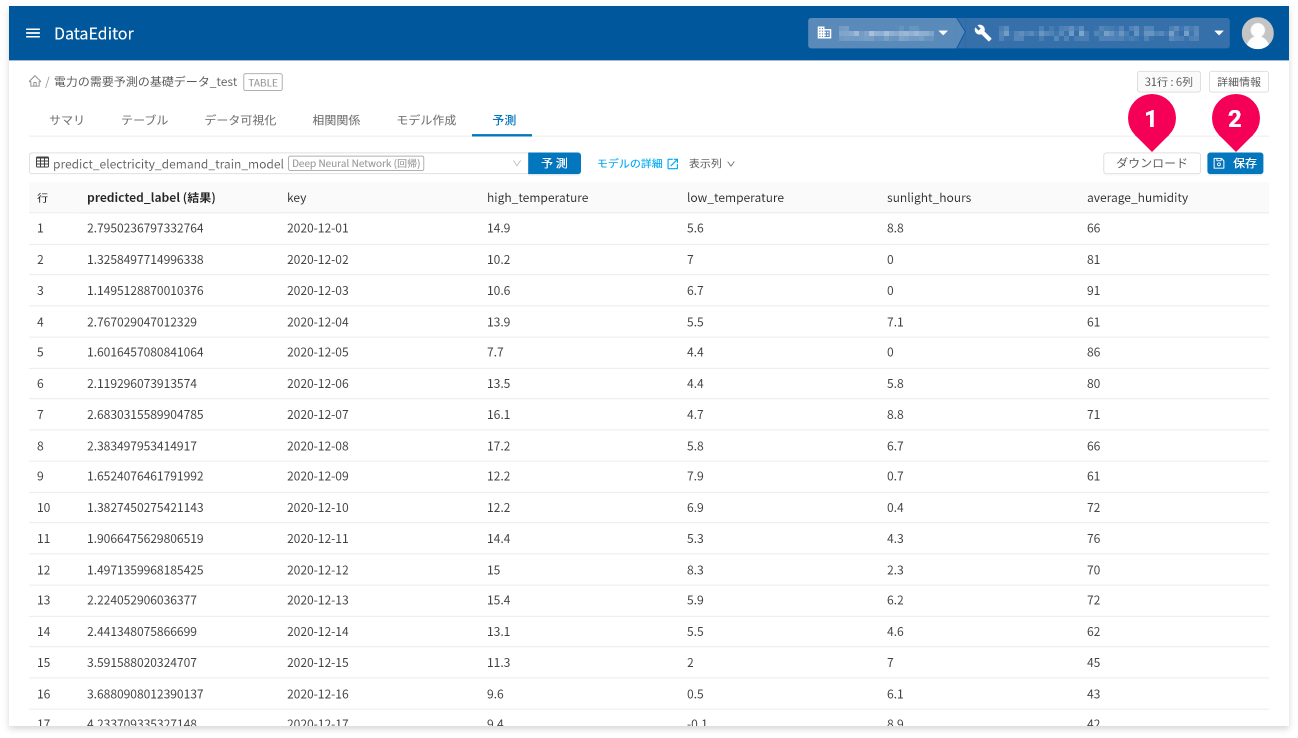
[ダウンロード]ボタン(❶)をクリックすると、予測結果の表を
CSV形式のデータでダウンロードできます。
- 予測結果の画面が複数ページにまたがる場合は、一度表示したページ数分のデータをダウンロード
予測結果が3ページ分あり、2ページまで画面上で確認し[
ダウンロード]ボタンをクリックした場合、2ページ分のデータがダウンロードされます。 - ラベル(predicted_label_probs)欄は出力から除外
[保存]ボタン(❷)をクリックすると、予測結果をDataEditorに登録できます。これにより、データ可視化の機能を使って視覚的に予測結果の評価ができます。
モデルジェネレーター(回帰)の例
警告
モデルジェネレーターモデルは、2024年2月1日以降、非推奨となりました。2024年2月1日のMAGELLAN BLOCKSのリリース以降、このモデルの作成はできません。作成済みのこのモデルについては、他のモデルで再作成してください。
予測
予測の手順は以下のとおりです。
まず、予測用データの画面を以下の手順で開きます。
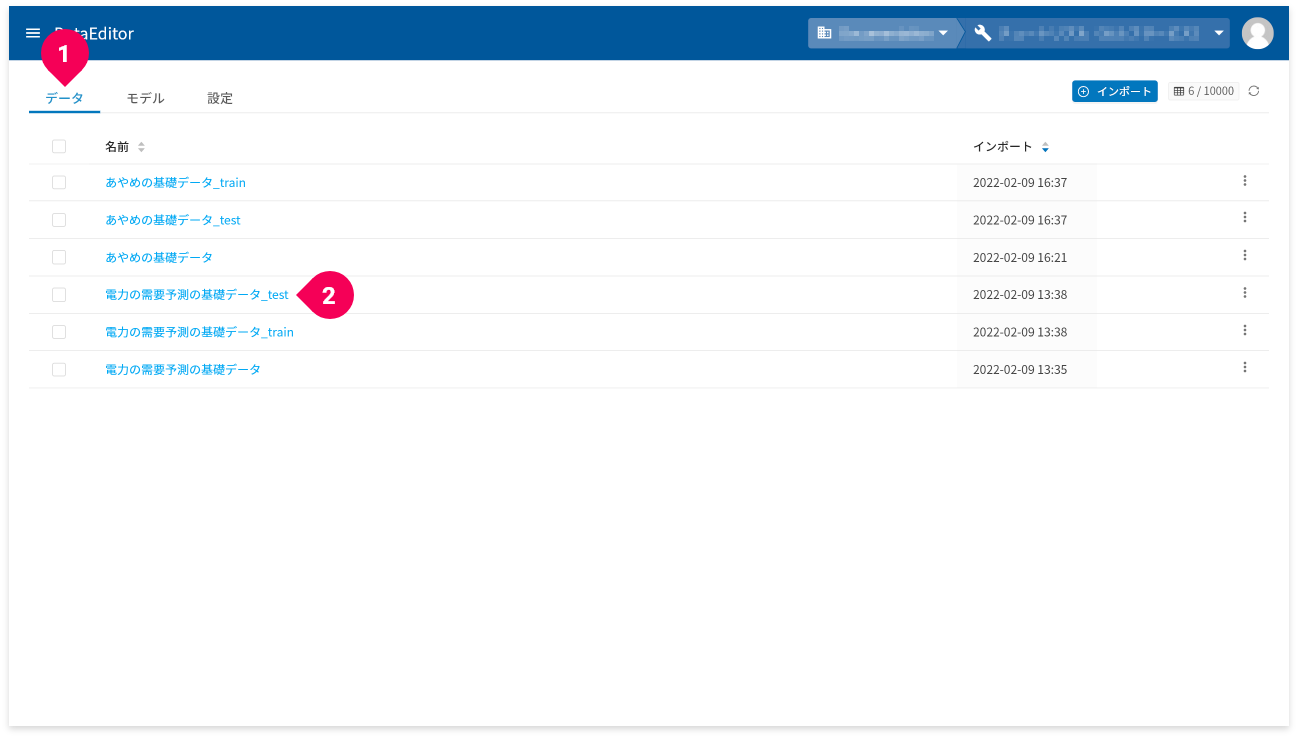
- [
データ]タブをクリック - 予測用データをクリック
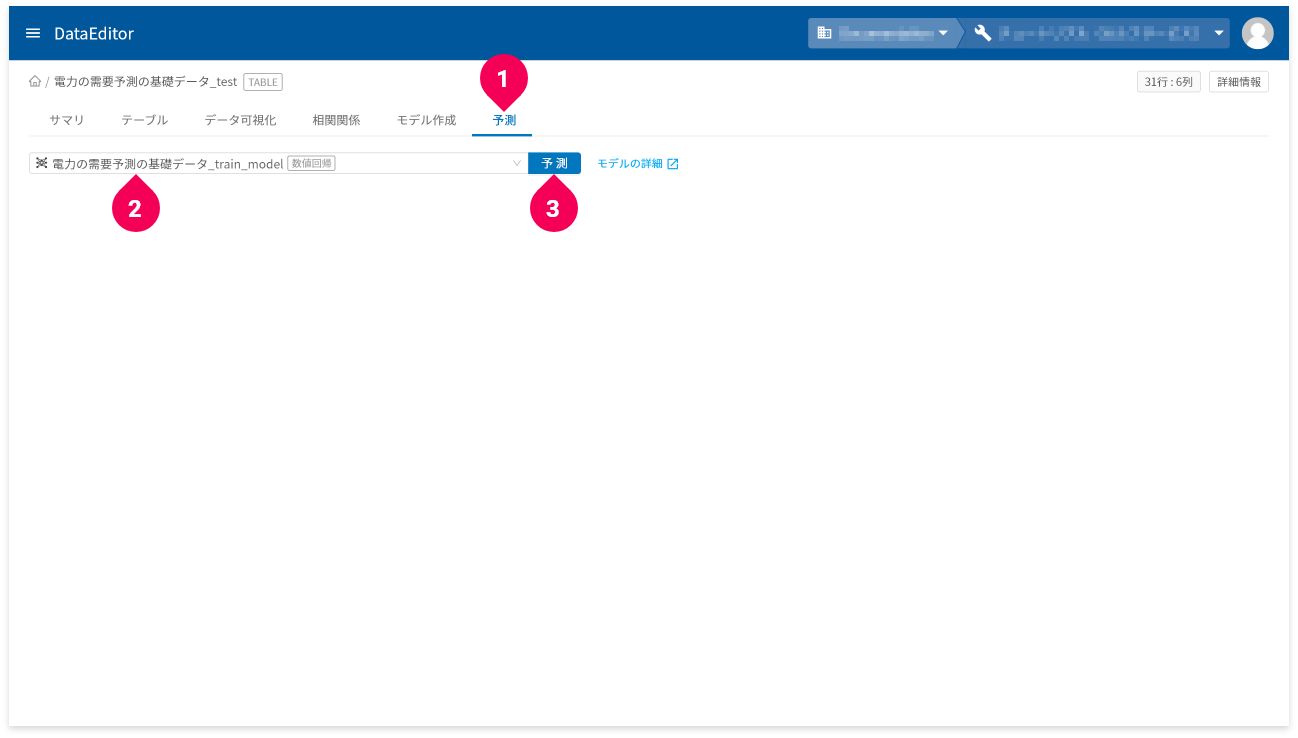
- [
予測]タブをクリック - 予測に使用するモデルをクリック
- [
予測]ボタンをクリック
しばらくすると、予測結果が表示されます。
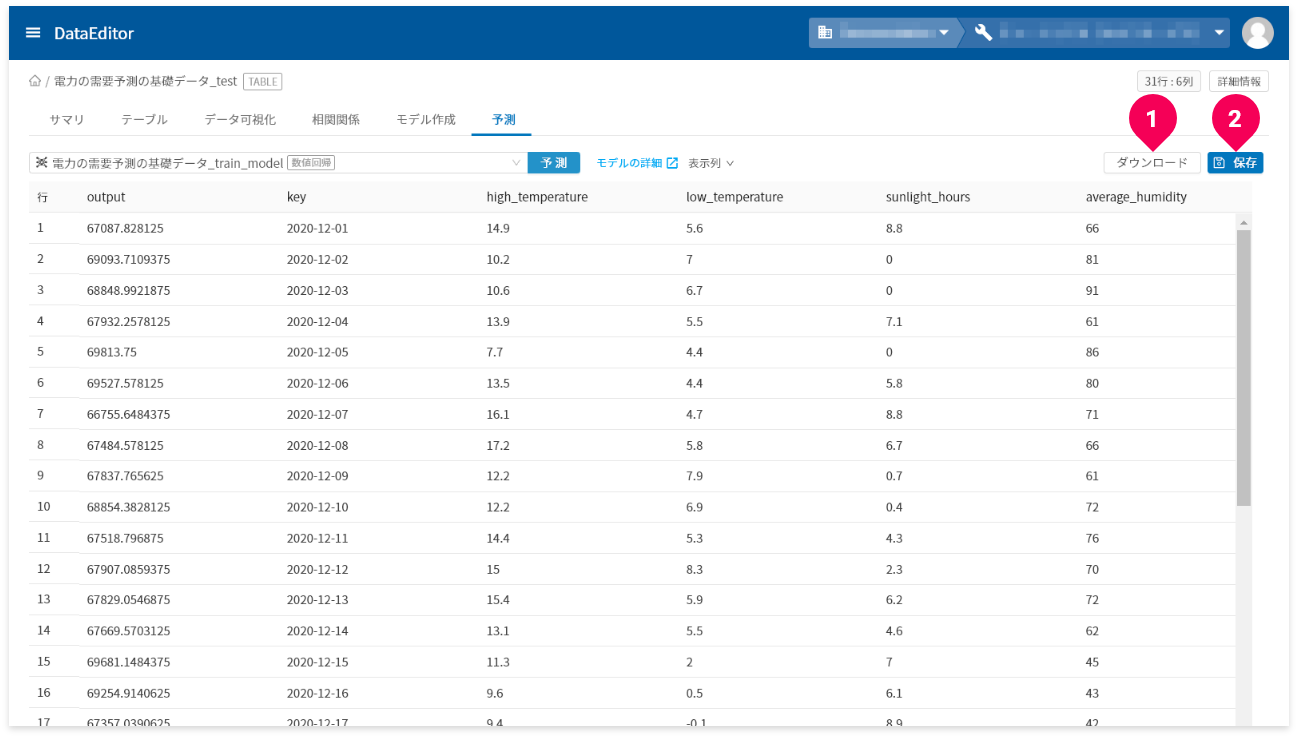
[ダウンロード]ボタン(❶)をクリックすると、予測結果をCSV形式のデータでダウンロードできます。
- 予測結果の画面が複数ページにまたがる場合は、一度表示したページ数分のデータをダウンロード
予測結果が3ページ分あり、2ページまで画面上で確認し[
ダウンロード]ボタンをクリックした場合、2ページ分のデータがダウンロードされます。
[保存]ボタン(❷)をクリックすると、予測結果をDataEditorに登録できます。これにより、データ可視化の機能を使って視覚的に予測結果の評価ができます。
ロジスティック回帰(分類)の例
モデル作成
- ホーム画面からモデル作成用のトレーニングデータをクリック
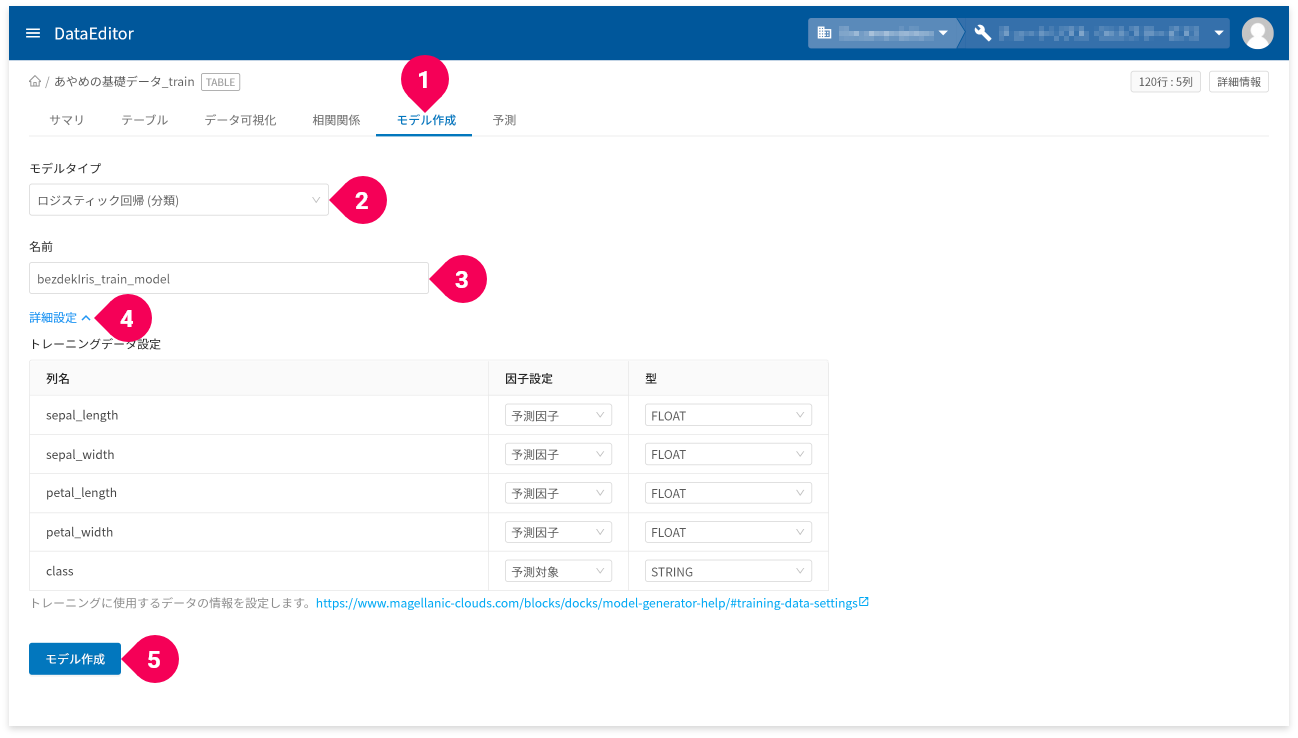
- [
モデル作成]タブをクリック - [
ロジスティック回帰(分類)]をクリック - 名前を必要に応じて変更
- [
詳細設定]をクリック
トレーニングデータ設定が編集できます。 - [
モデル作成]ボタンをクリック
- [
閉じる]ボタンをクリック
以上で、モデルの作成は完了です。
モデル確認
モデルの作成が完了したら、そのモデルの内容を確認して評価できます。
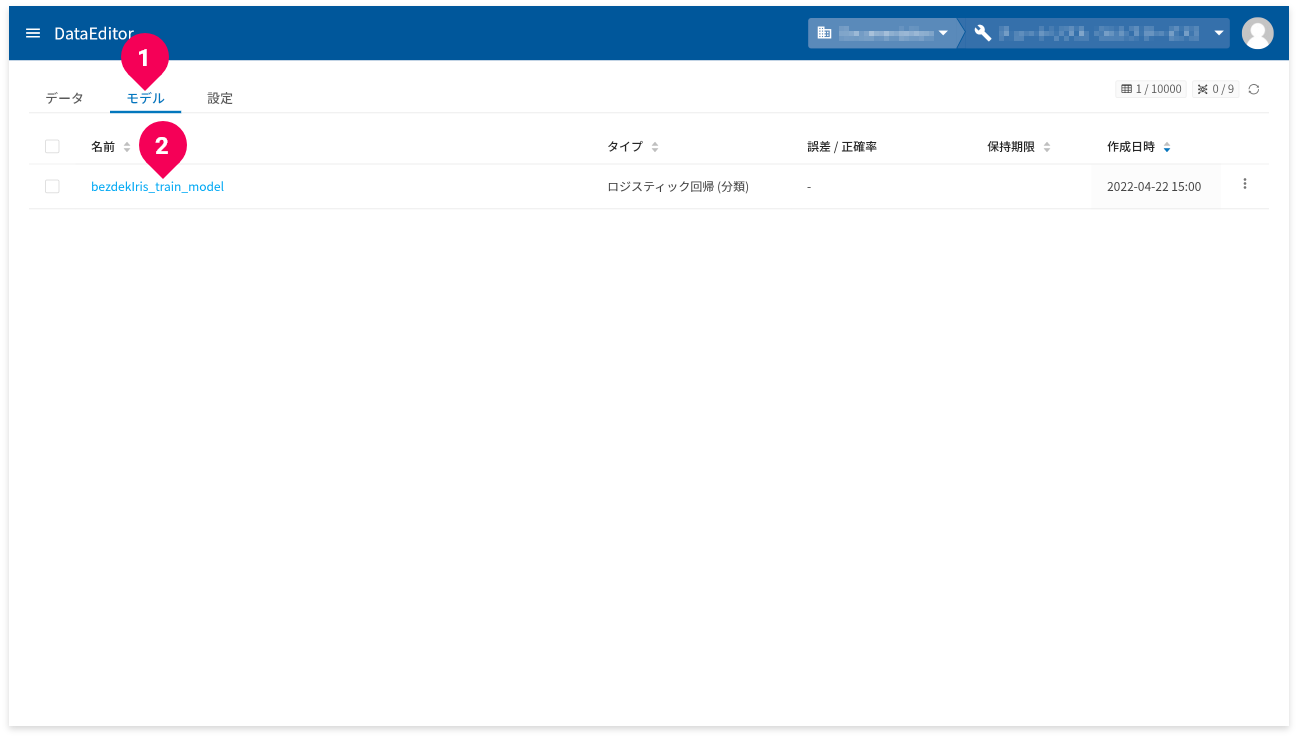
- ホーム画面から[
モデル]タブをクリック - 確認したいロジスティック回帰(分類)モデルの名前をクリック
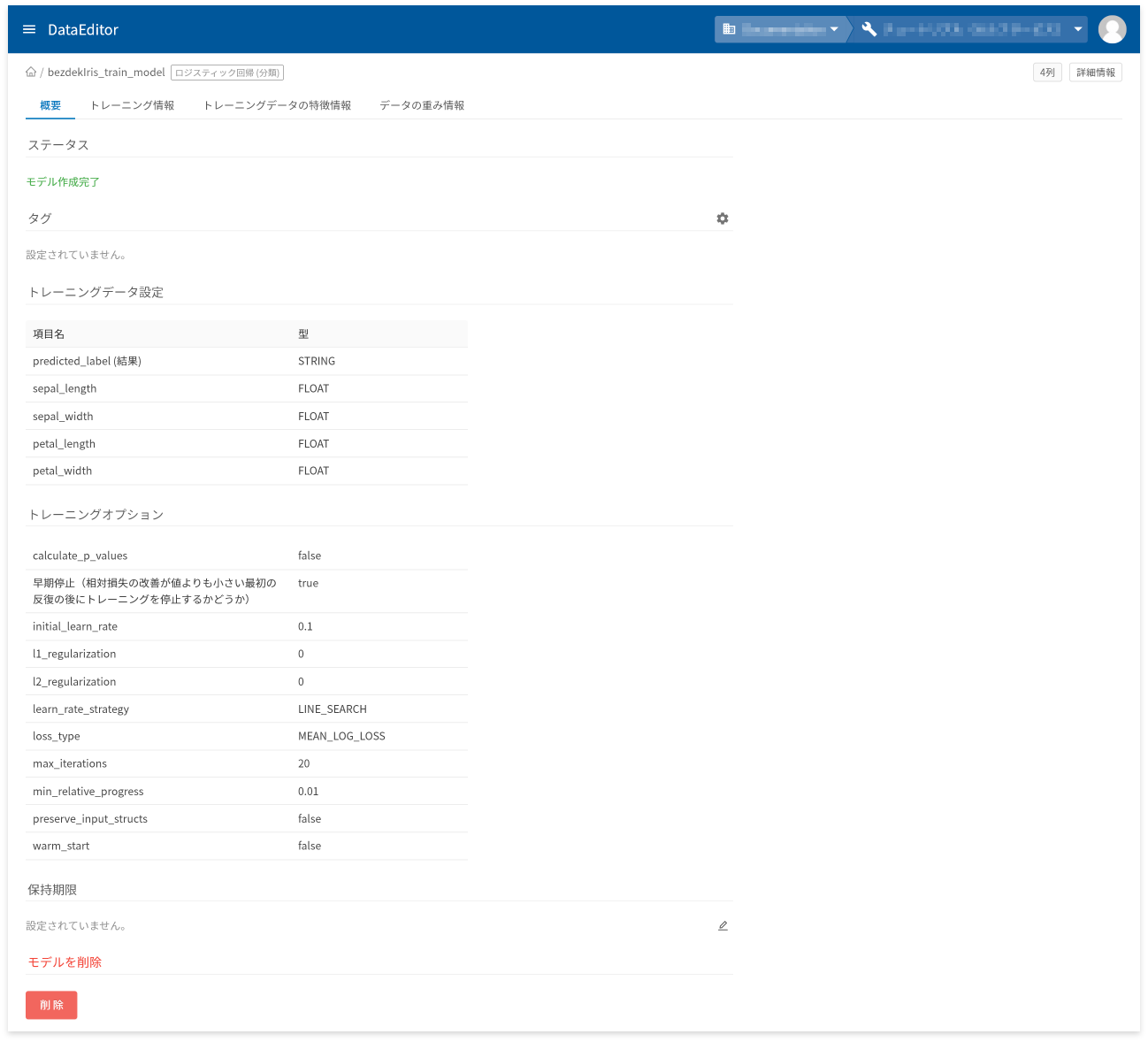
モデル詳細画面の[概要]タブでは、以下に挙げる情報の確認と操作ができます。
- モデル作成状況を表すステータスの確認
- タグの設定と確認
- トレーニングデータの項目と型の確認
- トレーニングオプションの確認
- 保存期限の設定と確認
- モデルの削除
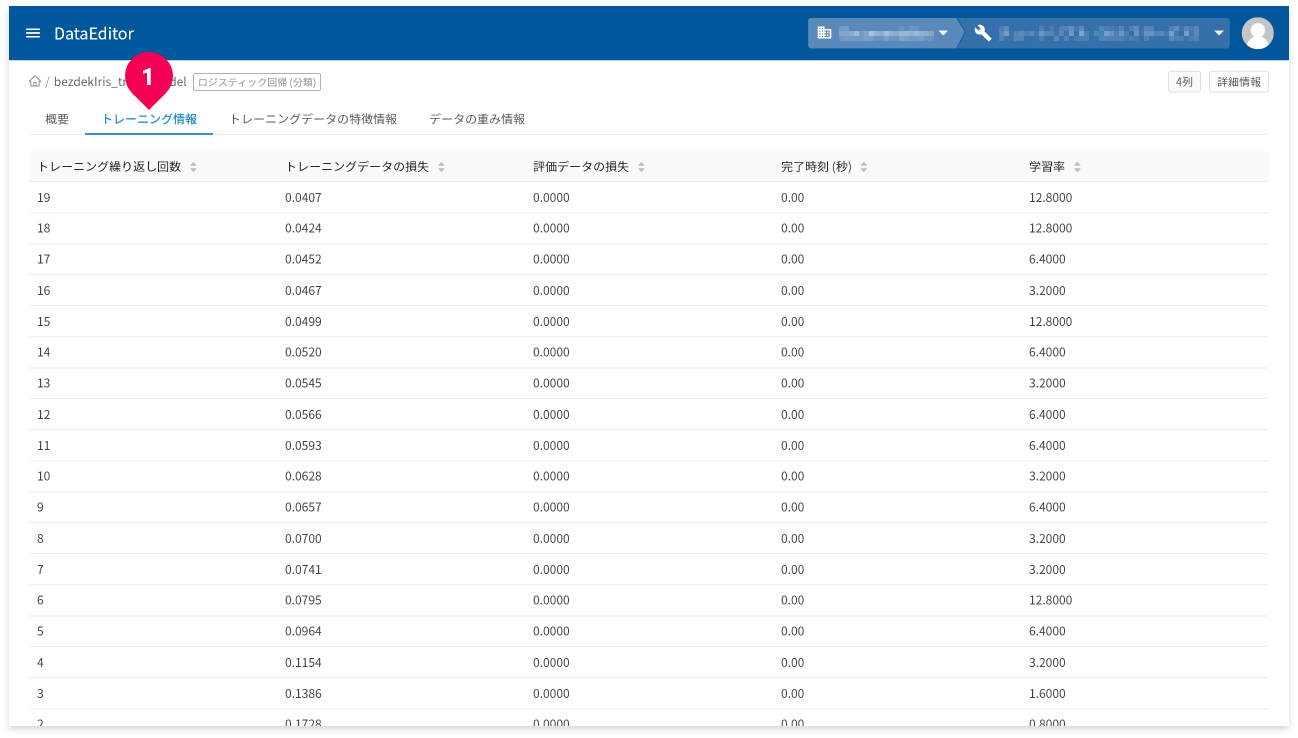
[トレーニング情報]タブ(❶)をクリックすると、トレーニング(学習)の情報が確認できます。
- トレーニング繰り返し回数:トレーニングの繰返し回数です。
- トレーニングデータの損失:トレーニングデータの繰り返し後に計算された損失指標(平均二乗誤差)です。
- 評価データの損失:評価の損失指標です。
- 完了時刻:各トレーニングの時間
- 学習率:各トレーニングの学習率
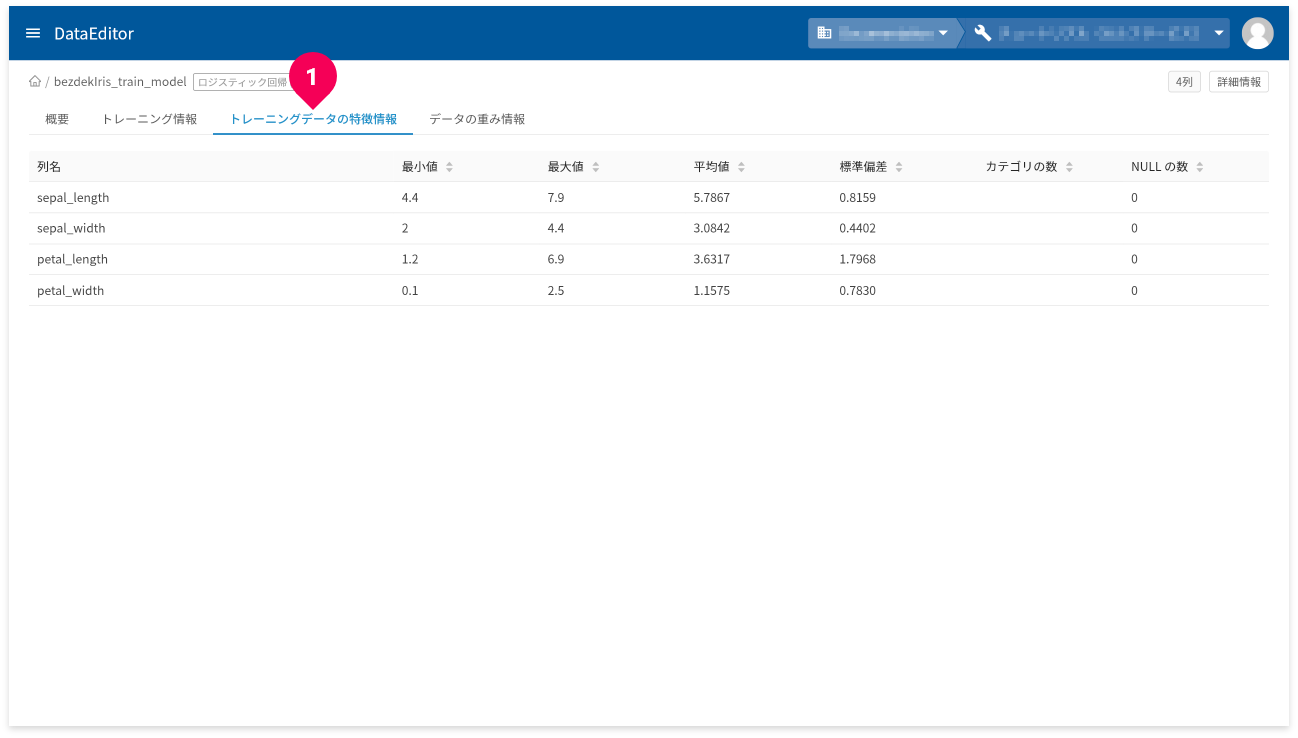
[トレーニングデータの特徴情報]タブ(❶)をクリックすると、トレーニングデータの特徴情報が確認できます。
- 列名:トレーニングデータの列名です。
- 最小値:トレーニングデータの最小値です。数値以外の場合は、NULLになります。
- 最大値:トレーニングデータの最大値です。数値以外の場合は、NULLになります。
- 平均値:トレーニングデータの平均値です。数値以外の場合は、NULLになります。
- 標準偏差:トレーニングデータの標準偏差です。数値以外の場合は、NULLになります。
- カテゴリの数:カテゴリの数です。カテゴリ以外の列の場合、NULLになります。
- NULLの数:NULLの数です。
