データ統合・データ加工に関するお話で第3回目です。
前回の記事では過去データを蓄積する仕組みについて説明しましたが、実際に過去データの蓄積を始める際にはすでに数ヶ月分から数年分のデータが手元にある場合があります。そのような過去データの蓄積を開始するタイミングで取り込んでおくことを過去データ移行と言います。
そこで今回は前回までに説明した縦横変換やパーティションテーブルを使ったデータの蓄積の手法を活用しつつ、フローデザイナーの外部実行という機能を使って過去データ移行をする方法を紹介いたします。
せっかくなので横縦変換クエリーの上級編的なのも含めてみます。
(もちろん過去データ移行だけでなく、データが都道府県ごとに存在するなど、その種類に応じて多数のファイルに分かれているような場合にも活用できます。)
目次
1.データ取込のシナリオ
今回のデータ取り込みでは「各店がまとめられた売上月報のExcelファイルが多数存在していて、それをもとにデータを蓄積する」ことを行います。各支店がまとめられた売上月報はこんなイメージですね。よくある形のデータですね。
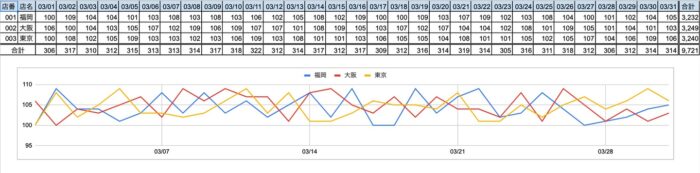
このデータは月報なので、月ごとにExcelファイルが存在します。2016年1月から存在しており、これらを全て取り込まないといけないとなったら、60個以上ものExcelファイルを取り込む処理を行う必要があります。今回はそれを実現していきましょう。
2.入力データの形式を確認
入力データはシナリオのところでも出しましたが、横(列方向)に日付を持つ月報です。人が見る分には良いのですが、データとして活用するにはデータを行として保有しておらず不適切ですね。また、今回はExcelファイルになっています。

このデータを文字通りそのまま取り込んで加工していきます。ついでに、少し前に増えた機能のExcel→CSVへ変換するブロックを使います。
3.蓄積データの形式を確認
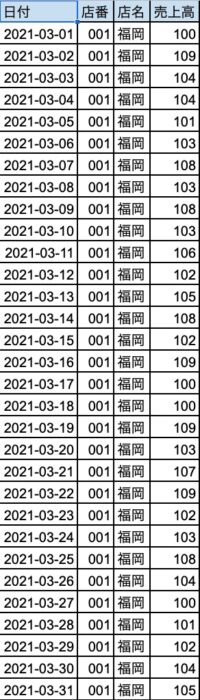
元のExcelファイル形式のままではデータとして使えないので、使える形にしていきましょう。
最終的なゴールとしては、下図のような形に持っていきたいと思います。日付の部分に、2016年1月1日〜2021年3月31日までがあるイメージですね。
