前回の「フローデザイナーでデータ統合:(1)データの縦横変換編」 に引き続きデータ統合・データ加工に関するお話です。
今回は過去データを蓄積する仕組みについてご説明したいと思います。データの蓄積とは毎日・毎月発生するデータをMAGELLAN BLOCKSの環境に取り込み、そして毎日のデータを溜め込んでいくことです。
具体的には、BigQueryのパーティションテーブル機能を用いて蓄積します。
1.パーティションテーブル
パーティションテーブルとは日付や数値の項目を用いてデータを塊(パーティション)ごとに管理し、アクセス時には必要なパーティションで指定したレコードのみにアクセスできる仕組みです。 この機能を使うことでデータを読み込む量を少なくすることができるので、処理時間が短くなるしアクセスに対する費用も抑えることができます。
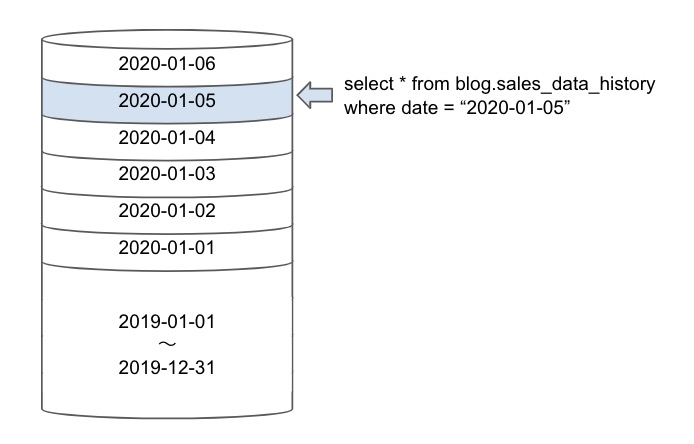
図のように1つのテーブルなのですが、日付毎に区切られて管理されているようになります。
日付を指定すればその部分だけアクセスすることができます。
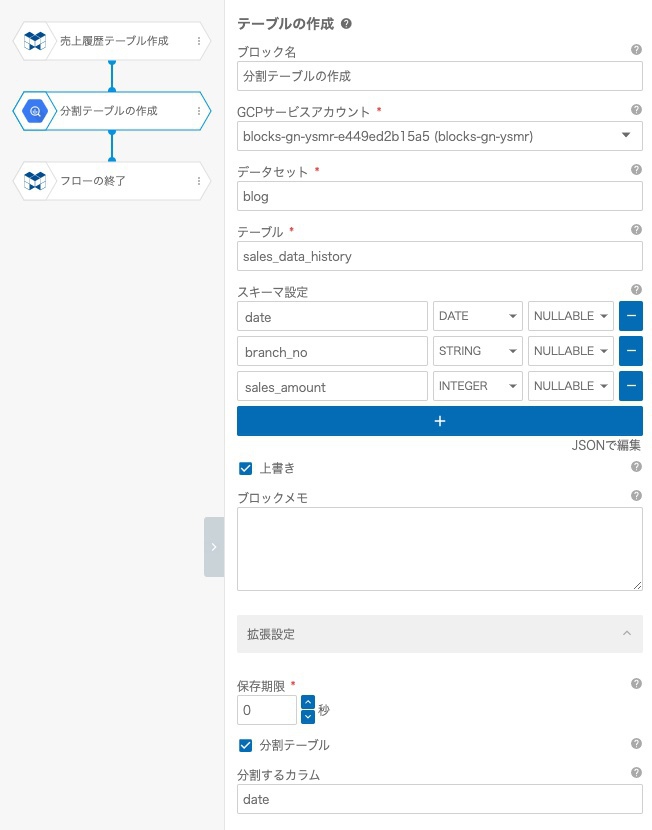
このパーティションを指定したテーブル作成を、MAGELLAN BLOCKS フローデザイナーのブロックで行うことができます。
拡張設定の 分割テーブル にチェックを入れて、 分割するカラム に具体的な項目名を指定することでパーティションテーブルを作成することができます。
一旦、このフローは単体で実行してテーブルを作成します。
2.処理の流れ
テーブルが作られた状態でどのようにデータを取り込んで蓄積していくのか、流れを説明します。
