これまでもMAGELLAN BLOCKSの使いやすさを向上させる機能改善をすすめてきましたが、いよいよDataEditorで一貫してデータの取込からモデル作成・予測・分析までできるようになりました。
実際にどのようなことができるようになったのか見ていきましょう。
1.データ取り込み(Googleスプレッドシートより)
データはいつもの電力需要データです。
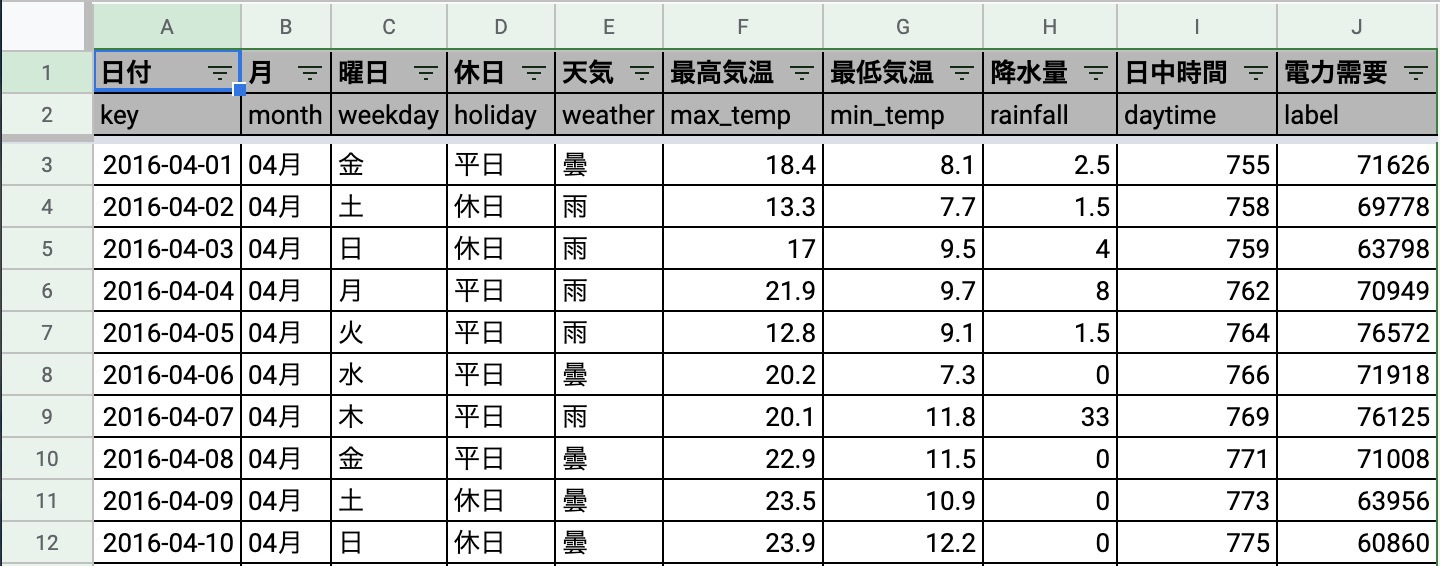
やっと東京電力パワーグリッドの公開データが溜まってきて、やっと3年分の学習データと3ヶ月の予測データ(全データ期間:2016/04/01〜2019/06/30)を準備できました。
それと今回から月・曜日・休日・天気について、0,1,2,ではなく文字にしています。これは最初から文字列列挙型で取り扱えるようにするためです。
