第2回では、DataEditorを使って準備したデータをもとに、学習データと予測データに分割しました。今回はいよいよ、モデルジェネレータに学習データを与えてモデルを作成します。
まずは、メニューからモデルジェネレーターを開きます。
利用開始(2つ目以後は追加)をクリックすると、ウィザードが表示されます。
モデルジェネレーター新規作成でまず、数値回帰タイプを選択します。続いて、①サービス名設定画面で、名前を入力します。名前は、何の目的のモデルを作成したいかと考えてつけると良いです。今回は「電力需要予測」とします。
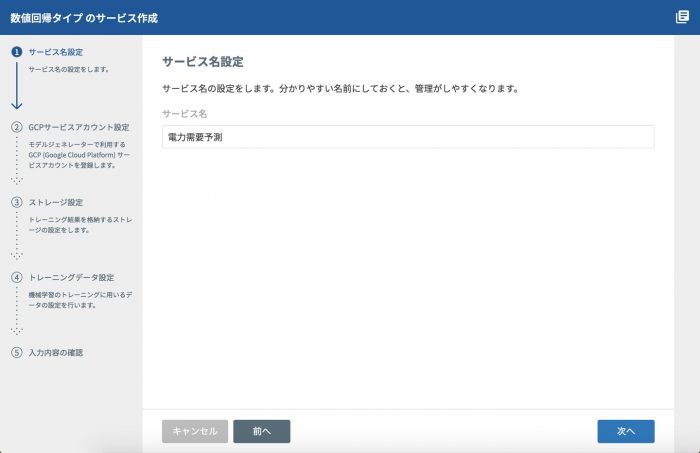
続いて、②GCPサービスアカウント設定画面で、GCPのサービスアカウントを選択します。
このタイミングで必要なAPIが有効になっているかチェックが動きます。今回は新しいGCPの環境を使っているので、Cloud Machine Learning APIが有効になっていません。
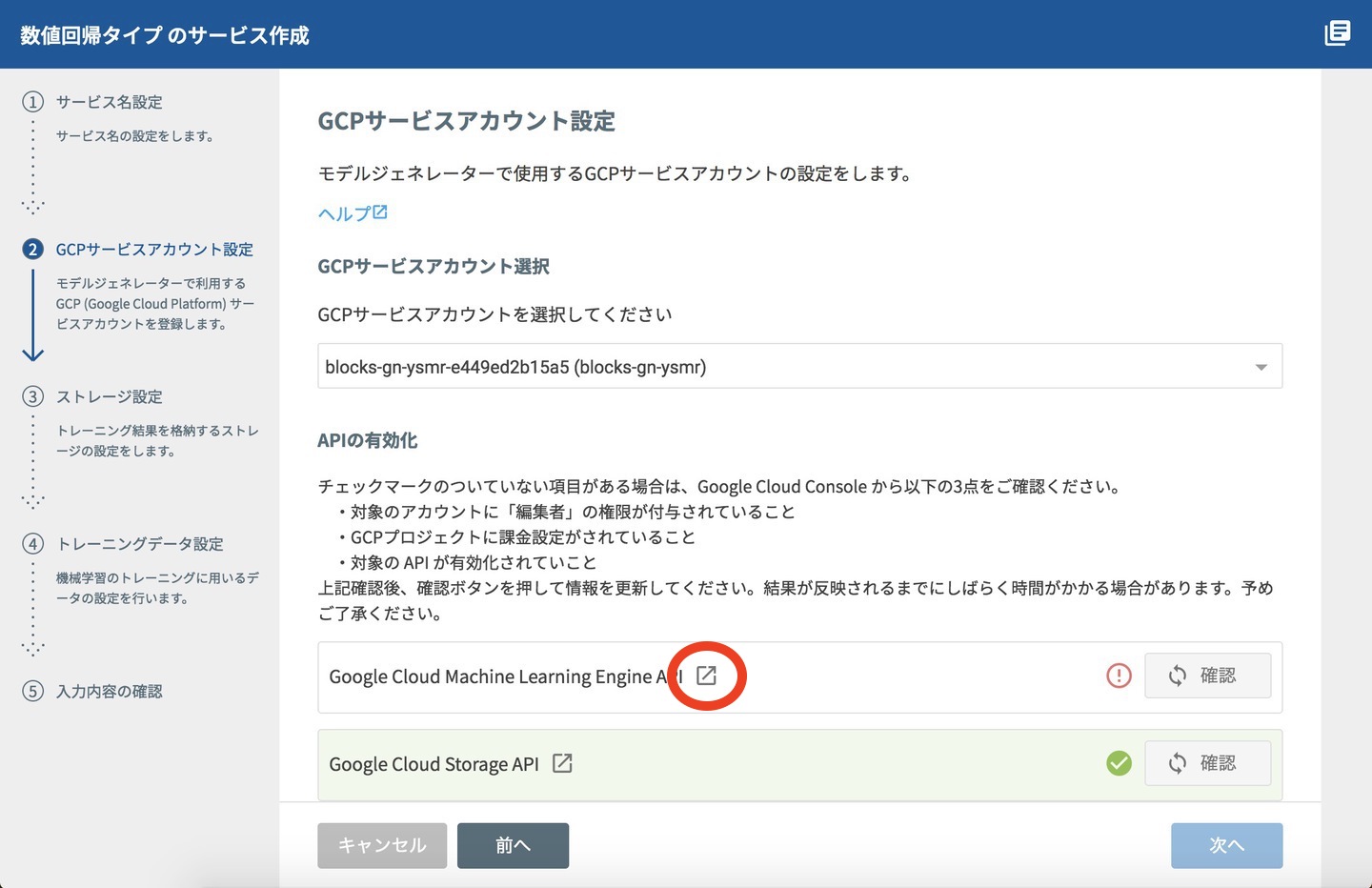
有効にするには、GCPサービスアカウント設定画面の中から、GCPコンソールを開くリンク(Google Cloud Machine Learnig Engine APIの赤丸部分)をクリックします。
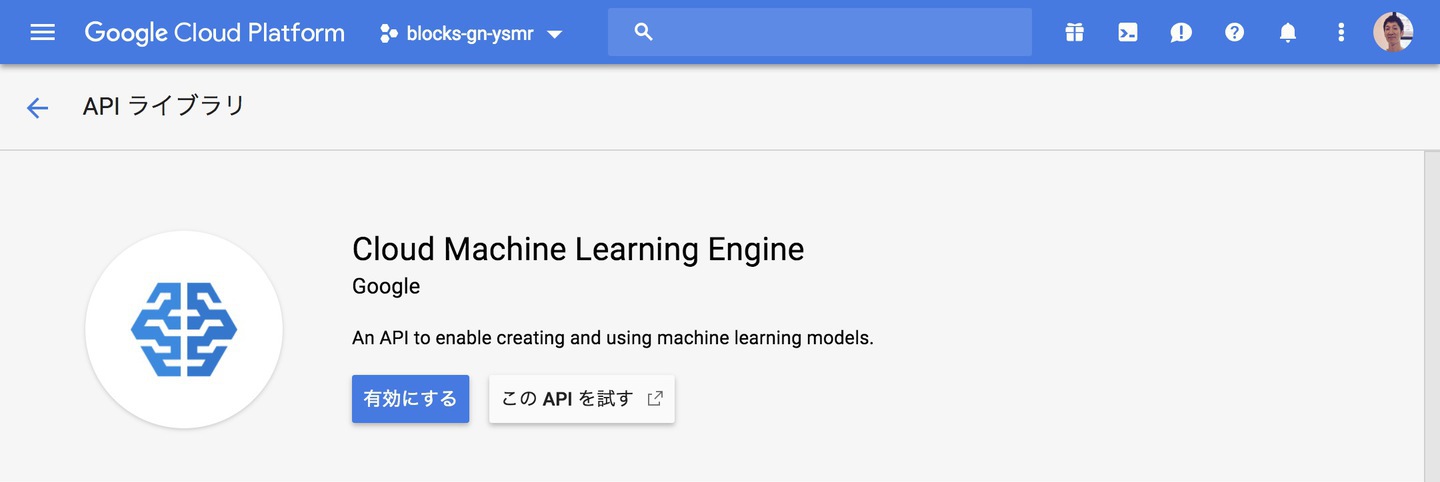
