今日はMAGELLAN BLOCKSを使ってマーケティングの反応予測をやってみます。
マーケティングの反応予測とは下記のようなことを言います。
・テレマーケティングでアウトバウンドコールするのに反応してくれそうなお客さまを予測して抽出する
・ダイレクトマーケティング(DM)を送るのに契約してくれそうなお客さまを予測して抽出する
・来店時に声かけして成約しそうなお客さまにだけ声かけする
今回はこちらの論文にあるポルトガルにある銀行のテレマーケティングデータを利用して反応予測を行います。
UCI Machine Learning RepositoryのBank Marketing Data Set
データの準備
UCIサイトのData Folderからbank.zipをダウンロードするとbank-full.csvというファイルが含まれています。 このデータはポルトガルにある銀行が定期預金キャンペーンを行なった際のデータです。 細かい内容は置いておきますが、データの項目としてはざっくり下記のような内容となっています。
予測因子
- 年齢
- 職業の種類
- 婚姻の状況
- 学歴状況
- 債務不履行有無
- 住宅ローン有無
- 個人ローン有無
- 連絡手段(固定電話、携帯電話など)
- 最後に通話した月
- 最後に通話した曜日
- 最後に通話した秒数
- キャンペーン期間中にコンタクトした回数
- 今回のキャンペーンまでに何回連絡したか
- 最後にコンタクト取ってからの経過日数
- キャンペーン以前に何度コンタクトできていたか
- 以前のキャンペーンの成否
予測対象
- 定期預金の契約有無
上記のうちキャンペーン期間中にコンタクトした回数は使わずにモデルを作成します。 またそのままだとちょっと使いづらかったのでデータをちょっと下記の加工しています。
- IDを付与
- 二値の項目を0,1に変換
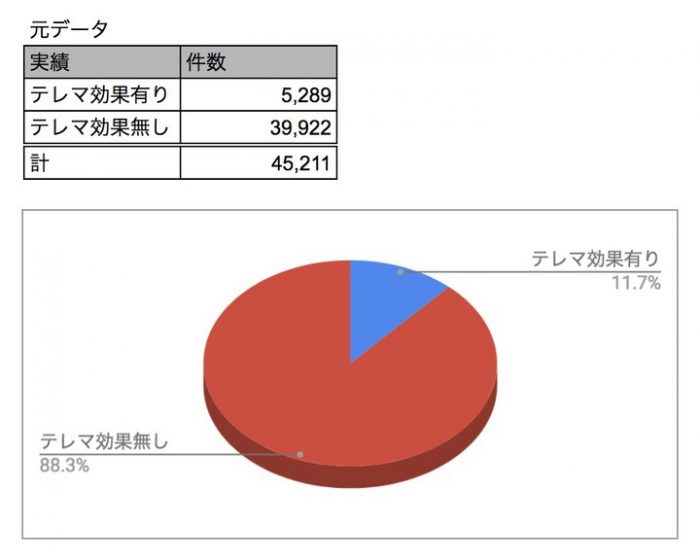
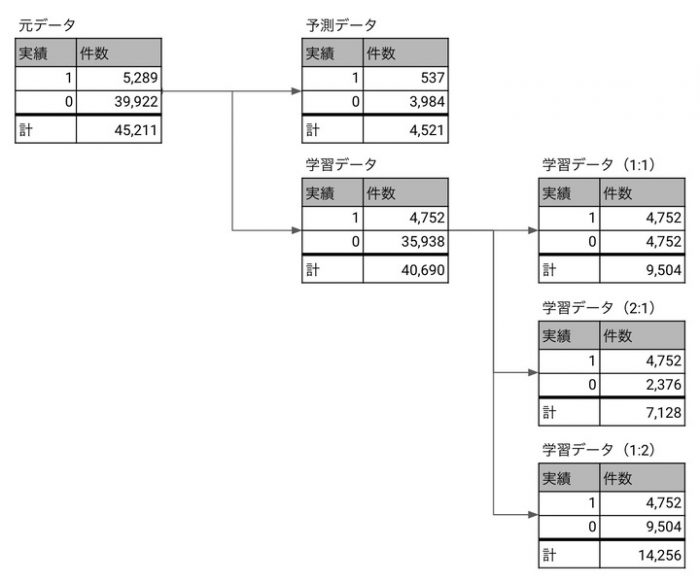
bank-full.csvのデータが全部で45,221件でそのうち定期預金契約をした顧客が5,289件でしなかった顧客が39,922件なのですが、このデータを元に学習と評価のための予測データに分割していきます。 マーケティングで利用するデータにありがちなのですが、データのバランスに大きな偏りが有ります。このようなデータはそのまま学習させると精度が出ない場合があるのでデータの量を調整します。
数値分類でデータが偏っている場合の進め方
大事なところなので分けました。
