前回は、Googleスプレッドシートを用いて、気象庁と天文台と東京電力パワーグリッドのデータをもとに、機械学習させるためのデータセットを作るところまでをやりました。
- 課題をブレイクダウンし問題を式にする
- 何を予測・判定するのか決定する
- 業務での使い方を考える
- データを準備する
- 学習・予測・評価する
この順序でいうと、「4. データを準備する」のところまでですね。
続いて、学習・予測・評価へ進みますが、その前に今回のデータにどのような傾向があるか見てみましょう。
せっかくなので、MAGELLAN BLOCKSの中でも、最近イチオシのDataEditorを使ってみます。

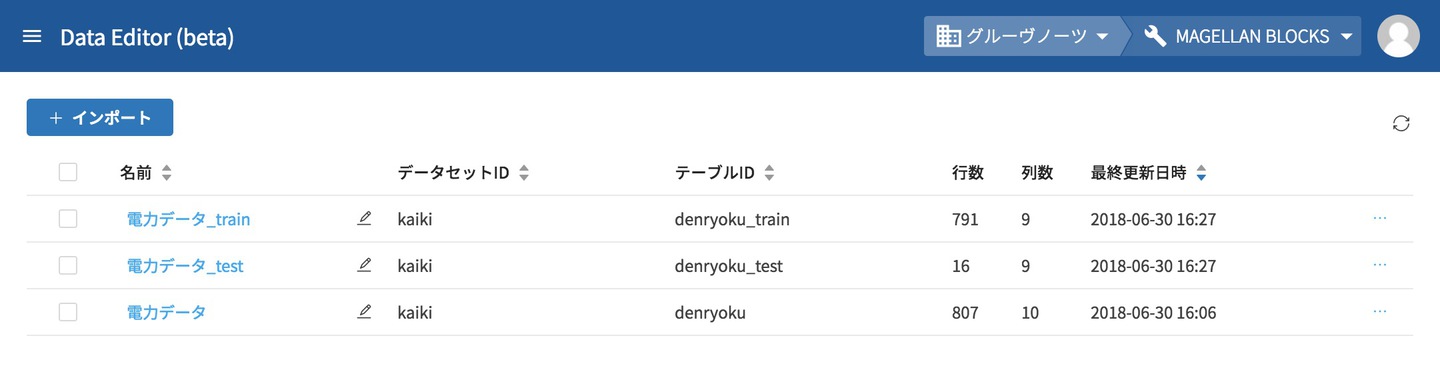
グローバルナビゲーションからDataEditorを開くと、初めに下のようなDataEditorのメイン画面が表示されます。
