今日は 文字コード に関するお話です。
なるべくやさしくお伝えするために、文字コードに詳しい方からすると端折ったり不適切な説明が含まるかもしれませんが、ご容赦ください。
少しややこしい説明が続きますが、「ふだんExcelなんだけどMAGELLAN BLOCKSでどうしたらいいの?」という方は、
後半の UTF-8のCSVファイルの作り方へ へスキップしてください。
目次
文字コードについて
文字コード という言葉を初めて聞く方もいるかと思いますが、文字化け であれば聞いたこと・見たことがあるのではないかと思います。
乱暴に表現すると日本語しかわからない人に英語で話しかけちゃうと文字化けが起こります。コミュニケーションとは相手(システム)が分かる言葉(文字コード)でやりとりする必要があります。
また文字コードには何種類もありますが、ここでお話しするのは大きく3種類です。
- ASCII:英数文字と半角の記号だけの文字コードです
- UTF-8:世界中で標準的に利用されている文字コードで、日本語・ハングルなどいわゆる半角で表現できない文字を取り扱うことができます
- Shift-JIS(以後SJISと表記):最初?に日本語に対応した文字コードですが、現在では非常に日本のエンジニアを困らせています。
MAGELLAN BLOCKS(および多くのWebアプリケーション)はASCIIおよびUTF-8に対応しています。
そしてこの3つの文字コードは包含関係が存在します。
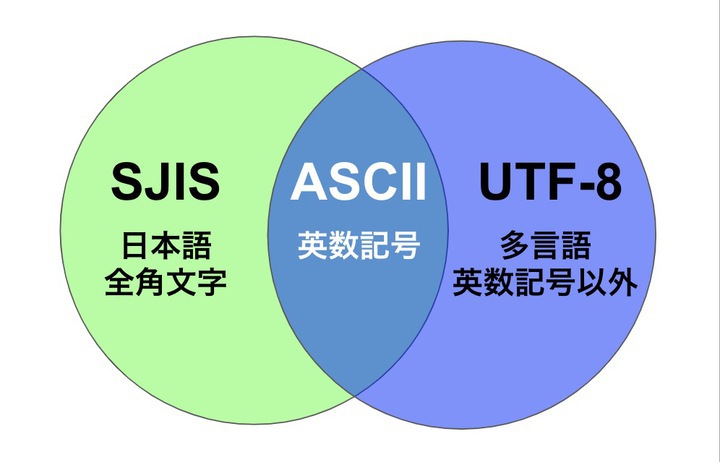
上図で見ていただいたとおり、実は英数記号部分はUTF-8もSJISも同じでASCIIの範囲内何です。
これまでMAGELLAN BLOCKSのハンズオントレーニングに参加いただいた方は、「晴,曇,雨,雪は1,2,3,4にしちゃってください」と言うのを聞いたことがあるかと思います。あれは 英数にすればASCIIなのでUTF-8として取り扱える からなんです。