有効/無効を指定するGoogle Cloud Platformの画面が開きますので、「有効にする」をクリックしましょう。この操作は数分かかります。
(もしGoogleアカウントでログインしていない場合は、ログインしてから表示されます。)
有効になったら、モデルジェネレーターの画面で、赤いビックリマークの右にある確認ボタンをクリックすると、もう一度チェックが行われます。有効になったことが確認できたら、次の③ストレージ設定の画面に移ります。
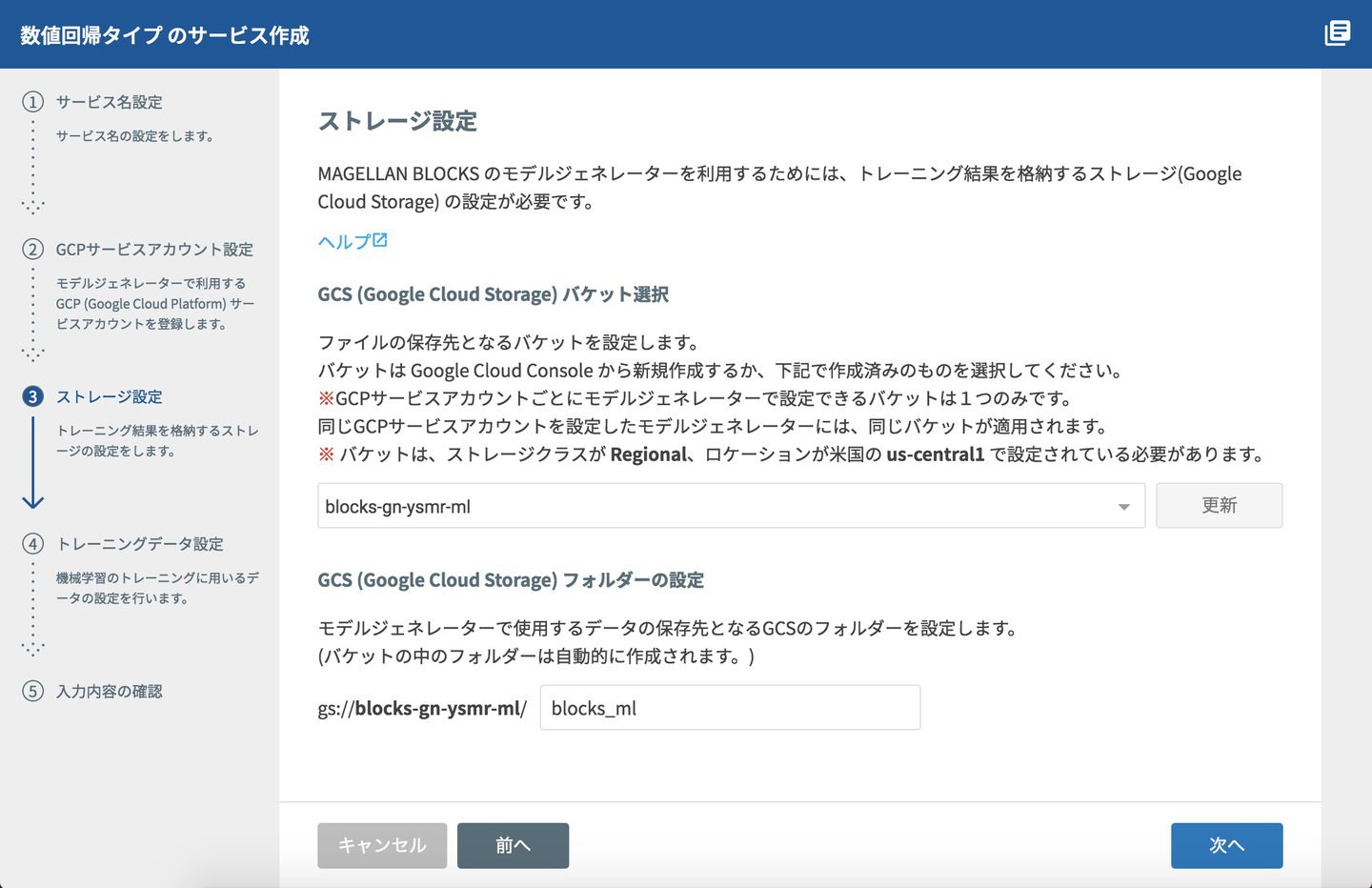
ストレージ設定画面では、モデルが格納されるフォルダの設定を行います。
GCSバケット選択で、バケットを指定して、フォルダ名を入力します。
GCSフォルダーの設定では、フォルダ名はフルサービスプランと同じ「blocks_ml」というフォルダ名前にしました。
ここまでは、お約束みたいな毎回な操作なので慣れですね。フルサービスプランだとGCPの設定はないので、もうちょっとスッキリした流れになっています。
さて、モデルジェネレーターを作成するメインどこまできました。トレーニングデータ設定です。
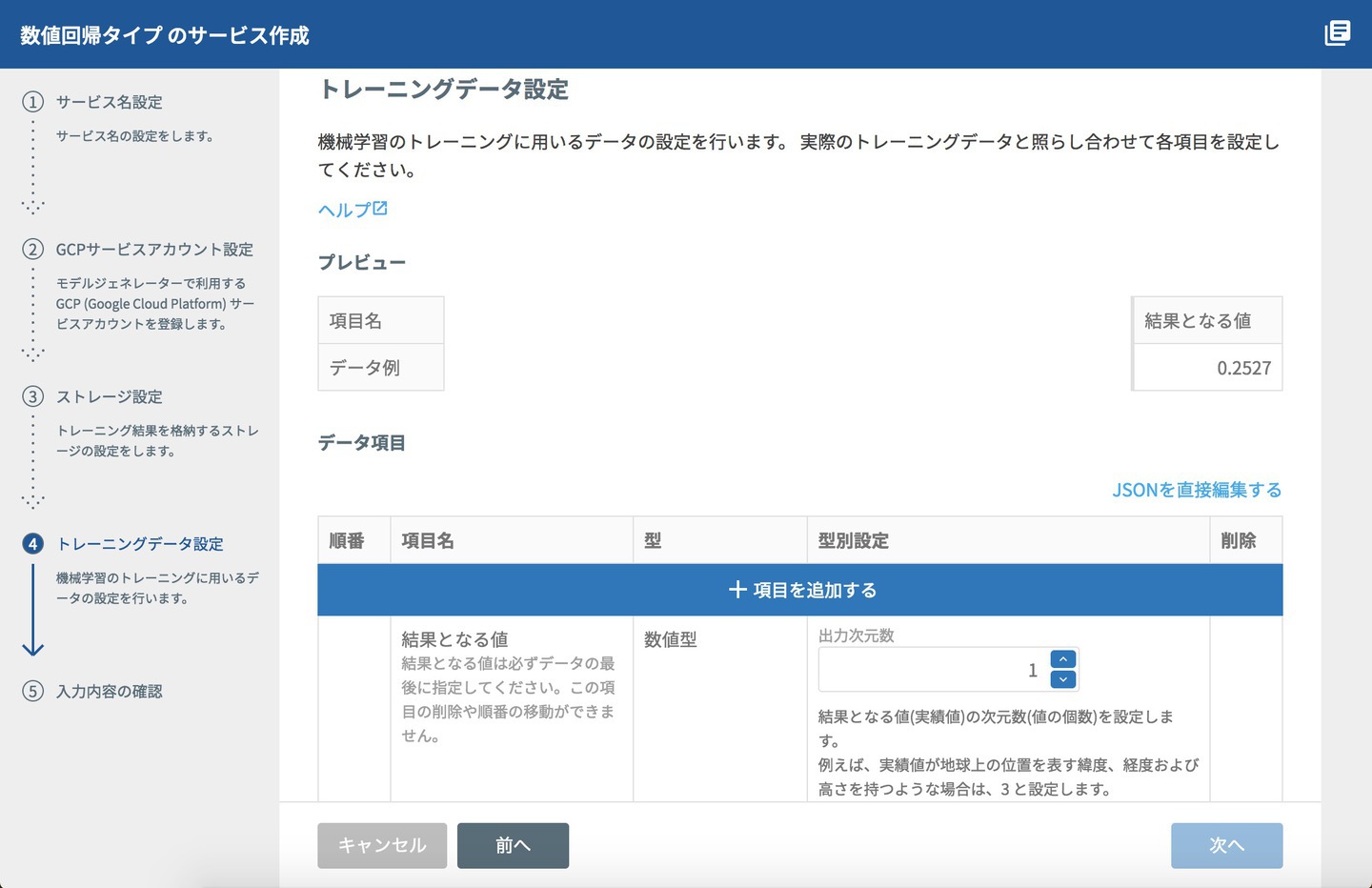
このトレーニングデータ設定画面では、トレーニングさせるデータに対する設定を行います。