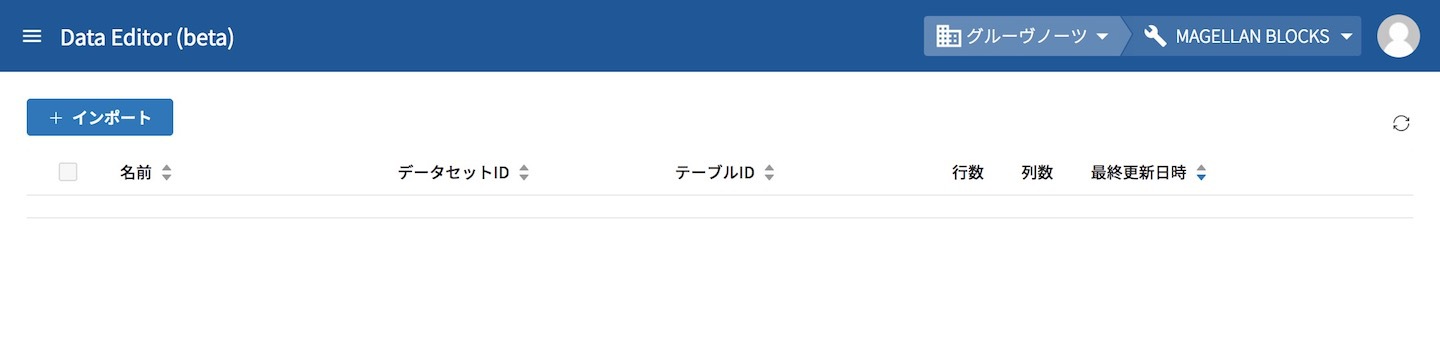
このDataEditorの機能は、痒い所に手が届く機能を随所に散りばめてくれていて、どんどん使いやすくなっています。弊社コンサルタントが相談する「こうなったら嬉しい」もたくさん取り込んでもらっています。
前回の1回目で作成したGoogleスプレッドシートをインポートするところから進めていきます。
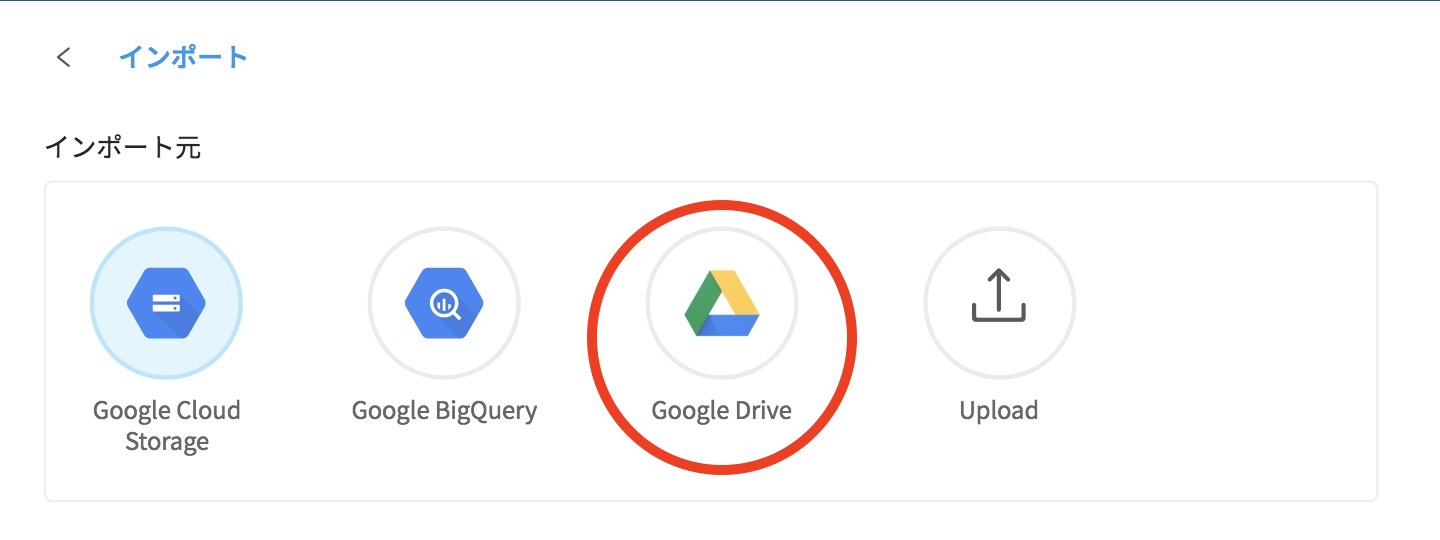
最初に、DataEditor画面の「+インポート」をクリックして、そのインポート画面からインポート元の中のうち「Google Drive」を選択します。

次に、Googleスプレッドシート側にMAGELLAN BLOCKSからアクセス可能にする設定を行います。
