今回はMAGELLAN BLOCKSを使って、データのクラスタリングを行う方法を紹介したいと思います。
クラスタリングはデータ間の類似度が高いものをグループ分けします。
MAGELLAN BLOCKSでは、このグループ分けの処理をプログラミングを書くことなく、ブロックを組み合わせるだけで、簡単に行うことができます。
それでは魚別の漁獲量データを利用し、獲れる魚が似ている市町村をクラスタリング分析をしてみたいと思います。
1. データの準備
漁獲量データは、政府統計ポータルサイト(e-Stat)のデータを利用します。
このサイトはCSVのレイアウトを指定したり、不要な項目を外してダウンロードすることができます。
https://www.e-stat.go.jp/
統計データを探す > 分野 > 海面漁業生産統計調査 > データベース >市町村別データ [年次] > 2017年 > 1-2 魚種別漁獲量 全国 > 「DB」
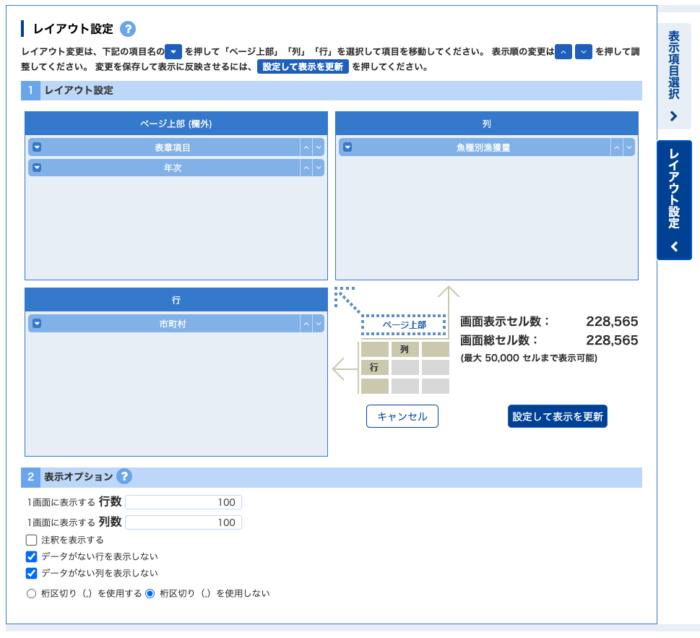
上記から「表示項目の設定」画面を開き、以下の設定を行います。
- 表示項目の設定
- 「2/4 魚種別漁獲量」
合計は不要なので、「計」がついたすべての項目のチェックを外す - 「4/4 年次」
2017年度のみチェックする
- 「2/4 魚種別漁獲量」
- レイアウトの設定
- ページ上部に「表示項目」「年次」
- 列に「魚種別漁獲量」
- 行に「市町村」
*これらはドラッグで動かすことができます - 表示オプションで「注釈を表示する」のチェックを外す
- 桁区切り(,)を使用しないを選択
最後に右上のダウンロードからCSVをダウンロードします。


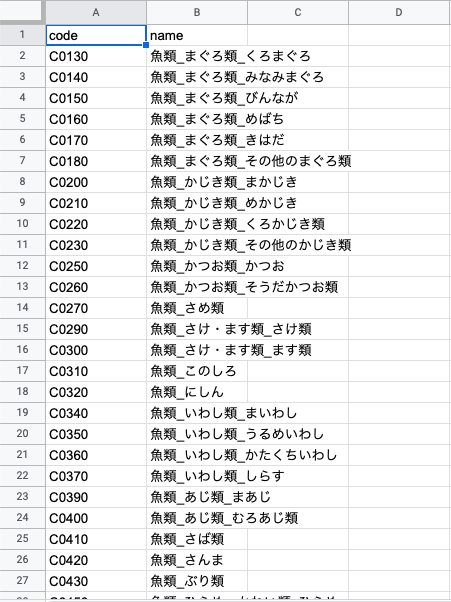