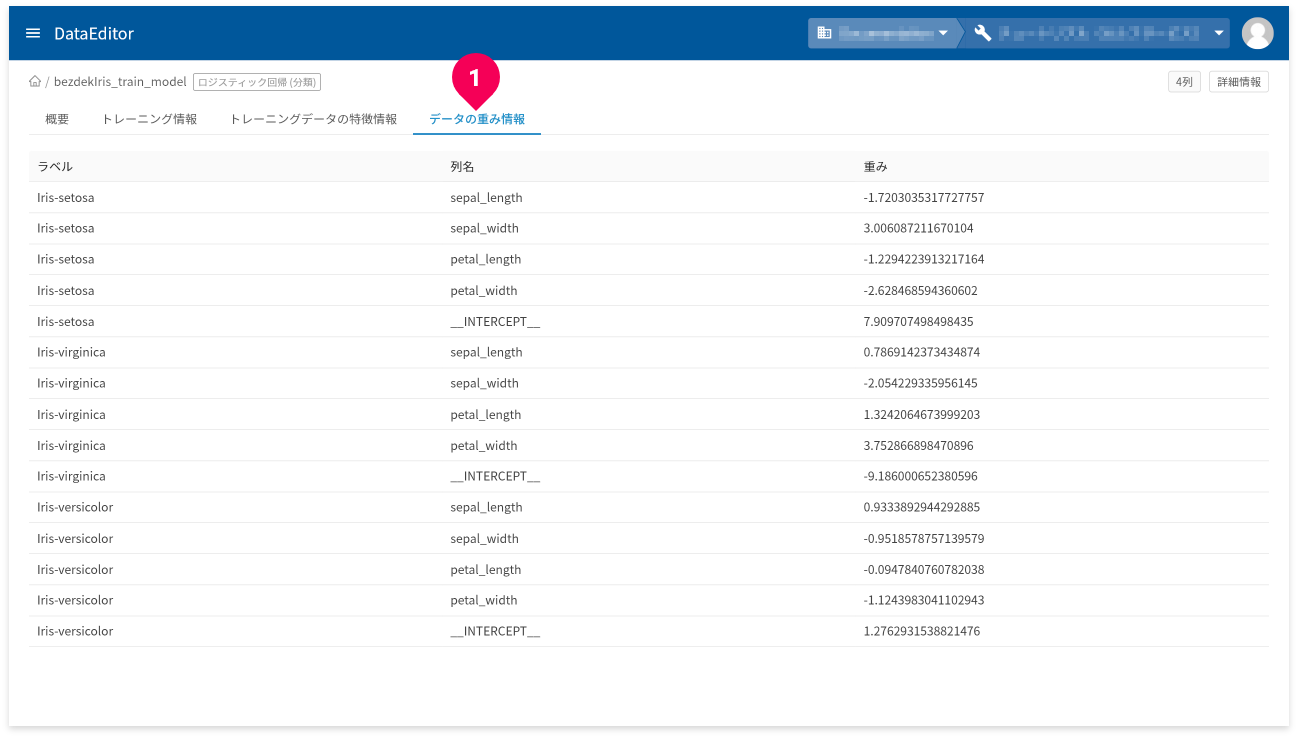
[データの重み情報]タブ(❶)をクリックすると、トレーニングデータの重み情報が確認できます。
モデルを評価した結果が悪ければ、トレーニングデータの因子(列)を見直して、モデルを作り直し再度評価します。このサイクルを良い結果が得られるまで繰り返します。
予測
作成したモデルと予測用のデータを使って、簡単に予測ができます。
- ホーム画面のデータ一覧から予測用のデータをクリック
- [
予測]タブをクリック - 予測に使用するロジスティック回帰(分類)モデルをクリック
- [
予測]ボタンをクリック
予測が完了すると、結果が表示されます。
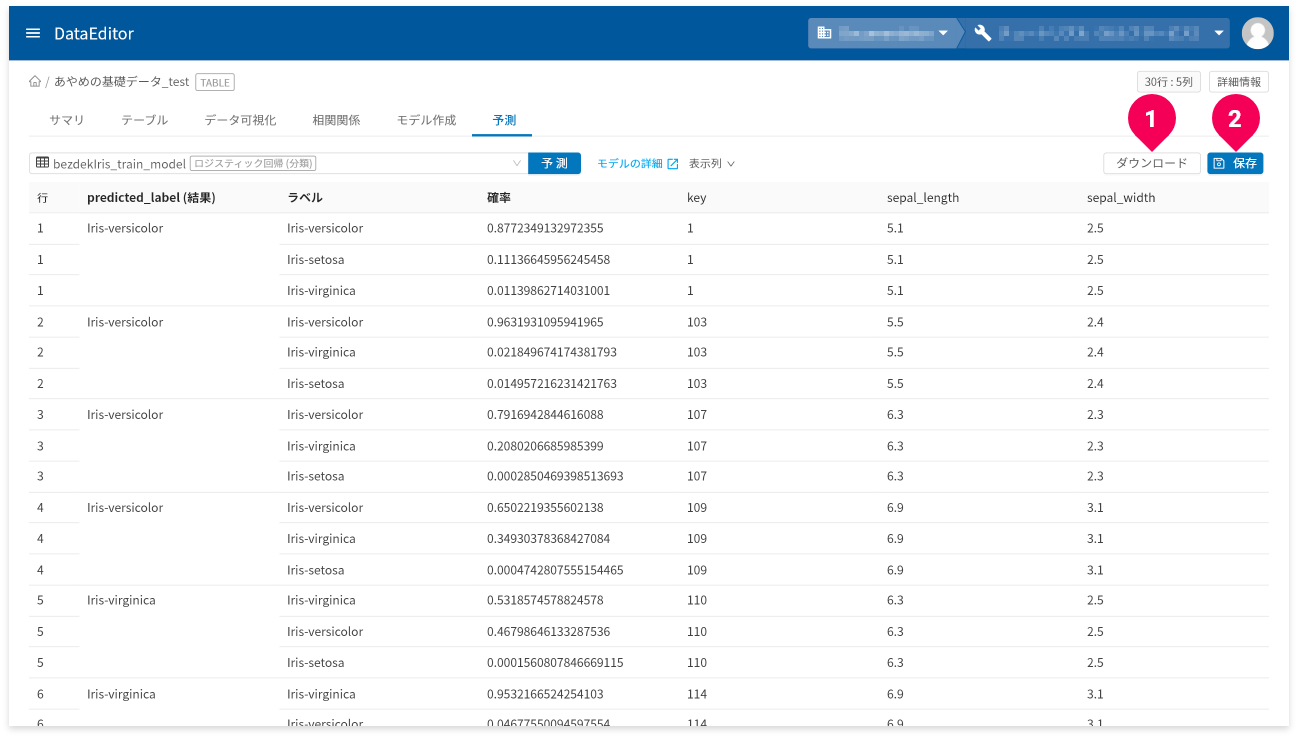
[ダウンロード]ボタン(❶)をクリックすると、予測結果の表を
CSV形式のデータでダウンロードできます。
- 予測結果の画面が複数ページにまたがる場合は、一度表示したページ数分のデータをダウンロードページ分のデータがダウンロードされます。
[保存]ボタン(❷)をクリックすると、予測結果をDataEditorに登録できます。これにより、データ可視化の機能を使って視覚的に予測結果の評価ができます。
AutoML(分類)の例
モデル作成
- ホーム画面からモデル作成用のトレーニングデータをクリック
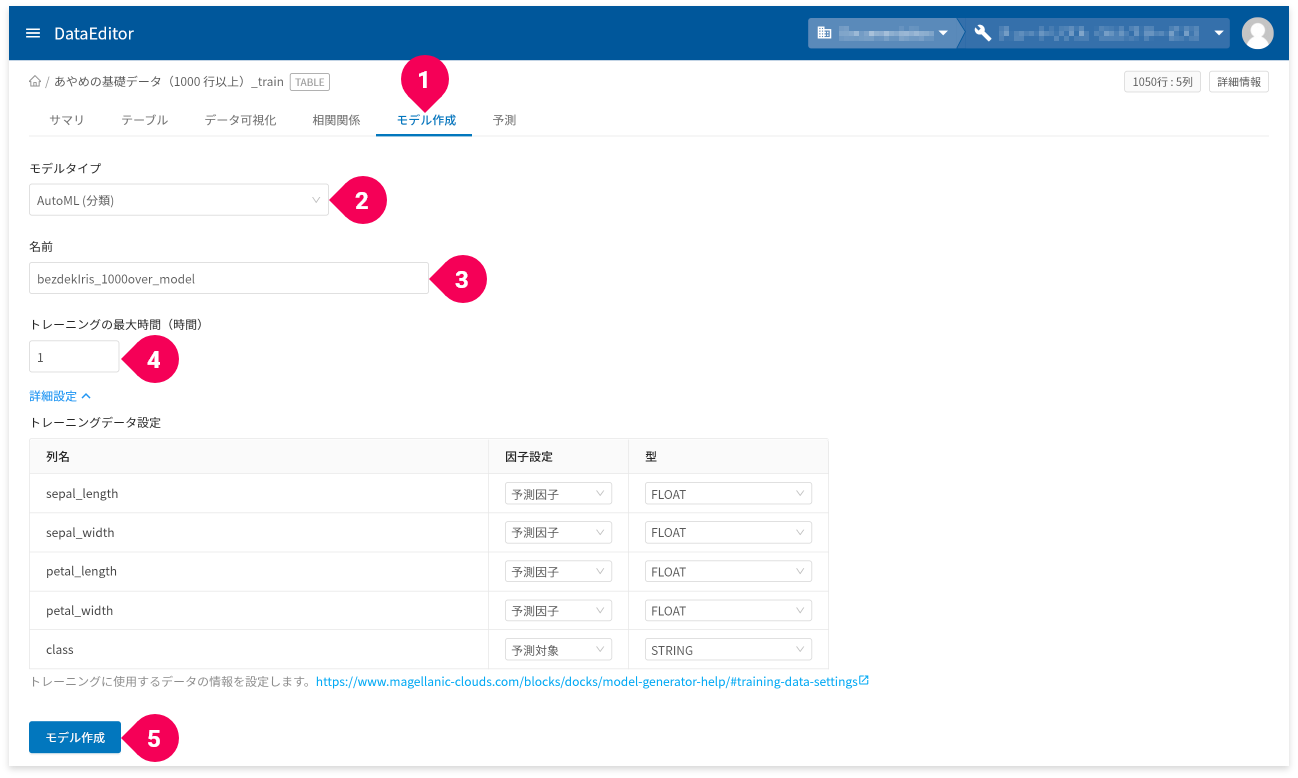
- [
モデル作成]タブをクリック - [
AutoML(分類)]をクリック - 名前を必要に応じて変更
- トレーニングの最大時間を時間単位で設定
- [
詳細設定]をクリック
トレーニングデータ設定が編集できます。 - [
モデル作成]ボタンをクリック
- [
閉じる]ボタンをクリック
以上で、モデルの作成は完了です。
モデル確認
モデルの作成が完了したら、そのモデルの内容を確認して評価できます。
- ホーム画面から[
モデル]タブをクリック - 確認したいAutoML(分類)モデルの名前をクリック
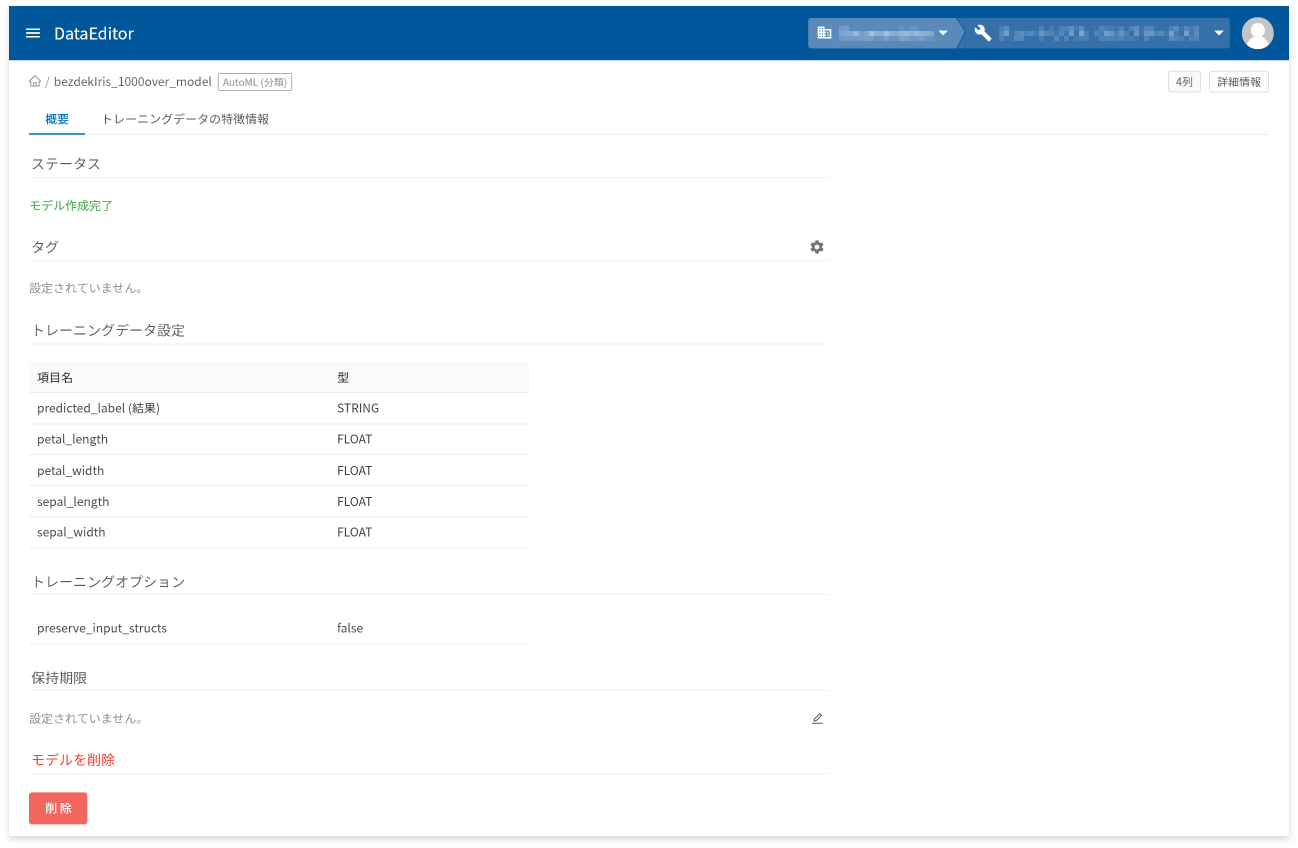
モデル詳細画面の[概要]タブでは、以下に挙げる情報の確認と操作ができます。
- モデル作成状況を表すステータスの確認
- タグの設定と確認
- トレーニングデータの項目と型の確認
- トレーニングオプションの確認
- 保存期限の設定と確認
- モデルの削除
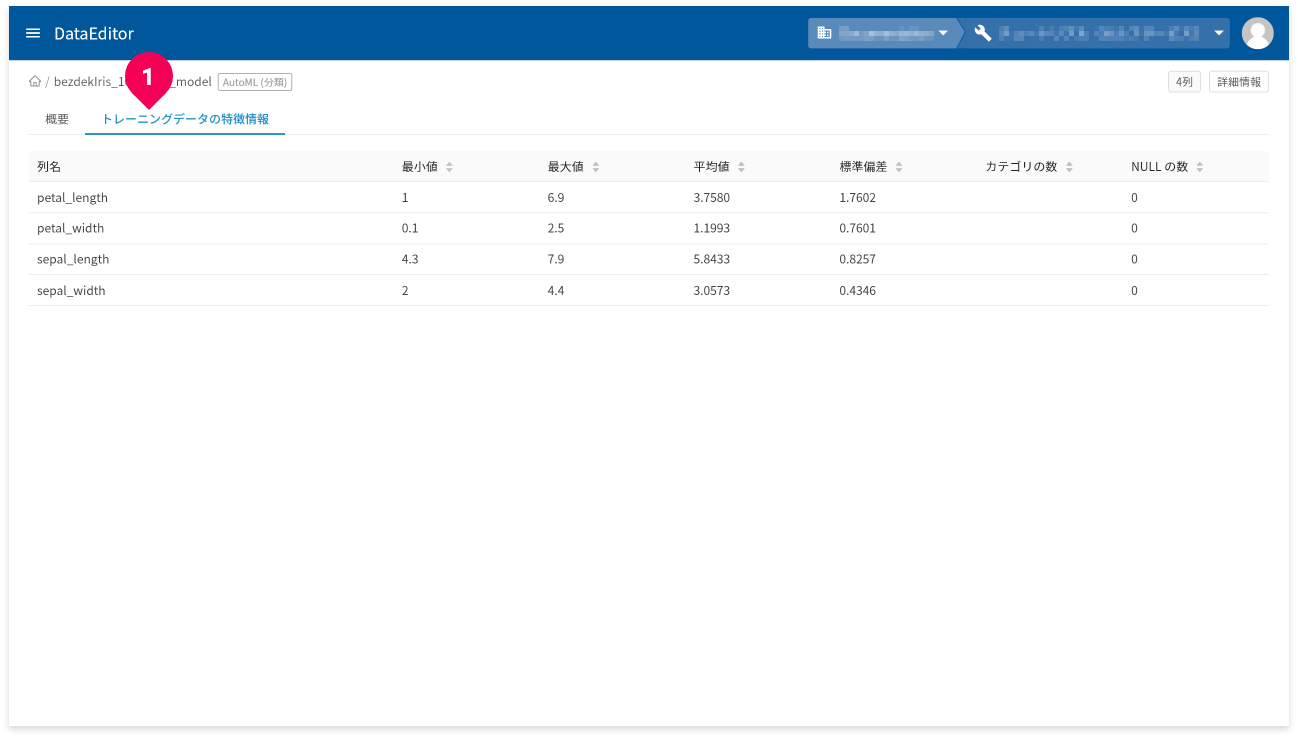
[トレーニングデータの特徴情報]タブ(❶)をクリックすると、トレーニングデータの特徴情報が確認できます。
- 列名:トレーニングデータの列名
- 最小値:トレーニングデータの最小値
- 最大値:トレーニングデータの最大値
- 平均値:トレーニングデータの平均値
- 標準偏差:トレーニングデータの標準偏差
- カテゴリの数:カテゴリの数
- NULLの数:NULL値の数
予測
作成したモデルと予測用のデータを使って、簡単に予測ができます。
- ホーム画面から予測用のデータをクリック
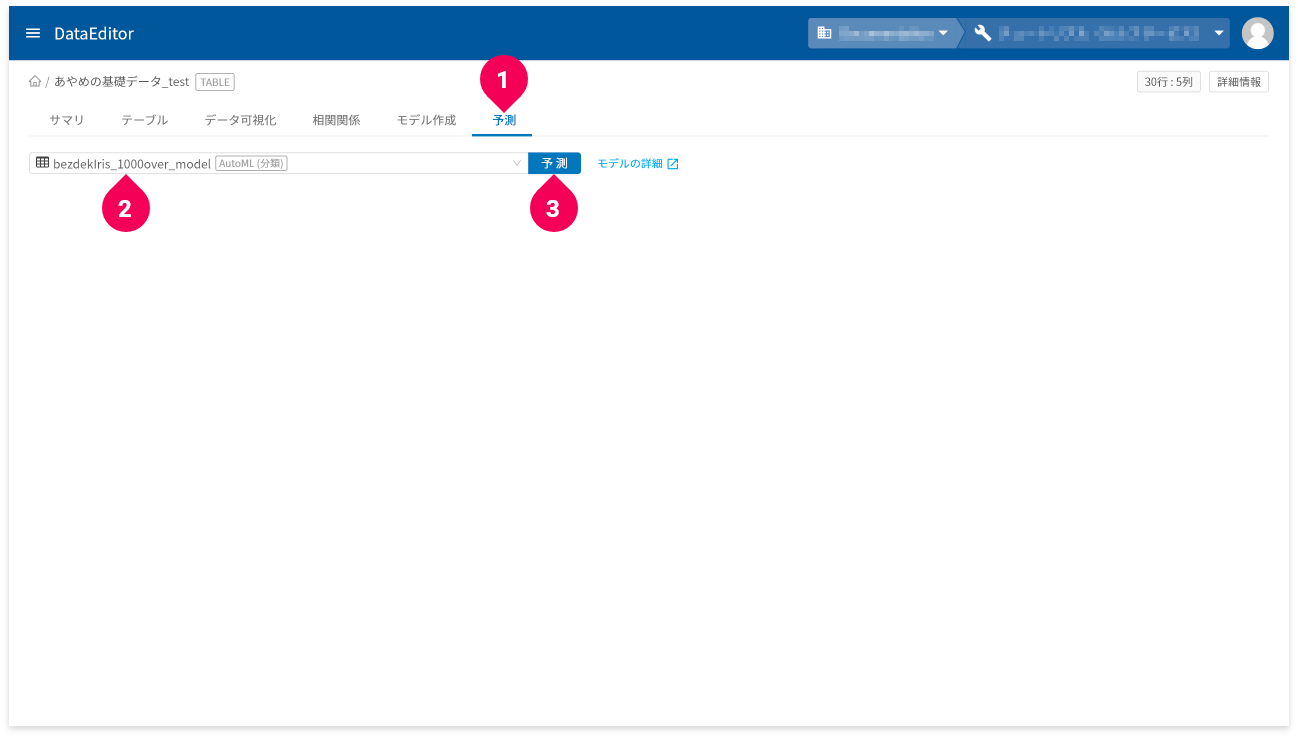
- [
予測]タブをクリック - 予測に使用するAutoML(分類)モデルをクリック
- [
予測]ボタンをクリック
予測が完了すると、結果が表示されます。
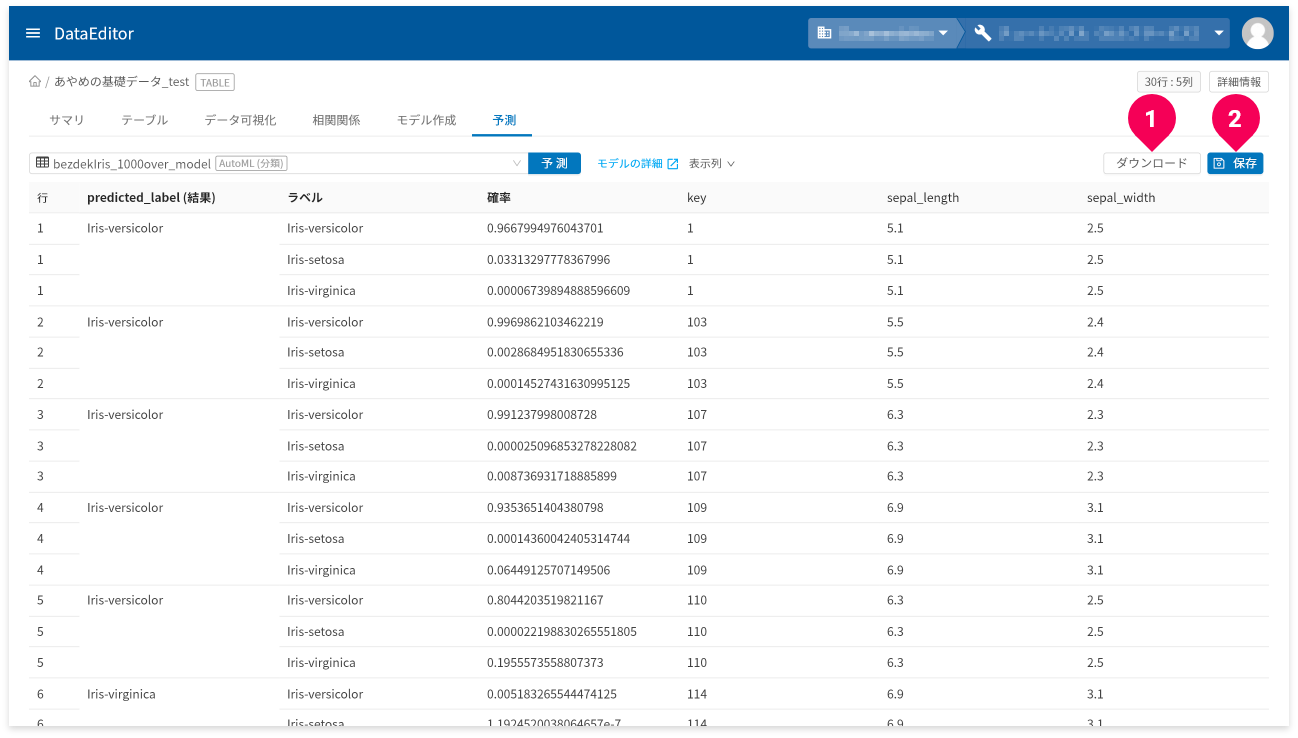
[ダウンロード]ボタン(❶)をクリックすると、予測結果の表を
CSV形式のデータでダウンロードできます。
- 予測結果の画面が複数ページにまたがる場合は、一度表示したページ数分のデータをダウンロード
予測結果が3ページ分あり、2ページまで画面上で確認し[
ダウンロード]ボタンをクリックした場合、2ページ分のデータがダウンロードされます。 - ラベル(predicted_label_probs)欄は出力から除外
[保存]ボタン(❷)をクリックすると、予測結果をDataEditorに登録できます。これにより、データ可視化の機能を使って視覚的に予測結果の評価ができます。
XGBoost(分類)の例
モデル作成
- ホーム画面からモデル作成用のトレーニングデータをクリック
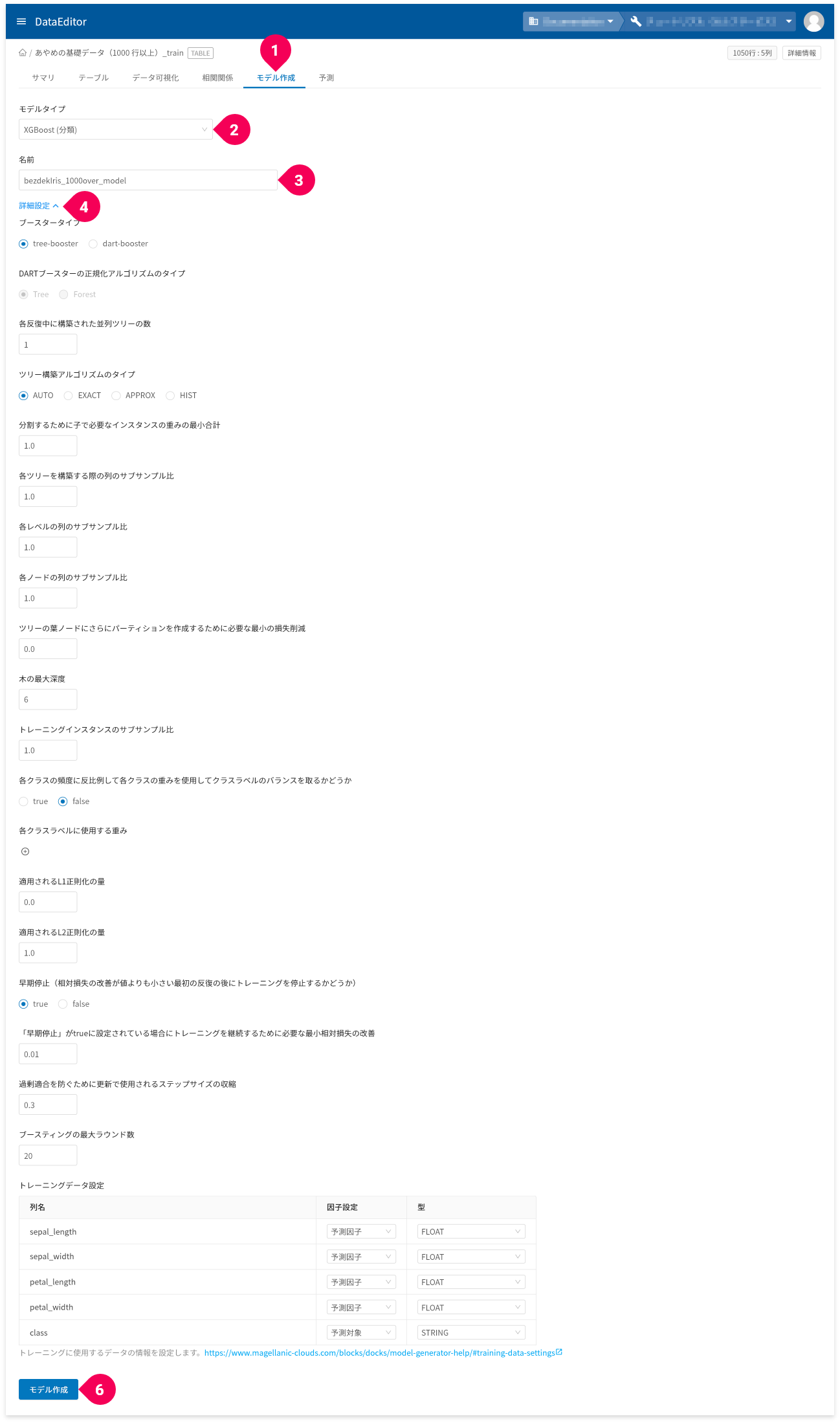
- [
モデル作成]タブをクリック - [
XGBoost(分類)]をクリック - 名前を必要に応じて変更
- [
詳細設定]をクリック
各種パラメーターの設定とトレーニングデータの設定ができます。パラメーター 説明 ブースタータイプ 使用するブースターのタイプを指定します。
DARTブースターの正規化アルゴリズムのタイプ DARTブースターの正規化アルゴリズムのタイプを指定します。
- Tree
- Forest