BOM(ボム)について
BOM(バイトオーダーマーク)は文字コード以上に聞いたことがない人が多いと思います。
ITエンジニアでも知らない人が多いです。これはUTF-8には無くてもいいものなのですが、Microsoft Excelが「BOMが無いとヤダヤダ」とワガママを言うのでちょっと知られてきました。
BOMに関して大事なことは
・ほとんどのUTF-8対応アプリケーションはBOMがいらない
・Excelが出力したUTF-8のCSVはBOMが付いている
ちなみにBOMは何のためのものかと言うと覚えなくてもいいのですが、UTF-16のような1文字が2Byteのデータで、1Byte目と2Byte目のセットの仕方をどっちの順にするかを表現している制御データです。(例えば "か" という文字を "KA" と表現するか "AK" と表現するかのようなもの)
実際のデータで見ると
こちらは読み飛ばしてもらっても構いません。「実際どうなってるの?」が知りたい人向けです。
CSVファイルのヘッダーのイメージで "key,あ" というデータがあった場合には下図のようになります。
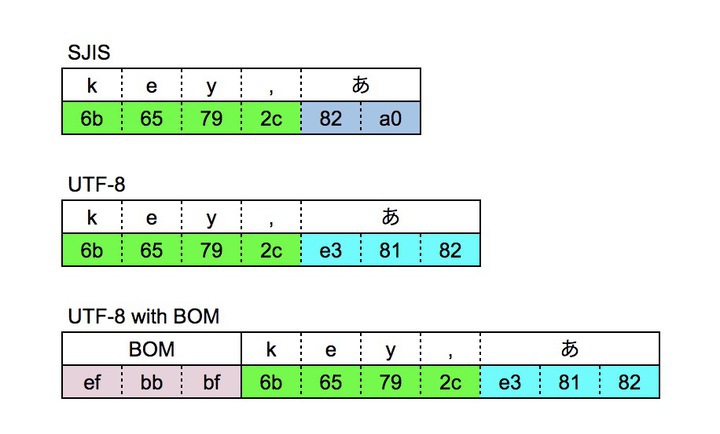
見ていただくと緑色の "key," のASCII部分は同じコードになっていると思います。MAGELLAN BLOCKSおよび多くのUTF-8対応アプリケーションでは、上図の中段のデータを期待しています。
なお Windowsのメモ帳は絶対使っちゃダメ なやつです。
UTF-8 → 本当はBOM付きUTF-8/Unicode → 本当はUTF-16 Little Endian/Unicode big endian → UTF-16 Big Endianとなっていて、かなり混乱させるような表現であり、しかもBOMなしUTF-8が使えないという残念さです。
