MAGELLAN BLOCKSのモデルジェネレーターでトレーニングを開始する際の下記の設定についてご案内します。
MAGELLAN BLOCKSを用いて機械学習の予測モデルを作成する際には専門的な知識はいりませんが、いざ始めようと思ったら「これはどういう意味だろう?」とよく思われる部分です。
- トレーニングの経過制限時間
- トレーニングの最大試行回数
- 早期打ち切り判定を利用する
設定の説明に入る前に
上記設定項目の説明に入る前にほんの少しだけ深層学習がどういうものか知っておいてもらえると、この説明がスムーズなので説明させていただきます。(なるほど大変だという認識だけで大丈夫です)
そもそも機械学習とは 「過去のデータを機械に見せて、機械がデータからその特徴を学習し、できあがった学習モデルで予測を行う」ものです。
そして深層学習とは 隠れ層が深い層ニューラルネットワークのモデルを用いた手法です。(すみませんちょっと乱暴な説明です。)
そして上記のざっくりとした説明を読んだ上で下図を見ていただきます。
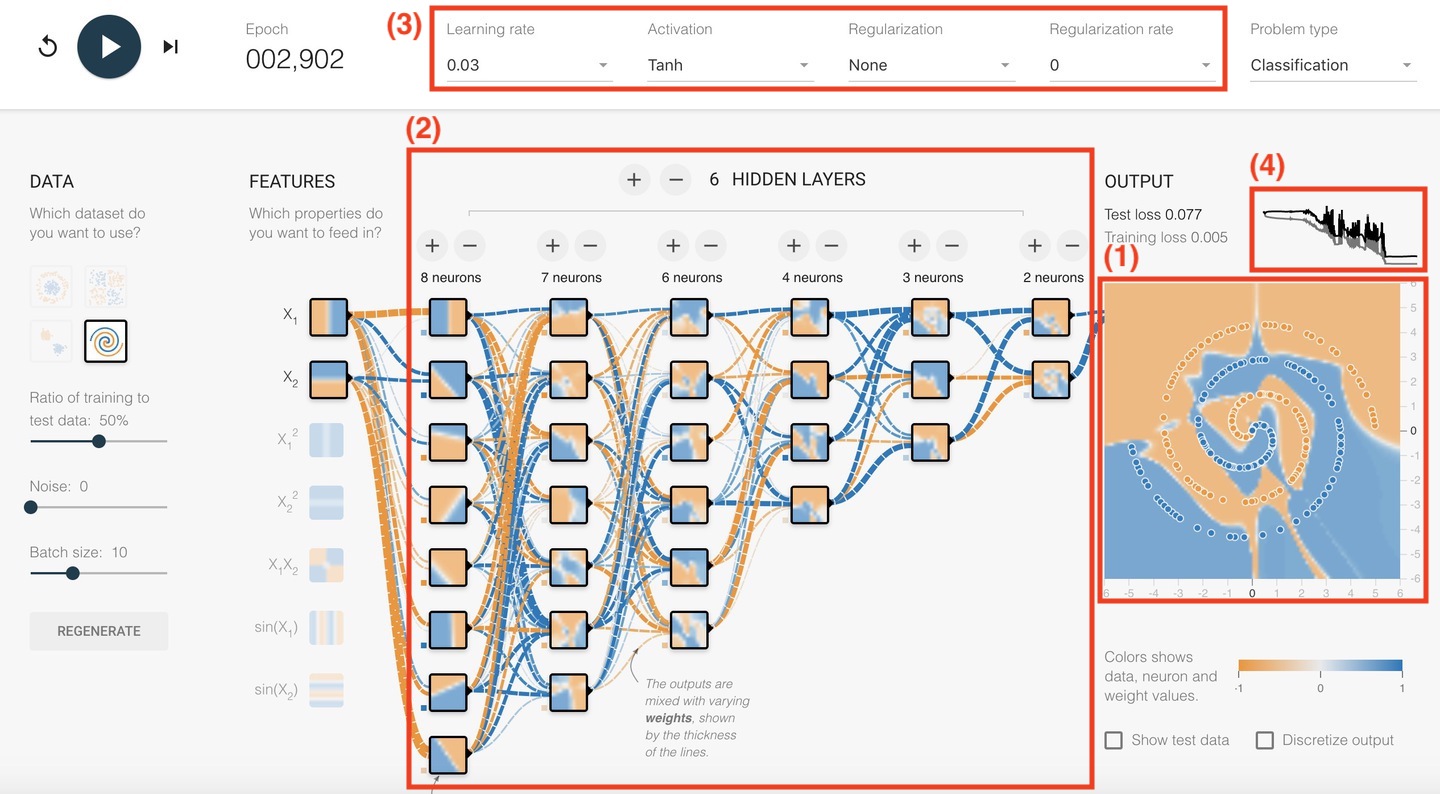
この図は深層学習の一般的なライブラリとして利用されているTensorflowのデモサイトサイトです。
まず右にある(1)のグルグルしたところ、この全ての点が学習データを示します。
青とオレンジの色が分類として学習させる結果で、青がOK/オレンジがNGと置き換えていただいて大丈夫です。そして縦軸横軸が予測因子で、例えば縦軸が気温/横軸が湿度と捉えていただきます。