DataEditor インポート画面のうちGCPサービスアカウント項目で、GCPサービスアカウントの右側にあるアイコンをクリックすると、設定に必要なメールアドレスをコピーすることができます。
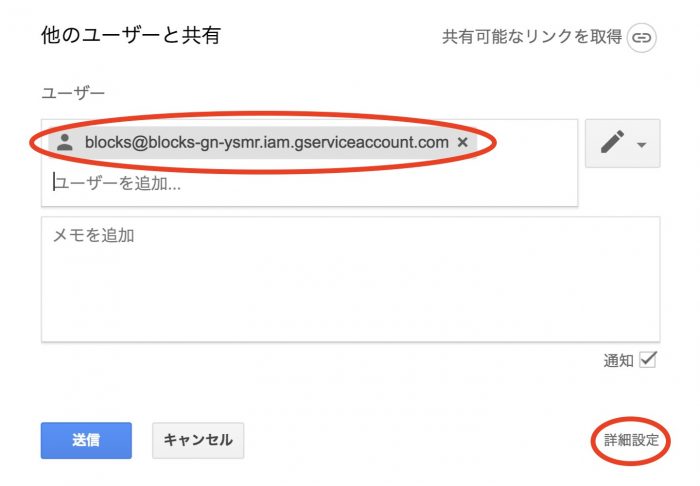
続いて、Googleスプレッドシート側で共有の設定を行いますので共有をクリックします。

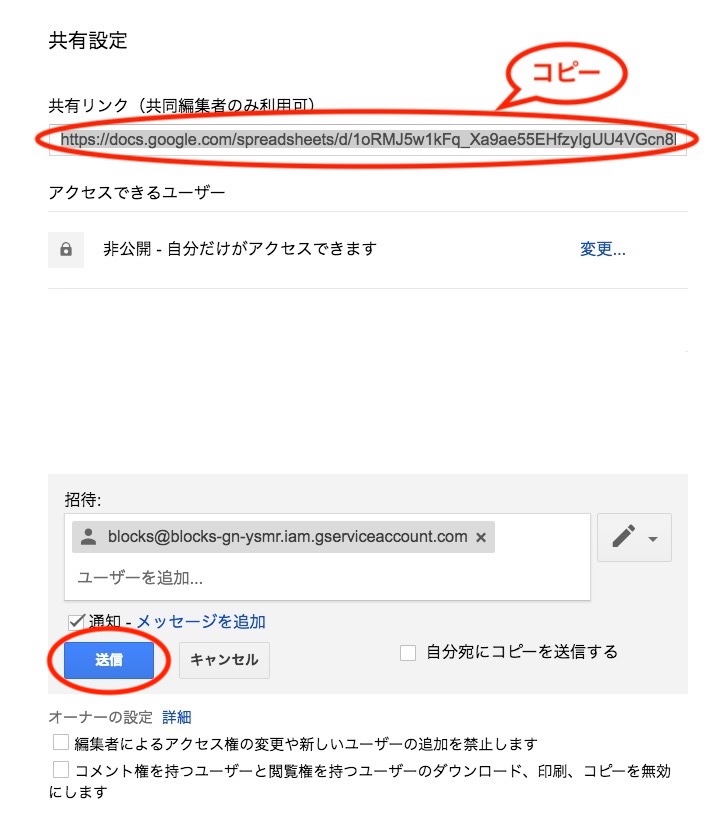
Googleスプレッドシート上で他のユーザーと共有の画面が表示されるので、コピーしたサービスアカウントのメールアドレスを貼り付けます。次に他のユーザーと共有の詳細を押して、共有リンクをコピーします。完了を押せば、これでMAGELLAN BLOCKS側からこのGoogleスプレッドシートにアクセスすることができます。