元のデータから予測データと学習データを分けるところは一緒なのですが、それだけではなくデータに極端な偏りがある場合には下図のように分類したいラベルごとにバランスを取ります。
これは偏りが大きい場合にはデータ量の多い方の特徴をより学習してしまうことによります。それを避けるためにバランスを調整します。
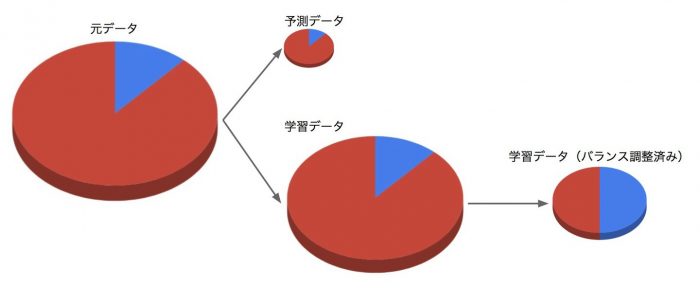
今回のようにデータに順番の概念がない場合には、まず予測データと学習データをランダムに分割します。今回は 1 : 9 の割合で予測データを1割残す様に分けています。ランダムに分割しているので、元データの偏った割合は予測データ・学習データ共に引き継がれます。
続いて偏ったまま分割した9割の学習データのうち少ない方(今回はテレマ効果なし)の件数を基準にバランスを取ります。上図は 1 : 1 の割合にしたイメージです。これを実際のデータに置き換えると下図のようにデータが絞られていきます。

まずはこの 1 : 1 にした9,504件の学習データでモデルを作って予測・評価していきます。
モデル作成・予測・評価
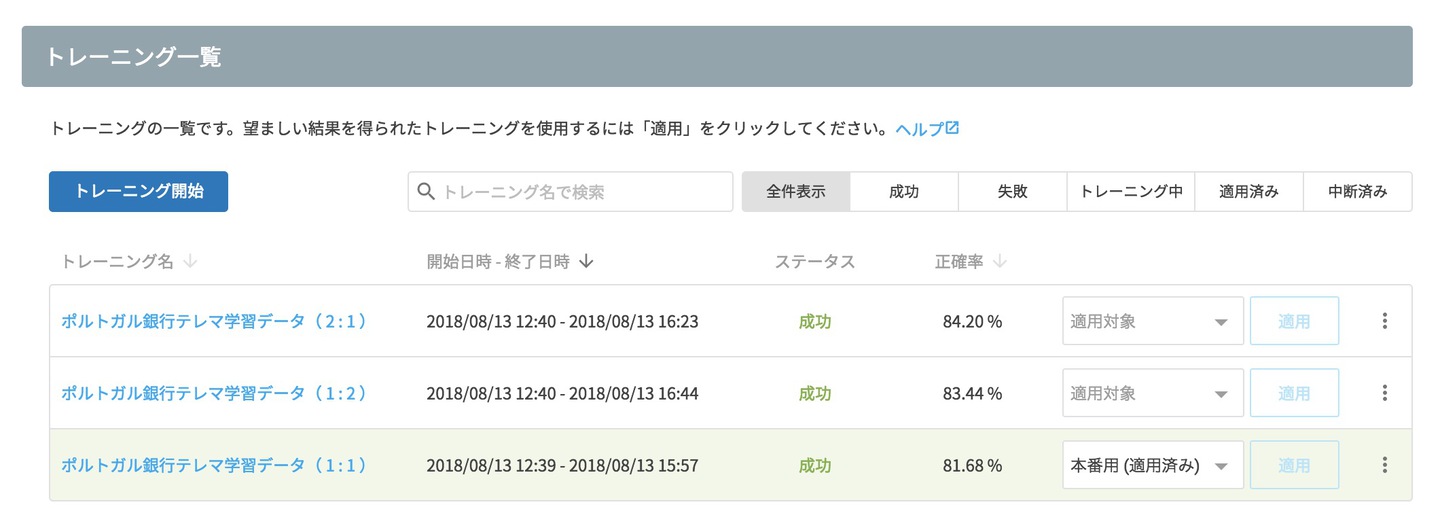
MAGELLAN BLOCKSのモデルジェネレーターを使って 1(テレマ効果あり),2(テレマ効果なし)を判別する数値分類タイプのモデルを作ります。 まずは 1 : 1 にバランスを調整したデータを使ってトレーニングを行いました。
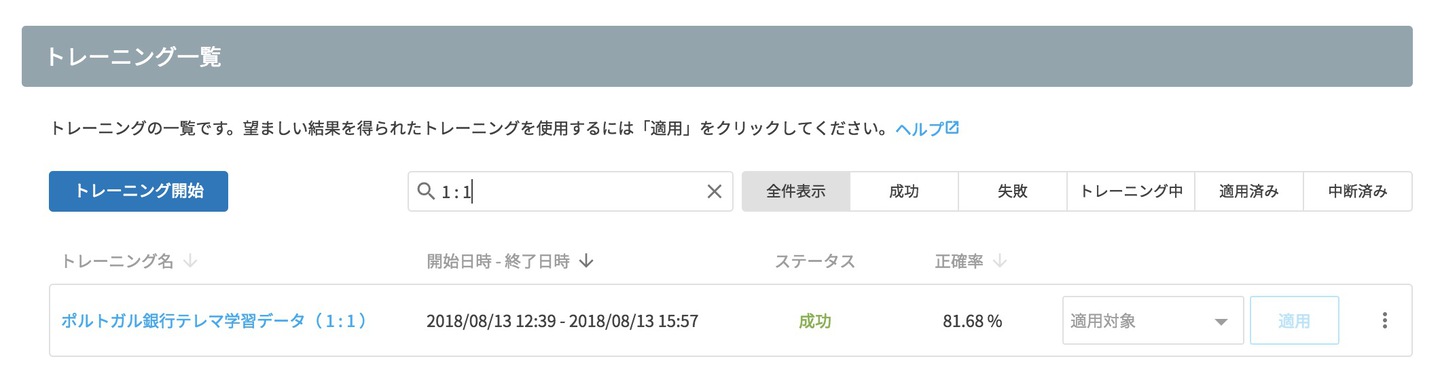
モデルジェネレーターに表示される正確率は 81.68% となっていますが、実際に予測してみるとどうなるかを評価します。
まずは混同行列です。
この混同行列をみる時に気にすべきポイントがあります。それは誤報(無駄撃ち)と取りこぼしです。
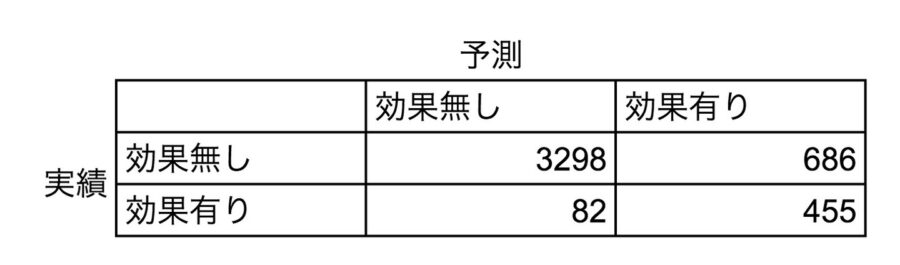
この予測モデルを使って9,504人のうち誰にプロモーションするかを考えた時に、効果ありと予測された1,141人(455+686)にプロモーションしたとします。そうすると下記のような状況が発生します(実際には取りこぼしは分かりません)。
- 686人には無駄撃ちなプロモーションをしている
- 82人の実際には効果がある人を取りこぼしている
この取りこぼしの少なさや無駄撃ちの少なさを評価する指標とそのバランスを評価する指標を紹介します。
- Precision(適合率)
誤報(無駄撃ち)の少なさの指標で100%に近いほど誤報が少ないモデルと評価できる。 - Recall(再現率)