よって各点が「温度がいくつ、湿度が幾つの時にOKだった/NGだった」というような意味です。
そして青とオレンジの背景が各点を学習して出来上がった予測モデルです。この予測モデルにがあれば「今まで経験してない温度・湿度でもOK/NGの判断」ができることを示します。
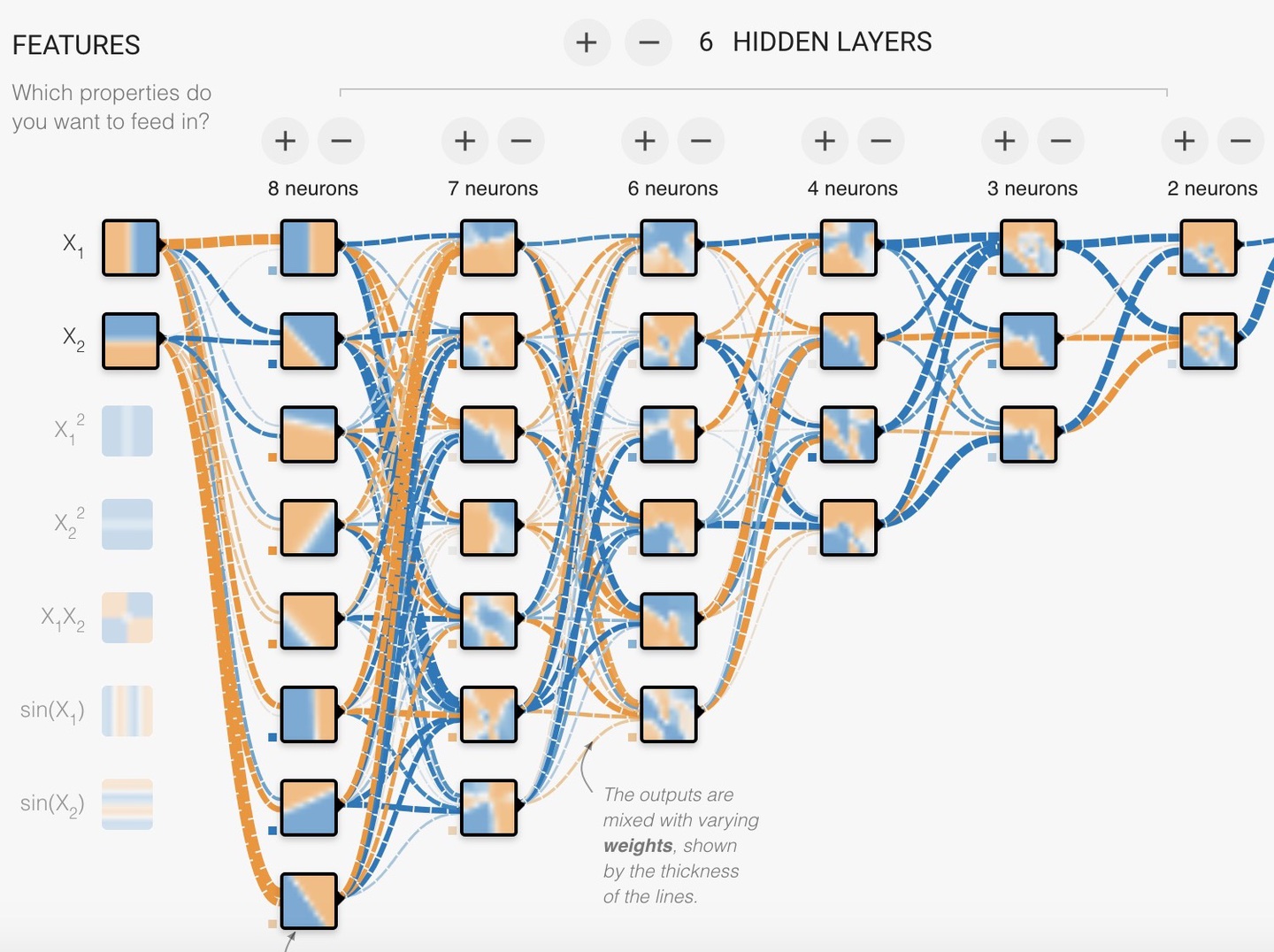
続いて中央部分の(2)ネットワークっぽいもの、これが深層学習のニューラルネットワークモデルです。その中でも赤ワクの部分を隠れ層といい、この場合6層の隠れ層があるモデルとなっています。

そして上側に(3)パラメーターっぽいもの、これらと(2)のニューラルネットワークモデルを合わせて、ハイパーパラメーターと言います。
このハイパーパラメーターですが、一度設定すればOKというわけではありません。
予測したい内容とデータによってどのようなハイパーパラメータにすればいいかが違います。
なので機械学習に取り組む時には 専門的が知識が必要 となります。しかしMAGELLAN BLOCKSを利用すると、この部分を自動的に行うため、専門的な知識不要で精度の高い深層学習の予測モデルを作ることができます。

最後に右上に(4)グラフがあります。
これがトレーニング中に算出される誤差で、小さくなると学習が進んできたということです。ただしこのトレーニングむ小さくなりそうだからと、延々すればいいというものではありません。
基本的にある程度グラフが下がって安定したら、学習が進んで収束したと判断しトレーニングを終了させます。このグラフの下がり方がなだらかになった赤丸のタイミングのことですね。