まずはサービスメニューからDataEditorを開きます。開いていただくとインポートボタンが右側にあるのでクリックします。インポートの設定画面が開きますので入力していきます。
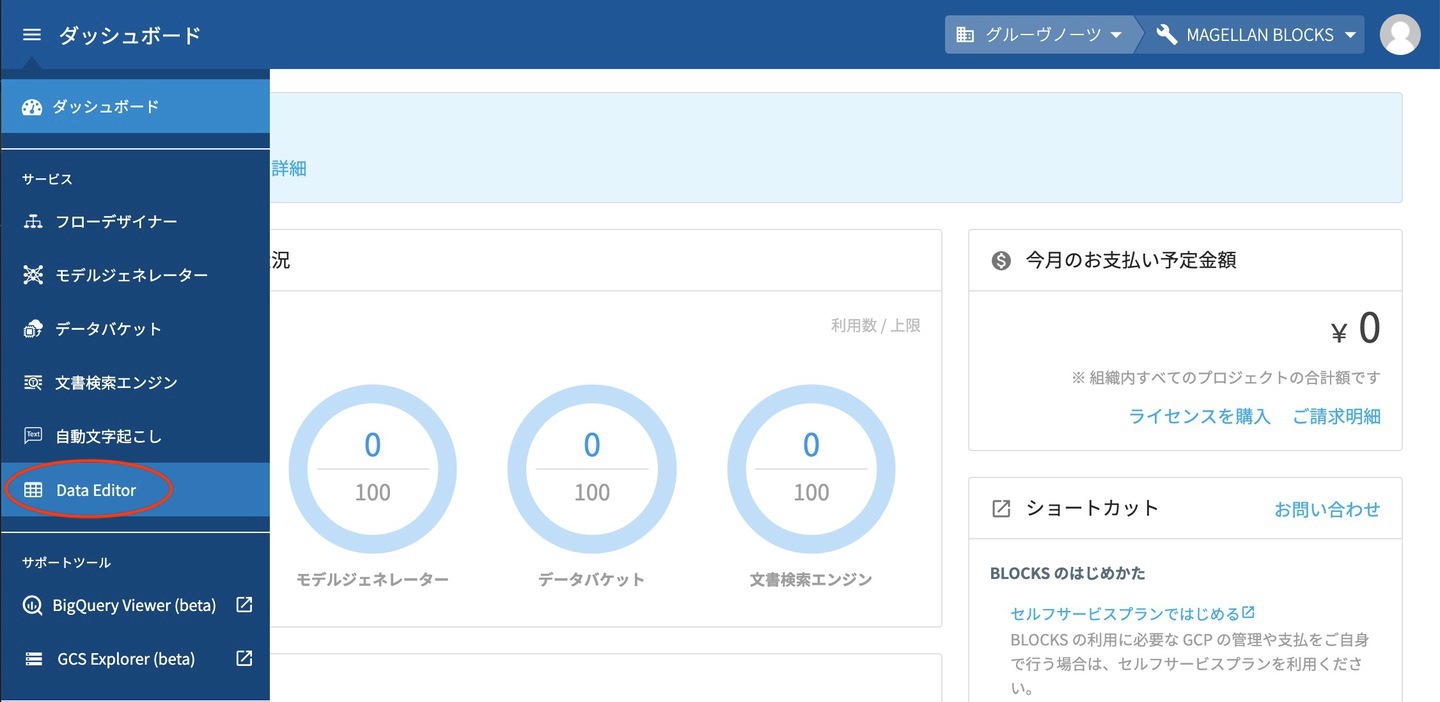

今回はGoogleスプレッドシートからインポートしますのでGoogle Driveを選択し、ファイルURIを入力したうえでスプレッドシートに合わせて読み飛ばし行を2行に設定します。続いて、インポート先としてデータセットID・テーブルID・名前を入力しインポートをクリックします。
インポートができたら開くをクリックし該当のテーブルを表示します。
2.データ加工(今回は学習データ・予測データの分割)