4.蓄積先のパーティションテーブルを作る
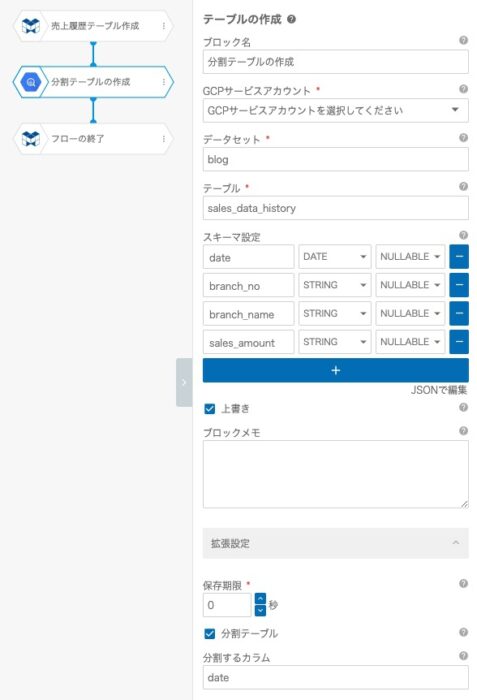
まずは蓄積先のパーティションテーブルを作成しましょう。 テーブル作成ブロックにて、空テーブルを作成します。拡張設定の分割テーブルのチェックと分割するカラムの指定を忘れないようにしましょう。
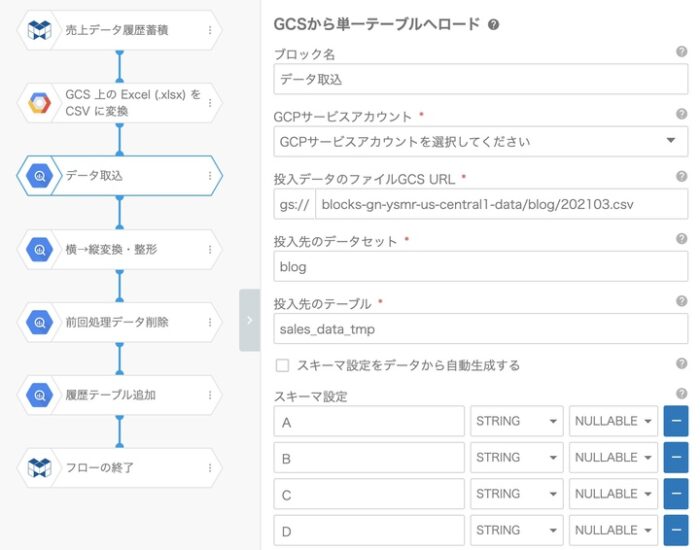
5.データを取り込む
今回のデータを取り込んで整形し蓄積するフローが下図になります。
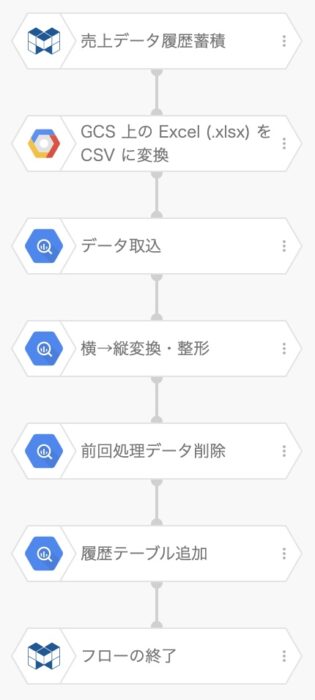
まずは、ExcelからCSVに変換する「GCS上のExcelをCSVに変換する」ブロックですね。企業内で利用されているデータがExcelであったり、データベースは別に存在していても抽出するとExcelにされたりする場合などは、このブロックでCSVへ変換します。
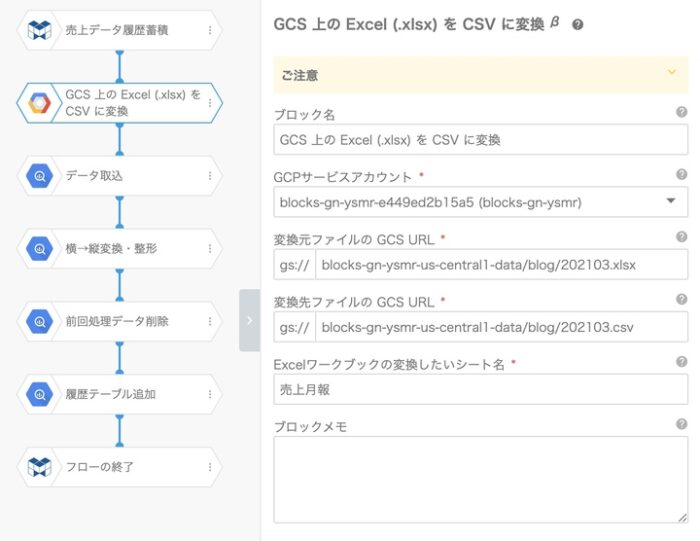
CSVファイルへ変換したら、BigQueryテーブルへ取り込むブロックにてロードします。
スキーマ設定では、項目名を“31日分+α”というようにきちんと定義するのが面倒なので、冒頭で記載したそのまま取り込む場合には、Excelの列名をそのまま(A列〜AH列)定義しています。また全てSTRING型で取り込み、後ほどデータ型を調整します。
6.横→縦に変換する
続いて、縦横変換のクエリー実行ブロックです。これは以前のブログで書いているので分かりますね。
今回はせっかくなので、横→縦変換の上級編クエリーにしてみましょう。前回は12ヶ月分のレコードをgenerate_arrayで生成した配列を展開してCROSS JOINし、12行×12列の状態からCASEステートメントにて1列にとする項目を選択しました。
今回の上級編では1-31日の列をそのまま配列にして展開。その際にoffsetを併せて出力し、DATE_ADDのインターバルとして使うことにより実現しています。CASEをたくさん書きたくないときに有効です。
with t1 as (select cast("2021-02-01" as date) as as_of_date) /* 基準となる日付を定義 */