モデルジェネレーターは、CSVデータのどの項目が気温や降水量ということは、全く気にしません。ただ「数値か数値でないか」ということを教えてあげる必要があります。これは「1月より2月は2倍大きい」と勘違いさせないためです。
そのためのデータ型には、下記があります。
- 数値型(数値の型)
- 文字列列挙型(数値でない型で、A,B,Cとカンマ区切りで設定)
- 月(文字列列挙のうち、よく使う月を独立)
- 曜日(文字列列挙のうち、よく使う曜日を独立)
- フラグ(文字列列挙のうち、よく使うフラグを独立)
- 時系列型(これは数値型の派生ですが、別の機会にご紹介します)
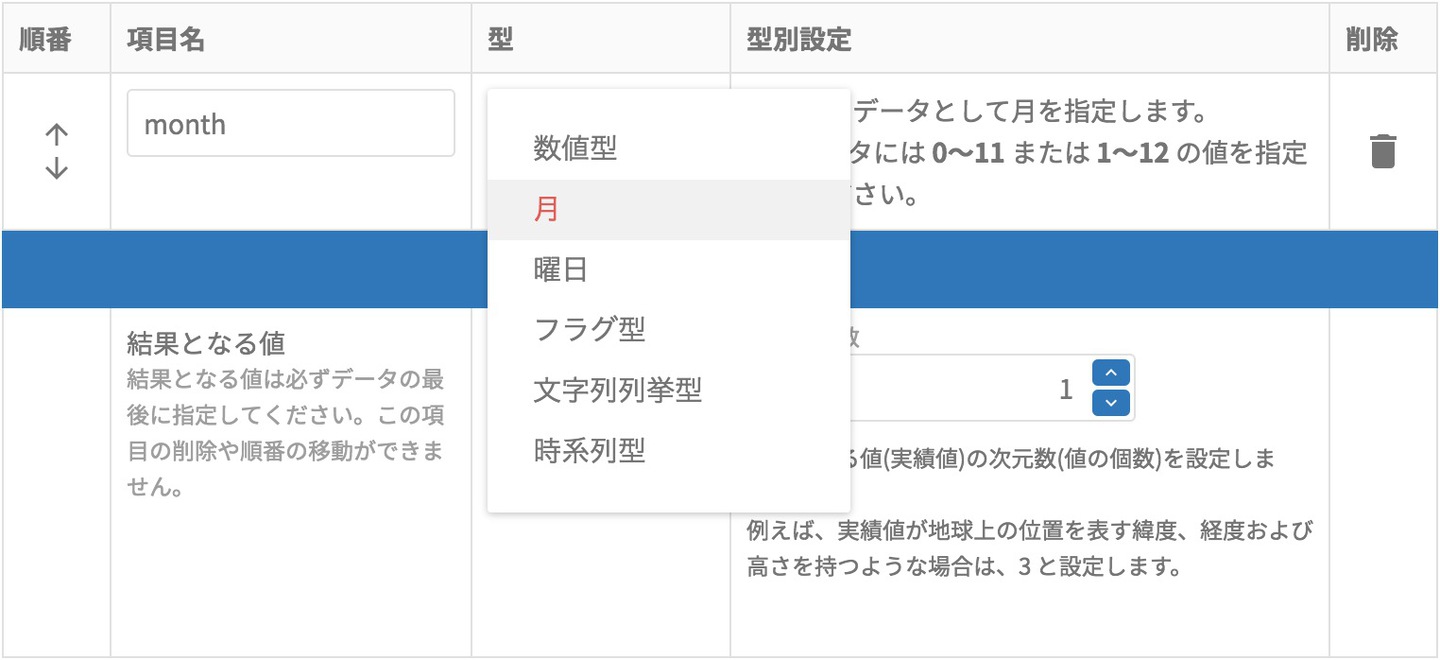
本来は、数値型と文字列列挙型だけでもよいのですが、月・曜日・フラグはよく使うので、型の項目の中でも独立させています。
それでは、データ項目に対して、各項目の設定を行います。
通常は、1つ1つポチポチ入力するのですが、便利な機能があるのでDataEditorを使います。DataEditorでは、電力データ_trainを開きます。下記画面の赤枠にあるweatherのグラフ表示をクリックします。先ほど集計して見た棒グラフが、小さく表示されます。この状態が大事なんです。
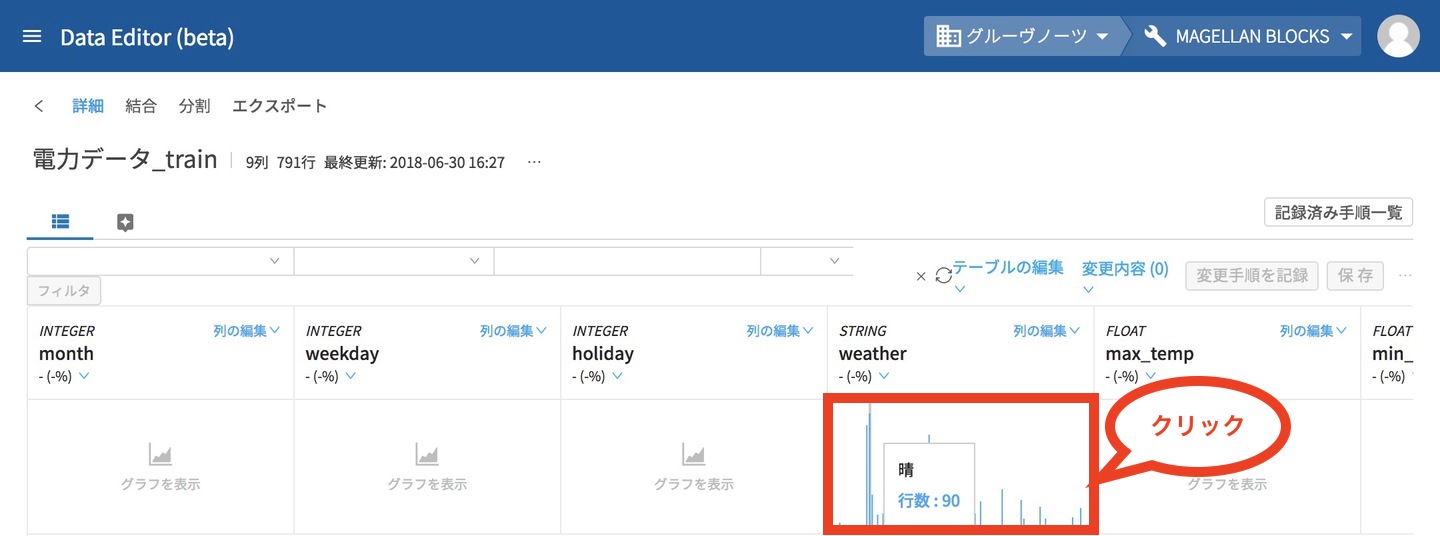
このweatherのグラフが表示された状態で、右上の「テーブルの編集」にある「モデルジェネレーター用のスキーマ情報をコピー」をクリックします。(手順が細かい!でも便利!!)