ダウンロードしたCSVは以下のとおりです。
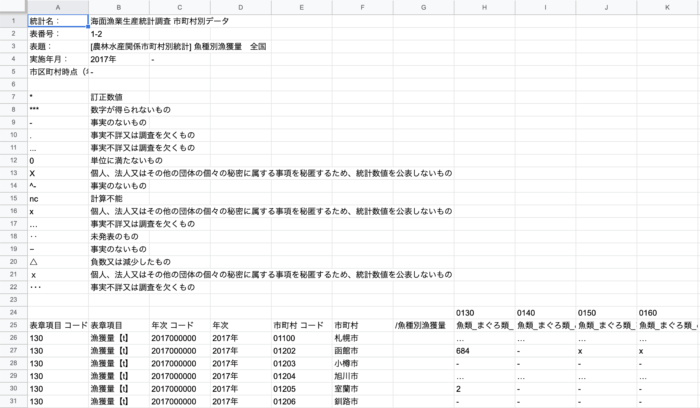
CSVの上部行に表記説明があります。データ分析する際にはこの表記の意味を考慮する必要がありますが、今回は一旦横に置き、漁獲量の数値以外のデータをすべて「0」に置換して利用します。
その他、スプレッドシートでヘッダーの置き換えや不要な列の削除を行い、以下のようなレイアウトにしました。
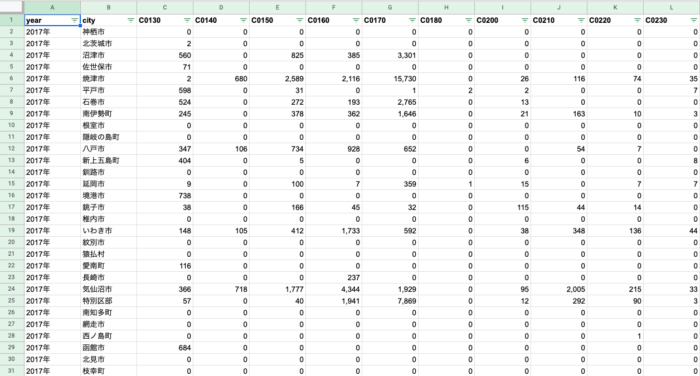
また、魚名は後でわかりやすいようにコードの対応表を別のシートに残しておきます。
2. MAGELLAN BLOCKSへのデータ取り込みとクラスタリング
作成したデータをMAGELLAN BLOCKSに取り込み、クラスタリングします。
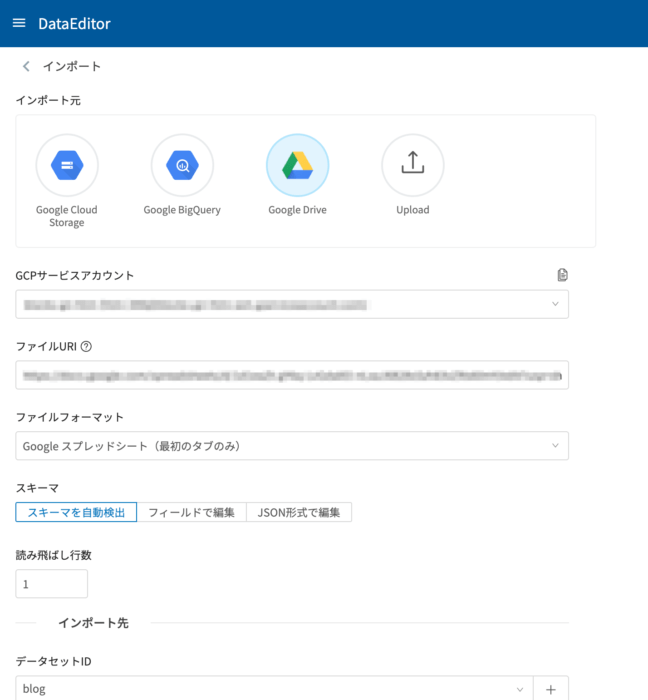
今回はMAGELLAN BLOCKSの「DataEditor」を利用し、スプレッドシートから直接データを取り込みます。
※DataEditorは、表形式のデータを視覚的に加工・分析できるサービスです。後述する「フローデザイナー」の機能でも、データを取り込むブロックがあり、処理フローの中でデータ取り込みを行うこともできます。
次に「フローデザイナー」でクラスタリングを行います。
メニューから必要なブロックをドラッグして以下のフローを作成します。
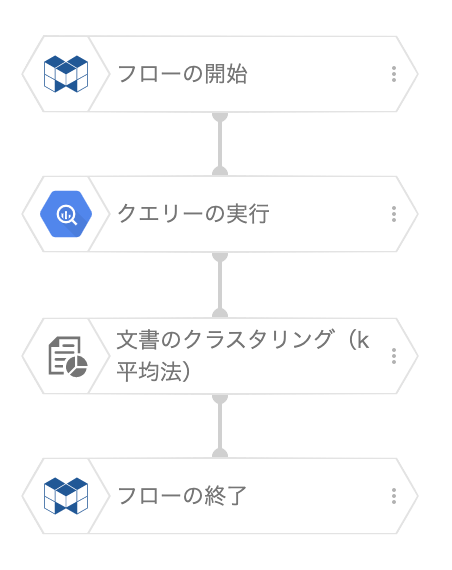
各ブロックの説明です。
- フローの開始
フローの最初に配置するブロックです。
スケジュール実行や成功失敗の通知設定が可能なブロックですが、今回は何も設定しません。 - クエリーの実行