ではDataEditorのインポート画面に戻って、インポートの続きです。
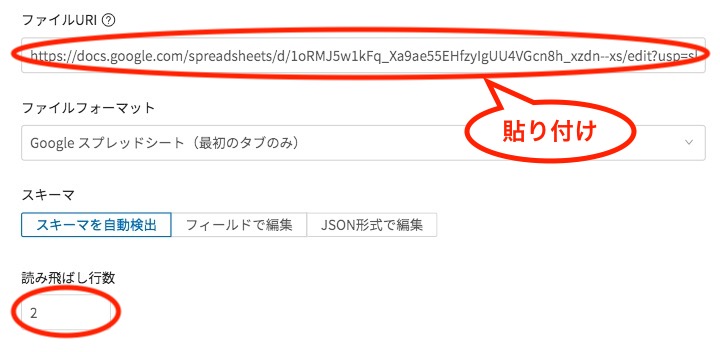
先ほどコピーしたGoogleスプレッドシート共有リンクを、DataEditorのファイルURIの項目に貼り付けます。
次に、読み飛ばし行を、今回2行にしているので合わせて 「2」にします。
DataEditor インポート画面の最後では、インポート先を指定します。
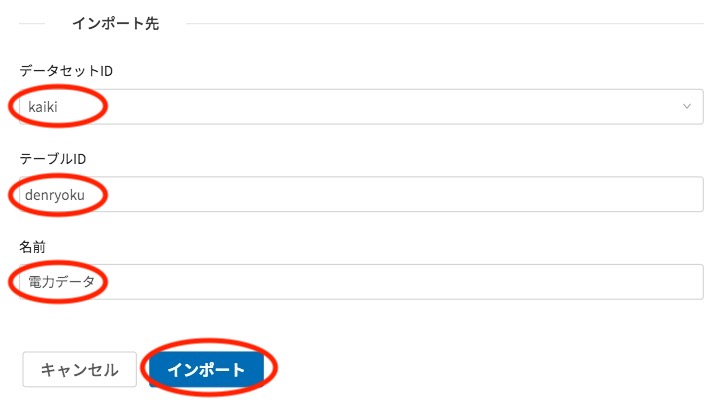
データセットIDとテーブルIDと名前を入力してインポートをクリックすると、DataEditorにインポートされます。
インポートされると、DataEditorメイン画面の一覧に対象のデータが表示されます。