,t2 as (
select
A as branch_no,
B as branch_name,
[C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,AA,AB,AC,AD,AE,AF,AG] as sales_amount
from blog.sales_data_tmp
where A between "001" and "999" /* 店番の列が数値であることで必要な行を選択 */
)
,t3 as (
select
date_add(as_of_date,interval idx day) as date, /* 基準日から1日ずつ配列の要素毎に加算 */
branch_no,
branch_name,
cast(sales_amount as int64) as sales_amount,
from t1 cross join t2 cross join unnest(sales_amount) as sales_amount with offset as idx
)
select * from t1 cross join t3
where last_day(date) = last_day(as_of_date) /* 31日間より短い月の場合に余分なレコードを除外 */
order by 1,2
;7.履歴テーブルに入れる
履歴テーブルに入れるのは、前回の記事「(2)パーティションテーブルへのデータ蓄積」で書いたとおりです。履歴テーブルから前回処理分を削除した後に、そのまま全件INSERTするだけになります。
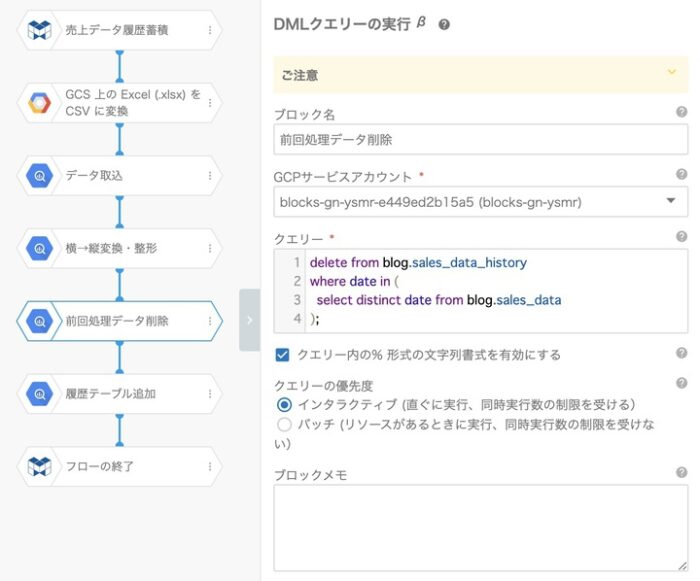
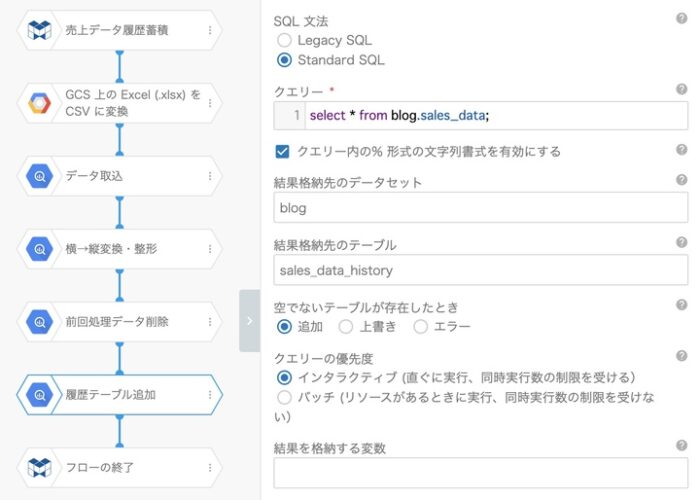
8.基準日をパラメータにして外部から実行する
ここまできたら、1ヶ月分のデータを取り込めた状態になります。次は、このフローのうち、月々のデータだと分かる部分の設定・記述をパラメーターに変えていきます。
月をパラメーターとして取り扱う場合には、基本的に2パターンの表現をします。
- ファイル名などに含まれるYYYYMMの形式(例:202101)