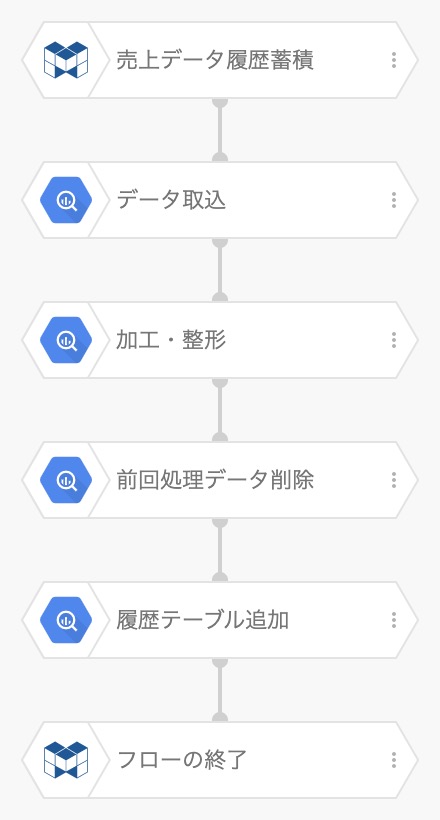
まずはフローは図の4つのブロックになります。(開始・終了ブロックを除く)
データの流れとしては下図のようになります。 それぞれポイントがあるので次章以降でご説明します。

3.データ取り込み
まずはデータの取り込みです。 取り込み元はGCS/Google Drive/スプレッドシートなど、データのフォーマットとしてはCSV/JSONなど色々とありますが、今回はスタンダードなGCSに保存されたCSVファイルを例にします。
今回はこのようなデータです。
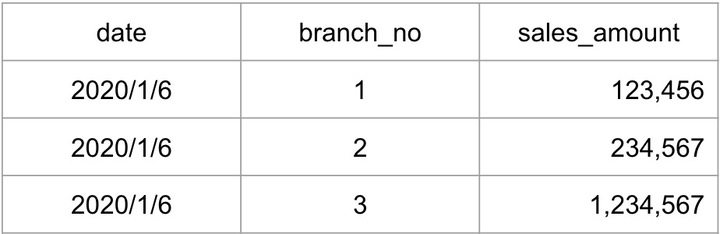
データの取り扱いに慣れている人から見ると「ちょっとだけ面倒」なデータなのが分かると思います。
- 日付は YYYY-MM-DD の形でいてほしい
- 店番のようなID系が数値の場合は ゼロ埋め されてほしい
- 金額のような数値は 桁区切りなし でいてほしい
というような状況によくなります。またデータの正確性に不安がある場合もあります。(例えば2月30日など。)
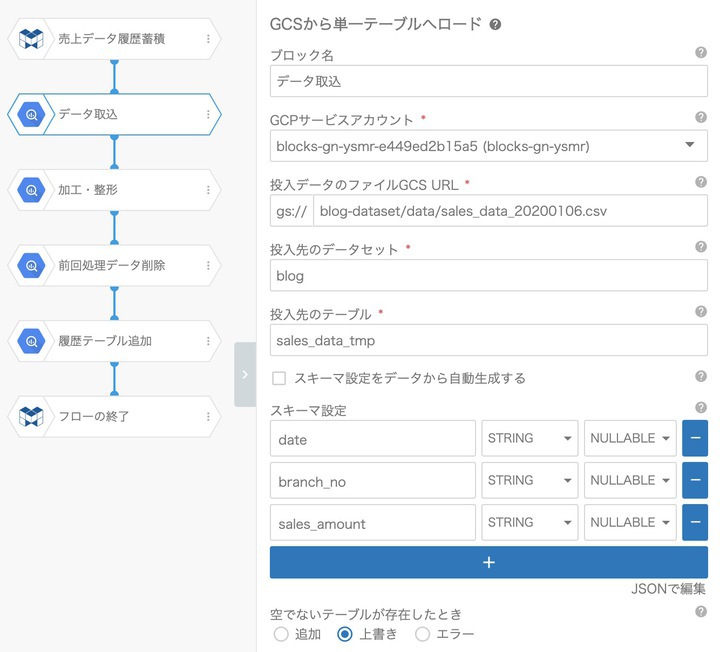
このようなデータを日付型で取り込むと、もちろんエラーになります。
エラーになった場合、100件くらいであれば直接エラーデータを探せますが、数万件を超えるとエラーデータをCSVから探すことは難しくなります。
そのような場合に対応するために 最初はすべて文字型 で取り込みます。
4.整形・加工
先程、すべての項目を文字型で取り込むと説明しました。なのでこのステップでは文字型で取り込んだデータを、分析などを行う際に使いやすい形に整えます。