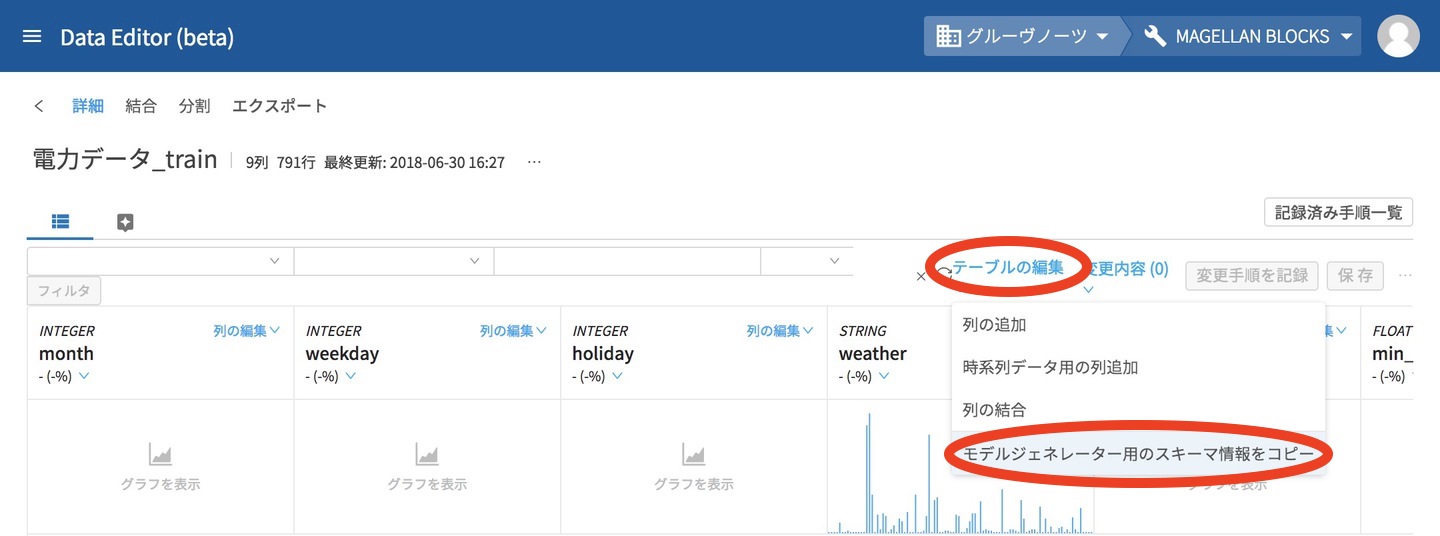
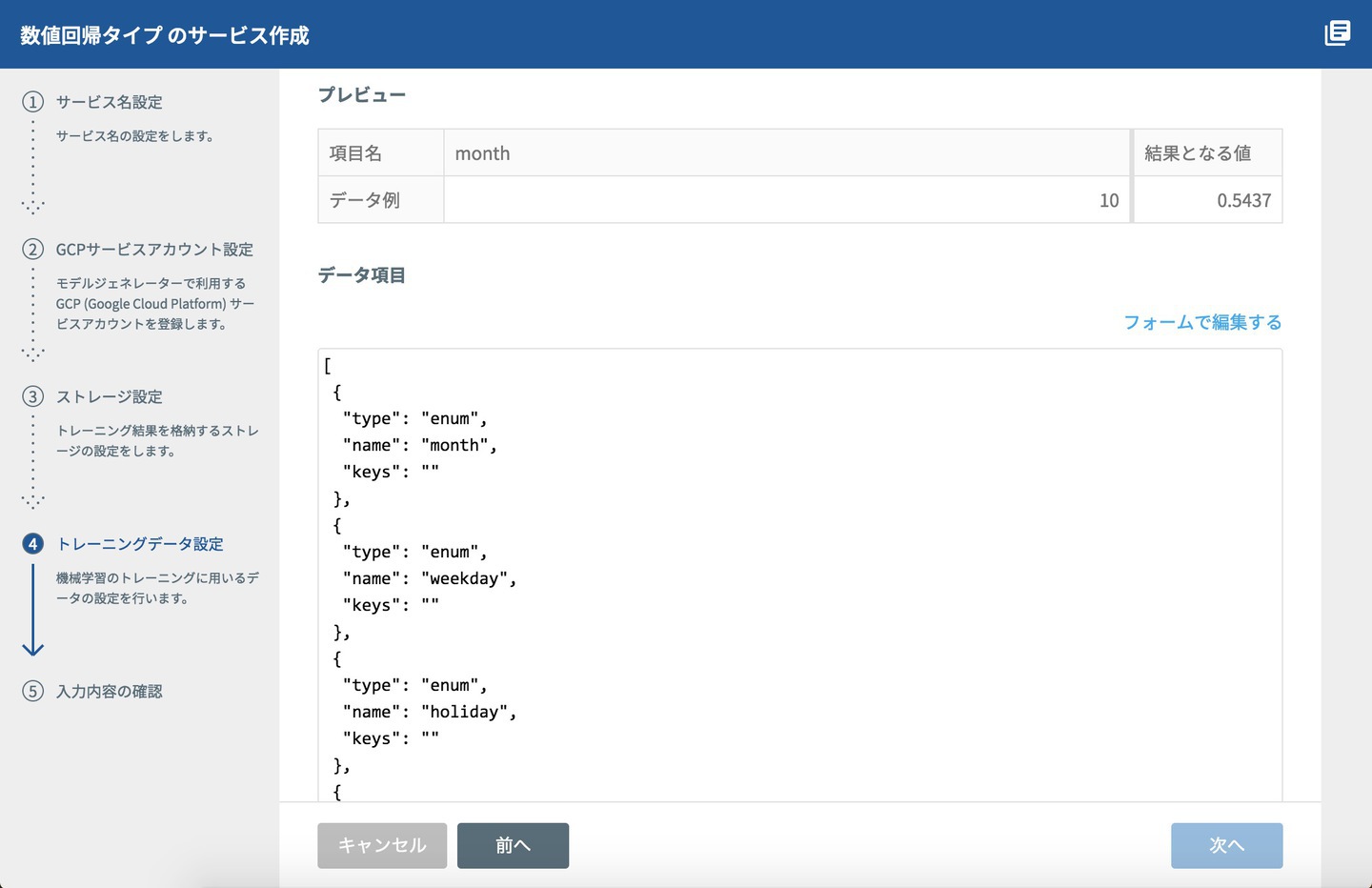
これで、「今回のデータはこんな形だよ」という情報が、DataEditorから④トレーニングデータ設定のクリップボードにコピーされます。
DataEditorからモデルジェネレーターに戻って、次は、トレーニングデータ設定の右上にある「JSONを直接編集する」をクリックして、表示されたテキストボックスに貼り付けます。
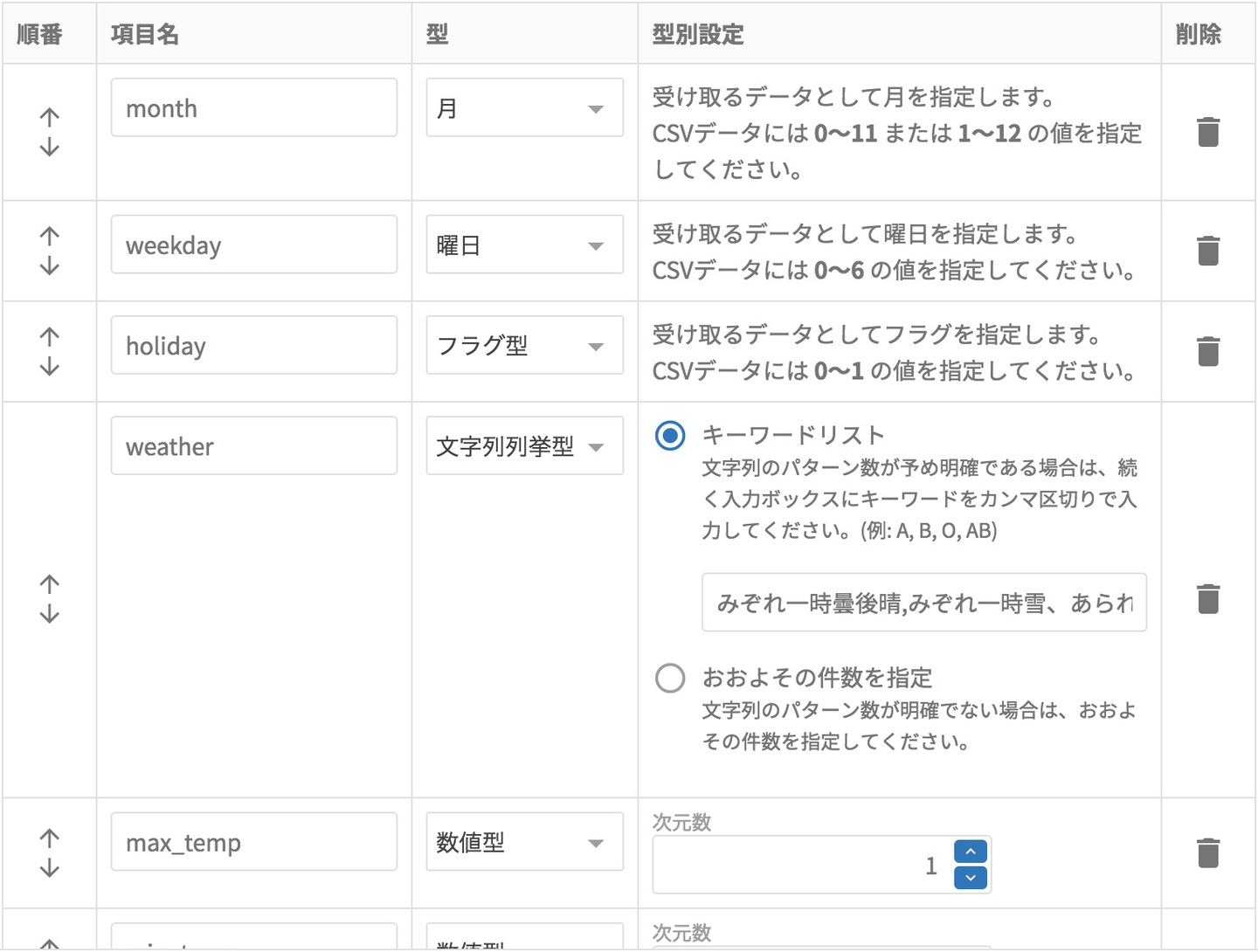
貼り付けた後でフィールドで編集に戻るとあら不思議、weatherの内容がしっかり入っています。