- 日付の基準日として取り扱うISOに準拠したYYYY-MM-DDの形式(例:2021-01-01)
上記を外部から受け取るときには、以下のような形で渡されることを想定してプロパティを設定します。(この形には後述のスプレッドシート&GASが勝手にやってくれます。)
{"_" :
{
"month" : "202103",
"as_of_date" : "2021-03-01"
}
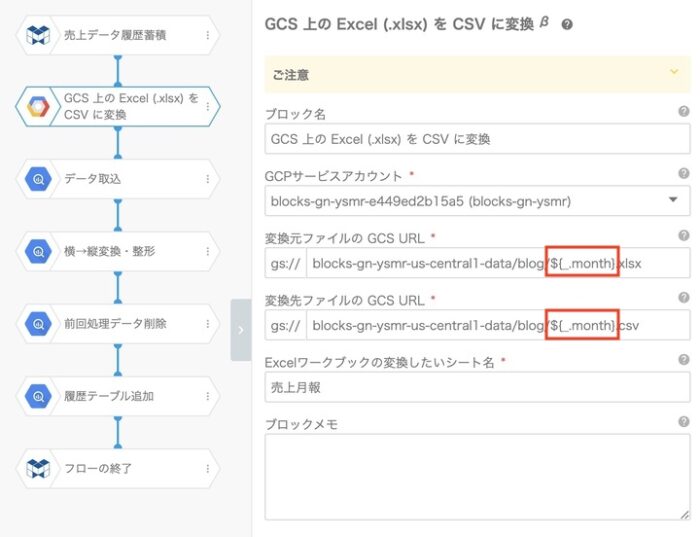
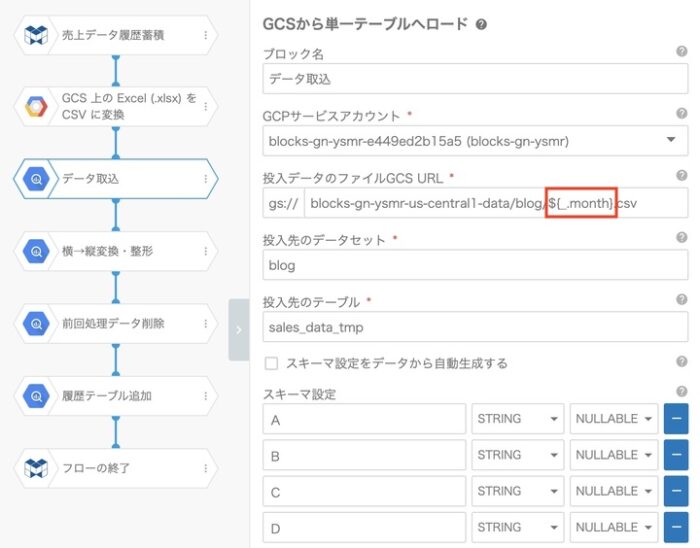
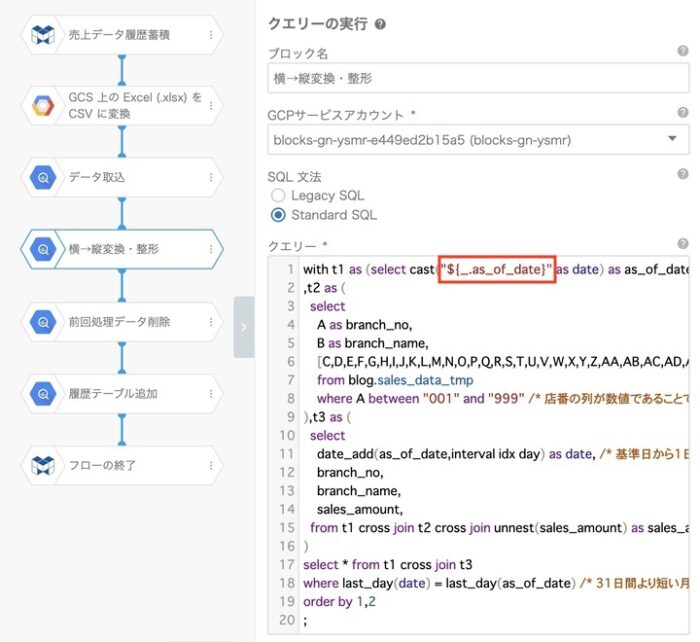
}先ほど作成したフローから変更するプロパティは3箇所になります。
- ExcelからCSVファイルへ変換ブロックの入力・出力ファイルのURL
- CSVファイルを単一テーブルへロードブロックの入力ファイルのURL
- 横→縦変換のDATE_ADDの基準とする日付
そしてフローにIDを設定します。
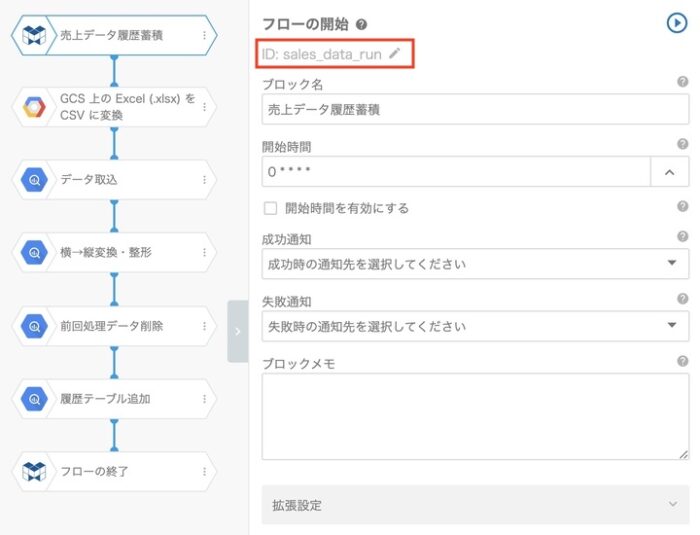
続いて外部実行について説明します。
外部実行は、「フローを外部アプリ」の方法で実行してください。
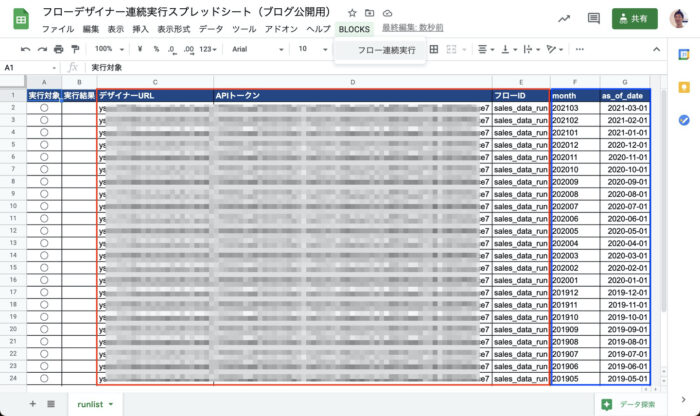
こちらがこの仕組みを利用して連続的に実行するGASを記述したGoogleスプレッドシートです。
赤枠が対象のフローを指定するためのURLやトークン、および先ほど設定したフローIDです。青枠が基準日のパラメーターとなるmonthとas_of_dateです。1行に1ヶ月分の設定となっています。
そしてこのスプレッドシートには以下(コードを見るをクリックすると表示されます)のGASが含まれています。
このGASによって、スプレッドシートの1行ずつの設定を読み込んでフローを実行していきます。そうするとプロパティを変更した3箇所の、${_.month}と${_.as_of_date}の部分がスプレッドシートに入力した値で置き換えられて実行されます。
function onOpen() {
let ui = SpreadsheetApp.getUi(); // Uiクラスを取得する
let menu = ui.createMenu('BLOCKS'); // Uiクラスからメニューを作成する