後続のクラスタリングのブロックの処理上、各魚(各列)の漁獲量を1列にまとめる必要があるため、漁獲量の列をすべて1つの配列にする処理を加えます。具体的には下記のクエリ文を設定しました。select year, city, [ C0130, C0140, C0150, C0160, C0170, C0180, C0200, C0210, C0220, C0230, C0250, C0260, C0270, C0290, C0300, C0310, C0320, C0340, C0350, C0360, C0370, C0390, C0400, C0410, C0420, C0430, C0450, C0460, C0480, C0490, C0500, C0520, C0530, C0540, C0580, C0600, C0630, C0640, C0650, C0660, C0670, C0710, C0720, C0730, C0740, C0750, C0770, C0780, C0790, C0810, C0820, C0830, C0840, C0850, C0870, C0880, C0900, C0910, C0940, C0970, C0980, C0990, C1000, C1000, C1010, C1030, C1040, C1060, C1100] as t from blog.fish
- 文章のクラスタリング(k-平均法)
こちらがクラスタリングの処理を行うブロックです。
クラスターの数やクラスタリング後のデータ保存先を指定します。
クラスター数はとりあえず「10」に設定してみました。
(「文章の」とタイトルがついているのは、MAGELLAN BLOCKSでは、文章解析用のブロック群「単語分割、言語判定、ベクトル化、コサイン類似度、クラスタリング」が用意されており、その中のクラスタリングブロックを今回利用しているためです。) - フローの終了