あとはmonth,weekday,holidayが数値型になっているので、それぞれ変更したらOKです。
トレーニングデータ設定が終わって次へを押すと、最終的な設定内容が⑤入力内容の確認画面に表示されます。毎日の天気はこんなに種類があるのかと気付かされますね。
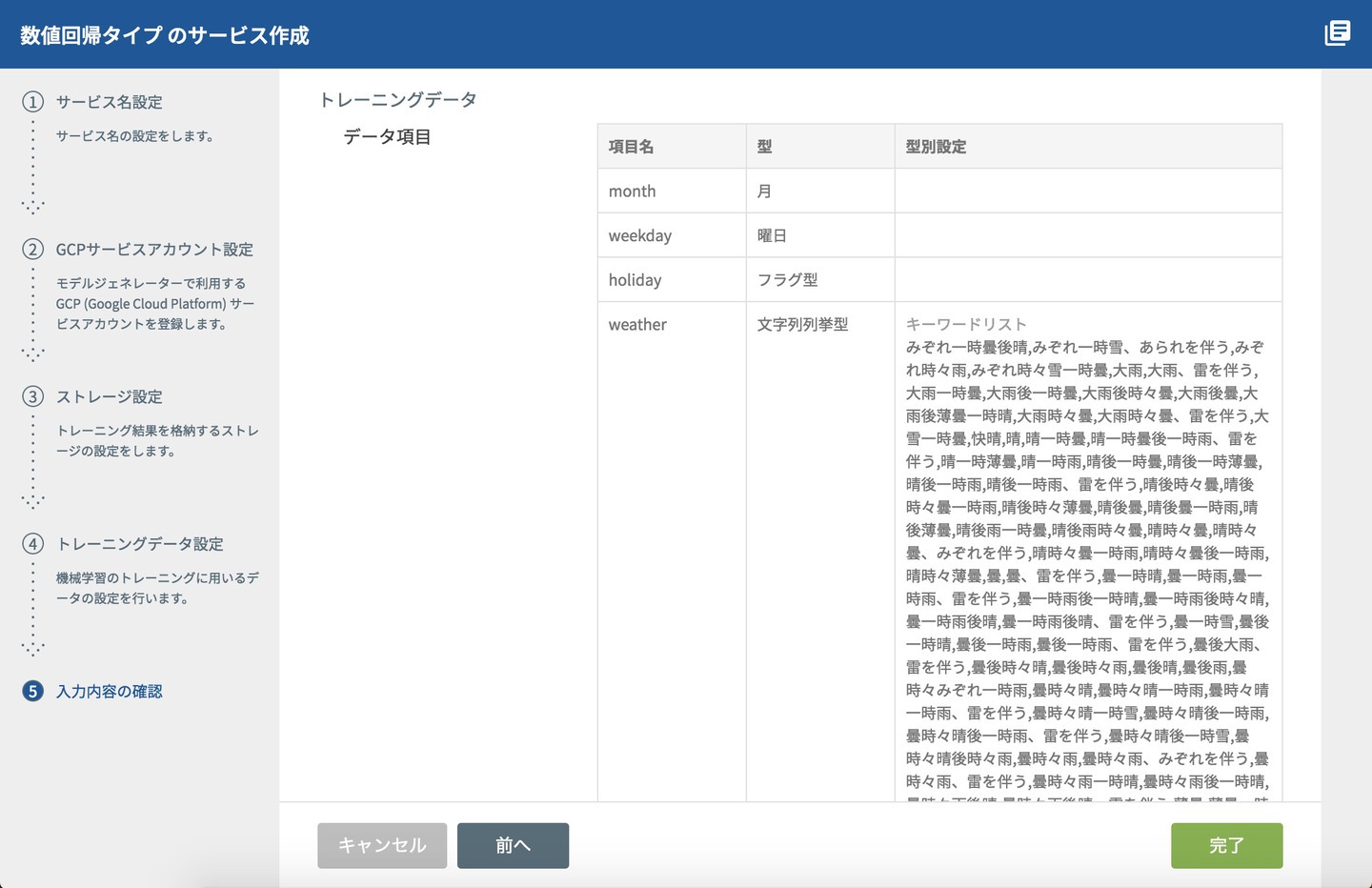
入力内容の確認で「完了」を押せば、いよいよモデルジェネレーターができてトレーニングを開始する準備が整います。
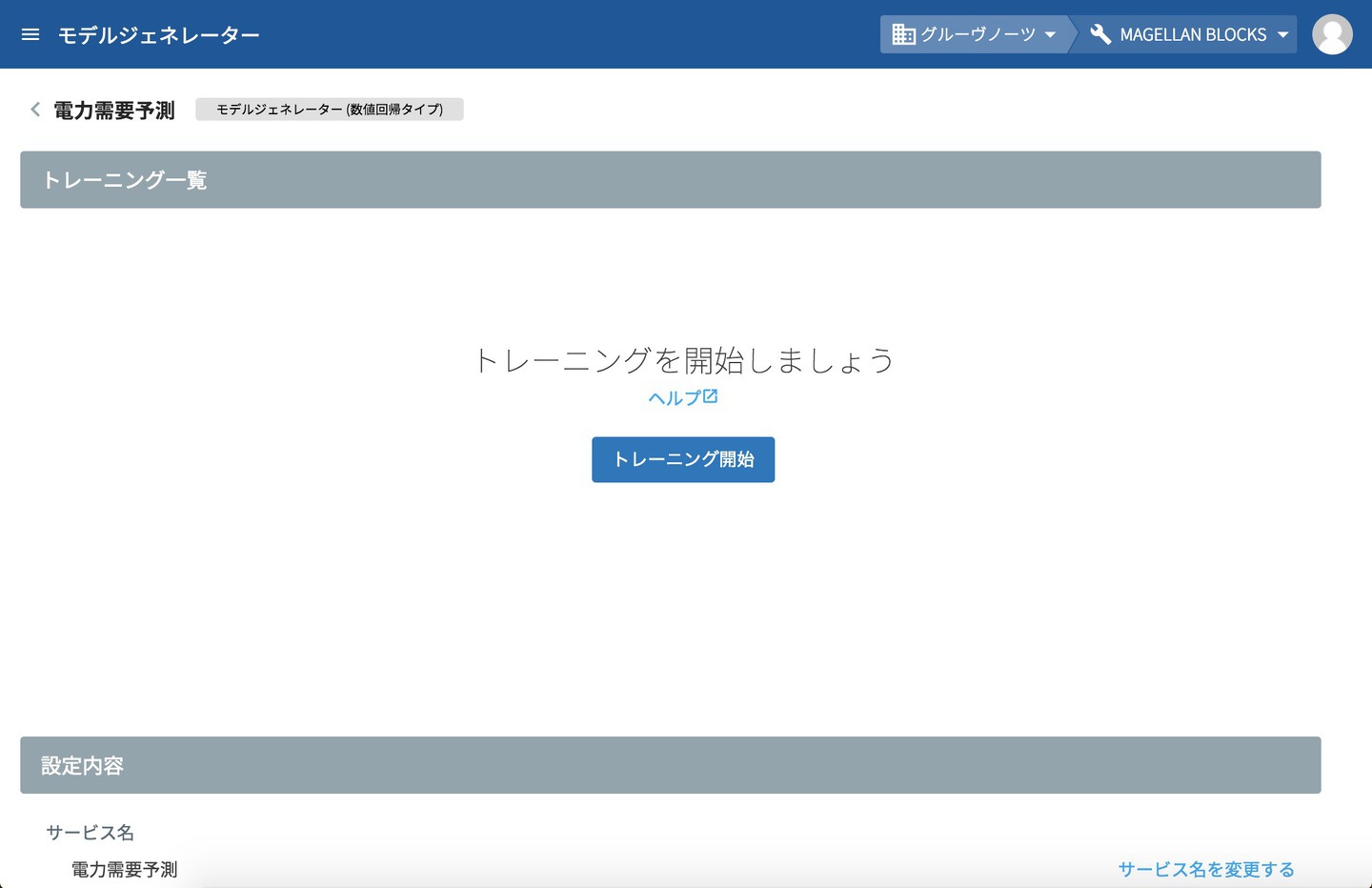
ここまででトレーニングをするための準備として、モデルジェネレーター 電力需要予測ができあがりました。
これから、先ほどエクスポートしたCSVファイルを使って、トレーニングを行います。