取りこぼしの少なさの指標で100%に近いほど取りこぼしが少ないモデルと評価できる。 - f-measure(F-値)
誤報と取りこぼしの少なさのバランスの指標で100%に近いほどバランスが良いモデルと評価できる。
ちょっと計算がややこしいですが、マーケティングに携わる方にはぜひついてきていただきたいです。
Precision(適合率)
Precision(適合率)は誤報の少なさなので、効果ありと予測したうちの実際に効果ありの割合となります。
これを計算式にすると
Precision(適合率)= 効果ありと予測して実際に効果ありの件数 ÷ 効果ありと予測した件数
という式になります。
これを今回のデータに当てはめてみると
Precision(適合率)= 455 ÷ ( 455 + 686 ) = 0.3987730061 ≒ 40%
40%なのでぱっと見あまり良くないですね。
Recall(再現率)
Recall(再現率)は取りこぼしの少なさなので、実際に効果があったうちの効果ありと予測した割合となります。
これを計算式にすると
Recall(再現率)= 効果ありと予測して実際に効果ありの件数 ÷ 実際に効果ありの件数
という式になります。
これを今回のデータに当てはめてみると
Precision(適合率)= 455 ÷ ( 455 + 82 ) = 0.8472998138 ≒ 85%
こちらは85%なのでぱっと見あまり良さそうですね。
この2つの指標値はどちらが大事かとうと、この予測モデルを使うシチュエーション(目的)によって変わります。
例えば今回のようにマーケティング目的であれば、取りこぼしはしょうがないとしても極端に誤報が多いとコストがかかるためPrecision(適合率)を重視するかもしれません。
逆に品質検査の目的であれば、誤報が多少あっても取りこぼしを減らす必要がありRecall(再現率)を重視するかもしれません。
分類モデルを利用するシチュエーションでは、自分はどういう目的で作ったモデルを利用するかよく考えておくことが大事です。
f-measure(F-値)
とは言うもののどっちも大事なのでそのバランスを見ないといけないシチュエーションも多いと思います。そこで利用するシチュエーションがf-measure(F-値)です。
f-measure(F-値)はPrecision(適合率)とRecall(再現率)のバランスなのですが、これはちょっと計算式がややこしいです。この計算式は「こういうもんだ」と使ってもらえればと思います。
f-measure(F-値)= 2 × Precision × Recall ÷ ( Precision + Recall )