それでは、実際にBOMの付いていないUTF-8のデータを、どのように作っていくかをご案内します。
BOMなしUTF-8のCSVファイルを作る方法
元データがExcelで、BOMなしUTF-8のCSVファイルを作る方法は、大きく下記の5つの方法があります。
- データに日本語を入れない
- Googleスプレッドシートに変換する
- シフトJISからUTF-8へ変換ブロックを使う
- コマンドラインツールを使う
- コマンドラインツールをCloud Shellで使う
1.データに日本語を入れない
ここまで読んでいただいた方には、方法って言うほどでもないのはおわかりいただけると思います。
日本語が入っていないデータ(英数半角記号)のデータはASCIIですが、UTF-8でもあるのでそのままExcelから名前をつけて、CSVとして保存してもらって大丈夫です。
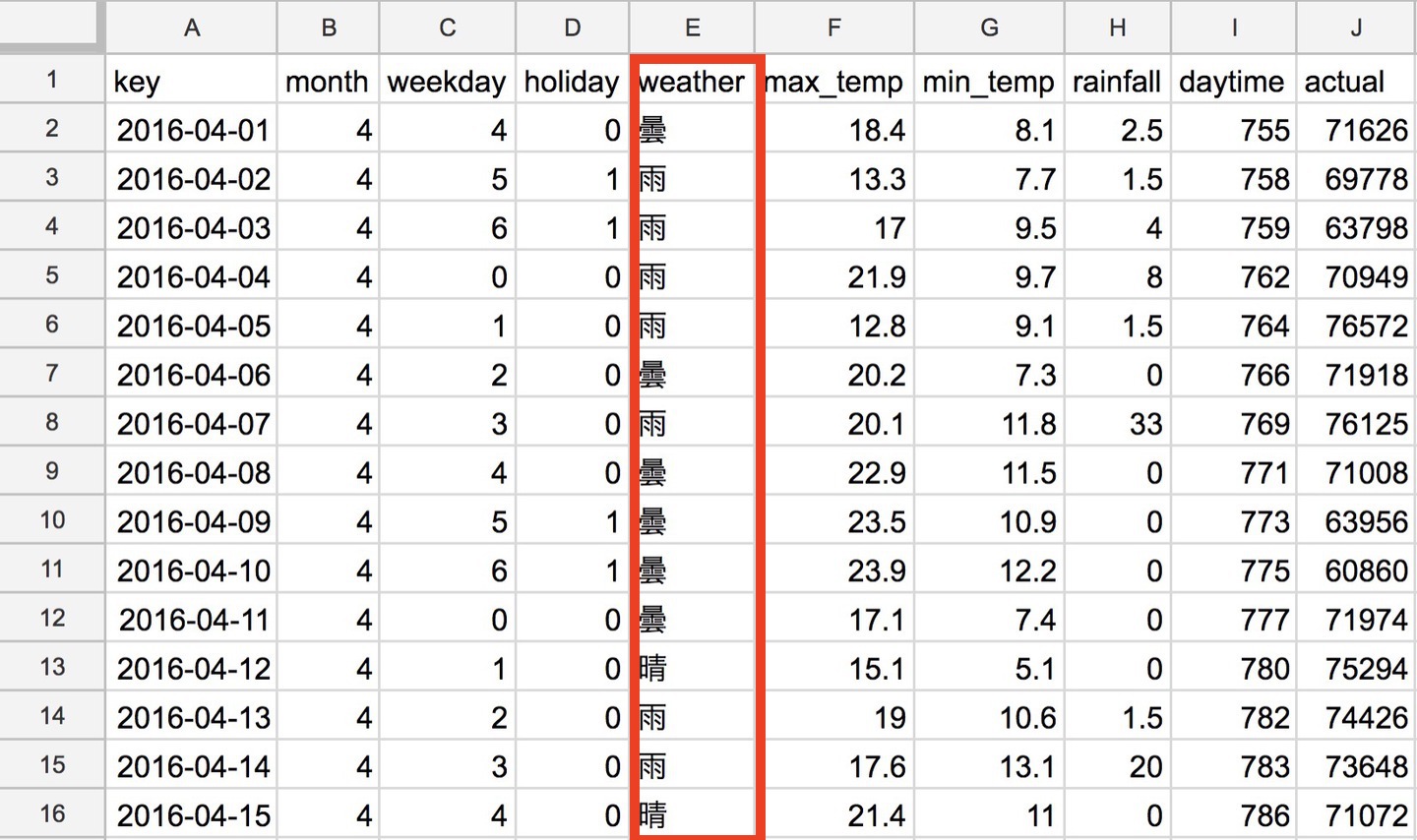
2.Googleスプレッドシートに変換する
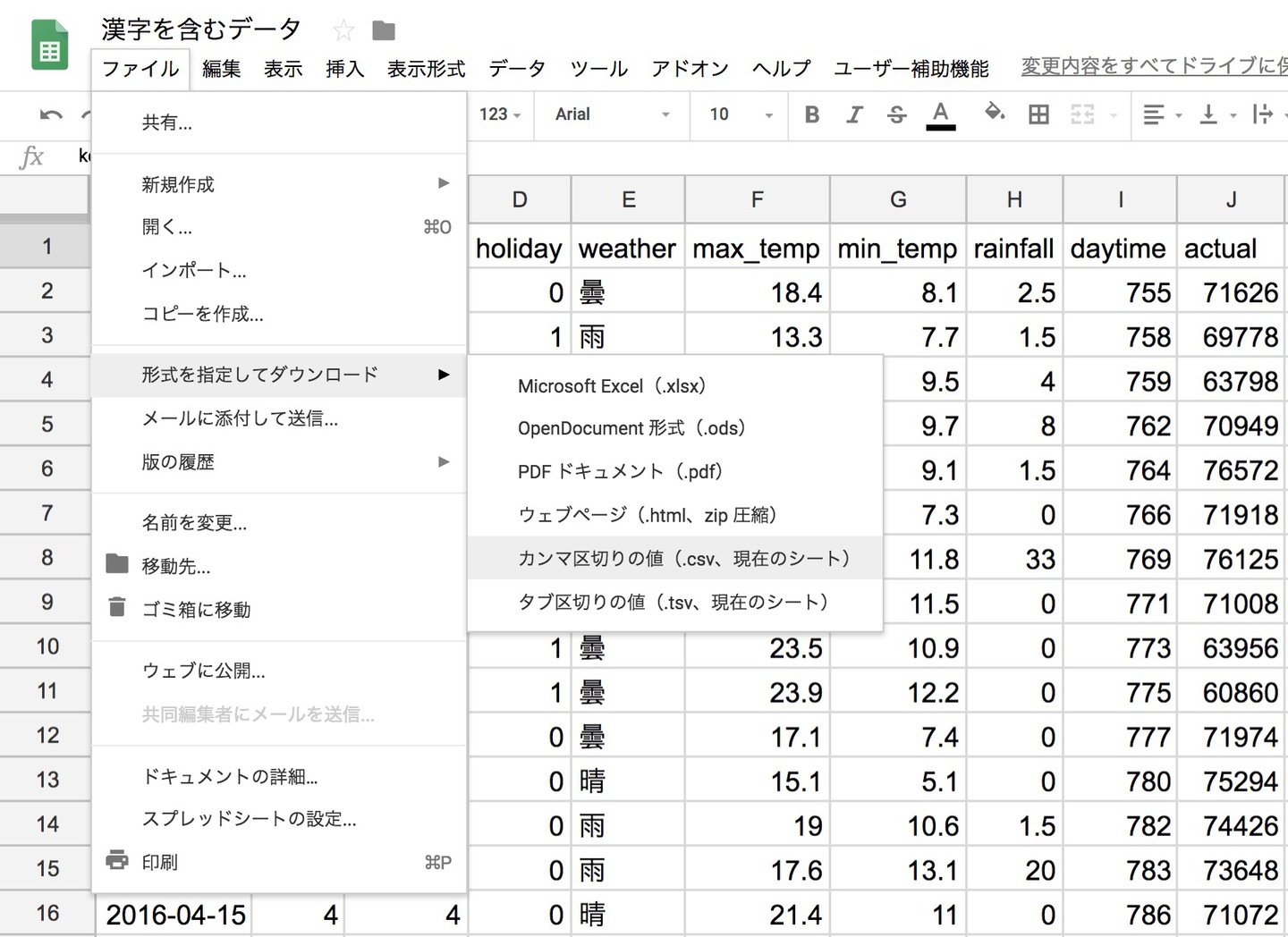
電力需要予測の時にもチラッと書きましたが、Googleスプレッドシートにインポートすると自動的に文字コード変換してくれます。
あとは、形式を指定してダウンロードの中からカンマ区切りの値を選択すると、BOMなしUTF-8のファイルがダウンロードできます。
3.シフトJISからUTF-8へ変換ブロックを使う
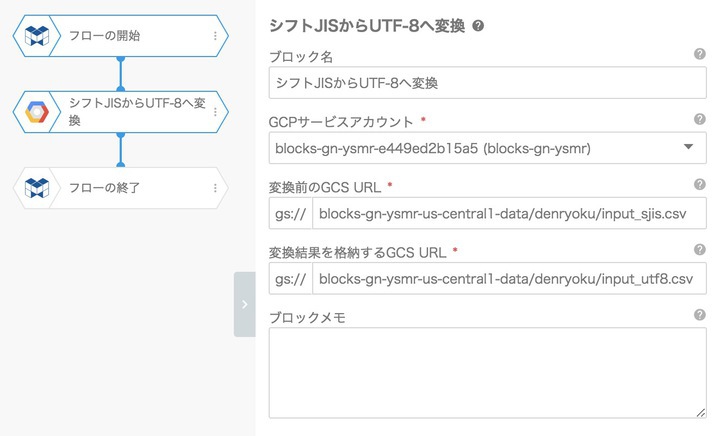
MAGELLAN BLOCKSのフローデザイナーに シフトJISからUTF-8へ変換ブロック というブロックがあります。