データ加工は色々出来ますが今回はほぼ準備ができているデータなので分割だけ行います。
今回は
・学習データ:2016/04/01〜2019/03/31(3年間)
・予測データ:2019/04/01〜2019/06/30(3ヶ月)
の2つに分割します。
DataEditorのテーブルタブを開き、テーブル操作のテーブル分割を選びます。テーブル分割の設定画面が開きますので入力していきます。
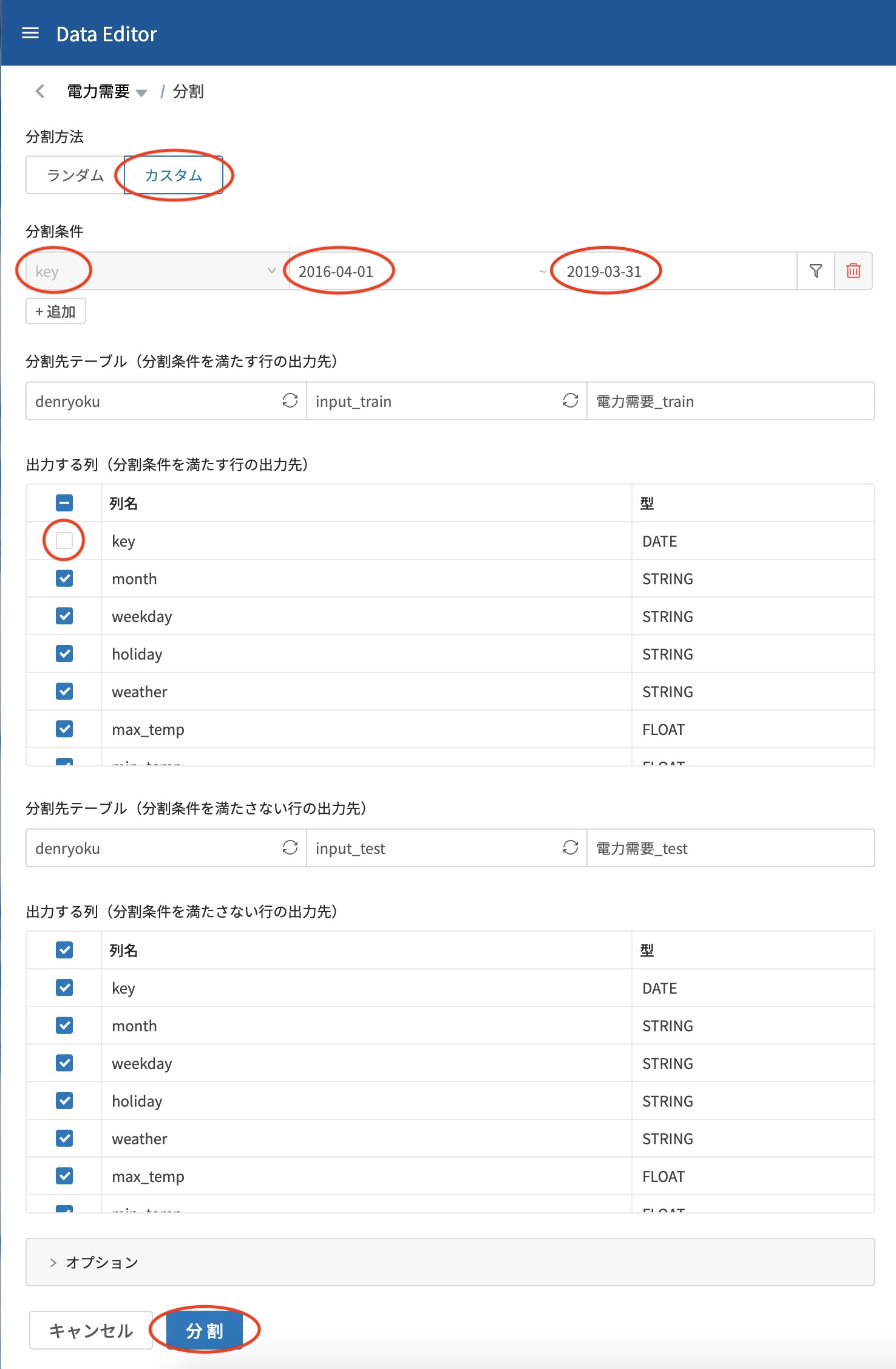
分割方法を カスタム へ変更し、分割条件に日付の keyを選択した後に、開始日付・終了日付に先程の 2016/04/01〜2019/03/31 を指定します。後は 分割条件を満たす行 の出力列から keyのチェックを外し、分割をクリックします。

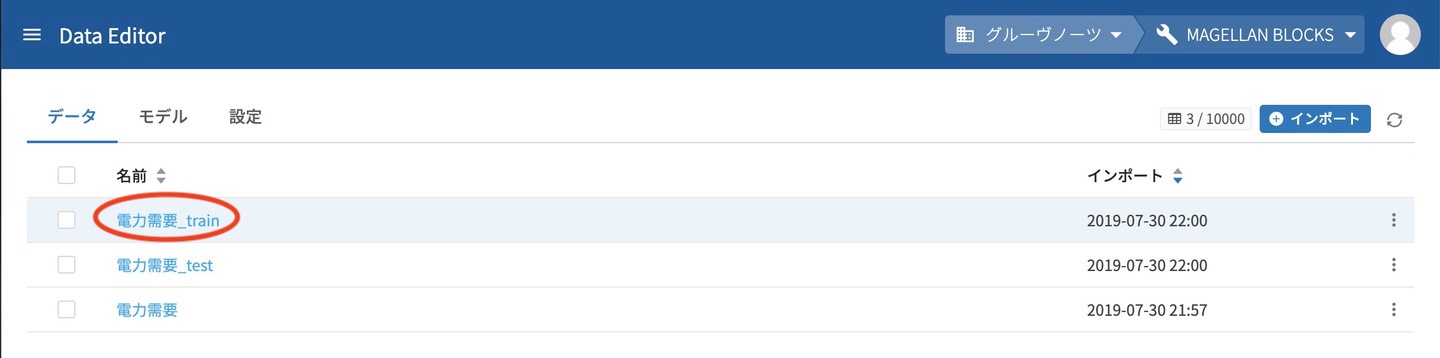