これを今回のデータに当てはめてみると
f-measure(F-値)= 2 × 0.40 × 0.85 ÷ ( 0.40 + 0.85 ) = 0.5423122765 ≒ 54%
結果は54%となりバランスは良くないですね。(45%と85%ですし)
モデルのバランス調整
ここまでで分類モデルを作って評価するところまできましたが、目的に合わせてモデルのバランスを調整するということをやっていきます。そのためには学習データのバランスを調整します。
- Precision(適合率)を改善して誤報を減らしたい
→取りこぼしを減らすには効果ありの割合を増やす(効果なしの割合を減らす) - Recall(再現率)を改善して取りこぼしを減らす
→誤報を減らすには効果ありの割合を減らす(効果なしの割合を増やす)
今回のデータであれば効果ありの件数は調整できないので、効果なしの件数を調整して割合を変更します。具体的には下図のようになります。
この学習データのバランスを 1 : 2 にしたデータと、 2 : 1 にしたデータで学習させたトレーニング結果がこちらです。
それぞれ予測して評価指標を出すとこのようになりました。
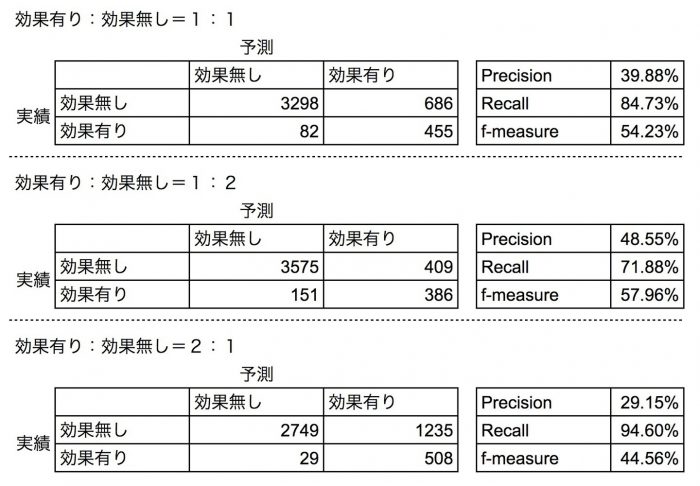
1 : 2 にしたモデルでの予測結果はPrecision(適合率)が改善し誤報が減っていることがわかると思います。その代わりRecall(再現率)が下がって取りこぼしが増えています。よってf-measure(F-値)が良くなっています。
2 : 1 にしたモデルでの予測結果はPrecision(適合率)が下がり誤報が増えていることがわかると思います。その代わりRecall(再現率)が改善して取りこぼしが減っています。よってf-measure(F-値)が悪くなっています。
このように元が同じデータでもPrecision/Recallのバランスを調整し、目的にあったモデルに近づけることが可能です。(そもそもの精度を上げるためにはより特徴を捉えた予測因子を増やす等の検討が必要です。)
今回は顧客ごとのデータでテレマーケティングの反応予測を行いました。もちろんDMや対面プロモーションでも同様に利用することが可能です。またセンサーデータをもとにした異常検知など他の分類予測も同じような考え方でモデルを作成することが可能です。過去のデータがあればすぐにできるので(今回も論文データをダウンロードしてきただけです)、ぜひ社内のマーケティング用のデータなどで分類予測に試みていただければと思います。
※本ブログの内容や紹介するサービス・機能は、掲載時点の情報です。