各反復中に構築された並列ツリーの数 各反復の間に構築される並列ツリーの数。デフォルト値は1です。ブーストされたランダムフォレストを学習するには、この値を1よりも大きく設定してください。
ツリー構築アルゴリズムのタイプ ツリー構築アルゴリズムの種類を指定します。
- AUTO
- EXACT
- APPROX
- HIST
分割するために子で必要なインスタンスの重みの最小合計 さらなるパーティショニングに必要な子ノードのインスタンスの重みの最小値を指定します。
ツリーの分割ステップの結果、インスタンス重みの合計が指定した値よりも小さいリーフノードが得られた場合、構築プロセスはそれ以上の分割を停止します。指定した値が大きいほど、アルゴリズムはより保守的になります。
値は必ず0以上を指定します。
各ツリーを構築する際の列のサブサンプル比 各ツリーを構築する際の列のサブサンプル率を指定します。
サブサンプリングは、構築されたツリーごとに1回行われます。
値は0から1の間で指定します。
各レベルの列のサブサンプル比 各レベルの列のサブサンプル率を指定します。
サブサンプリングは、ツリー内の新しい深さレベルへ到達するごとに1回行われます。列は、現在のツリーで選択された列のセットからサブサンプリングされます。
値は0から1の間で指定します。
各ノードの列のサブサンプル比 各ノード(スプリット)の列のサブサンプル率を指定します。
サブサンプリングは、新しいスプリットが評価されるたびに1回発生します。
列は、現在のレベルで選択された列のセットからサブサンプリングされます。
値は0から1の間で指定します。
ツリーの葉ノードにさらにパーティションを作成するために必要な最小の損失削減 ツリーのリーフノードでさらに分割するのに必要な損失の最小値を指定します。
指定した値が大きいほど、アルゴリズムはより保守的になります。
木の最大深度 ツリーの最大深度を指定します。
トレーニングインスタンスのサブサンプル比 トレーニングインスタンスのサブサンプル率を指定します。
この値を0.5に設定すると、ツリーを成長させる前にトレーニングがトレーニングデータの半分をランダムにサンプリングすることになり、オーバーフィットを防ぐことができます。
サブサンプリングは、各反復ごとに1回行われます。
値は0から1の間で指定します。
各クラスラベルに使用する重み クラスラベルごとに重みを設定します。
適用されるL1正則化の量 L1正則化open_in_newの適用量を指定します。
適用されるL2正則化の量 L2正則化の適用量を指定します。
早期停止(相対損失の改善が値よりも小さい最初の反復の後にトレーニングを停止するかどうか) 最初の反復の後で、「
「早期停止」がtrue に設定されている場合にトレーニングを継続するために必要な最小相対損失の改善」パラメーターで指定された値よりも小さいときに、トレーニングを停止するかどうかを指定します。- true:停止する
- false:停止しない
「早期停止」がtrueに設定されている場合にトレーニングを継続するために必要な最小相対損失の改善 「
早期停止」パラメーターにtrueを指定した場合、トレーニングを継続するために必要な相対的な損失の最小改善量を指定します。たとえば、0.01の値を指定すると、トレーニングを継続するためには、各反復で損失を1%減少させる必要があります。
過剰適合を防ぐために更新で使用されるステップサイズの収縮 学習率を指定します。
ブースティングの最大ラウンド数 ブースティング時の最大ラウンド数を指定します。
- [
モデル作成]ボタンをクリック
- [
閉じる]ボタンをクリック
以上で、モデルの作成は完了です。
モデル確認
モデルの作成が完了したら、そのモデルの内容を確認して評価できます。
- ホーム画面から[
モデル]タブをクリック - 確認したいXGBoost(分類)モデルの名前をクリック
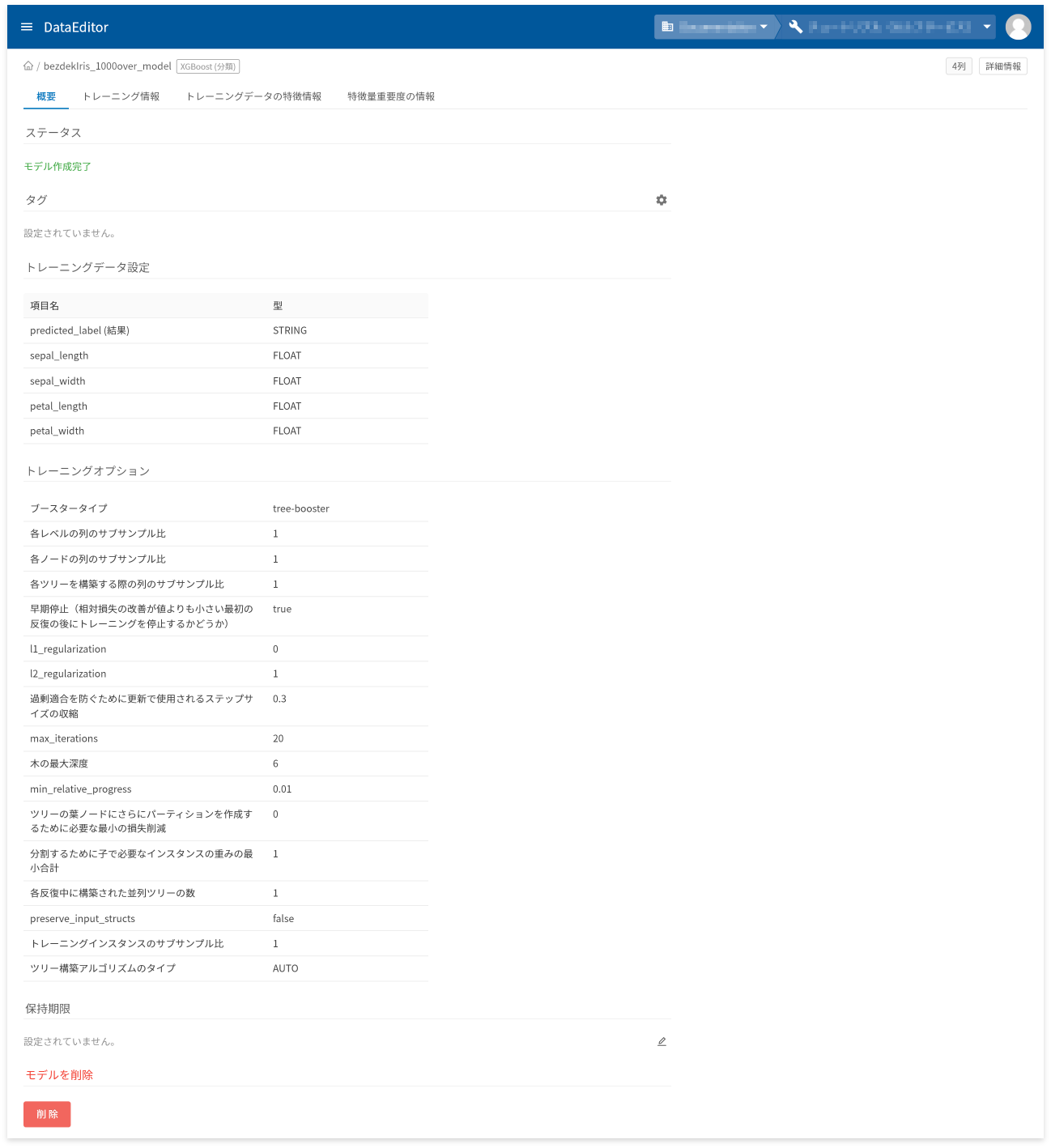
モデル詳細画面の[概要]タブでは、以下に挙げる情報の確認と操作ができます。
- モデル作成状況を表すステータスの確認
- タグの設定と確認
- トレーニングデータの項目と型の確認
- トレーニングオプションの確認
- 保存期限の設定と確認
- モデルの削除
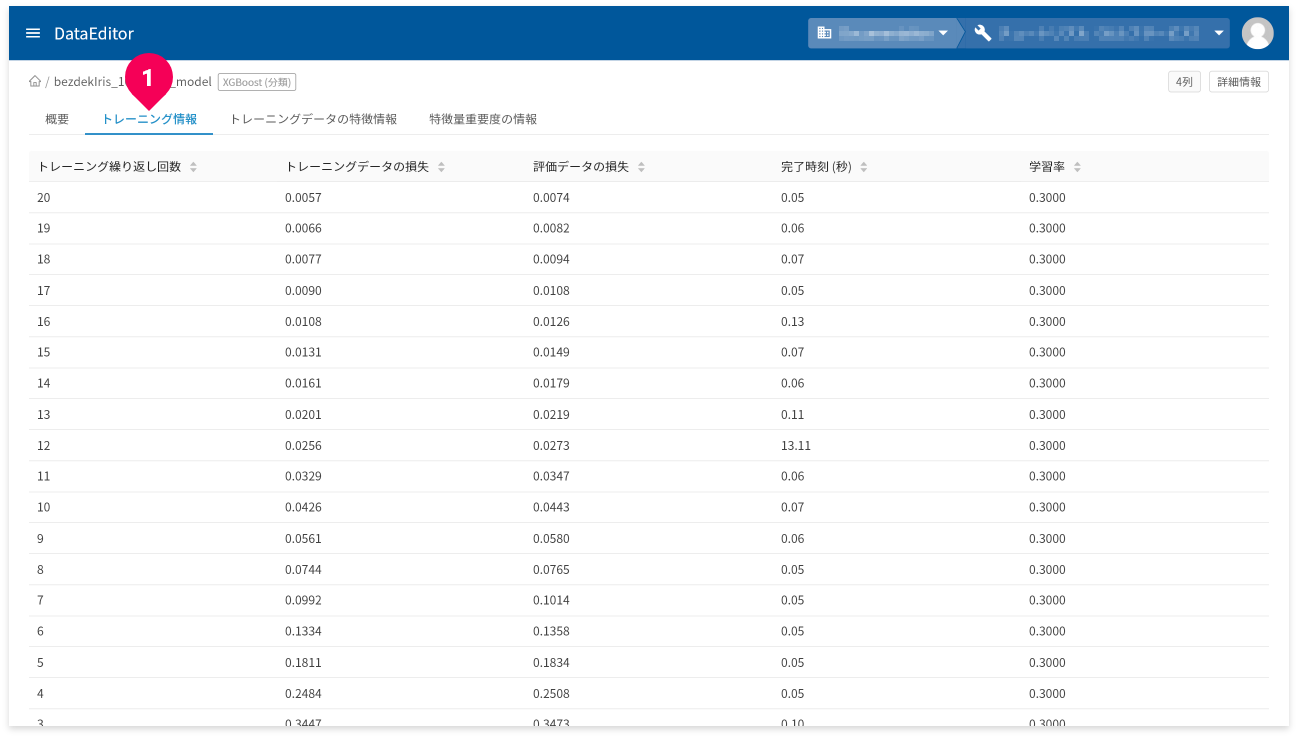
[トレーニング情報]タブ(❶)をクリックすると、トレーニング情報が確認できます。
- トレーニング繰り返し回数:トレーニングの繰返し回数
- トレーニングデータの損失:トレーニングデータの繰り返し後に計算された損失指標(平均二乗誤差)
- 評価データの損失:評価の損失指標
- 完了時刻:各トレーニングの時間
- 学習率:各トレーニングの学習率
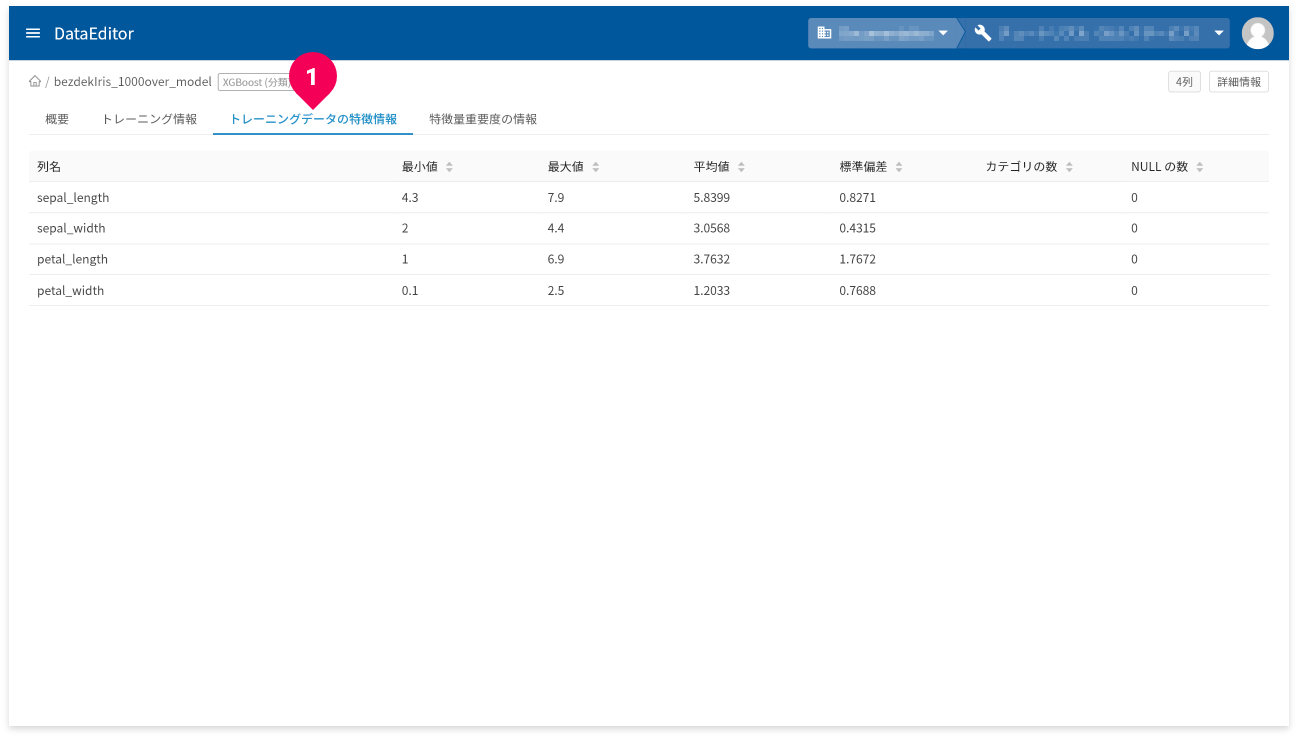