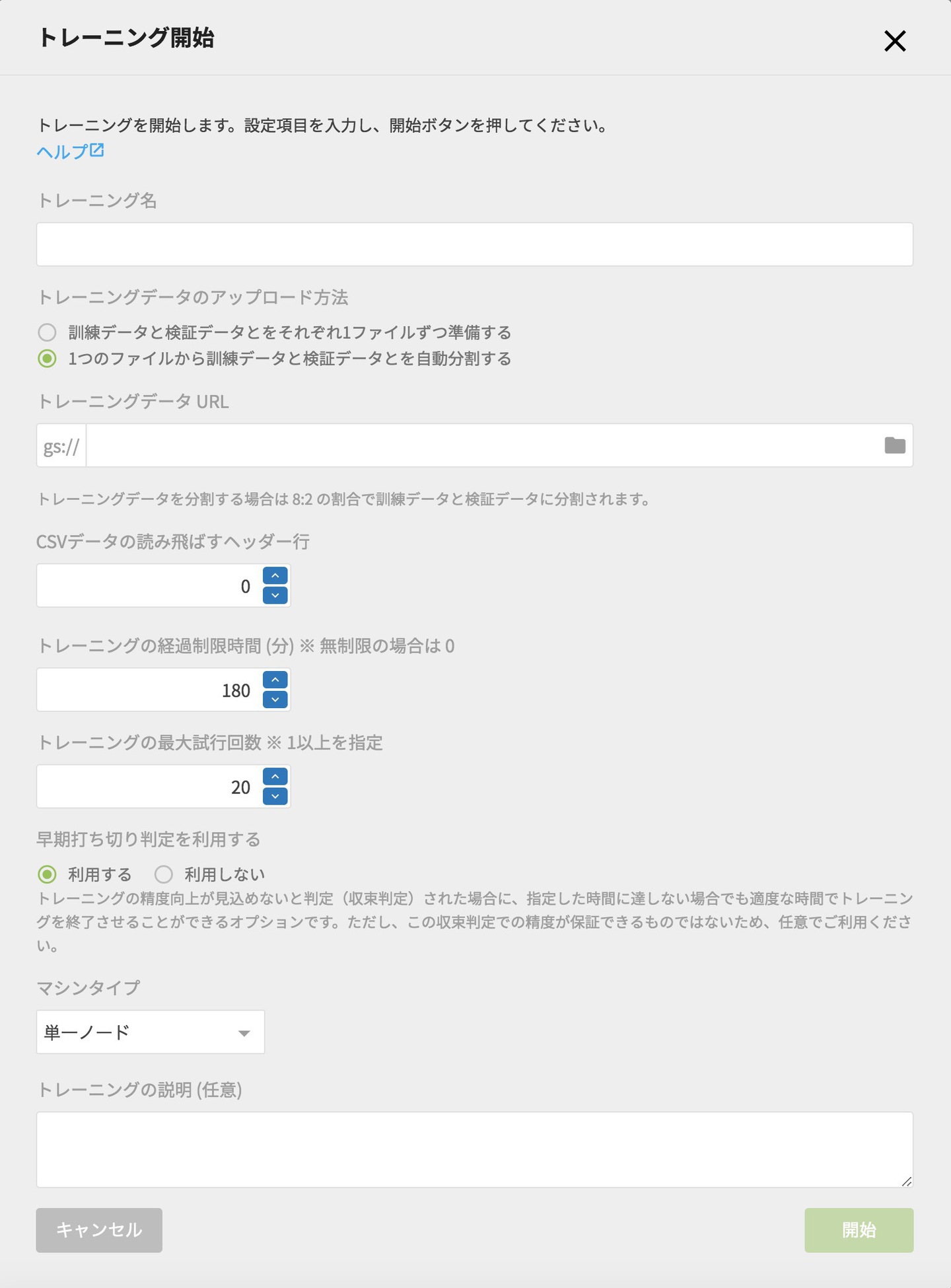
作成したモデルジェネレーターの電力需要予測から、「トレーニング開始」をクリックすると、このようなトレーニング開始画面が表示されます。
トレーニング開始画面のトレーニング名には、どういうトレーニングをしているのかがわかるような名前をオススメしています。今回は「26ヶ月分データ(180分×20回)」という名前にしました。
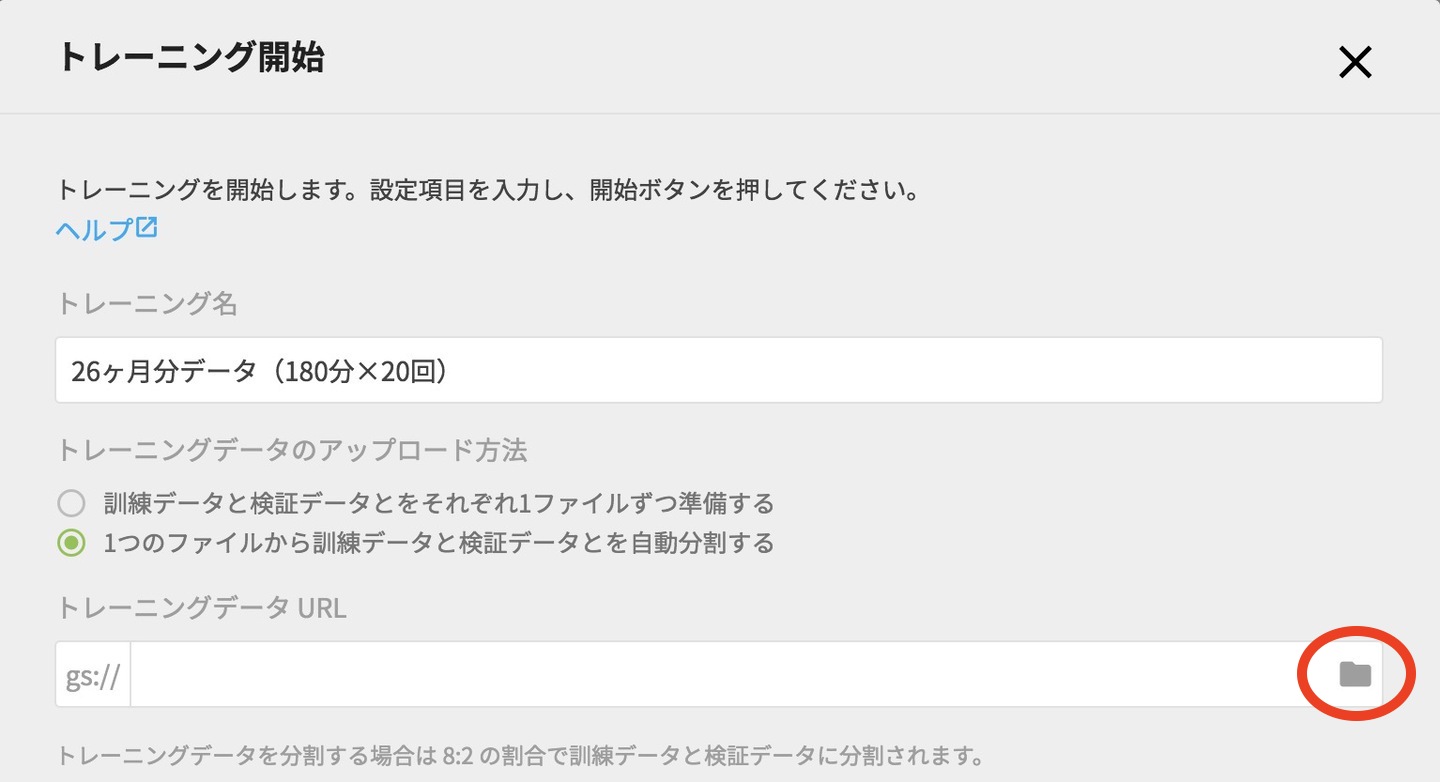
続いて学習用ファイルの指定ですが、トレーニングデータのアップロード方法の中で「1つのCSVファイルを元に分割する」を選択します。
選択したら該当のファイル指定をするには、トレーニングデータURLの項目の右側にあるフォルダアイコンをクリックして、選択画面を表示します。