menu.addItem('フロー連続実行', 'onClickExecFlow'); // メニューにアイテムを追加する
menu.addToUi(); // メニューをUiクラスに追加する
}
function onClickExecFlow() {
// 実行確認
let message = Browser.msgBox("フローを連続実行します", "続けますか", Browser.Buttons.OK_CANCEL);
if (message != 'ok') {
// キャンセル
return;
}
// シート取得
let sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName("runlist");
// 変数定義
let designerId;
let apiKey;
let flowId;
let i,j;
//sheetを定義
sheet = SpreadsheetApp.getActiveSpreadsheet().getActiveSheet();
//シート不一致チェック
if (sheet.getSheetName() != 'runlist') {
// キャンセル
return;
}
// 実行結果列をクリア
sheet.getRange(2,2, sheet.getLastRow() - 1, 1).clearContent();
// スプレッドシートからデータ取得(固定範囲)
let data = sheet.getRange(1,1, sheet.getLastRow(), sheet.getLastColumn()).getValues();
let header = data[0];
// データの全行繰り返す
for(i = 1; i <= data.length - 1; i++) {
// 実行対象が入力されている行のみBLOCKS実行
if (data[i][0] != '') {
// 実行対象行を取得
let line = data[i];
// フローデザイナー情報取得
designerId = line[2];
apiKey = line[3];
flowId = line[4];