[トレーニングデータの特徴情報]タブ(❶)をクリックすると、トレーニングデータの特徴情報が確認できます。
- 列名:トレーニングデータの列名
- 最小値:トレーニングデータの最小値。数値以外の場合はNULL。
- 最大値:トレーニングデータの最大値。数値以外の場合はNULL。
- 平均値:トレーニングデータの平均値。数値以外の場合はNULL。
- 標準偏差:トレーニングデータの標準偏差。数値以外の場合はNULL。
- カテゴリの数:カテゴリの数。カテゴリ以外の列の場合はNULL。
- NULLの数:NULL値の数
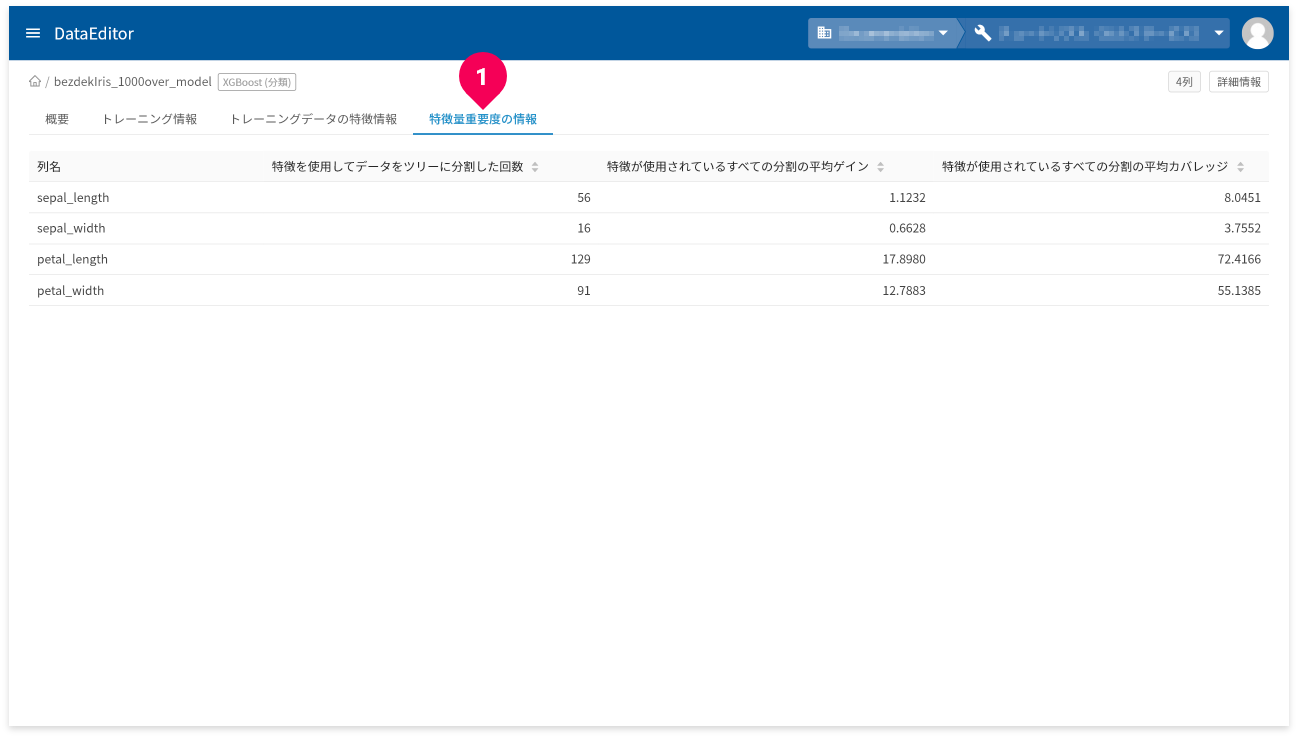
[特徴量重要度の情報]タブ(❶)をクリックすると、どの列が予測結果に与える影響が大きいのかを示す指標が確認できます。値が大きいほど、その列が予測結果に重要であることを意味します。
ここでは、以下3種類の指標が確認できます。
| 指標の種類 | 説明 |
|---|---|
| 特徴を使用してデータをツリーに分割した回数 |
ウェイト(weight)と呼ばれる指標です。 ツリーの分岐に、各列が何回用いられたかを表します。 |
| 特徴が使用されているすべての分割の平均ゲイン |
ゲイン(gain)と呼ばれる指標です。 ゲインは、各ツリーに対して、各列の寄与度を取ることで算出されます。これは、各列のモデルへの相対的な寄与度を意味します。 |
| 特徴が使用されているすべての分割の平均カバレッジ |
カバー(cover)と呼ばれる指標です。 ツリーの分岐に、到達する各列のトレーニングデータ数の平均値を表します。 |
この指標の中で、「特徴が使用されているすべての分割の平均ゲイン」が、各列の相対的な重要性を解釈する上で最も良い指標です。
予測
作成したモデルと予測用のデータを使って、簡単に予測ができます。
- ホーム画面から予測用のデータをクリック
- [
予測]タブをクリック - 予測に使用するXGBoost(分類)モデルをクリック
- [
予測]ボタンをクリック
予測が完了すると、結果が表示されます。
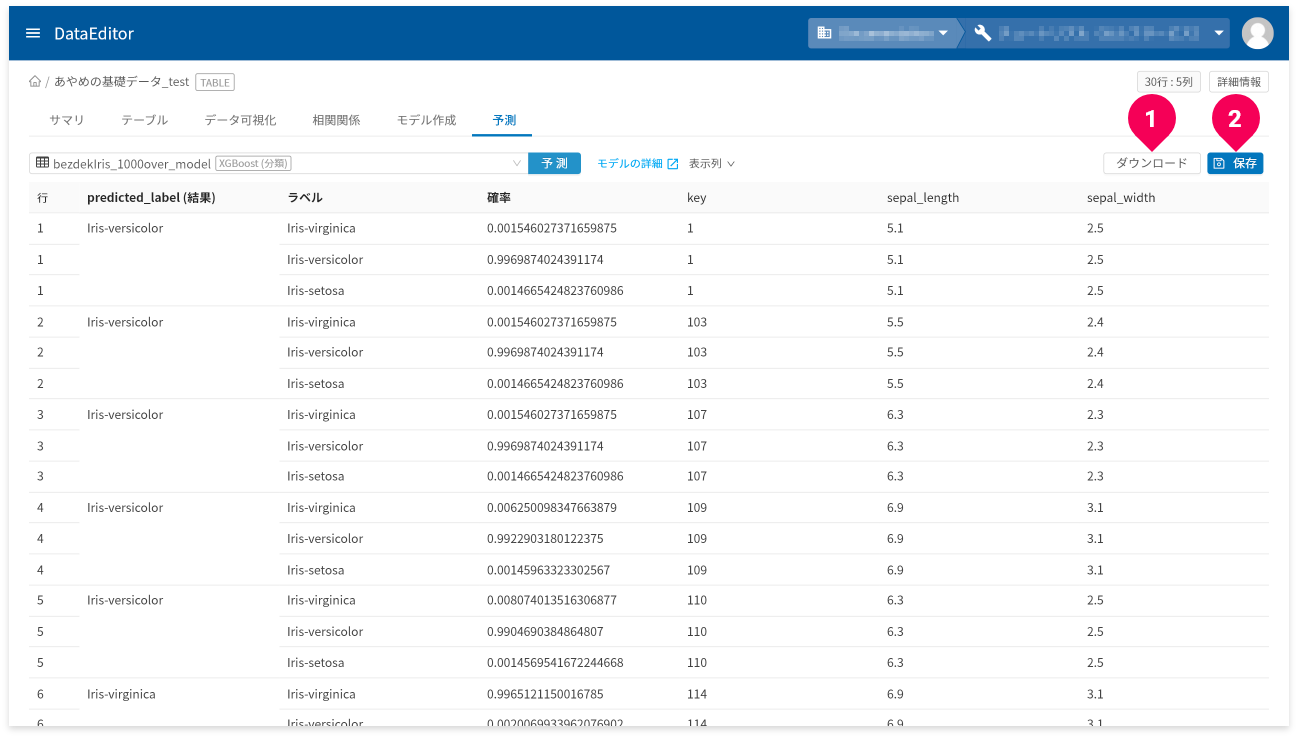
[ダウンロード]ボタン(❶)をクリックすると、予測結果の表を
CSV形式のデータでダウンロードできます。
- 予測結果の画面が複数ページにまたがる場合は、一度表示したページ数分のデータをダウンロード
予測結果が3ページ分あり、2ページまで画面上で確認し[
ダウンロード]ボタンをクリックした場合、2ページ分のデータがダウンロードされます。 - ラベル(predicted_label_probs)欄は出力から除外
[保存]ボタン(❷)をクリックすると、予測結果をDataEditorに登録できます。これにより、データ可視化の機能を使って視覚的に予測結果の評価ができます。
Deep Neural Network(分類)の例
モデル作成
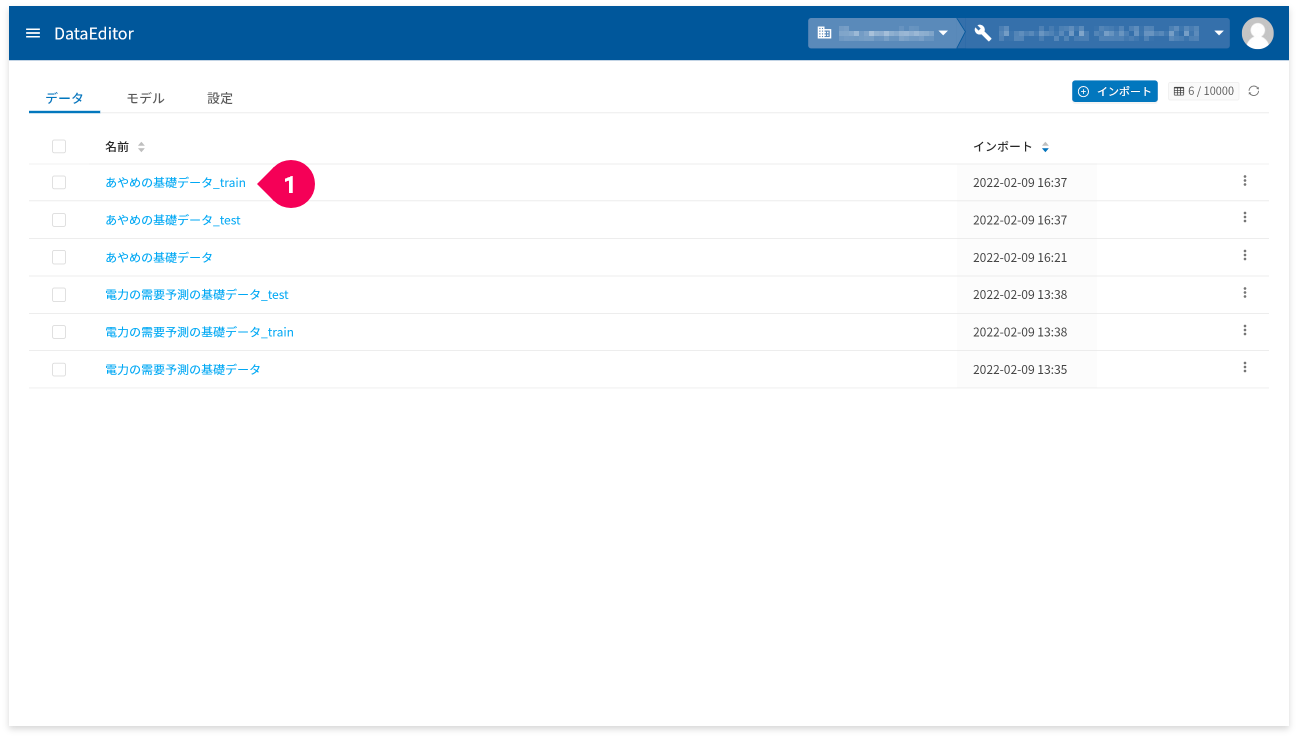
- ホーム画面からモデル作成用のトレーニングデータをクリック
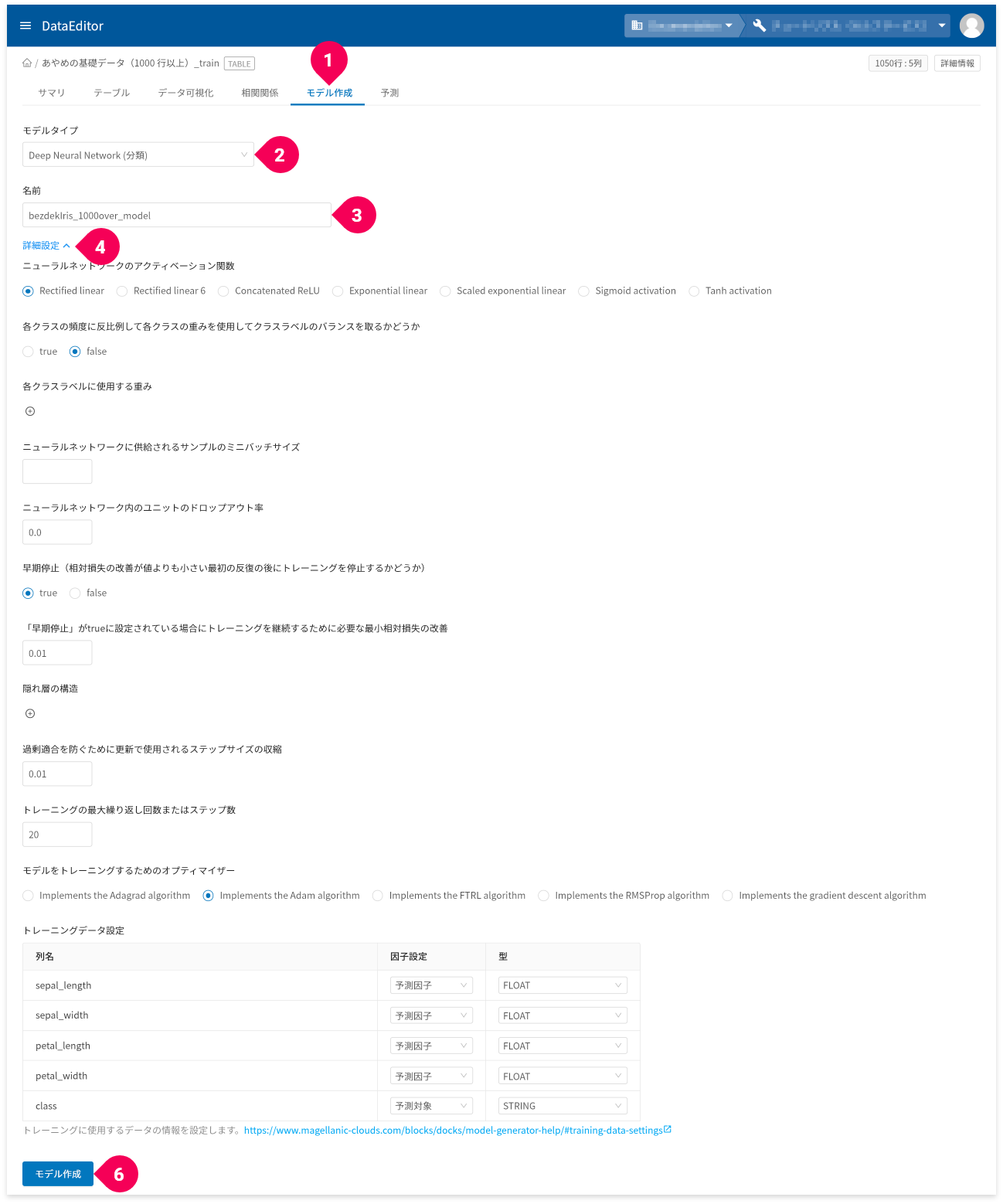
- [
モデル作成]タブをクリック - [
Deep Neural Network(分類)]をクリック - 名前を必要に応じて変更
- [
詳細設定]をクリック
各種パラメーターの設定とトレーニングデータの設定ができます。パラメーター 説明 ニューラルネットワークのアクティベーション関数 ニューラルネットワークの活性化関数(ニューロンへの入力値から出力値を求める関数)を指定します。
- Rectified linear:Rectified linear
- Rectified linear 6:Rectified linear 6
- Concatenated ReLU:Concatenated ReLU
- Exponential linear:Exponential linear
- Scaled exponential linear:Scaled exponential linear
- Sigmoid activation:Sigmoid activation
- Tanh activation:Tanh activation
各クラスの頻度に反比例して各クラスの重みを使用してクラスラベルのバランスを取るかどうか 各クラスの頻度に反比例して各クラスの重みを使用してクラスラベルのバランスを取るかどうかを指定します。
- true:クラスラベルのバランスを取る
- false:クラスラベルのバランスを取らない
各クラスラベルに使用する重み クラスラベルごとに重みを設定します。
ニューラルネットワークに供給されるサンプルのミニバッチサイズ データをいくつかのサブセットに分割するミニバッチサイズを8192以下の正の数で指定します。
慣習的には、1024や2048などの2のn乗値が使われます。