処理の終わりを表すブロックです。設定内容は特にありません。
フローを実行してみます。
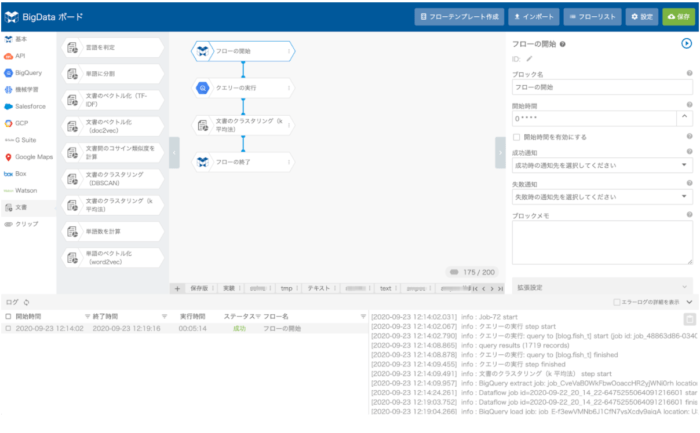
たった2つのブロックでクラスタリングができました。
結果データをみてみます。
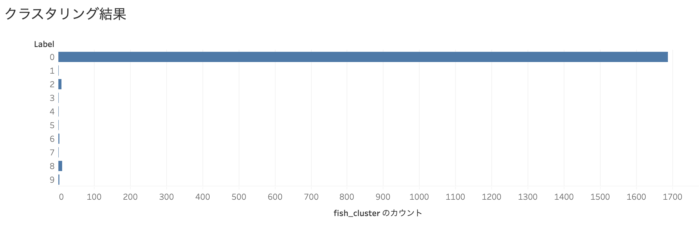
若干予想はついておりましたが、10個(0〜9)のクラスタのうち、ほとんどの市町村が「0」のグループになってしまいました。
各クラスタの魚種別や漁獲量はどうなっているでしょうか。
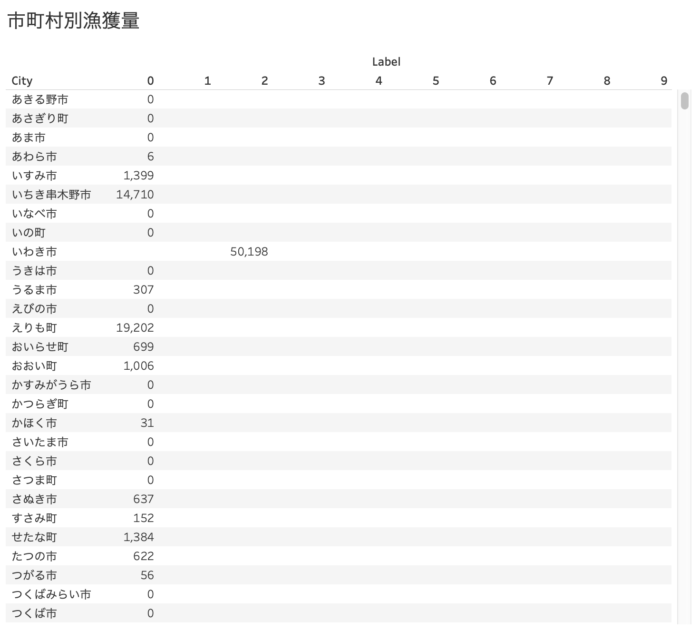
列がクラスタ、行が市町村毎の漁獲量です。
こうしてみると、市町村毎に漁獲量にかなりの偏りがあることがわかります。
漁獲量の大小がクラスタリングに大きく影響している可能性があるので、分析の目的にもよりますが、漁獲量を標準化する必要があるのかもしれません。(クエリブロックで追加可能)
漁獲量の単位が重さ(t)で表現されていますので、ウニとカニの重さが全く異なるように、魚別での分析を行うなどの工夫もした方が良さそうです。
また、漁獲量=0の市町村が全て「0」のグループに入っています。
漁獲量0をデータから除外することも検討する必要がありそうです。
ここでは一旦、漁獲量0のデータを除いて、結果をもう少しみることにしたいと思います。
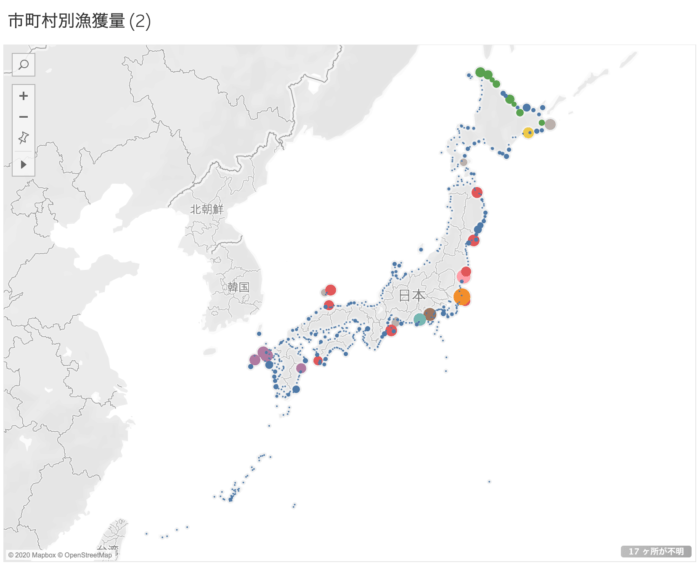
地図にプロットしてみました。(MAGELLAN BLOCKSで行ったクラスタリングの結果をTableauで表示しています。)
色はクラスターを表しており、円のサイズはその漁獲量です。