こちらを使うと、シフトJISからUTF-8のBOMなしに文字コードを変換してくれます。ただし、ファイルのサイズ制限が 10MB以下 となりますのでご注意ください。
4.コマンドラインツールを使う
若干エンジニア寄りにはなるかと思いますが、実は一番手軽な方法です。
主要なものとして iconv と nkf というコマンドがあります。筆者自身は、iconvの方がUnix/Linuxならどこでも入ってるので使い慣れてます。Windowsでインストール可能な方は調べてみてください。インストールが難しい方は、この後の方法を利用していただければと思います。
iconvの使い方
# SJIS->UTF-8
iconv -f CP932 -t UTF-8 denryoku_utf8.csv
# UTF-8->SJIS
iconv -f UTF-8 -t CP932 denryoku_cp932.csv
nkfの使い方
# SJIS->UTF-8
nkf --ic=CP932 --oc=UTF-8 denryoku_sjis.csv > denryoku_utf8.csv
# SJIS->UTF-8
nkf --ic=UTF-8 --oc=CP932 denryoku_utf8.csv > denryoku_sjis.csv
ここでさらっと CP932 とのを出してしまいましたが、CP932とはSJISの拡張された文字コードとお考えいただいて差し支えありません。いわゆる丸で囲った数字やギリシャ数字など、本来SJISでは存在しない文字に対応します。(逆に言えば、WindowsでShift-JISって書いてあってもCP932のことです。)
5.コマンドラインツールをCloud Shellで使う
このブログを読んでくださっている方は、ほぼGCPを触れる環境にある方だと思います。