ニューラルネットワーク内のユニットのドロップアウト率 ニューラルネットワークのユニットのドロップアウト率を指定します。
指定可能な値は、0.0から1.0です。
早期停止(相対損失の改善が値よりも小さい最初の反復の後にトレーニングを停止するかどうか) トレーニングの結果に改善が見られなかったとき、学習を停止するかしないかを指定します。
- true:トレーニングを停止する(過学習防止)
- false:トレーニングを停止しない
「早期停止」がtrueに設定されている場合にトレーニングを継続するために必要な最小相対損失の改善 上記「
早期停止」パラメーターをtrueに指定したとき、トレーニングを継続するために必要な相対的な損失の最小改善量を指定します。例えば、0.01の値を指定すると、イテレーションごとに損失が1%減少すると、トレーニングが継続します。
隠れ層の構造 隠れ層の数と、隠れ層ごとのユニット数を指定します。
過剰適合を防ぐために更新で使用されるステップサイズの収縮 トレーニングごとに重み付けパラメーターを更新する率を指定します。
トレーニングの最大繰り返し回数またはステップ数 イテレーション回数の最大値を指定します。
モデルをトレーニングするためのオプティマイザー モデルをトレーニングするためのオプティマイザーを指定します。
- Implements the Adagrad algorithm:Implements the Adagrad algorithmopen_in_new
- Implements the Adam algorithm:Implements the Adam algorithm
- Implements the FTRL algorithm:Implements the FTRL algorithm
- Implements the RMSProp algorithm:Implements the RMSProp algorithm
- Implements the gradient descent algorithm:Implements the gradient descent algorithm
- [
モデル作成]ボタンをクリック
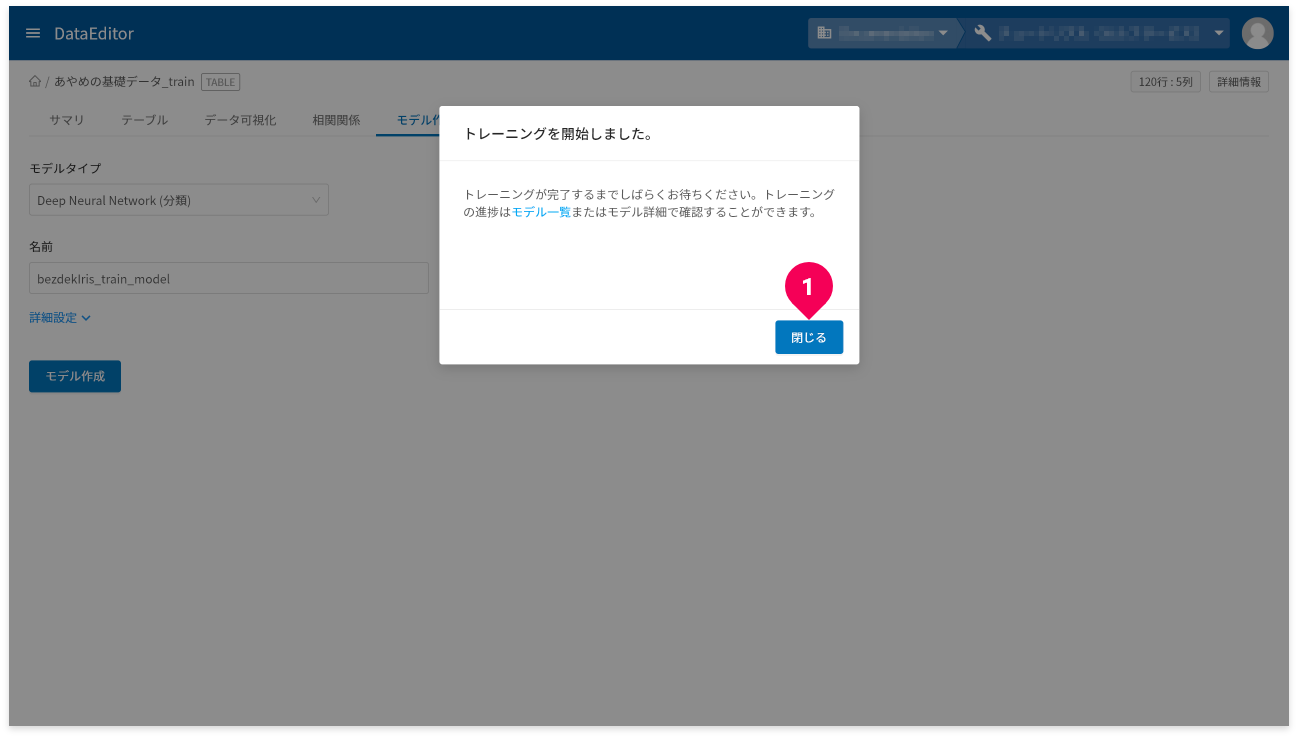
- [
閉じる]ボタンをクリック
以上で、モデルの作成は完了です。
モデル確認
モデルの作成が完了したら、そのモデルの内容を確認して評価できます。
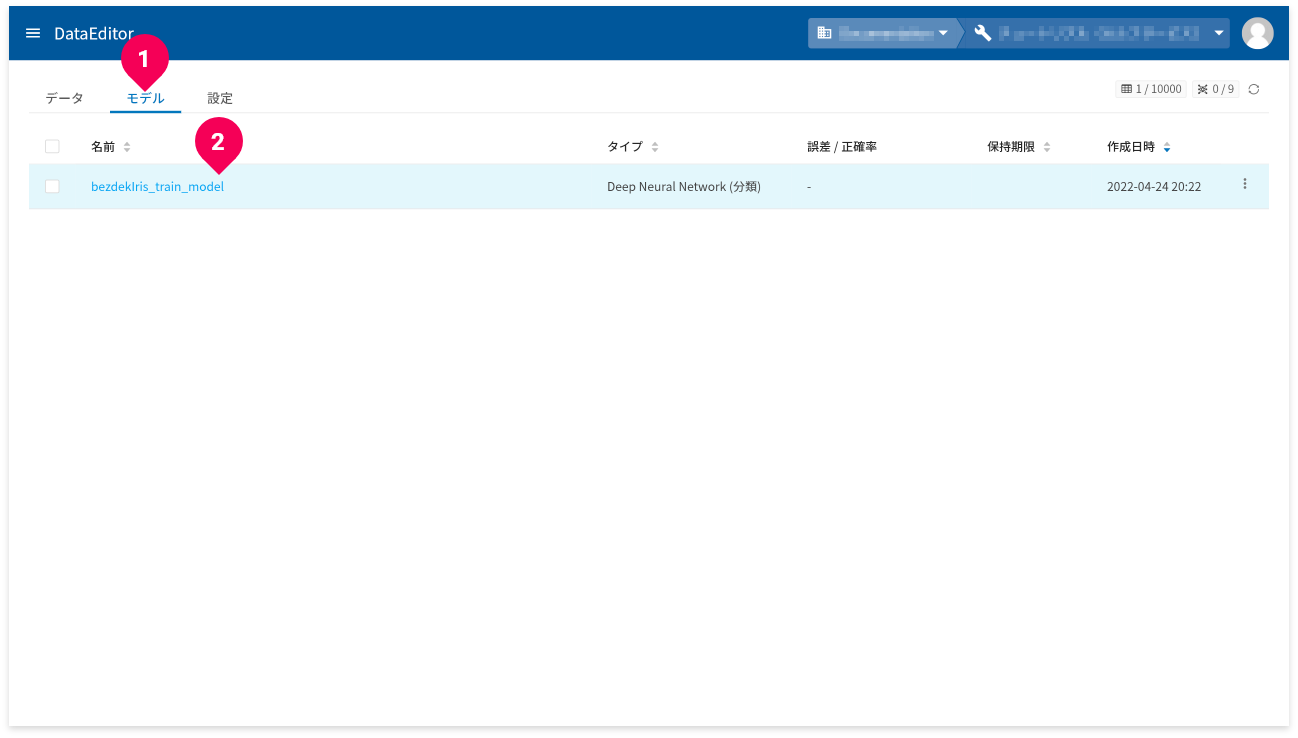
- ホーム画面から[
モデル]タブをクリック - 確認したいDeep Neural Network(分類)モデルの名前をクリック
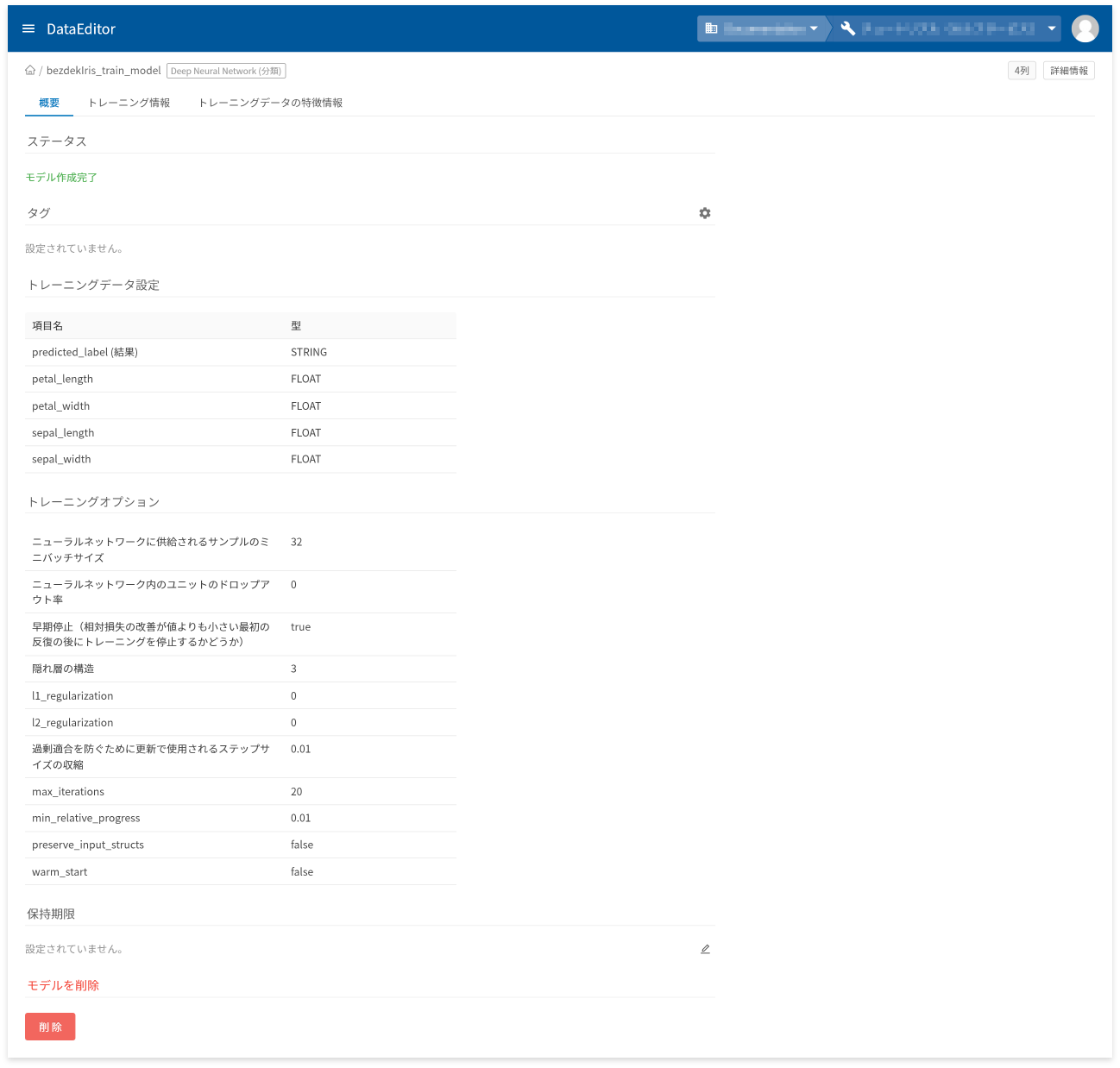
モデル詳細画面の[概要]タブでは、以下に挙げる情報の確認と操作ができます。
- モデル作成状況を表すステータスの確認
- タグの設定と確認
- トレーニングデータの項目と型の確認
- トレーニングオプションの確認
- 保存期限の設定と確認
- モデルの削除
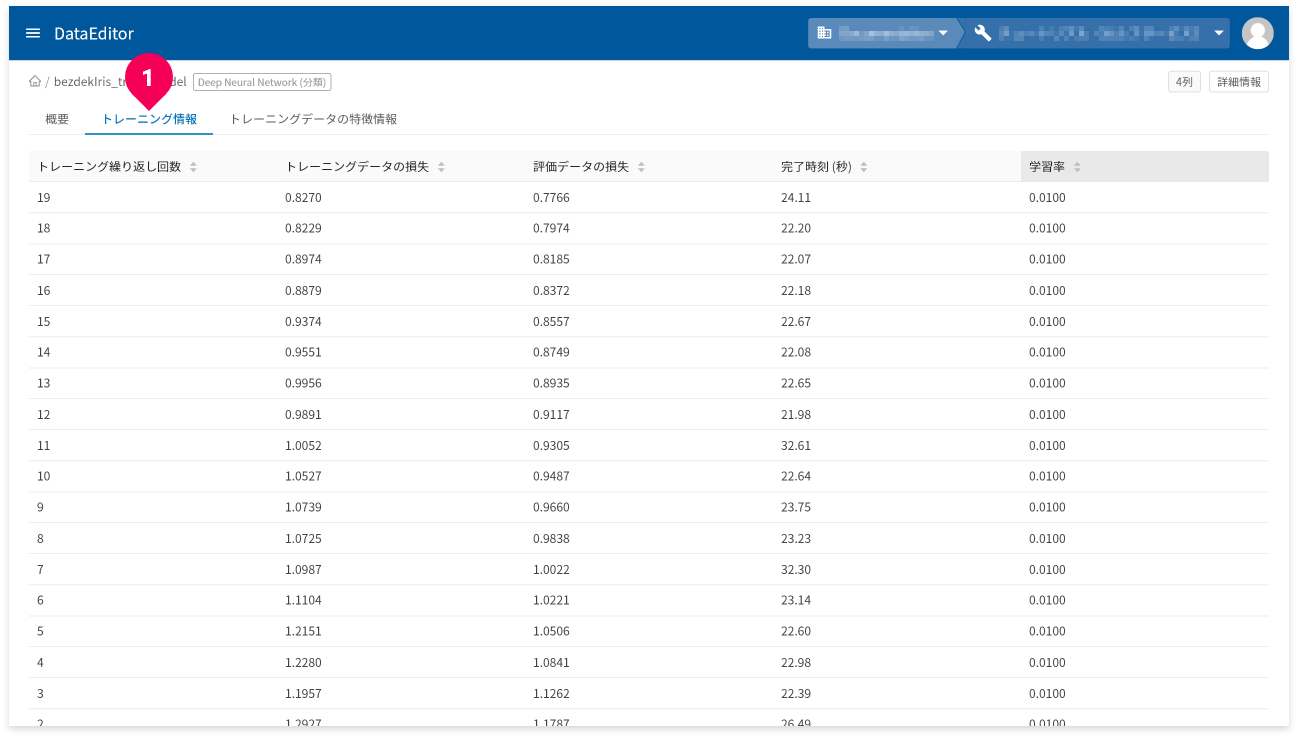
[トレーニング情報]タブ(❶)をクリックすると、トレーニング情報が確認できます。
- トレーニング繰り返し回数:トレーニングの繰返し回数
- トレーニングデータの損失:トレーニングデータの繰り返し後に計算された損失指標(平均二乗誤差)
- 評価データの損失:評価の損失指標
- 完了時刻:各トレーニングの時間
- 学習率:各トレーニングの学習率
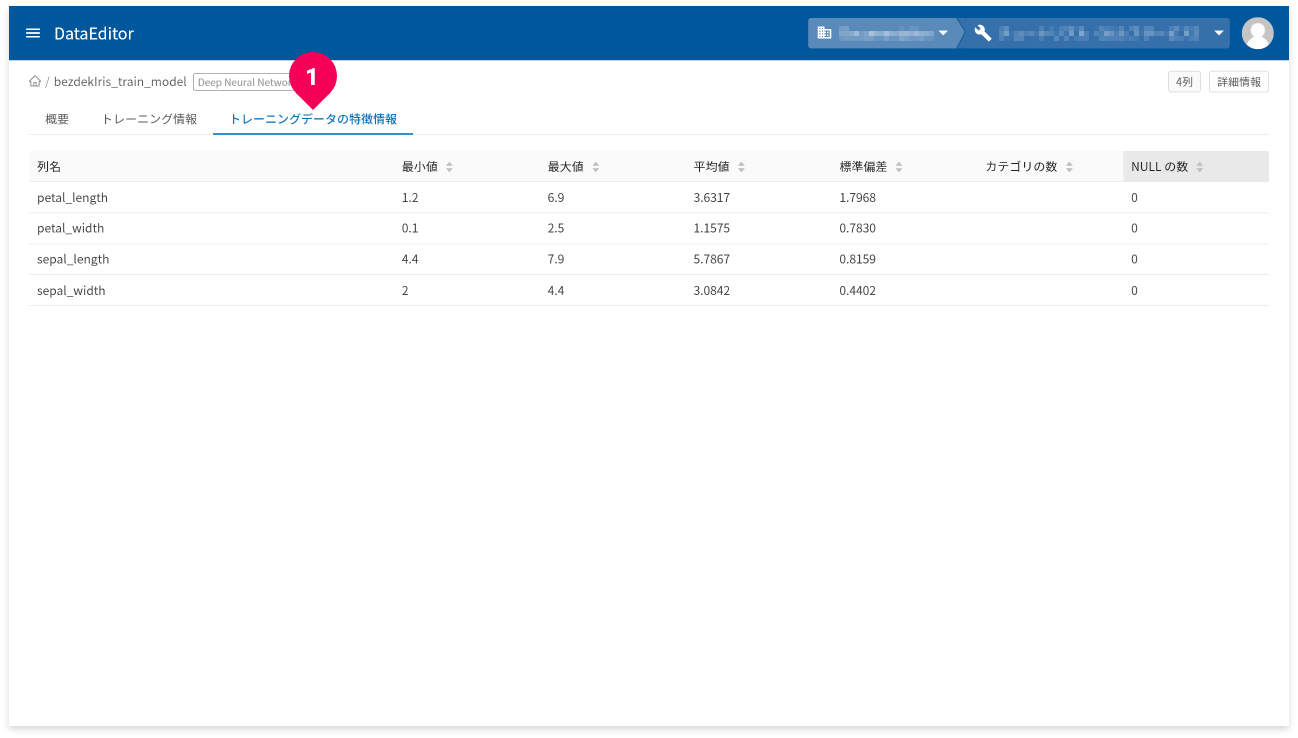
[トレーニングデータの特徴情報]タブ(❶)をクリックすると、トレーニングデータの特徴情報が確認できます。
- 列名:トレーニングデータの列名
- 最小値:トレーニングデータの最小値。数値以外の場合はNULL。
- 最大値:トレーニングデータの最大値。数値以外の場合はNULL。
- 平均値:トレーニングデータの平均値。数値以外の場合はNULL。
- 標準偏差:トレーニングデータの標準偏差。数値以外の場合はNULL。
- カテゴリの数:カテゴリの数。カテゴリ以外の列の場合はNULL。
- NULLの数:NULL値の数
予測
作成したモデルと予測用のデータを使って、簡単に予測ができます。
- ホーム画面から予測用のデータをクリック
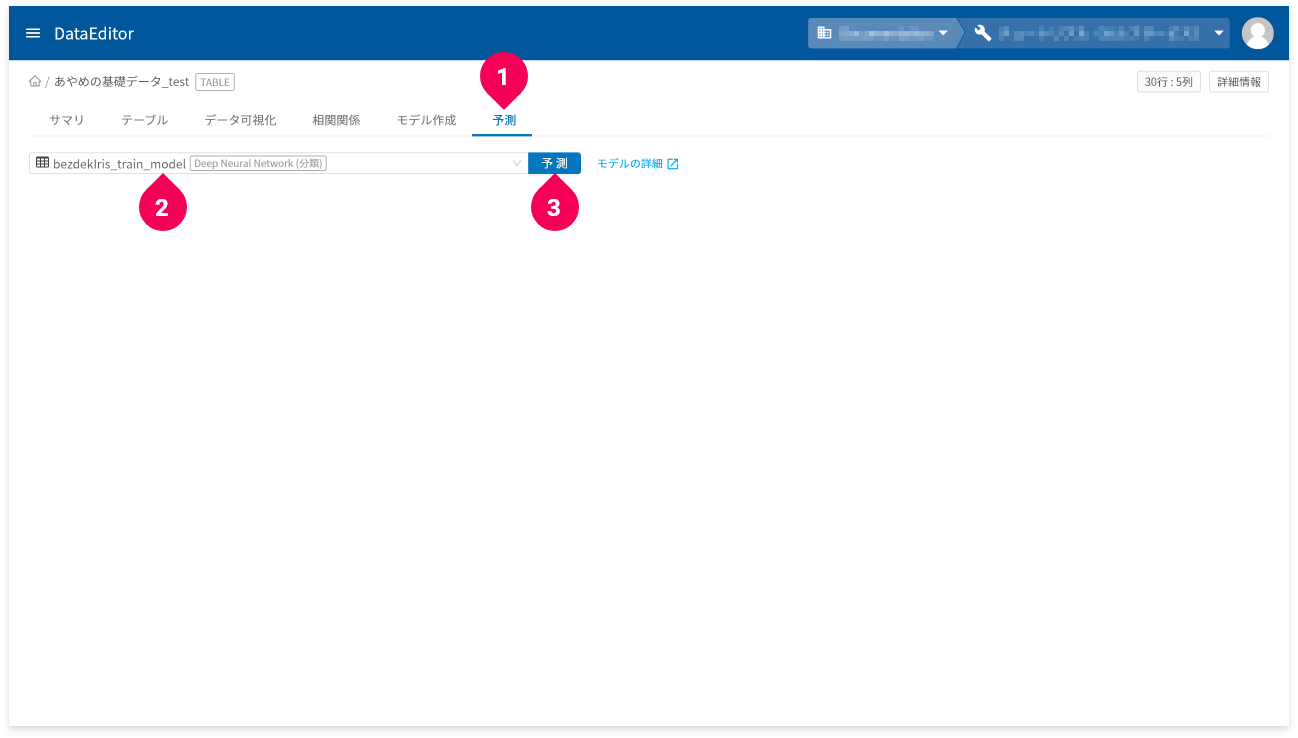
- [
予測]タブをクリック - 予測に使用するDeep Neural Network(分類)モデルをクリック
- [
予測]ボタンをクリック
予測が完了すると、結果が表示されます。
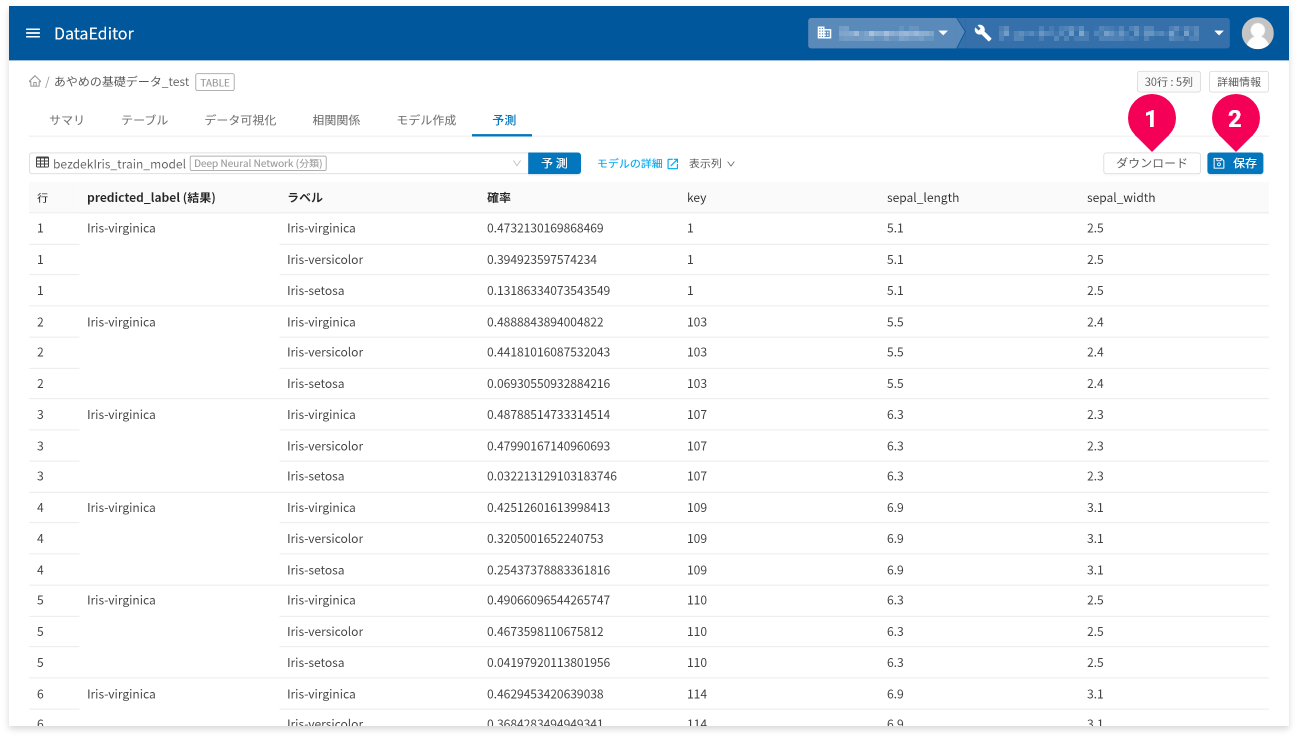