クラスタ0は漁獲量が少なく、全国的に散らばっています。
当然のことながら、陸内にはプロットされていませんが、e-Statには養殖業データもありました。それらデータとの関係性を分析してみるのも面白いかもしれません。
クラスタの色と市町村は以下のとおりです。
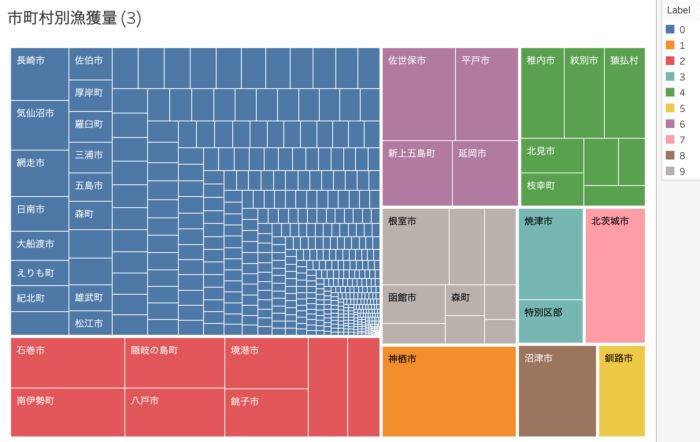
一人クラスター(オレンジ色)となっている神栖市(かみすし)は、Wikipediaによると波崎漁港のイワシ陸揚げ量が日本第2位だそうです。
緑色は北海道の北部に偏っており、紫色は九州に偏りがありました。
クラスタ毎の魚種は以下のとおりです。
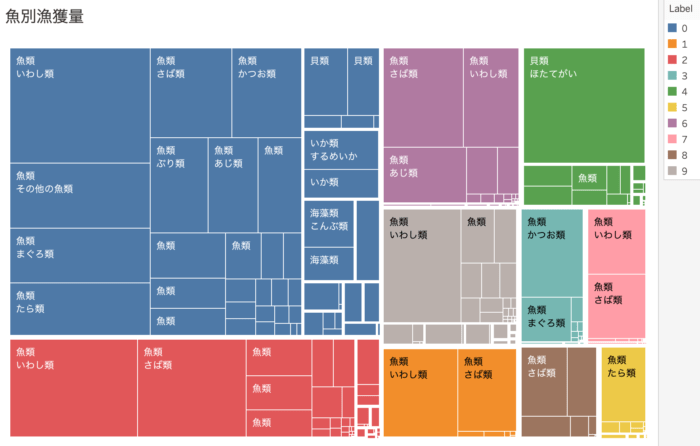
前述の神栖市はWikipediaのとおり、イワシが漁獲の半分以上を占めています。
また、イワシとサバはほとんどのクラスターにありました。全国的に獲れるのでしょうか。
北海道北部(緑色)の貝類は帆立貝がほとんどです。帆立が食べたくなったら道北に行くべきですね。
釧路市(黄色)はタラクラスターです。
ちなみに魚類別の漁獲量は以下のとおりでした。
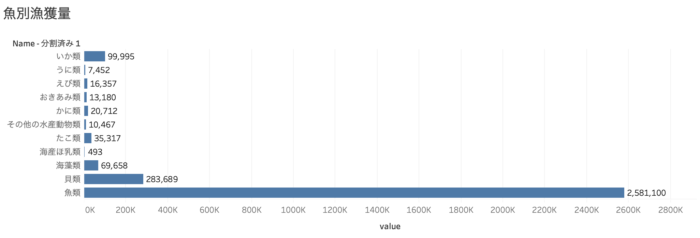
魚類はイワシとサバが占める割合が多く、その次が貝類の帆立です。
こちらは魚類に絞った漁獲量集計です。
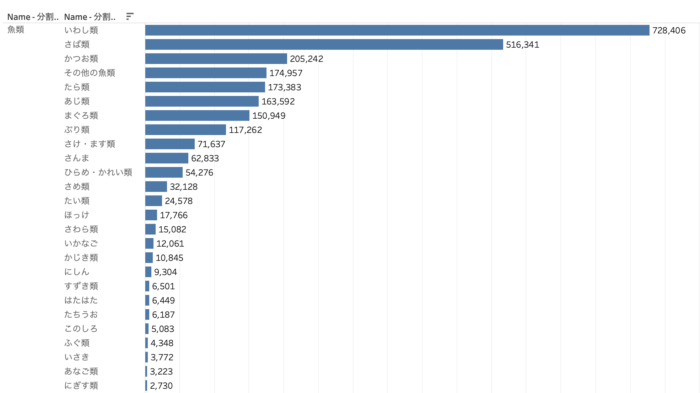
漁獲高と卸値などの経年傾向もみてみたいところです。漁獲制限などの影響も見れるかもしれません。減少があれば、おそらくそれと共に価格が高騰していっているのではないかと思われますし、大好きなウニとカニの漁獲量が減少傾向にあれば、国産ウニとカニは今よりももっと有り難く大事に感謝して食べなければいけません。