GCPのコンソールから、Cloud ShellというLinuxの環境を利用することが可能です。Linuxの環境なので、先ほど紹介した iconvが使えます。ただ、目的のテキストファイルCloud Shellから触るためにGoogle Cloud Storageからコピーを行います。
まずは、Google Cloud Consoleにアクセスします。
その後、画面右上のCloud Shellのアイコンをクリックします。
Cloud Shellが、Console画面の下側に表示されます。黒い部分ですね。
ここの黒い所の中だけLinuxとして動いているようなイメージです。
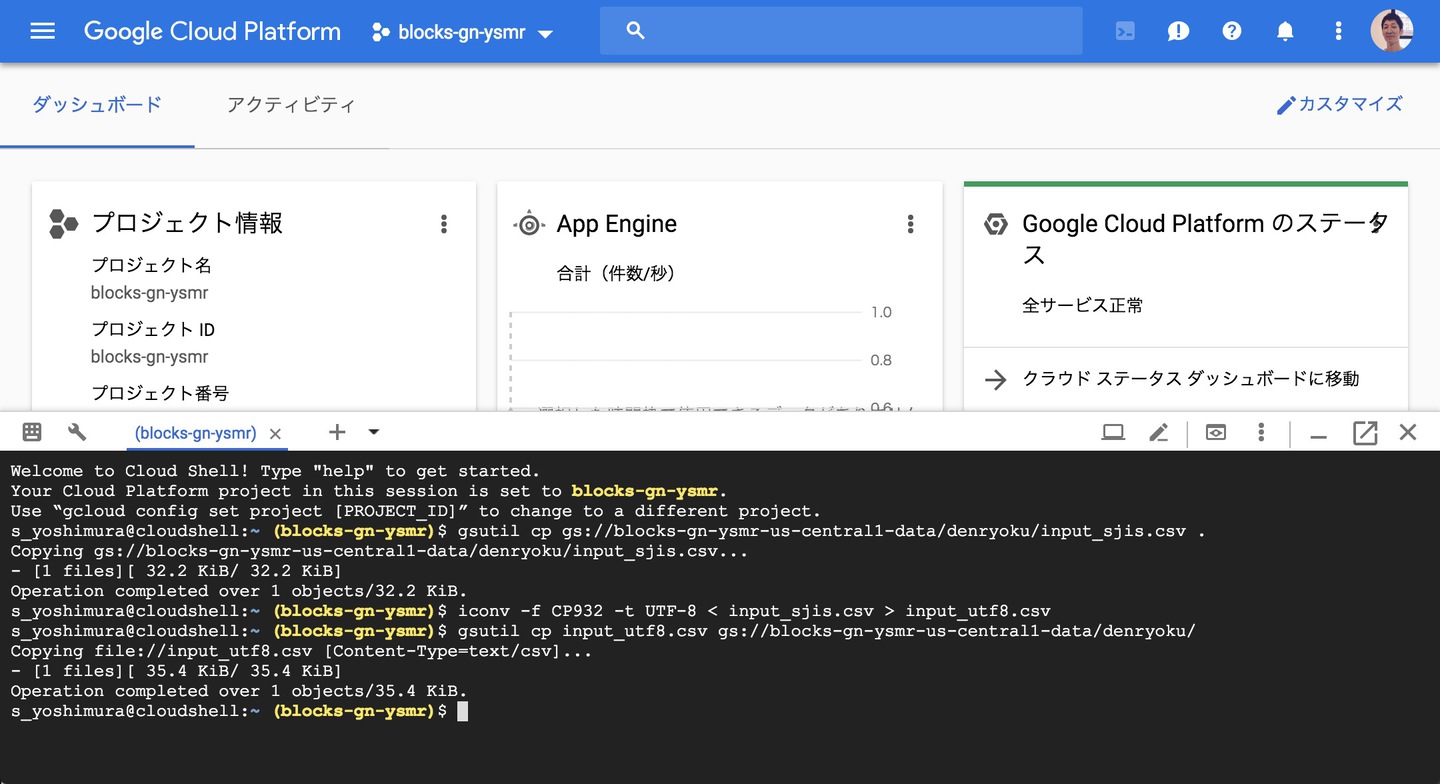
この黒い画面のところで、下記のようにファイルのコピーと変換を行います。
# GCSからテキストファイルを手元にコピーする
gsutil cp gs://blocks-gn-ysmr-us-central1-data/denryoku/input_sjis.csv .
# SJIS->UTF-8
iconv -f CP932 -t UTF-8 denryoku_utf8.csv
# 変換後のファイルをGCSへコピーする
gsutil cp input_utf8.csv gs://blocks-gn-ysmr-us-central1-data/denryoku/
実際に操作すると、このようなイメージになります。
ここまで案内してきたように、MAGELLAN BLOCKS(だけじゃないですが)で使われるUTF-8のファイルを準備する方法はたくさんあります。
「文字コードが出てきた!ややこしい!無理!」ってならず、ひとつずつやれば難しくないのでぜひ試してもらえたらと思います。
※本ブログの内容や紹介するサービス・機能は、掲載時点の情報です。