[ダウンロード]ボタン(❶)をクリックすると、予測結果の表をCSV形式のデータでダウンロードできます。
- 予測結果の画面が複数ページにまたがる場合は、一度表示したページ数分のデータをダウンロード
予測結果が3ページ分あり、2ページまで画面上で確認し[
ダウンロード]ボタンをクリックした場合、2ページ分のデータがダウンロードされます。 - ラベル(predicted_label_probs)欄は出力から除外
[保存]ボタン(❷)をクリックすると、予測結果をDataEditorに登録できます。これにより、データ可視化の機能を使って視覚的に予測結果の評価ができます。
モデルジェネレーター(分類)の例
警告
モデルジェネレーターモデルは、2024年2月1日以降、非推奨となりました。2024年2月1日のMAGELLAN BLOCKSのリリース以降、このモデルの作成はできません。作成済みのこのモデルについては、他のモデルで再作成してください。
予測
予測の手順は以下のとおりです。
- ホーム画面のデータ一覧から予測用データをクリック
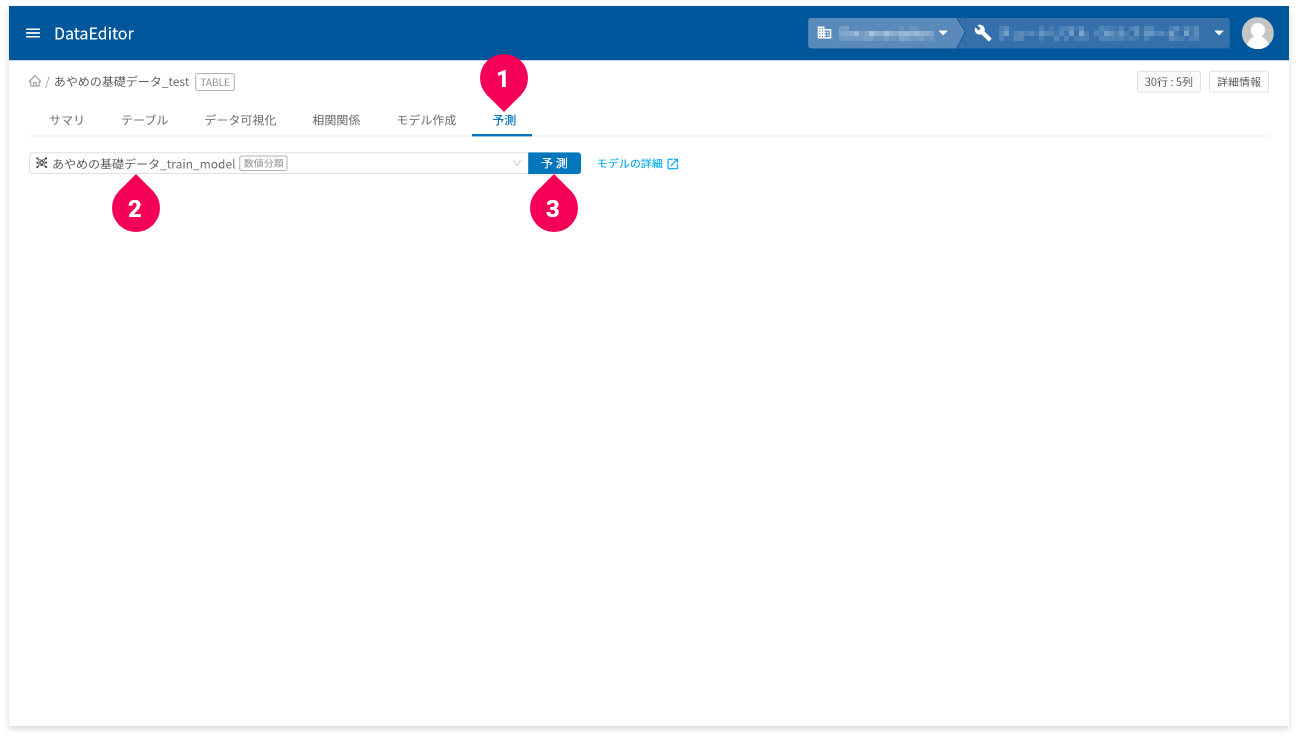
- [
予測]タブをクリック - 予測に使用するモデルジェネレーター(分類)モデルをクリック
- [
予測]ボタンをクリック
しばらくすると、予測結果が表示されます。
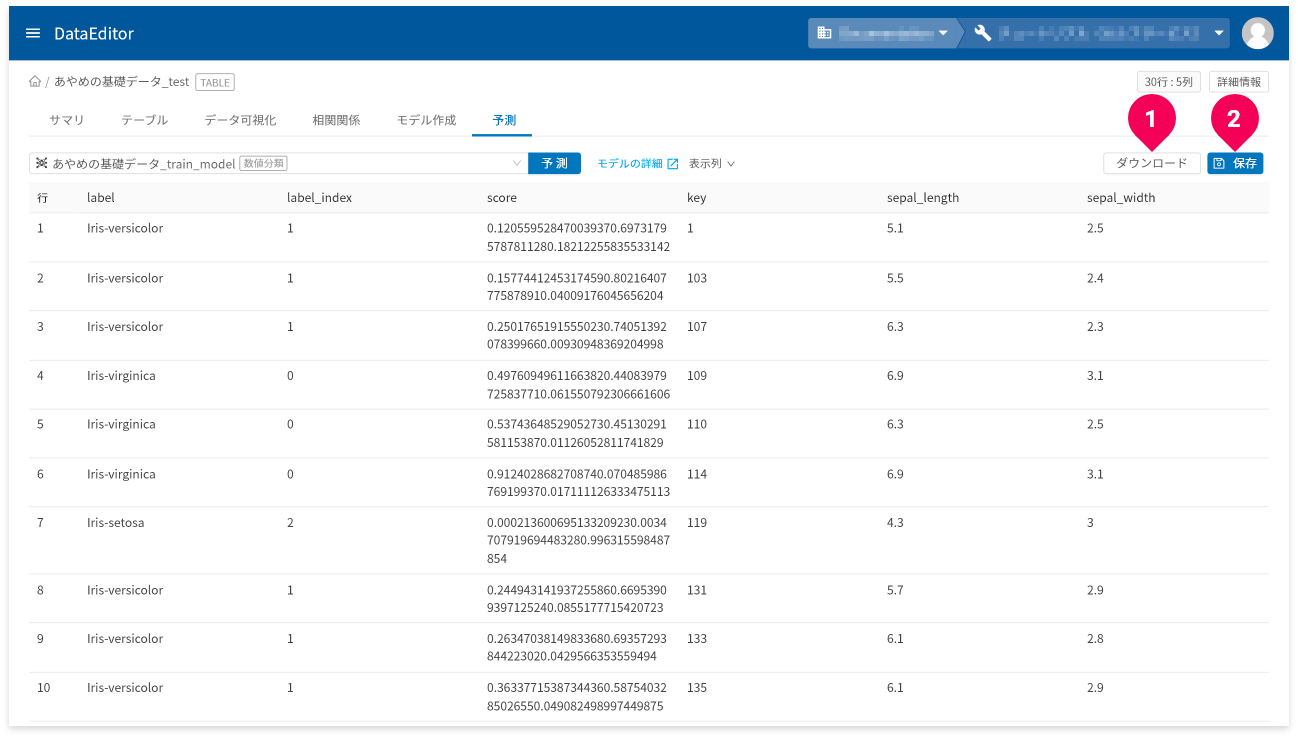
[ダウンロード]ボタン(❶)をクリックすると、予測結果を
CSV形式のデータでダウンロードできます。
- 予測結果の画面が複数ページにまたがる場合は、一度表示したページ数分のデータをダウンロード
予測結果が3ページ分あり、2ページまで画面上で確認し[
ダウンロード]ボタンをクリックした場合、2ページ分のデータがダウンロードされます。
[保存]ボタン(❷)をクリックすると、予測結果をDataEditorに登録できます。これにより、データ可視化の機能を使って視覚的に予測結果の評価ができます。
k-平均法の例
モデル作成
- ホーム画面からモデル作成用のトレーニングデータをクリック
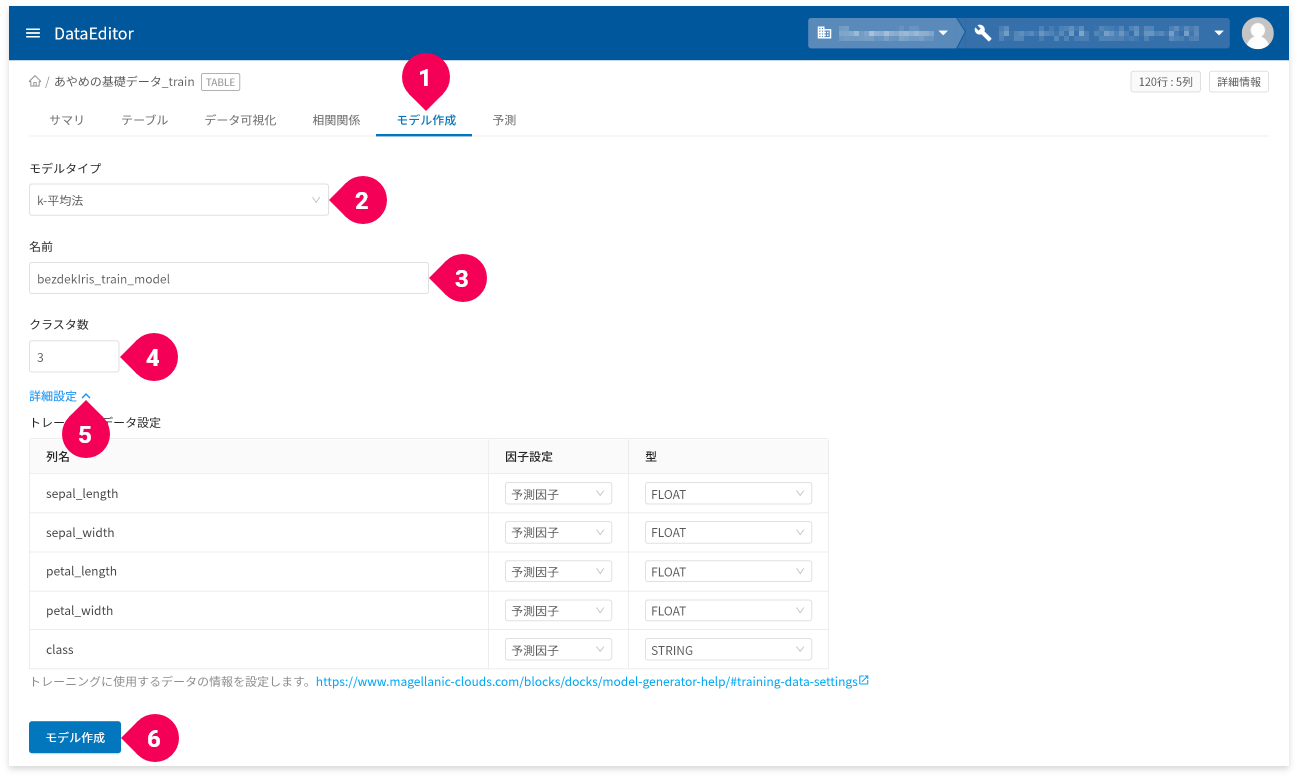
- [
モデル作成]タブをクリック - [
k-平均法]をクリック - 名前を
あやめの分析モデルに変更 - クラスタ数(分類する数)を適切に変更
- [
詳細設定]をクリック
トレーニングデータ設定が編集できます。
因子に結果となる値の列が含まれている場合は、因子設定を「使わない」に変更します。k-平均法は教師なし学習となるため、トレーニングデータ設定で与えるデータには、結果(答え)となる値の列は含めません。 - [
モデル作成]ボタンをクリック
- [
閉じる]ボタンをクリック
以上で、モデルの作成は完了です。
モデル確認
モデルの作成が完了したら、そのモデルの内容を確認して評価できます。
- ホーム画面から[
モデル]タブをクリック - 確認したいk-平均法モデルの名前をクリック
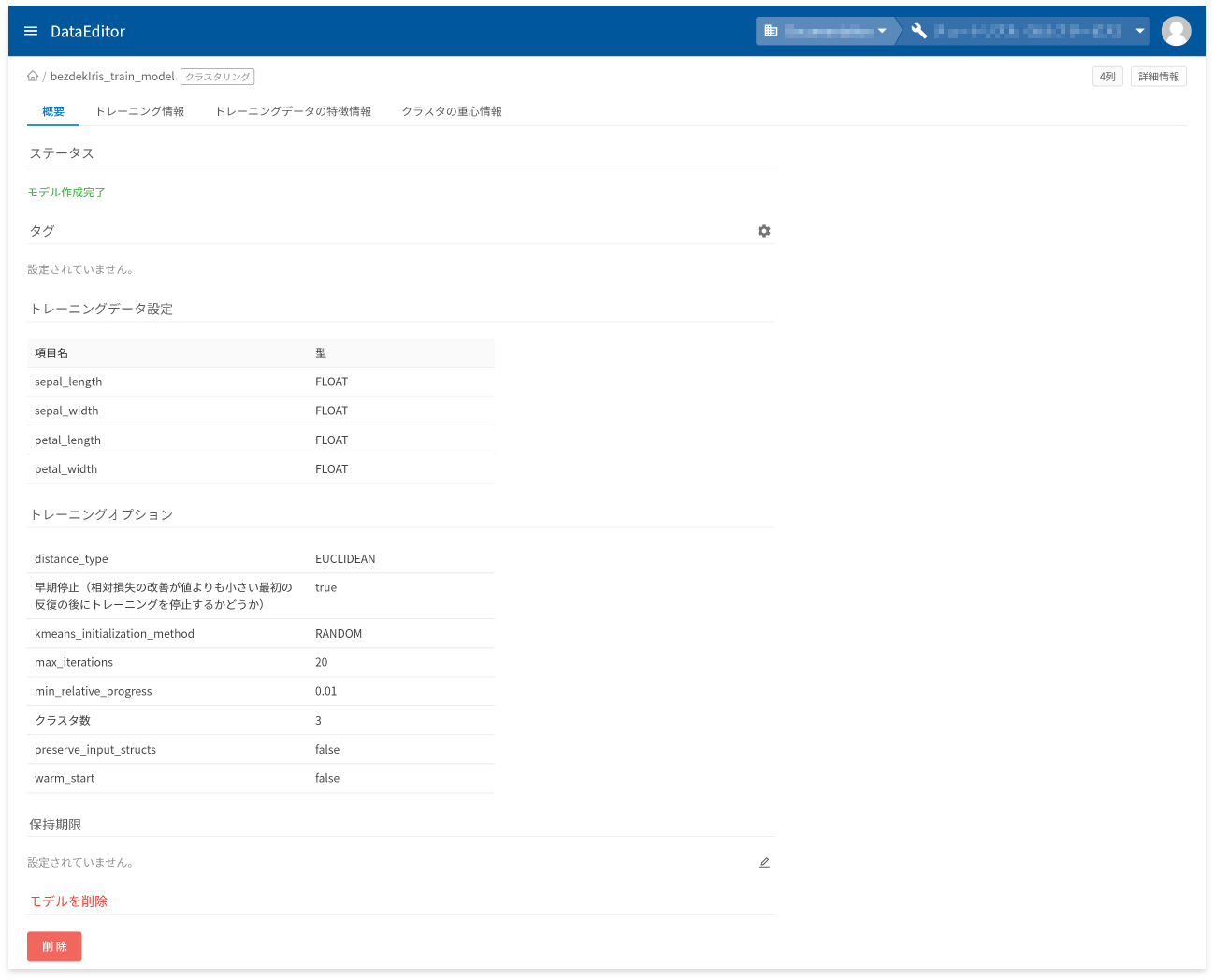
モデル詳細画面の[概要]タブでは、以下に挙げる情報の確認と操作ができます。
- モデル作成状況を表すステータスの確認
- タグの設定と確認
- トレーニングデータの項目と型の確認
- トレーニングオプションの確認
- 保存期限の設定と確認
- モデルの削除
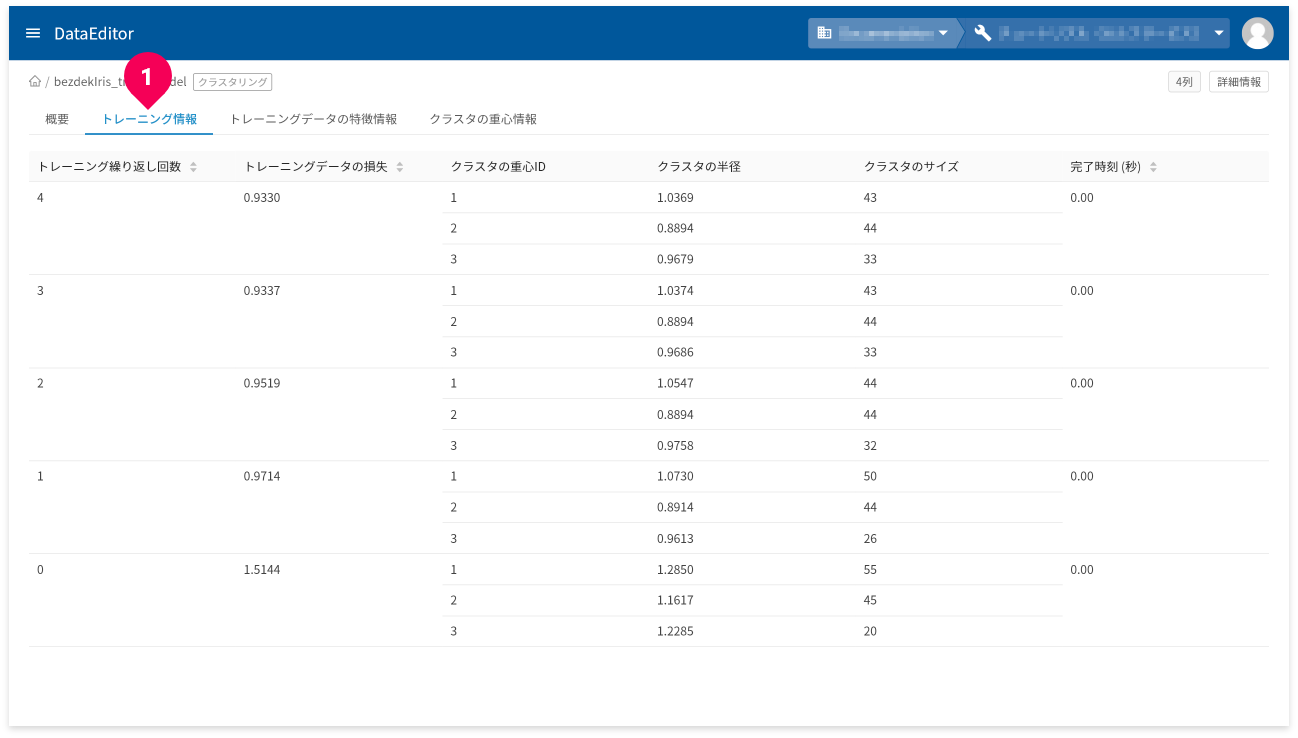
[トレーニング情報]タブ(❶)をクリックすると、トレーニング(学習)の情報が確認できます。
- トレーニング繰り返し回数:トレーニングの繰返し回数です。
- トレーニングデータの損失:トレーニングデータの繰り返し後に計算された損失指標(平均二乗誤差)です。
- クラスタの重心ID:クラスタの重心ごとのIDです。
- クラスタの半径:クラスタの半径です。
- クラスタのサイズ:クラスタのサイズです。
- 完了時刻(秒):各トレーニングの時間です。
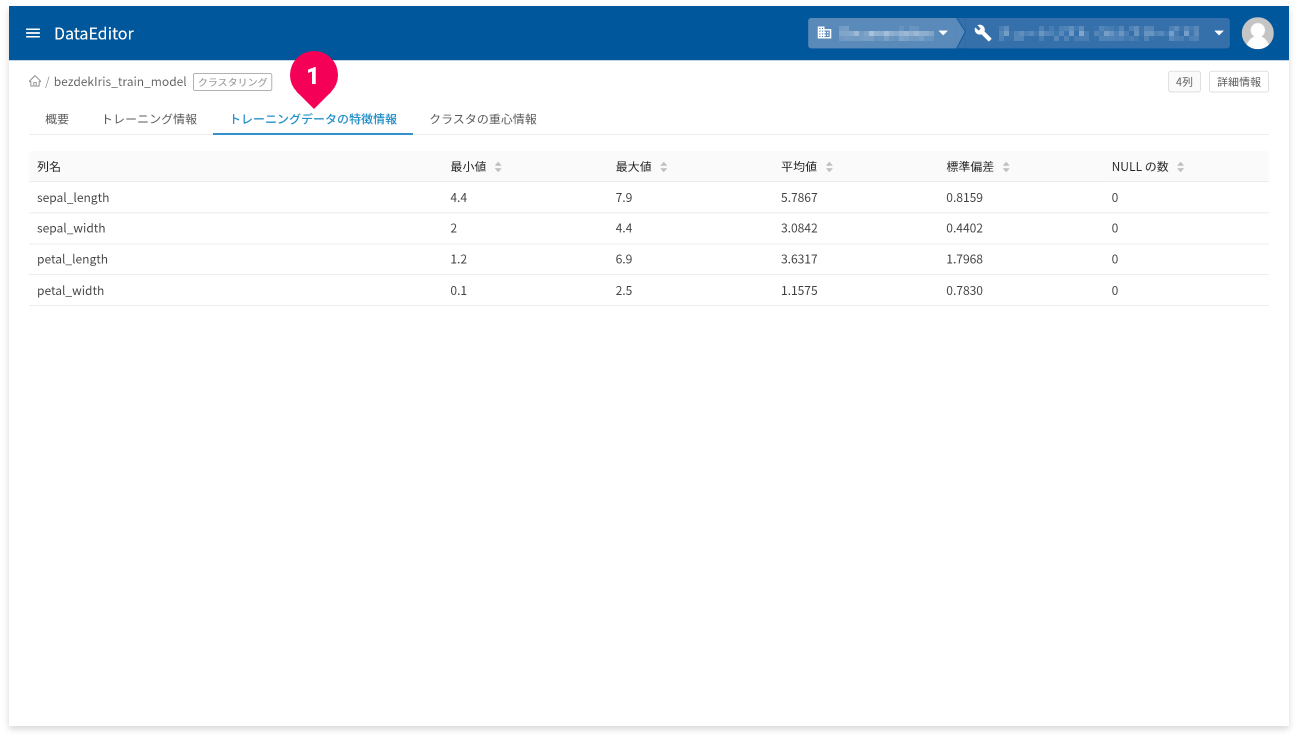
[トレーニングデータの特徴情報]タブ(❶)をクリックすると、トレーニングデータの特徴情報が確認できます。
- 列名:トレーニングデータの列名です。
- 最小値:トレーニングデータの最小値です。数値以外の場合は、NULLになります。
- 最大値:トレーニングデータの最大値です。数値以外の場合は、NULLになります。
- 平均値:トレーニングデータの平均値です。数値以外の場合は、NULLになります。
- 標準偏差:トレーニングデータの標準偏差です。数値以外の場合は、NULLになります。
- カテゴリの数:カテゴリの数です。カテゴリ以外の列の場合、NULLになります。
- NULLの数:NULLの数です。