分割が完了しテーブルの一覧を確認すると、電力データ・電力データ_train・電力データ_testの3テーブルができています。この中から 電力データ_train を使ってモデルの作成に進んで行きます。
3.モデル作成(数値回帰モデル)
分割して出来上がった 電力データ_train の モデル作成タブを開きます。モデル作成タブを開くと 数値回帰・数値分類・クラスタリング と作成可能なモデルの種類が表示されるので、今回の電力需要予測では 数値回帰 を選択します。
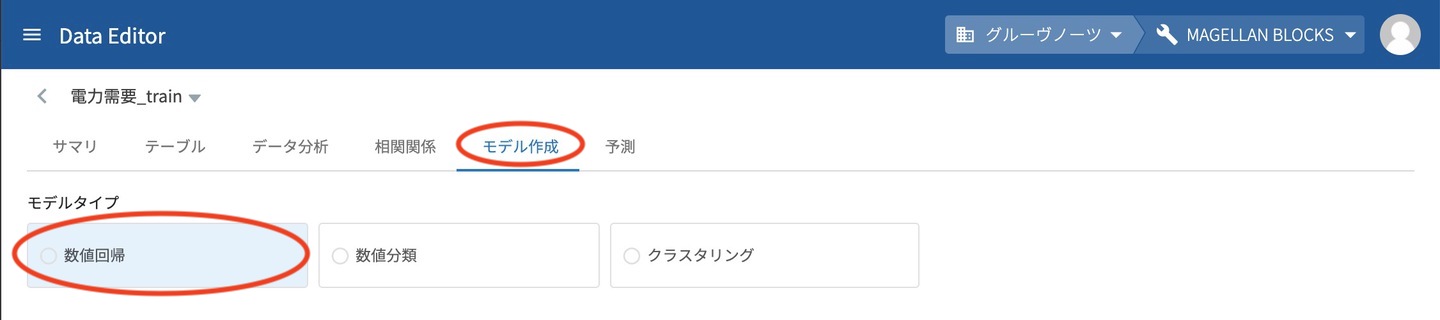
数値回帰を選択するといくつかの設定がでてきますが、今回はすべてデフォルトの設定で進めます。そのくらい簡単になってます。
モデル作成をクリックします。