DataEditorメイン画面から、「名前」をクリックするとテーブルの中身をみることができますが、ここでは、データを表示・グラフを表示をクリックしないと見えないようにしています。これは、いきなり大量データを見るとBigQueryの課金が意図せず発生するのを防ぐためです。せっかくなので、傾向を見ようと思います。
データ表示をするためには、右のように赤枠にある、データ探索のアイコンをクリックします。すると、集計の行列を指定する画面が表示されます。
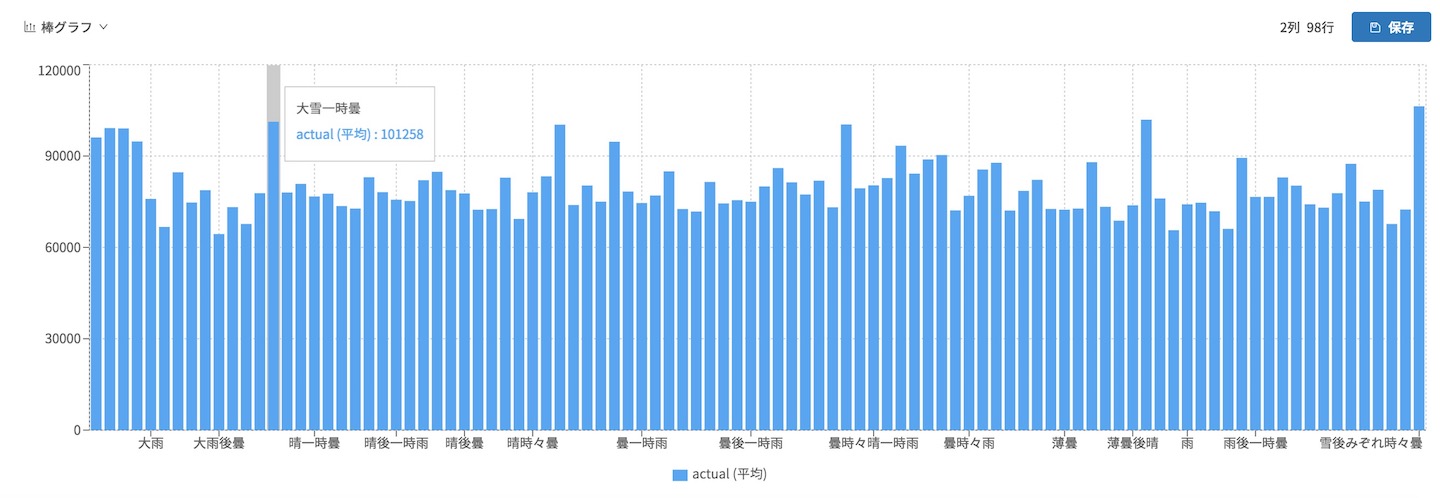
ここで列に天気、行に実績の平均を設定します。
表示のボタンをクリックすると、一旦は表形式で表示されます。
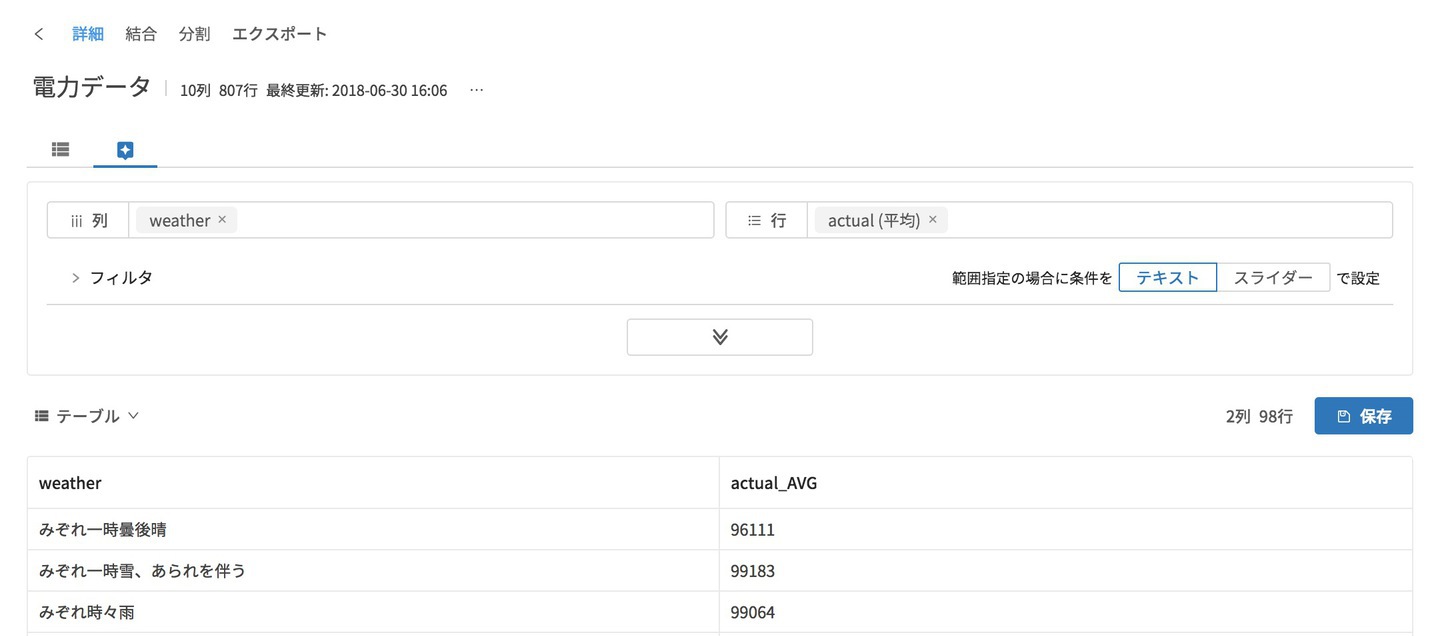