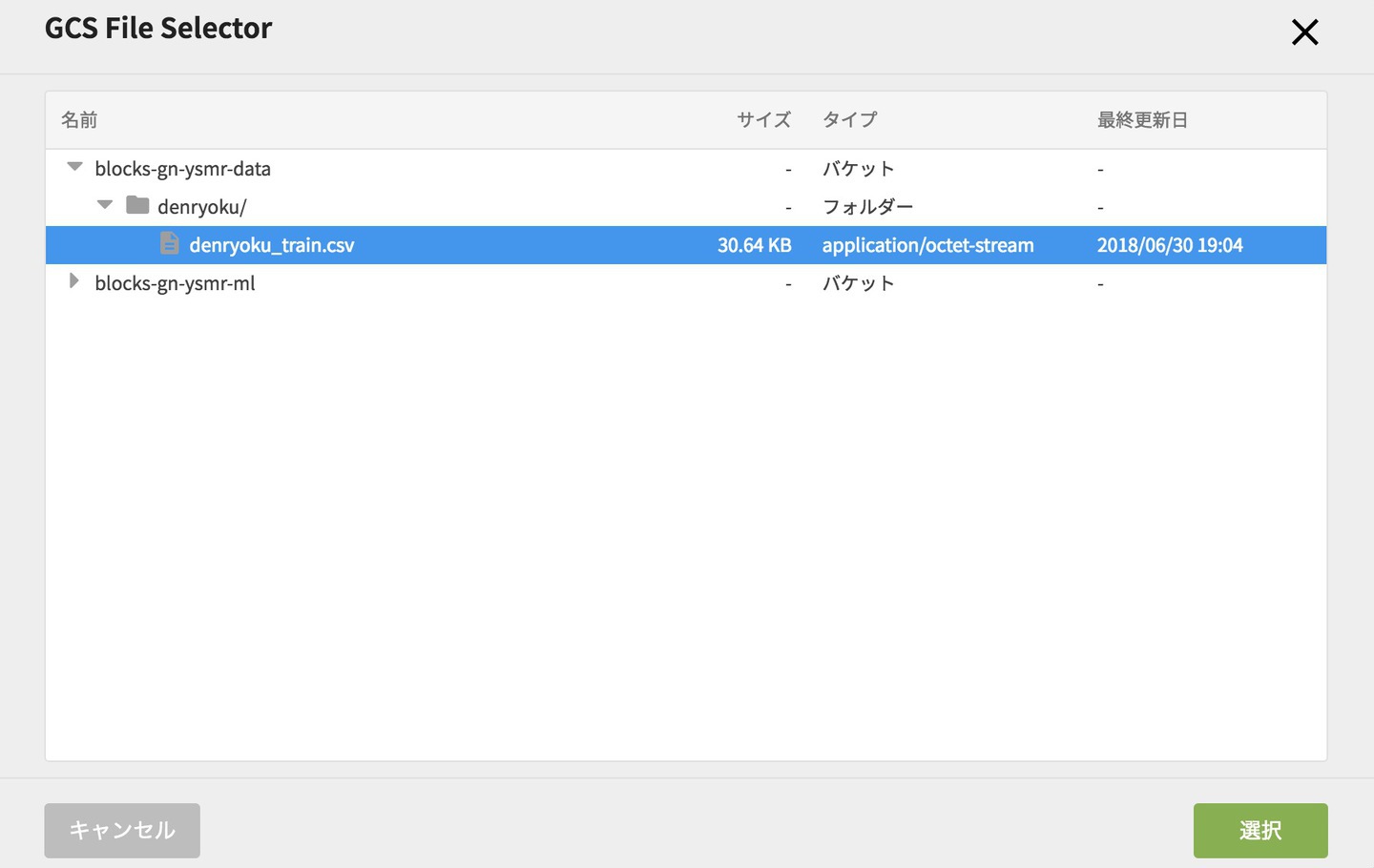
GCS File Selector画面で、前回エクスポートしたCSVファイルをクリックし、右下の「選択」をクリックします。(フォルダを展開するにはちっちゃい三角をクリックします。)
続いて、トレーニング開始画面で、CSVファイルの読み飛ばすヘッダー行を1にします。
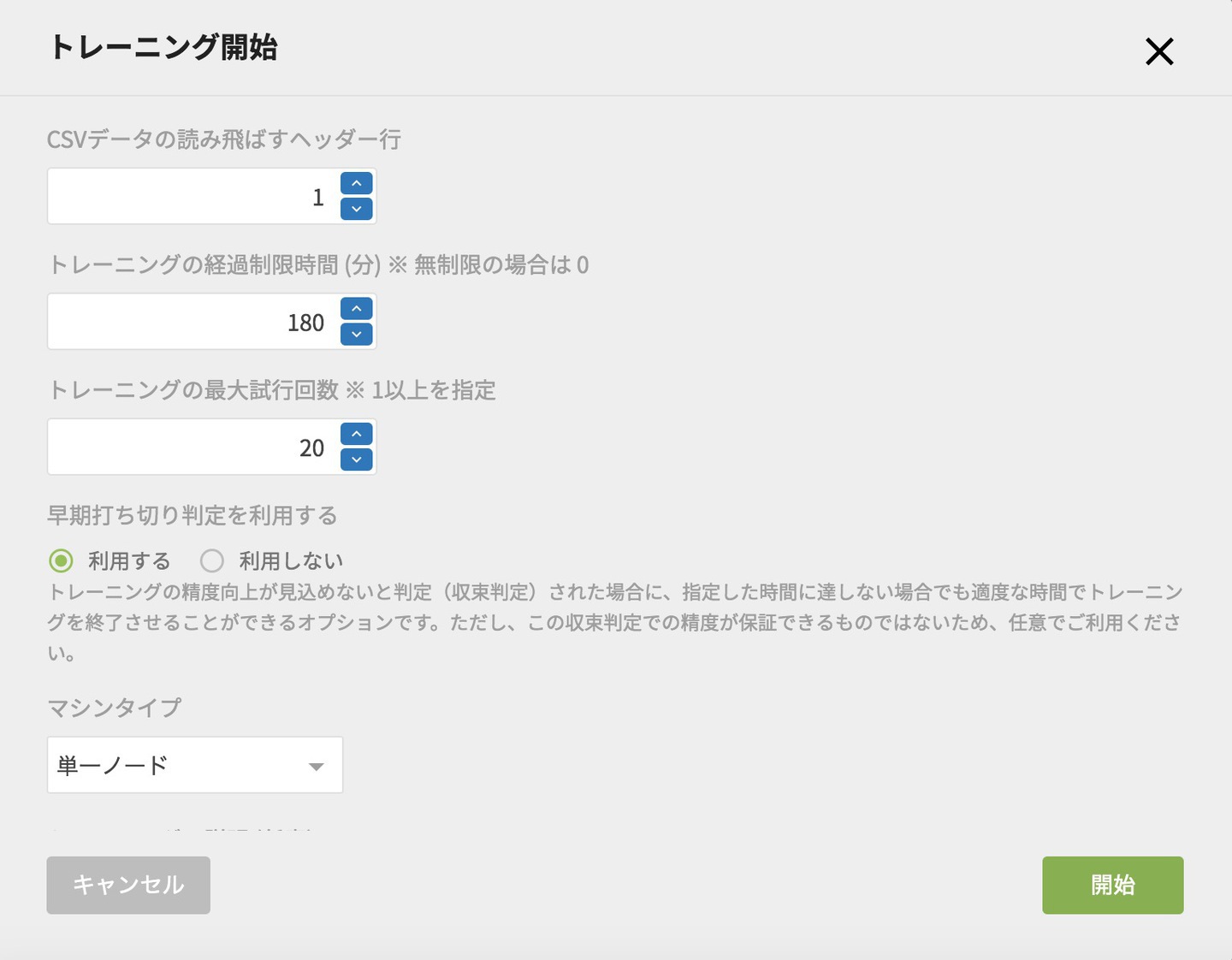
CSVファイルの読み飛ばすヘッダー行の「1」の設定は、エクスポート時にヘッダーを出力にしていたからです。
ここのように入力を終えたら、「開始」を押します。
他にも設定がありますが、詳しい説明はまたの機会に紹介します。