ちなみにデータを整える行為は、前回の記事 で説明したデータの縦横変換も含まれます。今回のデータであればこのように整えます。
select
parse_date("%Y/%m/%d",date,) as date, /* 日付を整える */
format("%03d",cast(branch_no as int64)) as branch_no, /* 3桁でゼロ埋め */
cast(replace(sales_amount,",","") as int64) as sales_amount, /* カンマ区切りを除外 */
from blog.branch_sales_data_tmp;
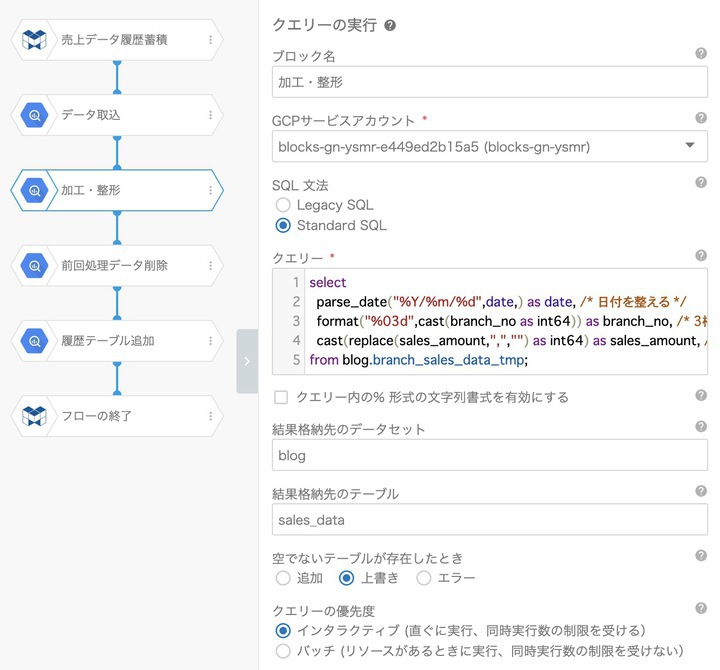
上記のクエリを設定する際に1つだけ注意事項があります。クエリー内の% 形式の文字列書式を有効にする のチェックを外します。 これは、フローデザイナーには「% 形式の文字列書式」という機能があり parse_dateで指定すると%とバッティングするためです。
このクエリで、「データ取込」ブロックで取り込んだ文字型のデータを使いやすいデータに整えることができます。今回で作ったデータは、1日分のデータです。これを次の2つのブロックによる処理で蓄積します。
5.履歴テーブルから前回処理分の削除
蓄積すると言いながら一度削除する意味の説明をします。 この後で履歴テーブルにデータを追加するのですが、追加処理を複数回実行するとどうなるでしょう?もちろん重複したデータを登録してしまうことになります。
これを回避するために前回登録したデータを削除するためのブロックを準備します。 それが、この「前回処理データ削除」ブロックです。