テーブル形式から棒グラフに切り替えると、こんな感じです。だいたい同じですが、ちょいちょい平均電力使用料の多い天気がありますね。
さて、このデータを学習データと予測データに分割します。
DataEditor画面上側の分割をクリックします。すると分割の設定画面が表示されます。
今回は下記のように分割したいと思います。
- 学習データ:2016/04/01〜2018/05/31
- 予測データ:2018/06/01〜2018/06/16
それに合わせて条件を設定します。
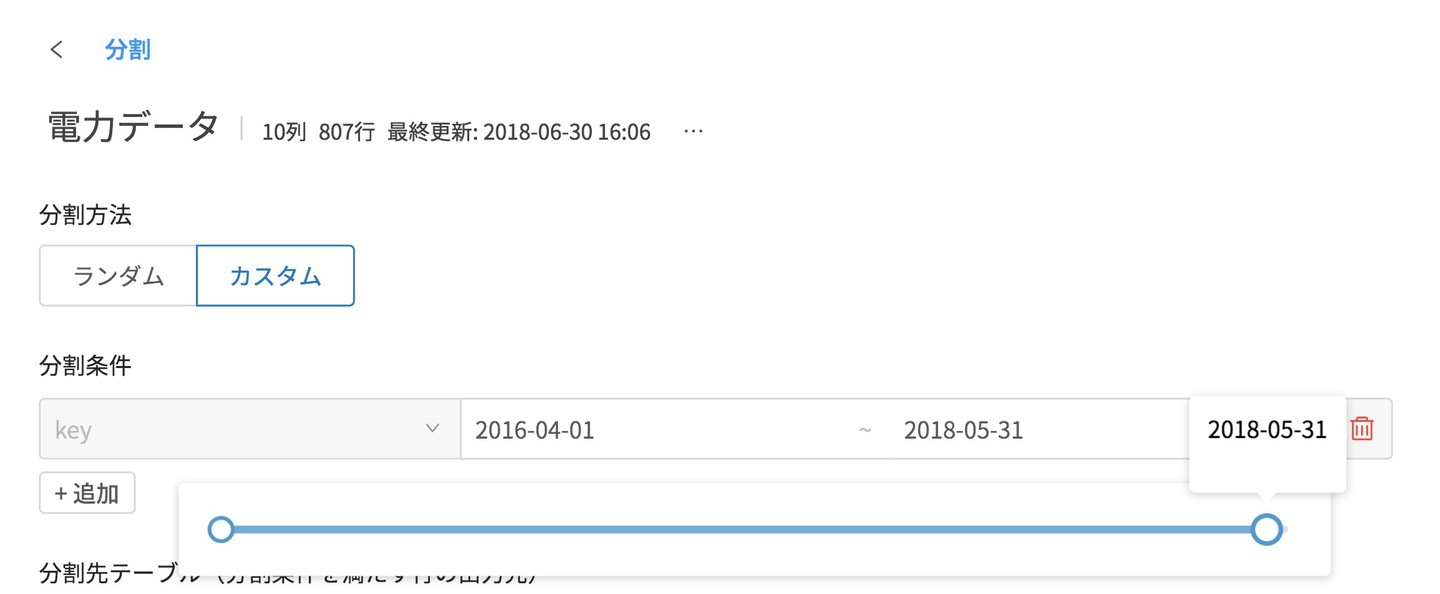
まずは分割方法をランダムからカスタムにし、分割条件の項目にkeyを設定します。
keyを設定した後で右側にあるフィルタアイコンをクリックすると、現在入っている日付の範囲とスライドバーが表示されます。