またこの魚が獲れる地域では、あの魚も獲れるというパターンの依存関係の分析をすることで分かるかもしれません。(依存関係解析もMAGELLAN BLOCKSを使うと簡単にできてしまいます。これもまた別の機会に誰かが紹介すると思います。)
このブログを書き終わったら続けて分析してみたいと思います。
3. Vector Viewerで表示
最後に漁獲量をベクトル値として捉え、MAGELLAN BLOCKSのVector Viewerで3次元のグラフに市町村をプロットしてみました。
※ Vector Viewerは、高次元のベクトルデータを視覚化し、インタラクティブに解析できるツールです。
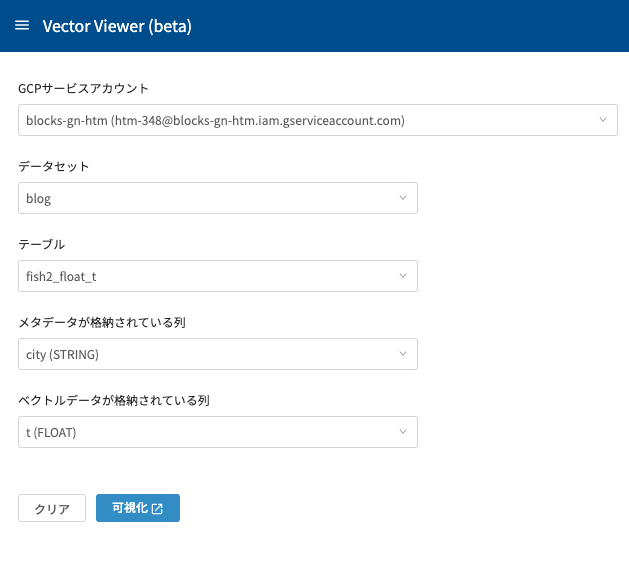
可視化するテーブルを選択し、可視化ボタンを押すとこのようなグラフを表示してくれます。(テーブルは2番目のクエリ実行ブロックの結果として保存されたテーブルを流用しています。)
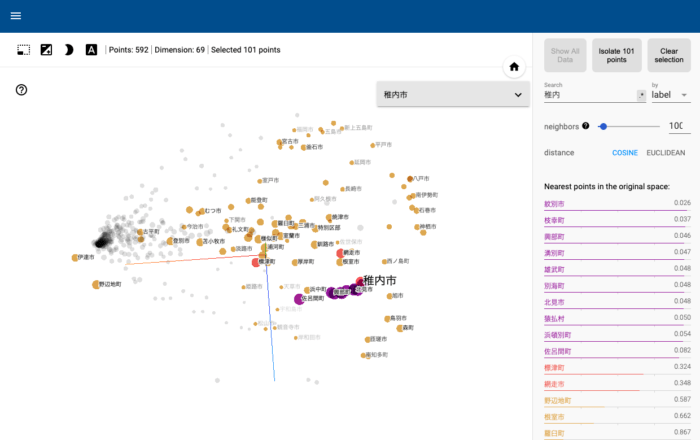
試しに稚内市で検索すると、クラスタリング結果で同じグループとなった市町村とコサイン類似度が近いことがわかりました。
このように視覚化されることによって、よりデータを感覚的に掴みやすくなります。
終わりに
クラスタリングはデータを探索する一つの手段に過ぎませんが、簡単にできれば、その分その先の考察や分析により時間を割くことができます。
MAGELLAN BLOCKSは、量子コンピュータ(イジングマシン)を利用した最適化も行えるパワーツールでもありますが、このような手助けをするツールとしても非常に便利に利用することができ、特にフローデザイナーは、試行錯誤からの本運用移行へのハードルを多分に下げてくれます。
※本ブログの内容や紹介するサービス・機能は、掲載時点の情報です。