はい。これで本来したかったモデルジェネレーターのトレーニング設定を説明する準備ができました。
これまで述べたことは覚える必要はありません。なんか大変そうだという認識だけで大丈夫です。
トレーニング開始設定について
それではトレーニング開始時の設定について説明します。説明のしやすさ・理解していただきやすさの都合上、画面とは順番を変えて進めさせていただきます。
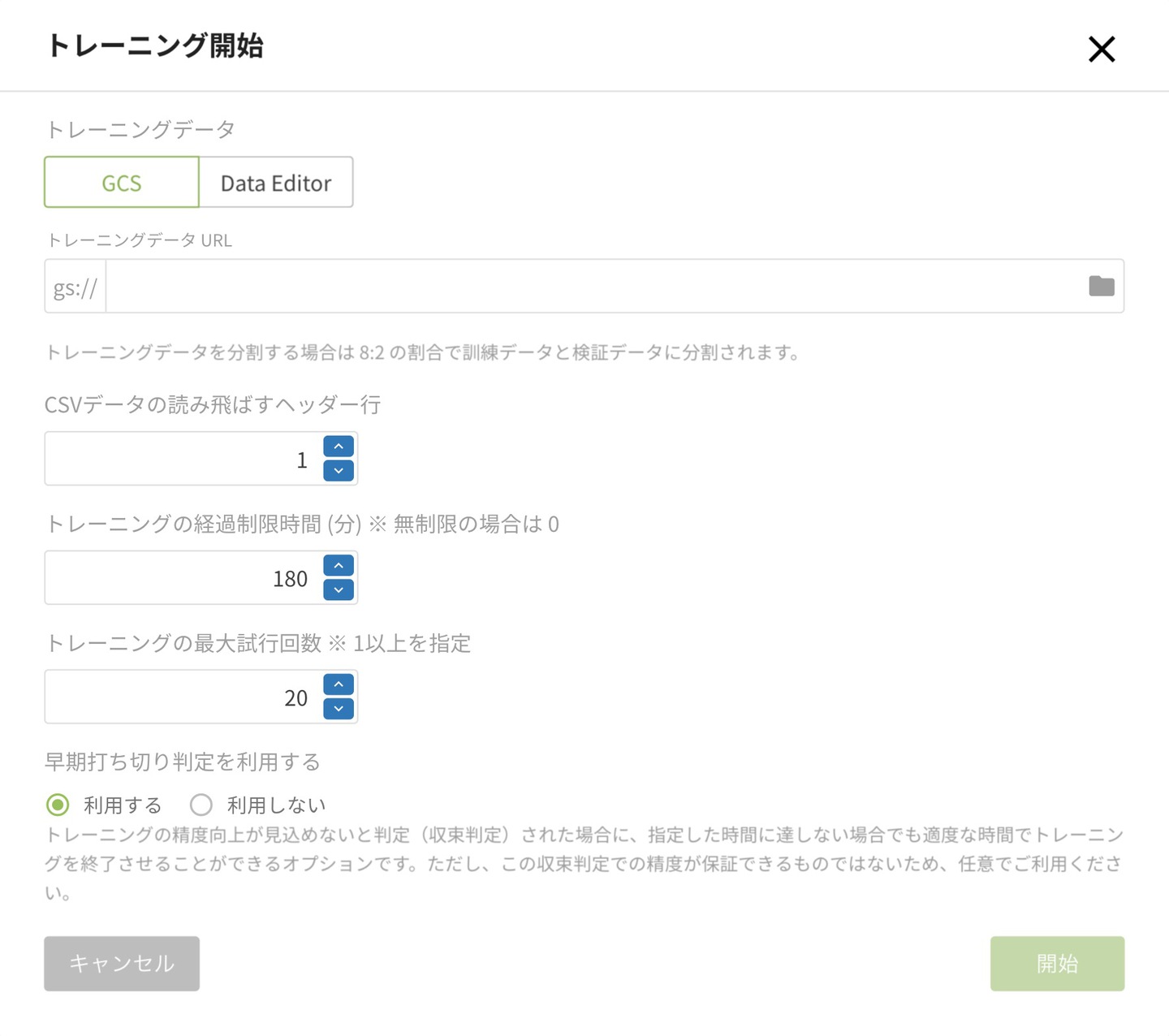
- 早期打ち切り判定を利用する
- トレーニングの経過制限時間
- トレーニングの最大試行回数
1.早期打ち切り判定を利用する
この設定は基本的に 利用する で使っていただきます。
設定の説明に入る前にの(4)グラフで説明した、「学習が進んで収束したと判断しトレーニングを終了させます」を自動的に行う設定です。
稀なケースですが十分学習が進んで収束したかと思ったのに、さらにトレーニングさせてみると、より誤差が小さくなる場合があるため 利用しない の設定もあります。
2.トレーニングの経過制限時間
続いて経過制限時間ですが、「早期打ち切り判定を利用する」を「利用する」にしているけれど、データが不適切な場合など全く収束しない場合に 収束しなかった場合に最長何分続けるか を設定する項目です。
初期設定は180分となっており、こちらも基本的にはあまり変更しません。
減らす場合としては「トレーニング動くよね確認を1分でする」場合かと思います。逆に増やす場合は「トレーニングデータがかなり多くて180分では足りない場合」が該当します。基本的には一旦180分でお試しいただければと思います。