そこからスライドバー右の丸を動かして、学習データを2016/04/01〜2018/05/31へ変更します。
次に、学習データ(条件を満たすデータ)の項目と予測データ(条件を満たさないデータ)の項目を設定します。
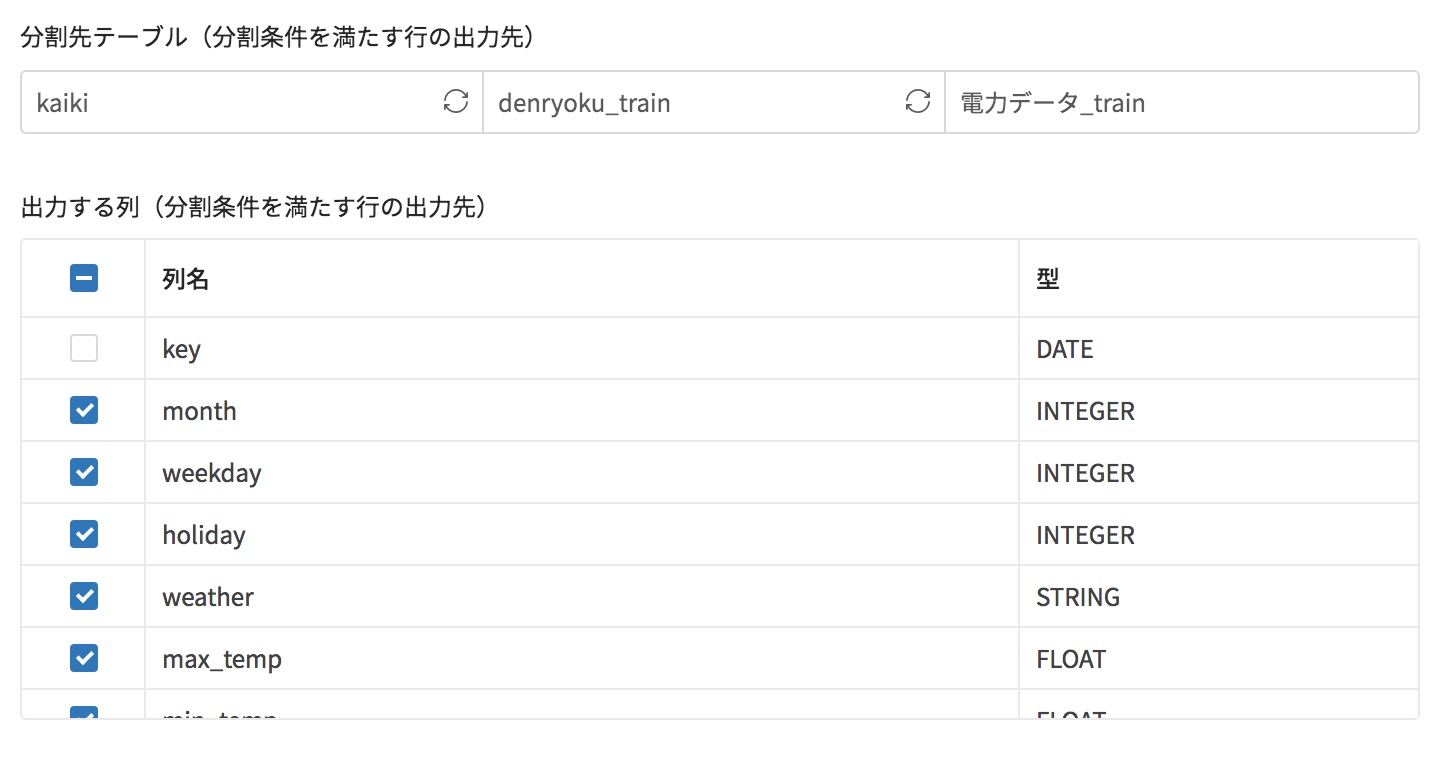
学習データは予測因子・学習対象として、不要な先頭のkeyのチェックを外します。
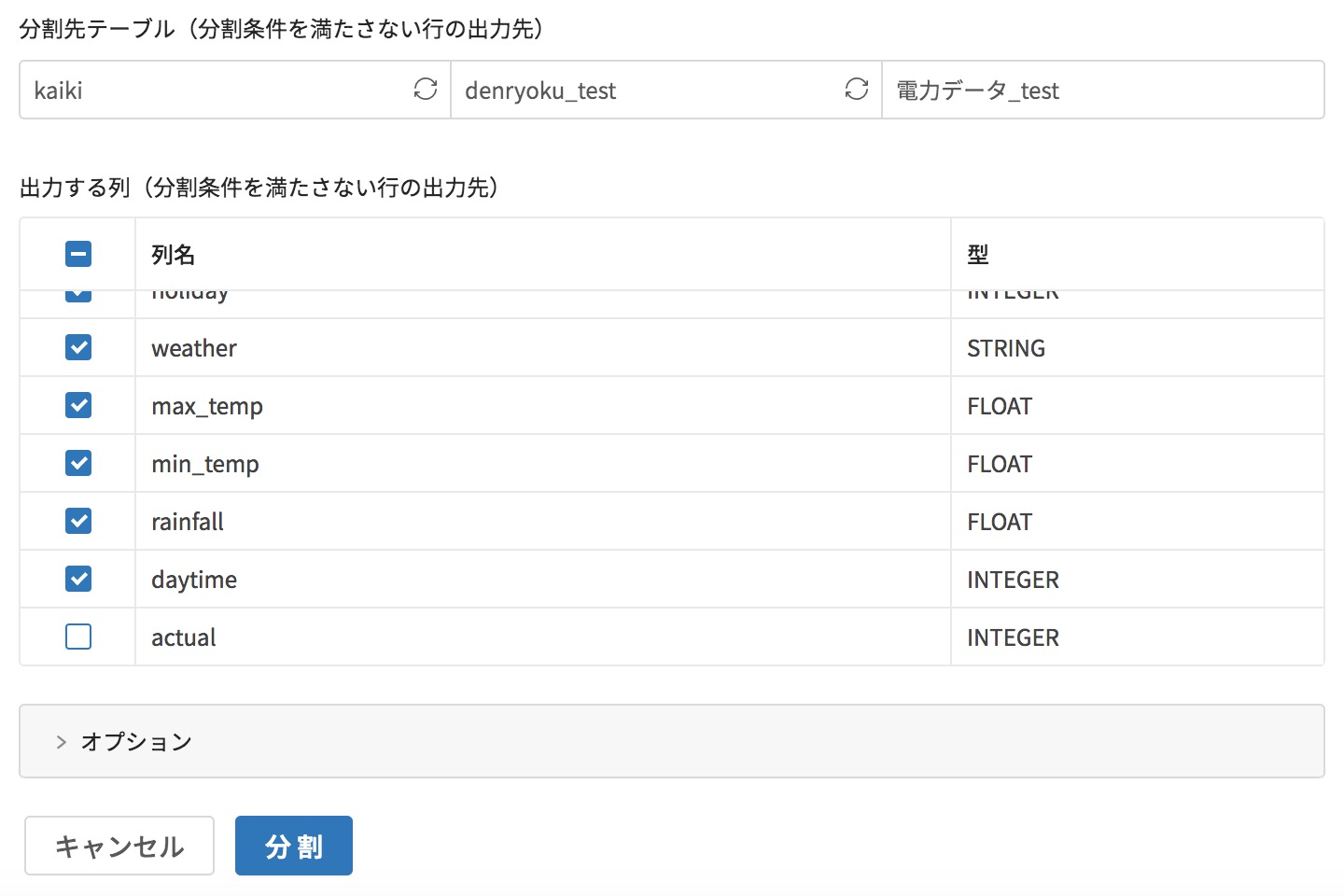
予測データは予測時に実績情報は不要なので、末尾のactのチェックを外します。
あとは、一番下の分割をクリックすると、もとのDataEditorのメイン画面で、分割された2つのテーブルが作成されます。
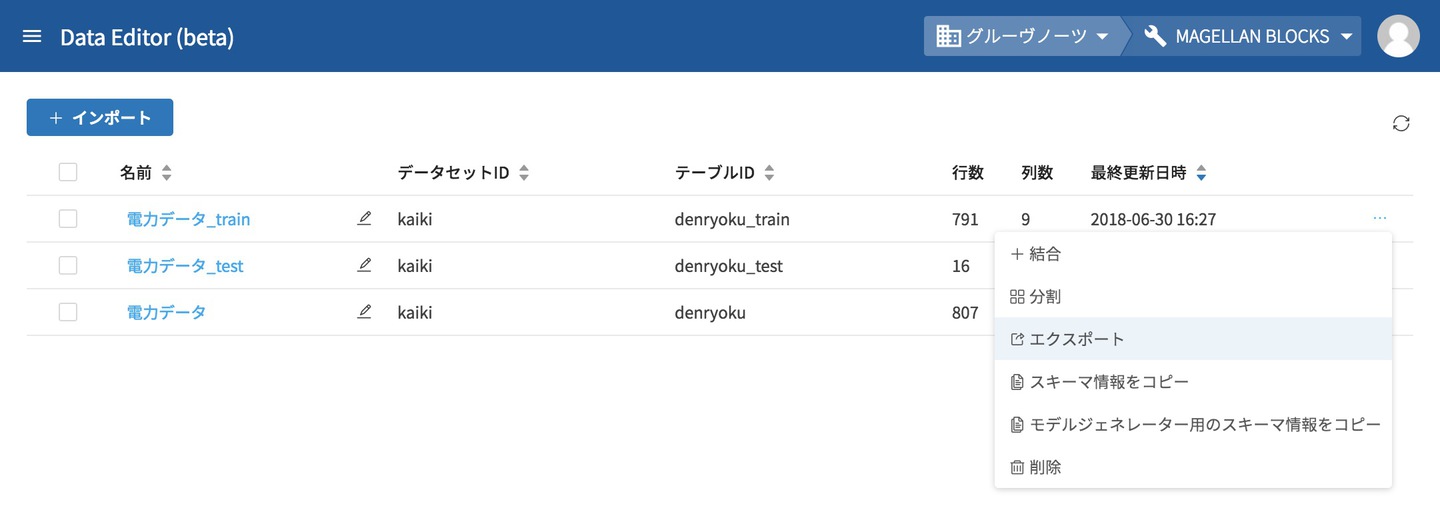