トレーニングが開始されるとウィンドウが表示されるので閉じて終わるまで待ちます。(数時間)
トレーニング中は 誤差 / 正確率のところに進捗がバーで表示され、完了すると誤差または正確率の値が表示されます。


4.予測
予測も簡単です。ざっくり言うと予測対象のデータを選んで、モデルを選んで、実行するだけです。
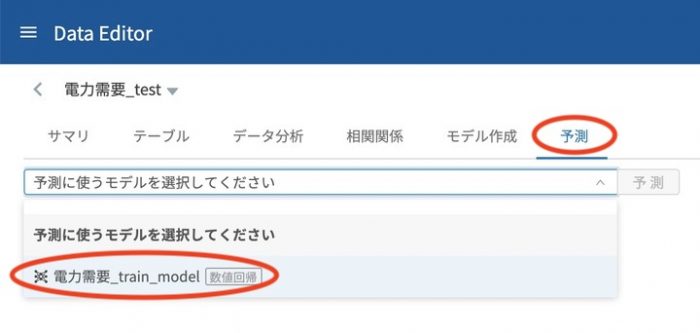
データ一覧から今回は分割した残りの 電力需要_test を選択します。
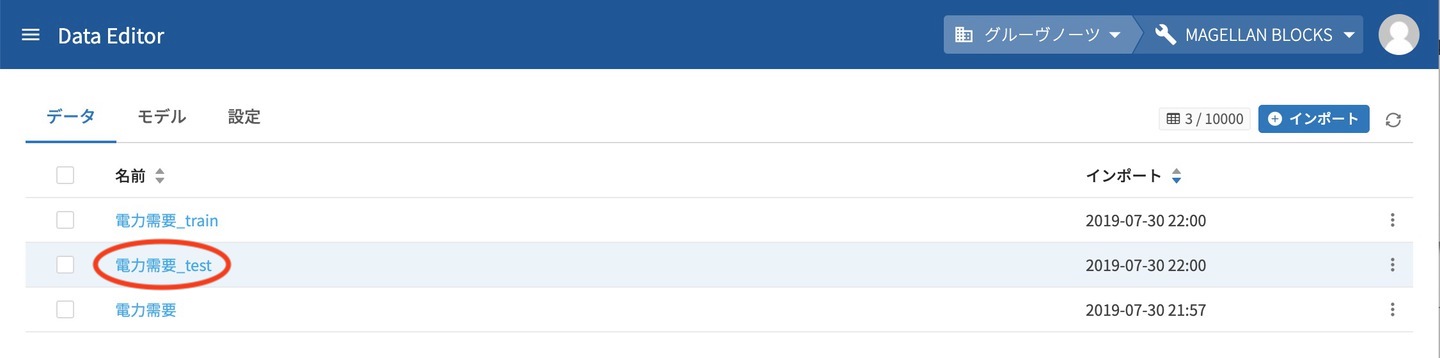
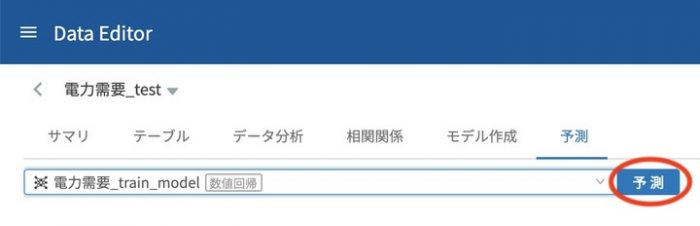
予測 タブを開くと 予測に使うモデルを選択して下さい のところで、作成したモデルを選択します。選択したら 予測 ボタンをクリックするだけです。