// パラメーター取得
let payload = {};
for (let j = 5; j <header> 100) { throw new Error("Timeout Error"); }
// GETリクエスト
let response = UrlFetchApp.fetch(url, options);
response = response.getContentText("UTF-8");
response = JSON.parse(response);
status = response.status;
Logger.log('job_id #' + jobId + ' status is ' + status);
}
// 終了後判定
if (status != 'finished' && status != 'failed' && status !='canceled') {
Logger.log('response = ' + response);
return false;
}
// フロー実行ステータス確認結果
return status;
} catch (e) {
Logger.log("ステータス取得に失敗しました:" + e);
console.log("ステータス取得に失敗しました:" + e);
return e;
}
}
これを直近の日付からデータの存在する過去の分まで実行していくことによって、2021年3月から1ヶ月ずつ遡っていく流れで、過去データを実行した分だけ変換されながら蓄積していくことができます。
まとめ
企業の現場ではExcelが1ファイルであればなんとか手で編集したとしても、100ファイルあったらさすがに無理というシチュエーションが多くあると思います。フローデザイナーと外部実行の機能を活用すれば、そういった場合にも少ない労力で対応することが可能です。
さすがにこれまでの記事と比較すると今回は難度が上がっているように感じるかもしれませんが、すこし頑張れば「絶対無理」だったことが「なんとかなる」にたどり着くことができます。データ分析をするにもデータが整備されてないと嘆かず、フローデザイナーを活用した仕組みづくりを検討いただければと思います。
※本ブログの内容や紹介するサービス・機能は、掲載時点の情報です。