最後に、モデルジェネレーターはCSVファイルをもとに学習するため、電力データ_trainをエクスポートします。対象のデータテーブルの一番右の点々からエクスポートを選択します。
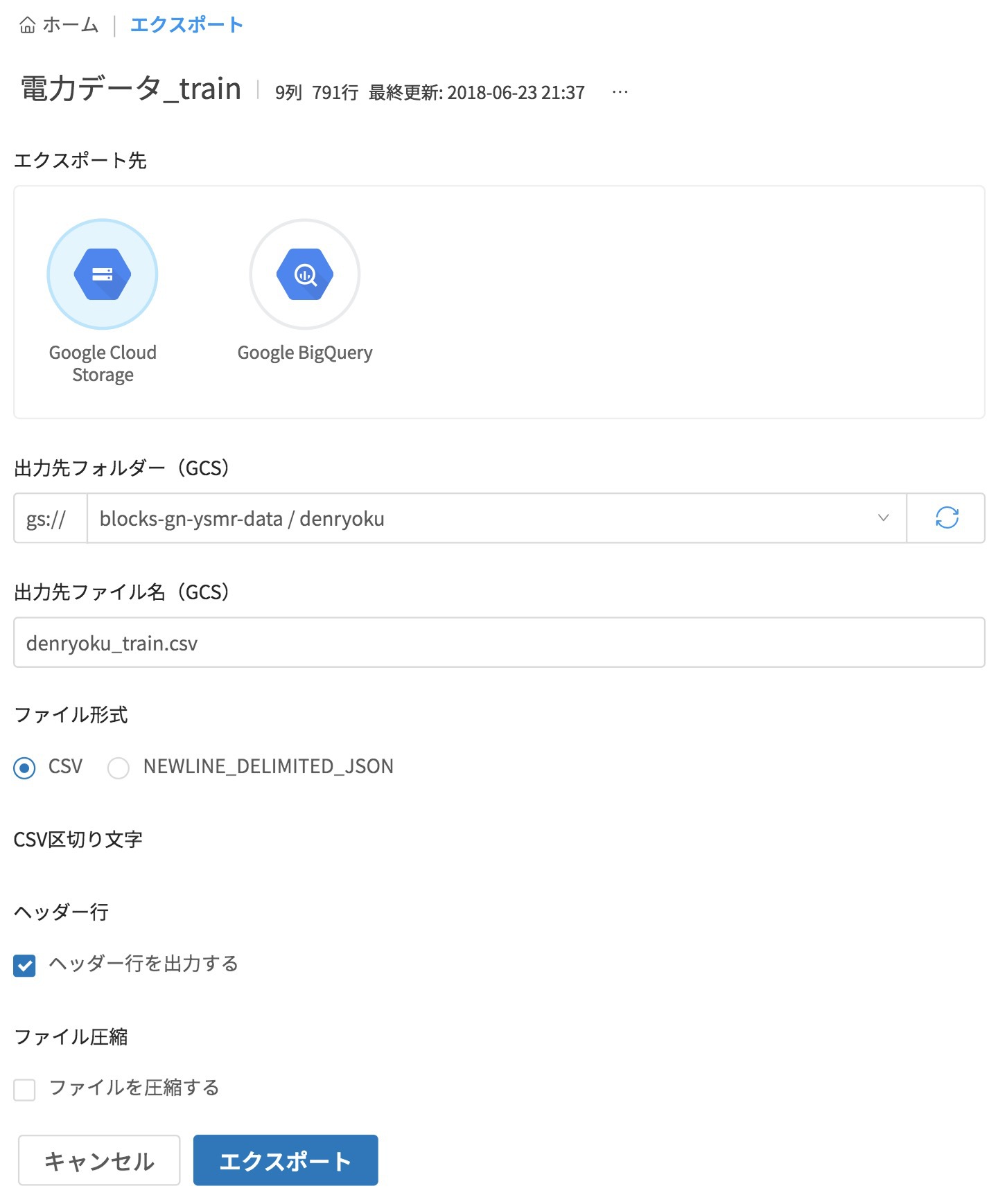
エクスポートは、エクスポート先のGCS上の場所を選択します。
あとはエクスポートをクリックするだけです。
これで、モデルジェネレーターでモデルを作るために学習させるCSVファイルが準備できました。説明は割愛しますが、予測用に電力データ_testもエクスポートしておきます。
次回「電力需要予測をMAGELLAN BLOCKSでやってみた(3)」は、モデルジェネレーターを作成しCSVファイルをトレーニングさせてモデルを作るところまでやっていきます。
※本ブログの内容や紹介するサービス・機能は、掲載時点の情報です。