同じ操作を何度繰り返しても、同じ結果が得られる ようにすることを冪等性(べきとうせい)を持たせると言います。フローデザイナーで処理を作るときは、なるべく冪等性を持たせた仕組みにすると何かと楽です。
今回のように前回処理分の削除をするには次のクエリを実行します。
delete from blog.branch_sales_data_history where date in ( select distinct date from blog.branch_sales_data );
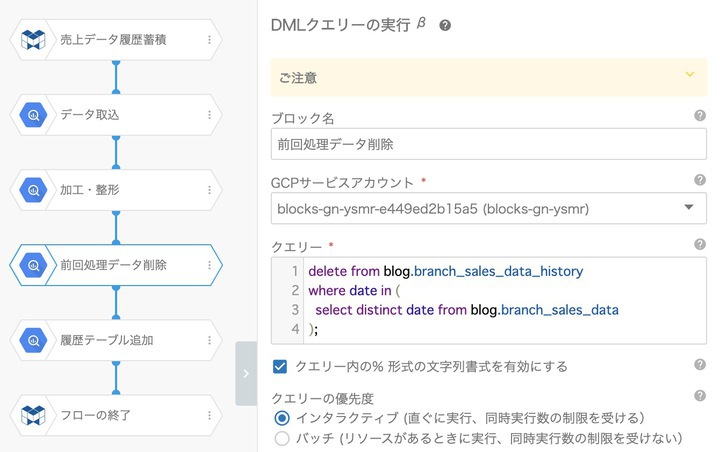
inで指定しているサブクエリのdateでパーティションを指定しています。このようなクエリで一度削除しておけば、もう一度追加してもデータが重複せず管理できます。
6.履歴テーブルへの追加
最後に履歴テーブルへの追加です。
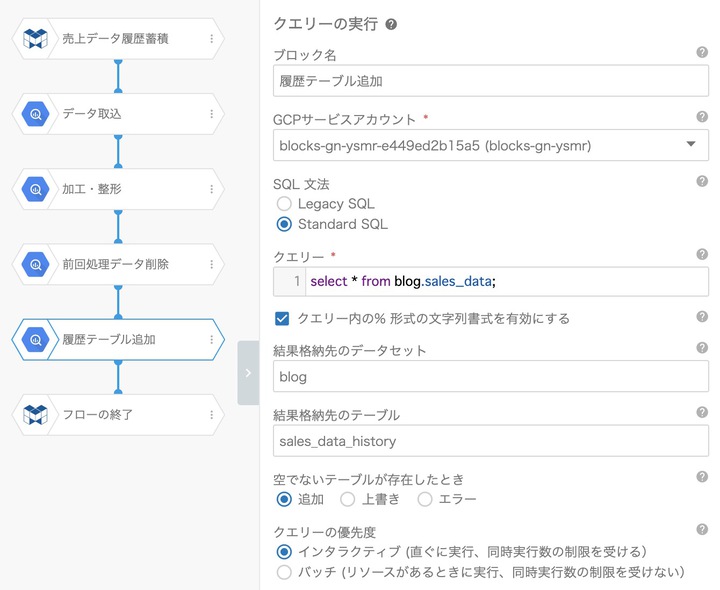
これは簡単です。図のようにブロックの設定をするだけです。
いかがでしたでしょうか?
基本的にはどんなデータの蓄積も、こうしたパターンを派生させるだけです。
「フローデザイナーでデータ統合:(1)データの縦横変換編」の記事 のように縦横変換が含まれるのであれば整形・加工のステップに含めますし、追加だけでなく更新も含まれるような場合には、「前回処理データ削除」ブロックの設定条件を変更します。
MAGELLAN BLOCKSのフローデザイナーを使えば、このようなデータの取り込み・加工・蓄積が簡単に実現できます。分析環境がまだ全然作れていない!という場合には、フローデザイナーで仕組みづくりをご検討いただければと思います。
※本ブログの内容や紹介するサービス・機能は、掲載時点の情報です。