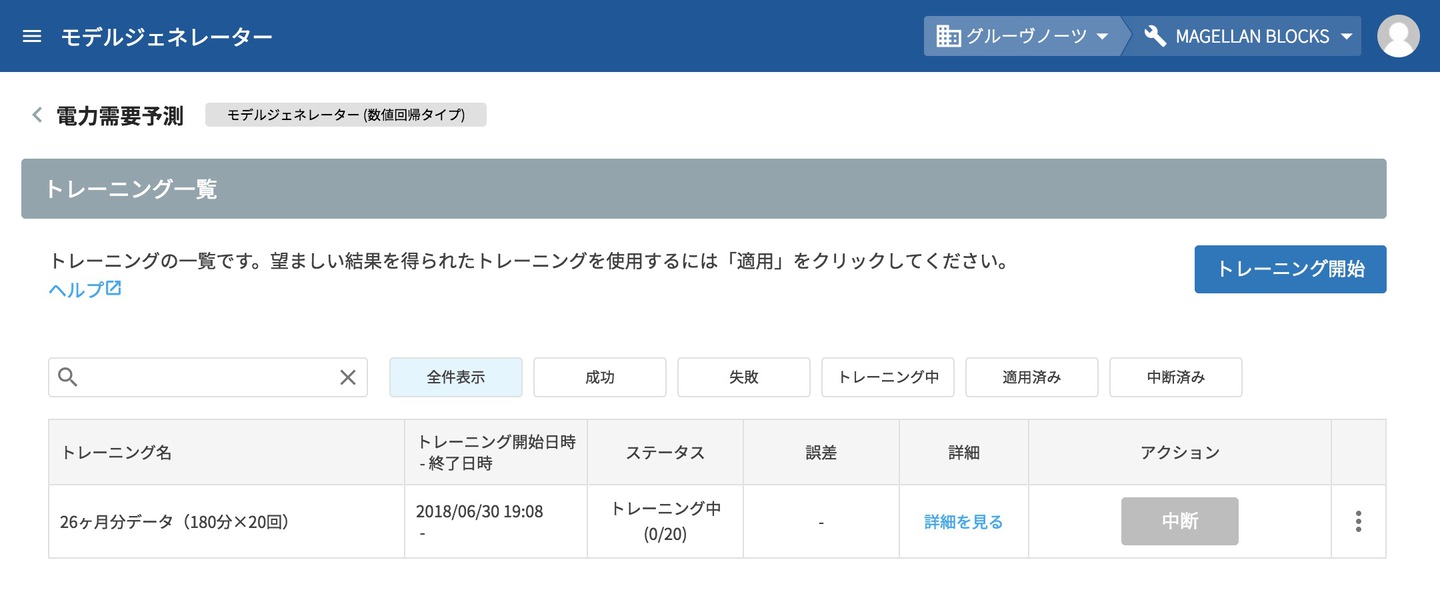
トレーニングが開始されると、モデルジェネレーターの電力需要予測のトレーニング一覧に経過が表示されます。ステータスが「トレーニング中」から「成功」になると終了です。
ステータスが成功になったら、アクションで「本番用」を選択して「適用」をクリックします。
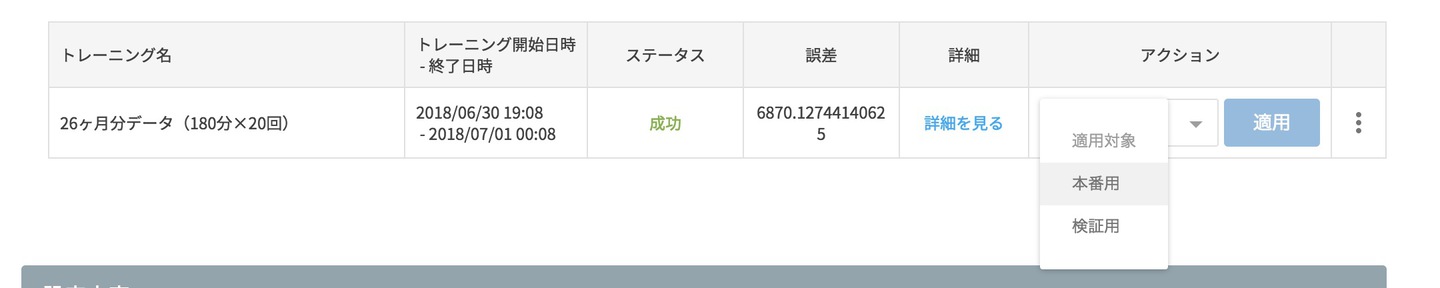
これで、モデルジェネレーターを作成してトレーニングが完了し、学習済みモデルが作成されました。
次の最終回「電力需要予測をMAGELLAN BLOCKSでやってみた(4)」では、いよいよフローデザイナーを使って予測します。
※本ブログの内容や紹介するサービス・機能は、掲載時点の情報です。