3.トレーニングの最大試行回数
そして最大試行回数は専門的な知識が必要と述べたハイパーパラメータのチューニングに関わります。
ハイパーパラメータは予測したい内容とデータによって、様々なパターンを試していいところを探し出す必要があり、MAGELLAN BLOCKSのモデルジェネレーターはこの 最適なハイパーパラメータを自動的に探索 してくれます。その「ハイパーパラメータの探索回数を何回にするのか」というのがこの設定項目です。
初期設定は20回となっておりますが、この回数はGoogle Cloud Platformのコストと直結する部分なこともあり少し控えめな初期値としております。この探索は20回で十分な場合もあり、もっと増やして50回100回と必要な場合もあります。
オススメとしてはデータを調整しながら試行錯誤する最初のタイミングで、同じデータを使って20回・50回・75回・100回と並列してトレーニングを行い、「何回くらい試行させればだいたい誤差が小さくなってくるか」を確認し以後はその回数で継続することです。
そもそも深層学習とはの話から書かせていただきましたが、あまり悩んで欲しいポイントではないので最大試行回数を増やすくらいで、あとはデータについて、業務観点で頭をひねってトレーニングを色々試してもらえれば、精度のいいモデルを作れるかと思います。
このとおりMAGELLAN BLOCKSをご利用いただけば、本来必要な専門的な知識なしに予測モデルを簡単に作れるので、ぜひお試しいただければと思います。
※本ブログの内容や紹介するサービス・機能は、掲載時点の情報です。