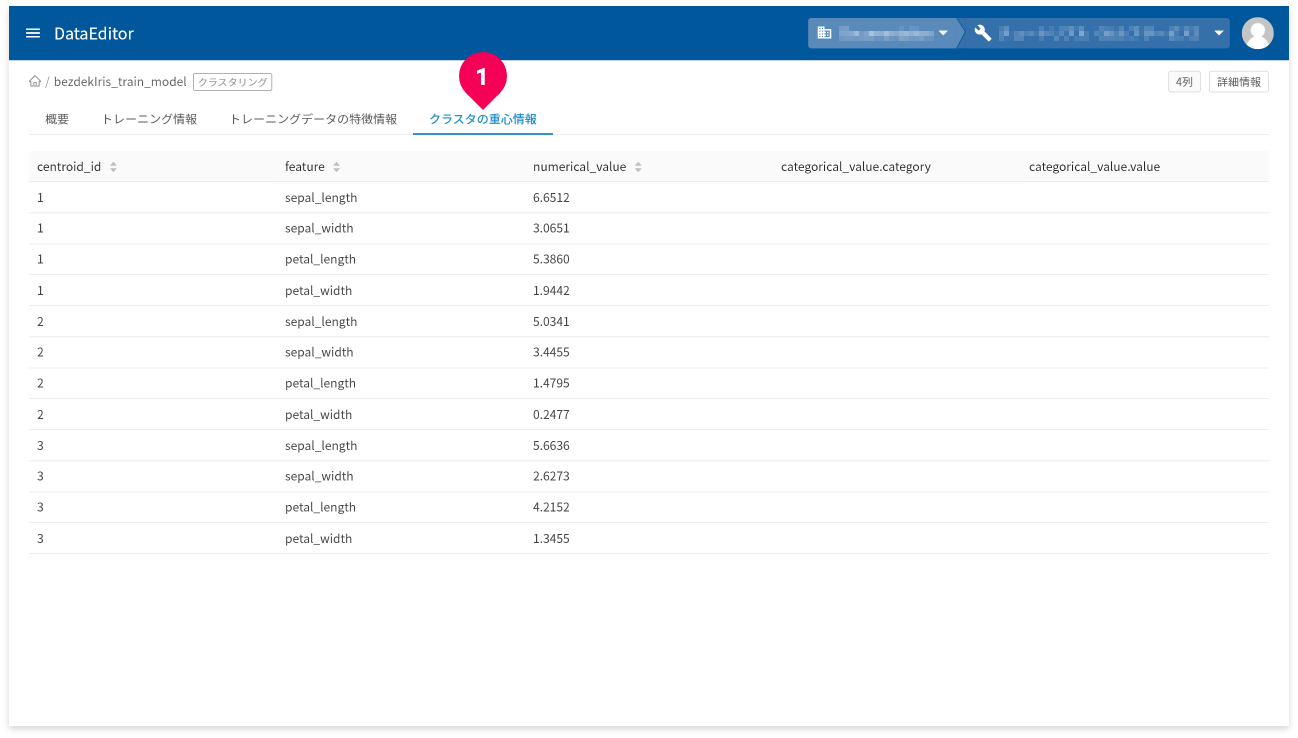
[クラスタの重心情報]タブ(❶)をクリックすると、トレーニングデータのクラスタの重心情報が確認できます。
- centroid_id:クラスタの重心ごとにつけられたIDです。
- feature:列の名前です。
- numerical_value:
featureが数値の場合は、featureが表す列の重心値です。featureが数値以外の場合は、NULLです。 - categorical_value.category:文字列型の列の場合、重心となる文字列です。数値型の列の場合は空欄です。
- categorical_value.value:
categorical_value.categoryの重心としての確からしさです。値は0から1の範囲です。
モデルを評価した結果が悪ければ、トレーニングデータの因子(列)を見直して、モデルを作り直し再度評価します。このサイクルを良い結果が得られるまで繰り返します。
予測
作成したモデルと予測用のデータを使って、簡単に予測ができます。
- ホーム画面のデータ一覧から予測用のデータをクリック
- [
予測]タブをクリック - 予測に使用するロジスティック回帰(分類)モデルをクリック
- [
予測]ボタンをクリック
予測が完了すると、結果が表示されます。
[ダウンロード]ボタン(❶)をクリックすると、予測結果の表を
CSV形式のデータでダウンロードできます。
- 予測結果の画面が複数ページにまたがる場合は、一度表示したページ数分のデータをダウンロード
予測結果が3ページ分あり、2ページまで画面上で確認し[
ダウンロード]ボタンをクリックした場合、2ページ分のデータがダウンロードされます。 - NEAREST_CENTROIDS_DISTANCE欄は出力から除外
[保存]ボタン(❷)をクリックすると、予測結果をDataEditorに登録できます。これにより、データ可視化の機能を使って視覚的に予測結果の評価ができます。
ARIMA+(時系列)【限定公開】の例
重要
このモデルは限定公開です。利用にあたっては、ライセンス購入申請が必要です。このモデルを利用したい場合は、MAGELLAN BLOCKSのお問い合わせ機能からライセンス購入申請をお願いします。
モデル作成
ARIMA+(時系列)モデルの作成手順は、以下のとおりです。
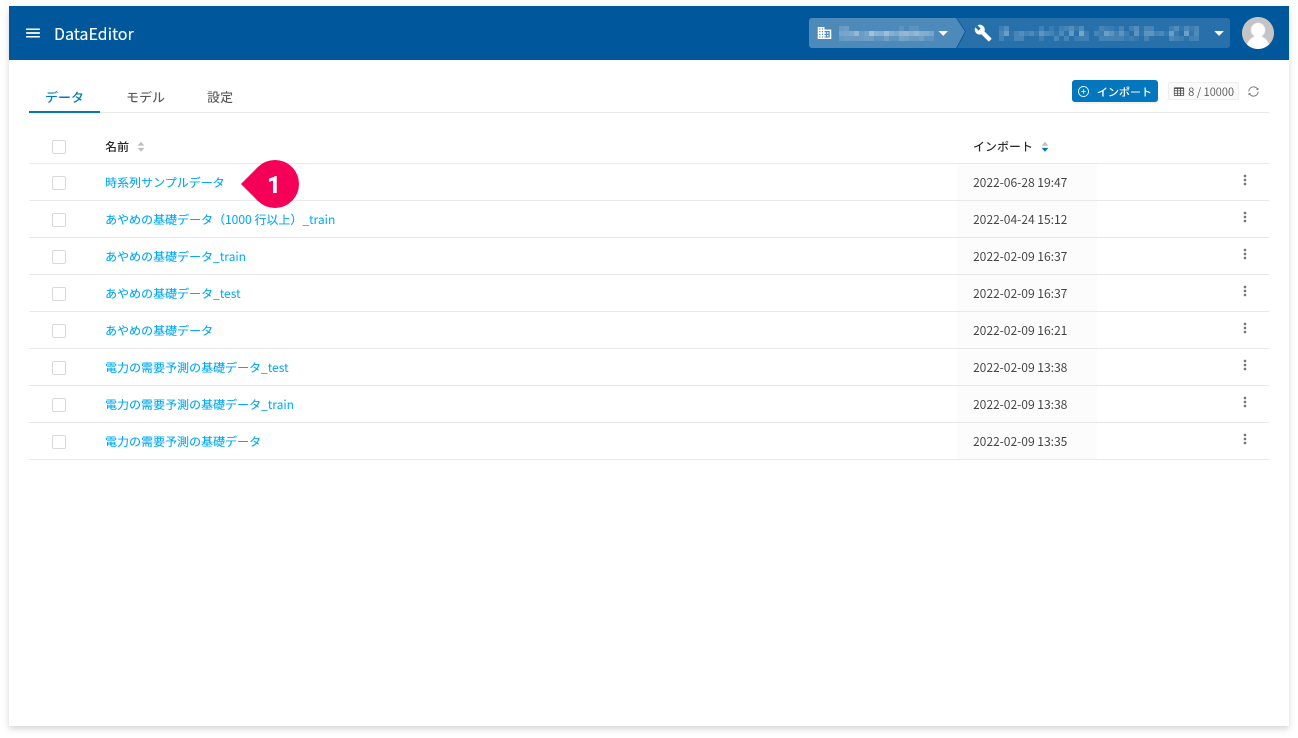
- ホーム画面からモデル作成用のトレーニングデータをクリック
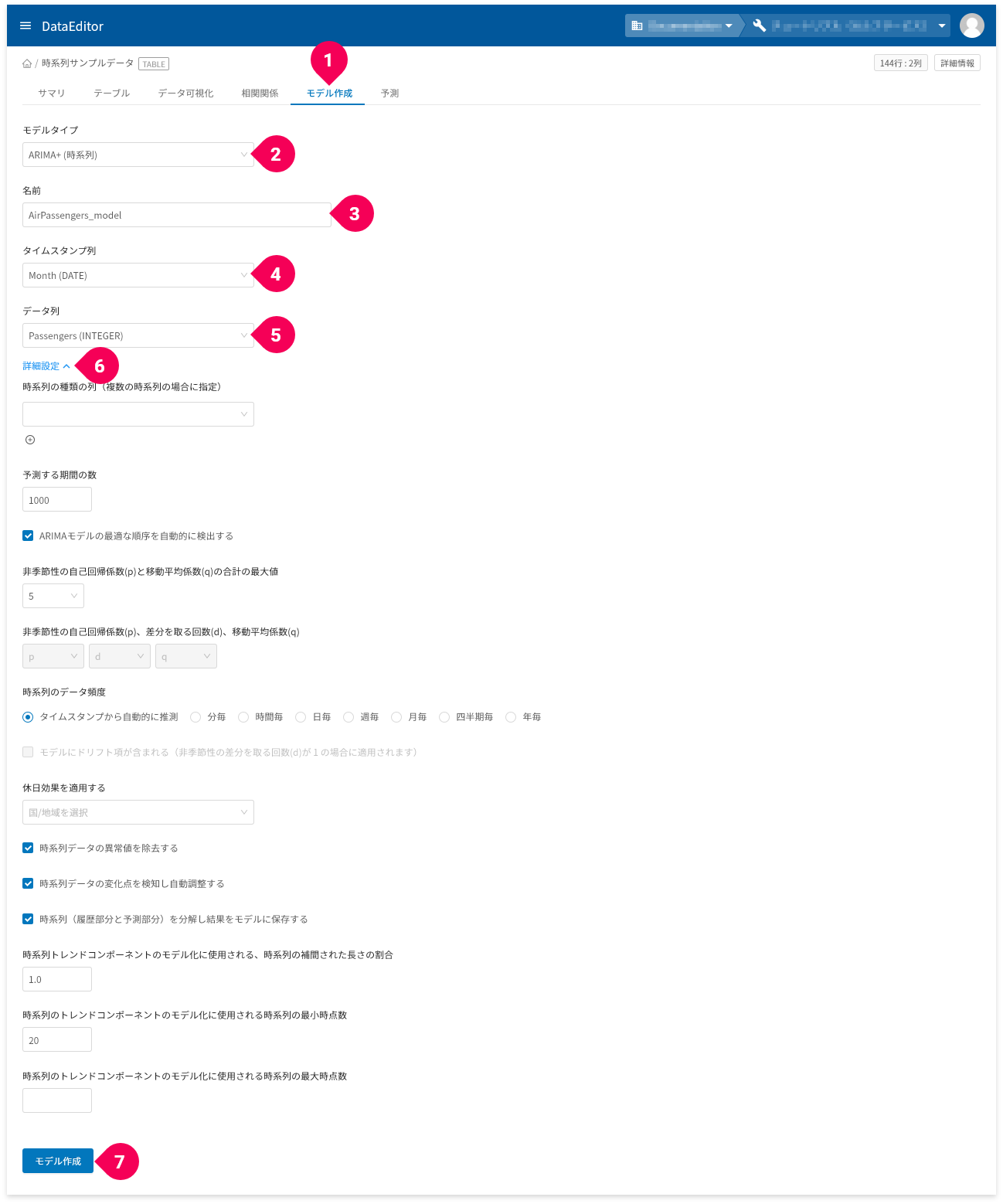
- 「
モデル作成」タブをクリック - 「ARIMA+(時系列)」をクリック
- 必要に応じて名前を変更
- トレーニングデータのタイムスタンプ列のカラムを選択
- トレーニングデータのデータ列(予測したいデータ)のカラムを選択
- 「
詳細設定」をクリック
ARIMA+の各種パラメーターの調整ができます。初期値で問題なければ、調整不要です。パラメーター 説明 時系列の種類の列(複数の時系列の場合に指定) 複数の時系列カラムがある場合は、その数分のカラムが指定できます。
予測する期間の数 予測したい期間の長さを指定します。単位は、タイムスタンプ列のデータ頻度の扱いによります。タイムスタンプ列のデータが、月ごとの扱いであれば月単位、日ごとの扱いであれば日単位となります。
ARIMAモデルの最適な順序を自動的に検出する AIC(Akaike Information Criterion:赤池情報量規準)が最も低い最適なモデルを自動的に検出するかどうかを指定します。
非季節性の自己回帰係数(p)と移動平均係数(q)の合計の最大値 自己回帰係数(p)と移動平均係数(q)の合計の最大値を指定します。指定できる値は、1から5の整数です。
「
ARIMAモデルの最適な順序を自動的に検出する」がオフの場合は、指定できません。非季節性の自己回帰係数(p)、差分を取る回数(d)、移動平均係数(q) ARIMAモデルの最適な順序を自動的に検出しない場合は、自己回帰係数(p)、差分を取る回数(d)、移動平均係数(q)を手動で設定します。
「
ARIMAモデルの最適な順序を自動的に検出する」がオンの場合は、指定できません。時系列のデータ頻度 トレーニングデータのタイムスタンプ列のデータ頻度を指定します。
- タイムスタンプから自動的に推測
- 分毎
- 時間毎
- 日毎
- 週毎
- 月毎
- 四半期毎
- 年毎
モデルにドリフト項が含まれる(非季節性の差分を取る回数(d)が1の場合に適用されます) ドリフト項を含めるかどうかを指定します。
「
ARIMAモデルの最適な順序を自動的に検出する」がオンの場合は、自動的に決定されます。休日効果を適用する 休日効果を適用したい場合は、適用したい国や地域を選択します。
休日効果を有効にすると、休日中に見られる異常な増大と減少が異常として処理されなくなります。
時系列データの異常値を除去する 時系列データの異常値を除去するかどうかを指定します。
時系列データの変化点を検知し自動調整する 時系列データの変化点を検知し自動調整するかどうかを指定します。
時系列(履歴部分と予測部分)を分解し結果をモデルに保存する 時系列(履歴部分と予測部分)を分解し結果をモデルに保存するかどうかを指定します。
時系列トレンドコンポーネントのモデル化に使用される、時系列の補間された長さの割合 時系列トレンドコンポーネント(成分)をモデル化するために使用される時系列の補間された長さの割合を指定します。時系列のすべての時点は、非トレンド成分をモデル化するために使用されます。たとえば、時系列に100個の時点がある場合、0.5を指定すると、モデリングに最新の50個の時点が使用されます。このパラメーターを使用すると、予測精度を犠牲にすることなくトレーニングが高速化できます。
値は0から1の範囲内でなければなりません。初期値(1.0)では、時系列内のすべての時点が使用されます。
注意
このパラメーターは、「時系列のトレンドコンポーネントのモデル化に使用される時系列の最小時点数」と併用できますが、「時系列のトレンドコンポーネントのモデル化に使用される時系列の最大時点数」とは併用できません。時系列のトレンドコンポーネントのモデル化に使用される時系列の最小時点数 時系列のトレンドコンポーネント(成分)をモデル化する際に使用される時系列の最小の時点数を指定します。
値は、4以上の数値を指定してください。
このパラメーターは、「
時系列トレンドコンポーネントのモデル化に使用される、時系列の補間された長さの割合」と併用して使用します。時系列のトレンドコンポーネントのモデル化に使用される時系列の最大時点数 時系列のトレンドコンポーネント(成分)のモデル化に使用される時系列の最大時点数を指定します。
値は、4以上の数値を指定してください。最初に試す数値としては、30をおすすめします。
注意
このパラメーターは、「時系列トレンドコンポーネントのモデル化に使用される、時系列の補間された長さの割合」または「時系列のトレンドコンポーネントのモデル化に使用される時系列の最小時点数」と併用できません。 - [
モデル作成]ボタンをクリック
- [
閉じる]ボタンをクリック
以上で、モデル作成操作は完了です。
トレーニングが完了するまで、しばらく時間がかかります。トレーニングの進捗は、モデル一覧で確認できます。
モデル確認
モデルの作成が完了したら、そのモデルの内容を確認して評価できます。
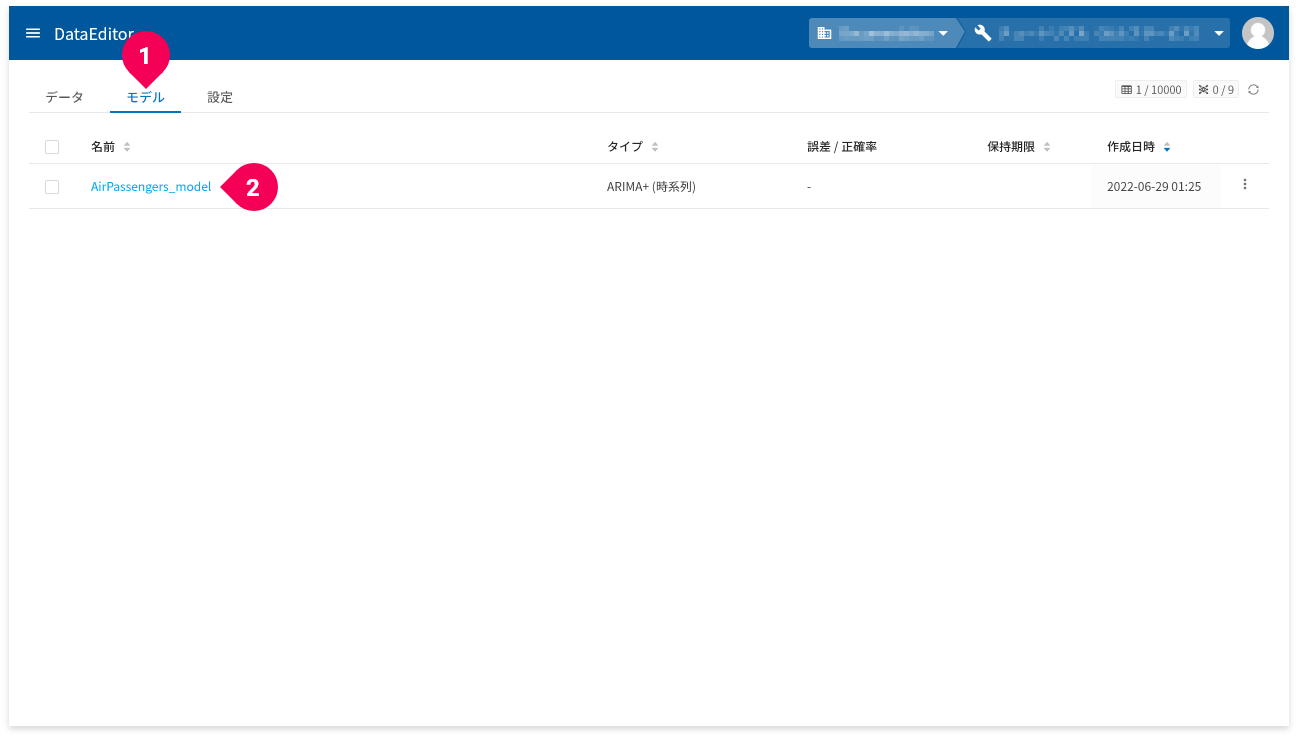
- ホーム画面から[
モデル]タブをクリック - 確認したいARIMA+(時系列)モデルの名前をクリック
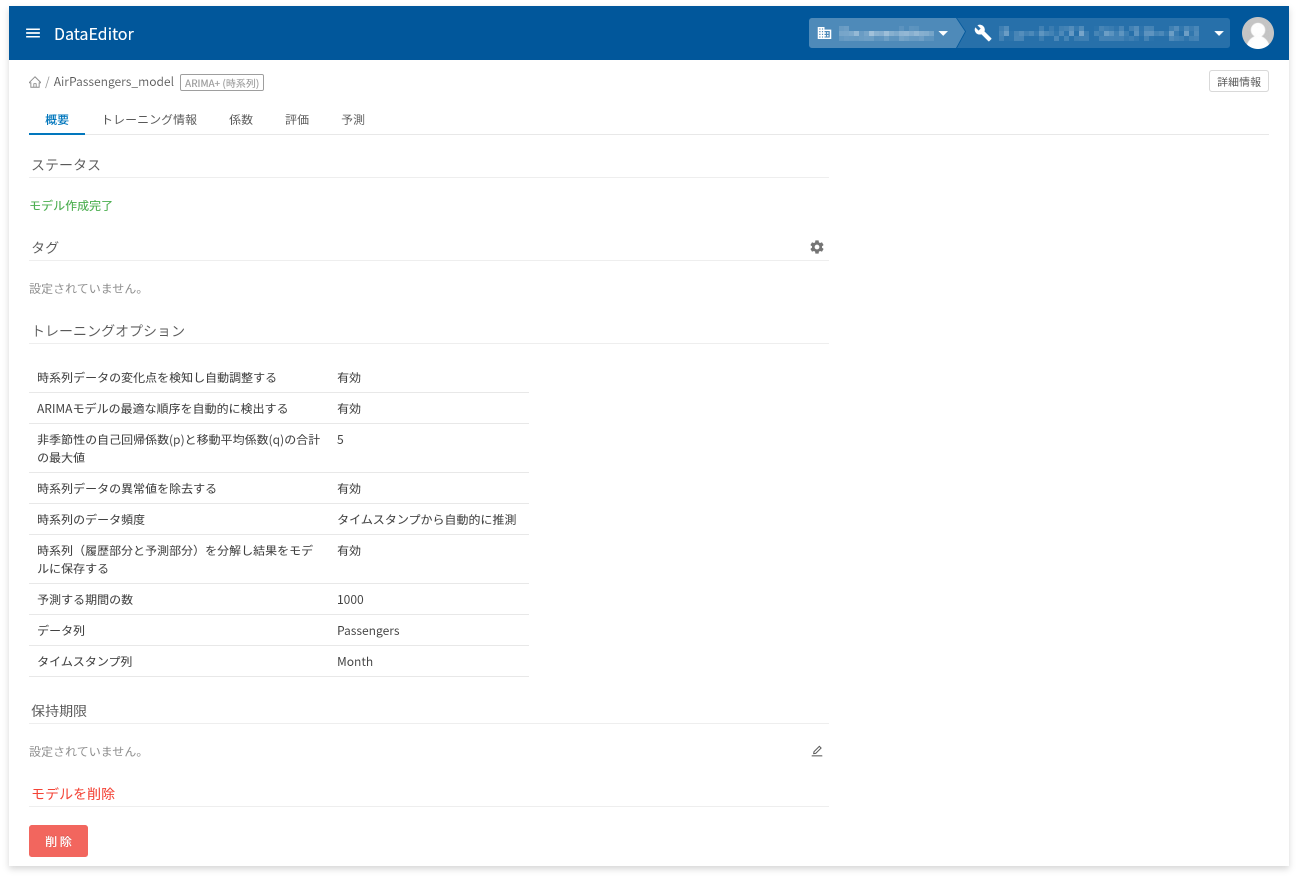
モデル詳細画面の「概要」タブでは、以下に挙げる情報の確認と操作ができます。
- モデル作成状況を表すステータスの確認
- タグの設定と確認
- トレーニングオプションの確認
- 保存期限の設定と確認
- モデルの削除
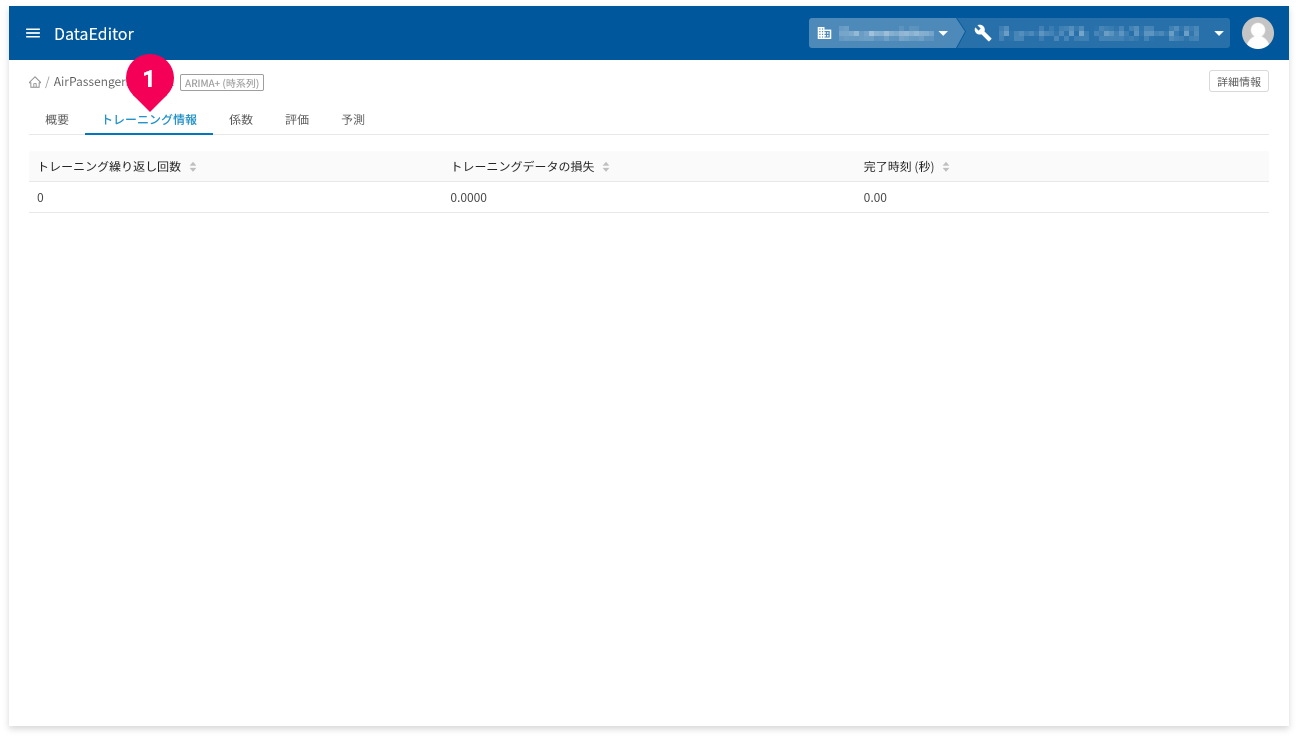
「トレーニング情報」タブ(❶)をクリックすると、トレーニング情報が確認できます。
- トレーニング繰り返し回数:トレーニングの繰返し回数
- トレーニングデータの損失:トレーニングデータの繰り返し後に計算された損失指標(平均二乗誤差)
- 完了時刻:各トレーニングの時間
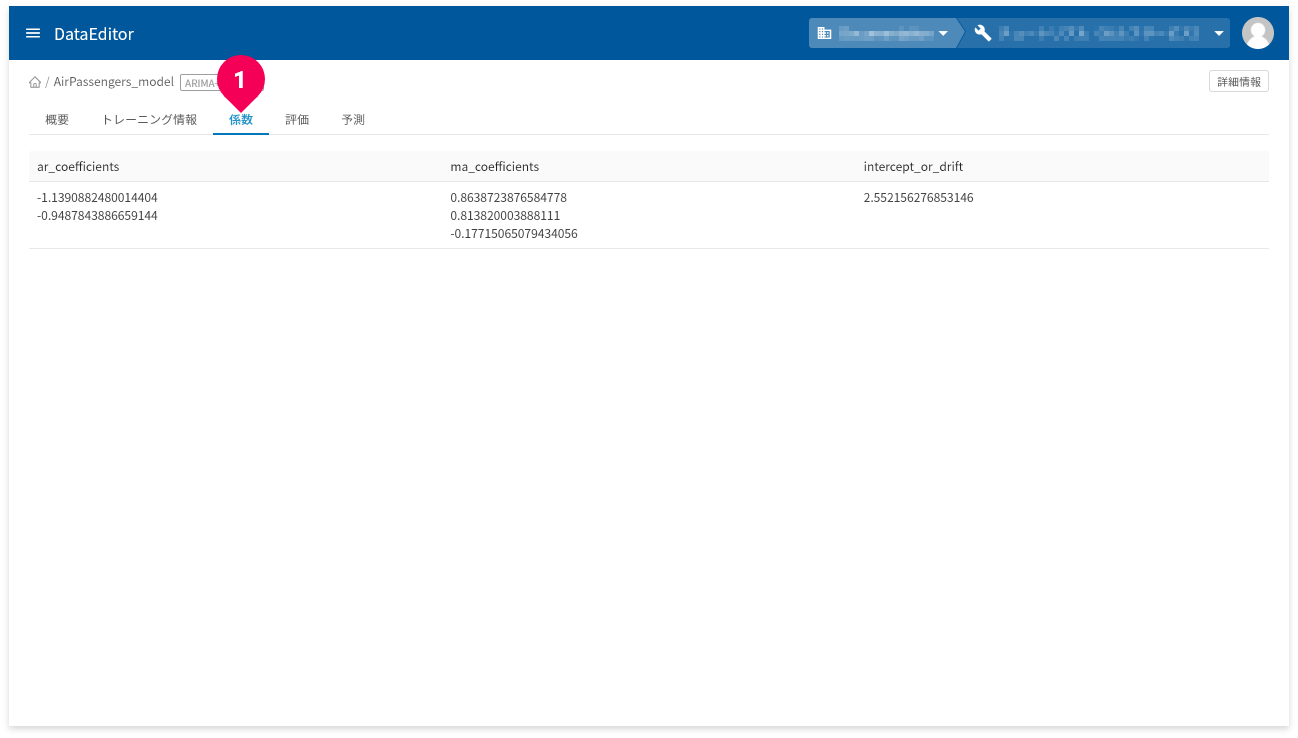
「係数」タブ(❶)をクリックすると、ARIMA+(時系列)モデルの係数が確認できます。
- ar_coefficients:自己回帰(AR)部分のモデル係数
- ma_coefficients:移動平均(MA)部分のモデル係数
- intercept_or_drift:定数項
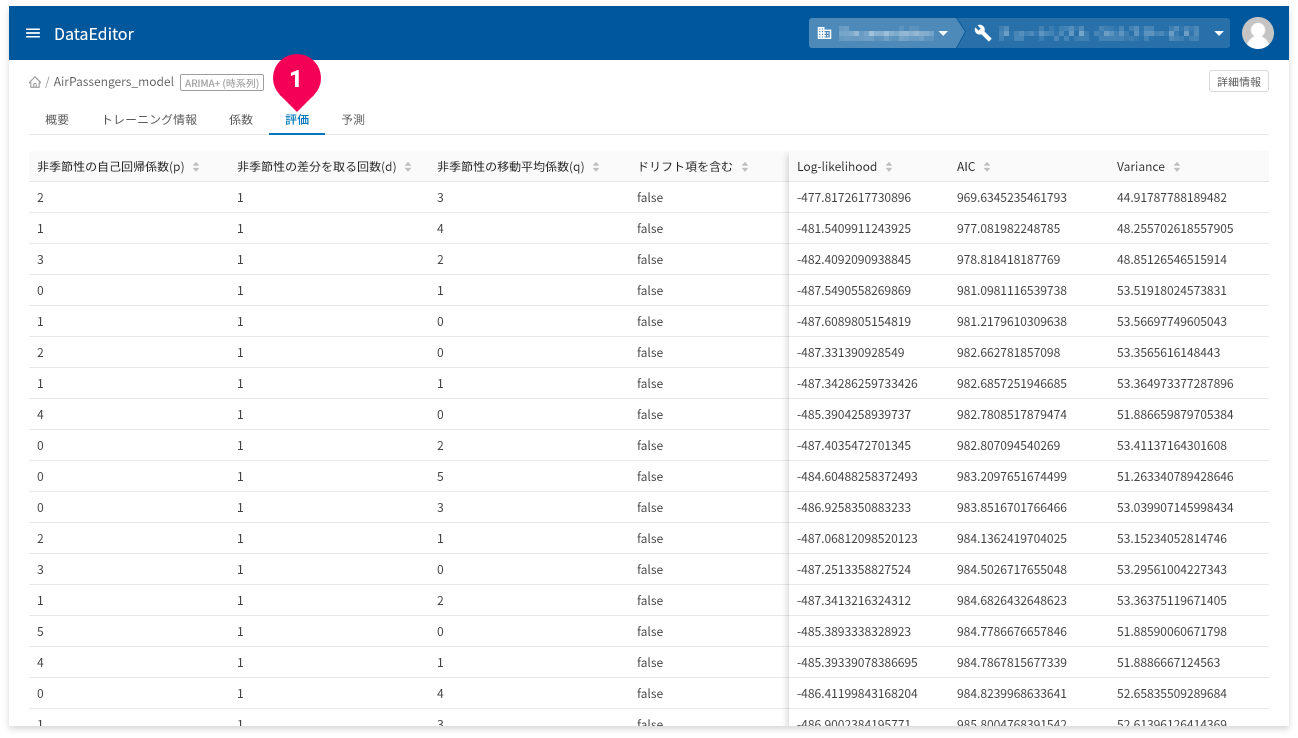
「評価」タブ(❶)をクリックすると、評価されたすべてのモデルの評価指標が確認できます。
予測
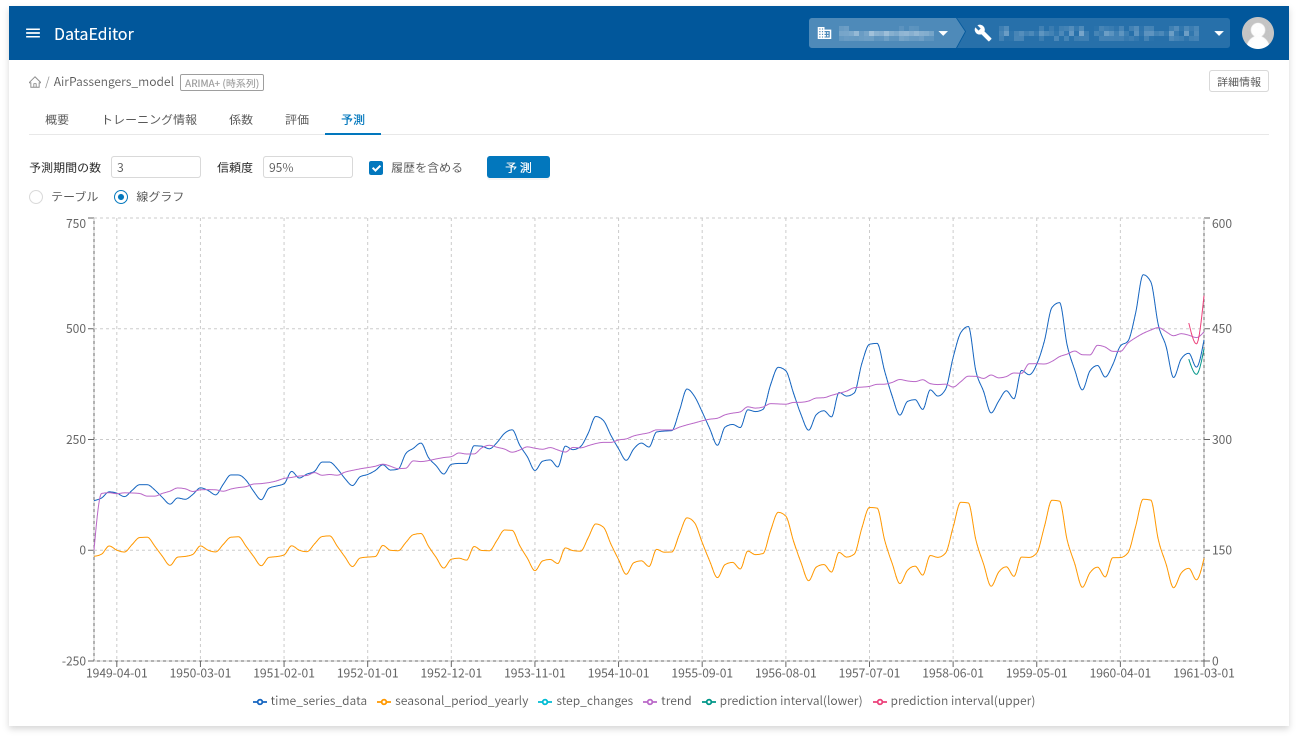
ARIMA+(時系列)の予測は、他のモデルとは異なり、作成したモデルの詳細画面で未来の時系列値を予測します。
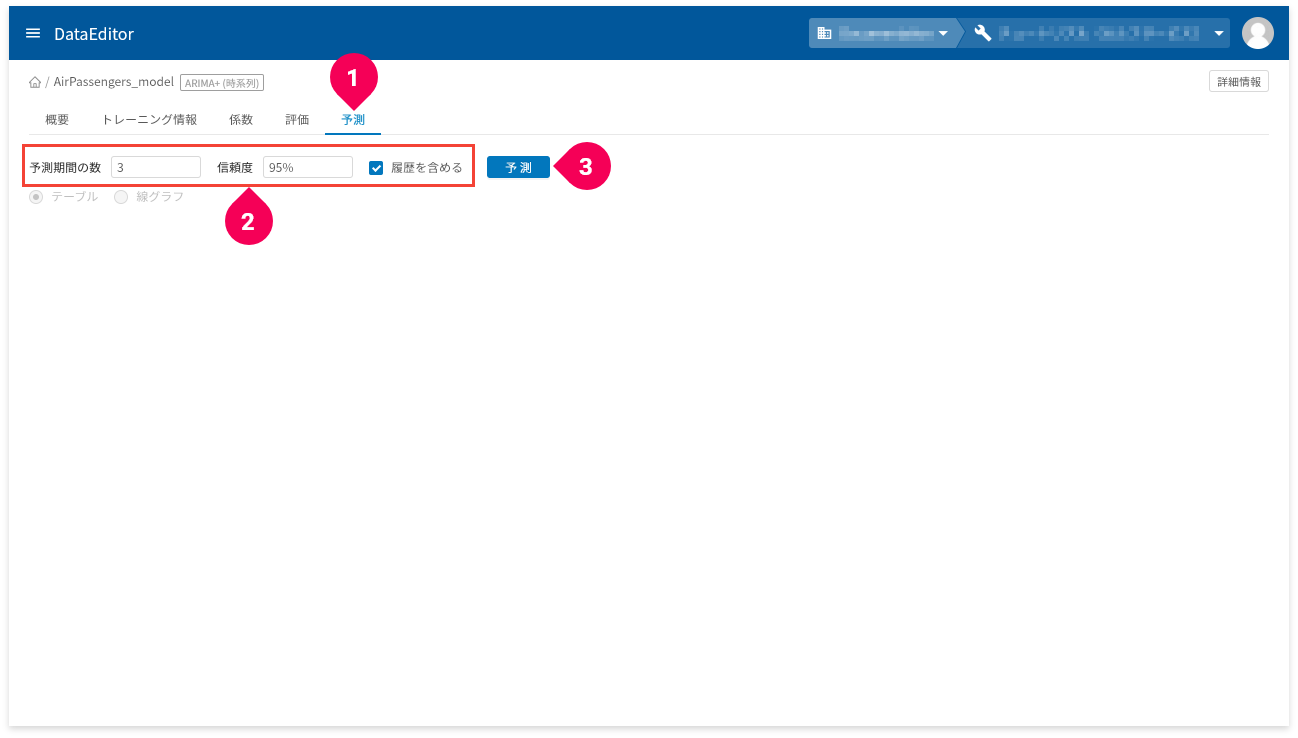
- 「
予測」タブをクリック - 「
予測期間の数」・「信頼度」・「履歴を含める」を調整 - [
予測]ボタンをクリック
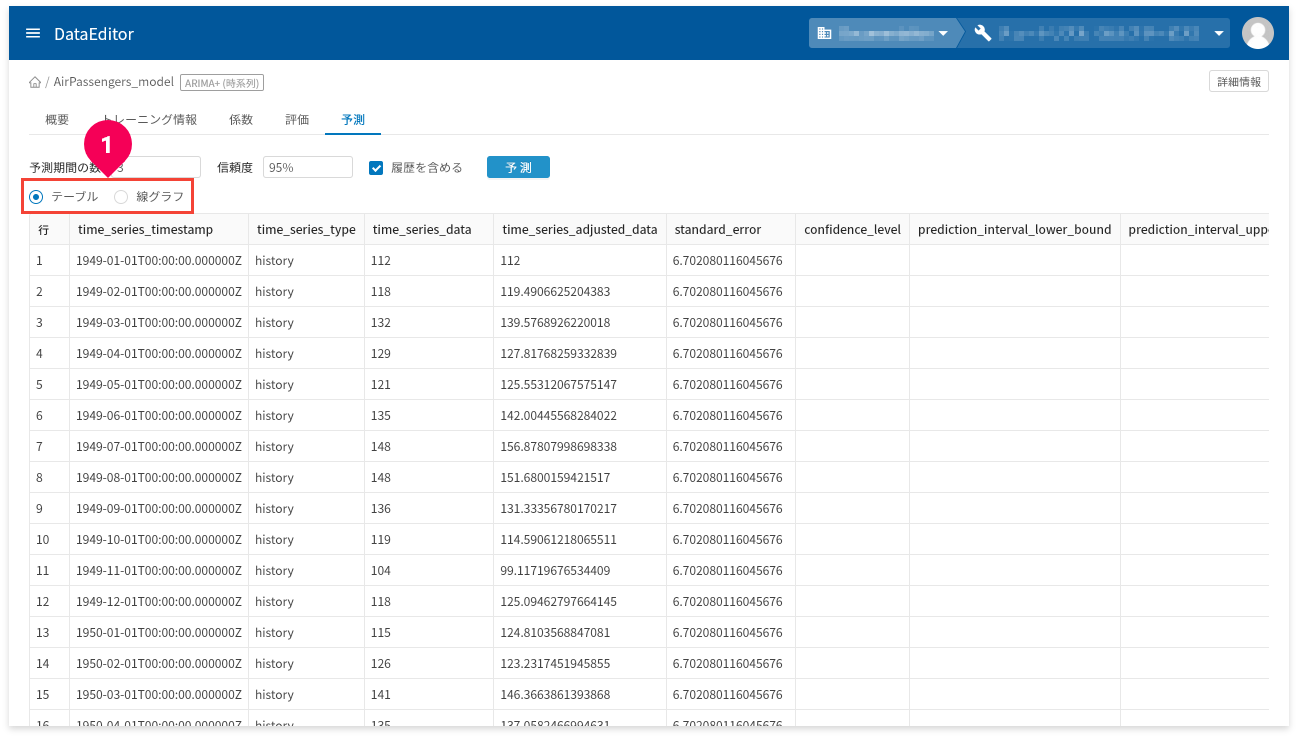
❶の部分で、テーブル表示と線グラフ表示が切り替えられます。
下図は、線グラフで表示した例です。