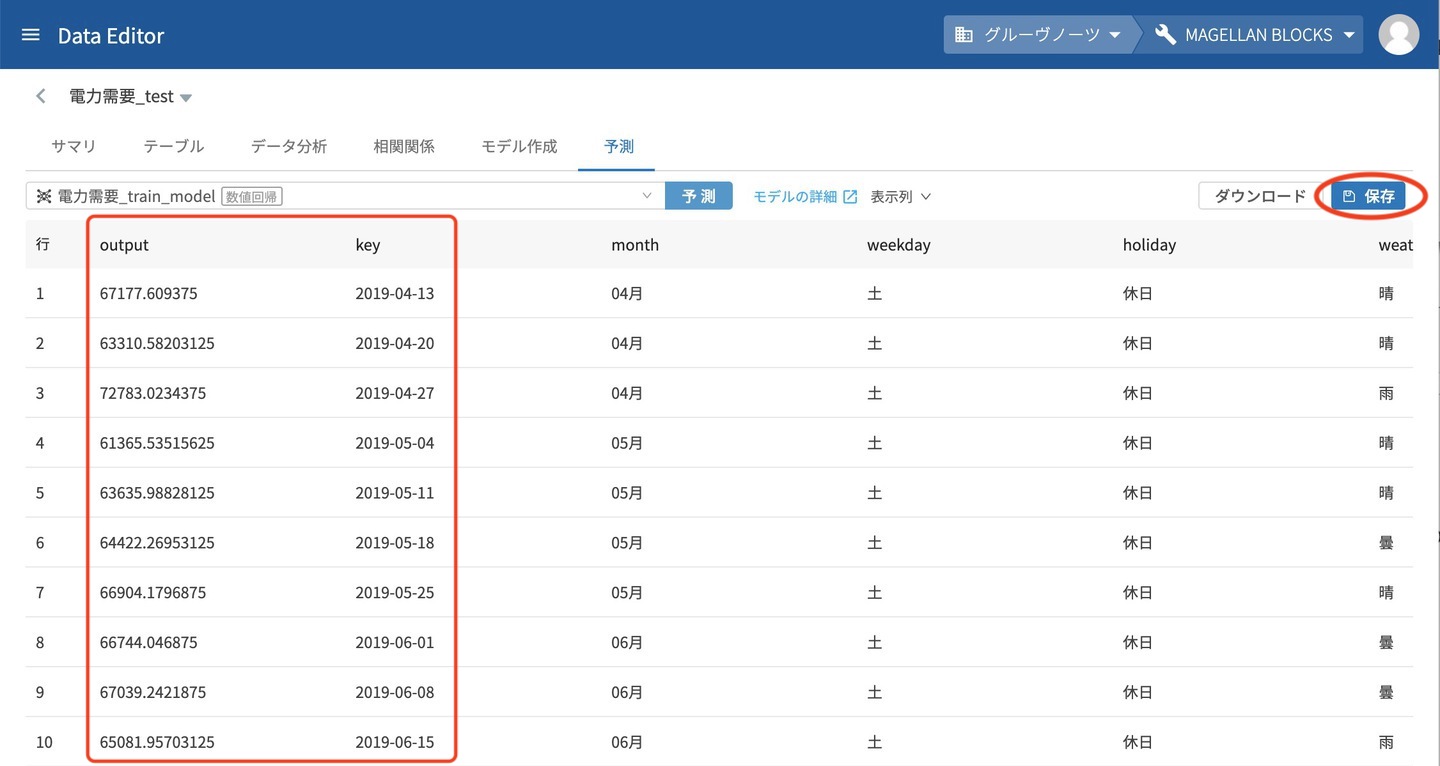
予測処理が終わると結果の一覧が表示されます。結果は予測データとして保有してた項目+予測値のoutput が一緒に表示されます。この状態では保存されていないので、右上の保存をクリックします。
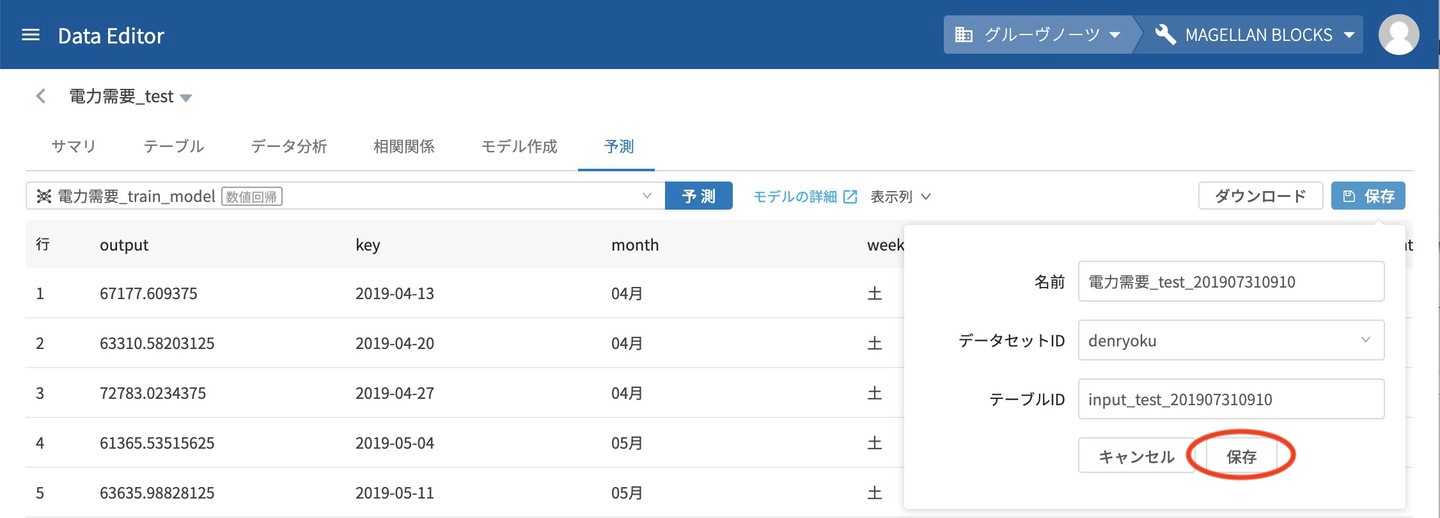
データの名前の指定ウィンドウが表示されますので、そのまま保存をクリックします。
5.予測結果の分析(今回はグラフ化)
結果が保存されるとデータとして分析タブが使えるようになります。今回は需要予測なのでkey毎に実績値(label)と予測値(output)を抽出して線グラフで表示してみました。とても簡単な操作でここまでできるようになりました。
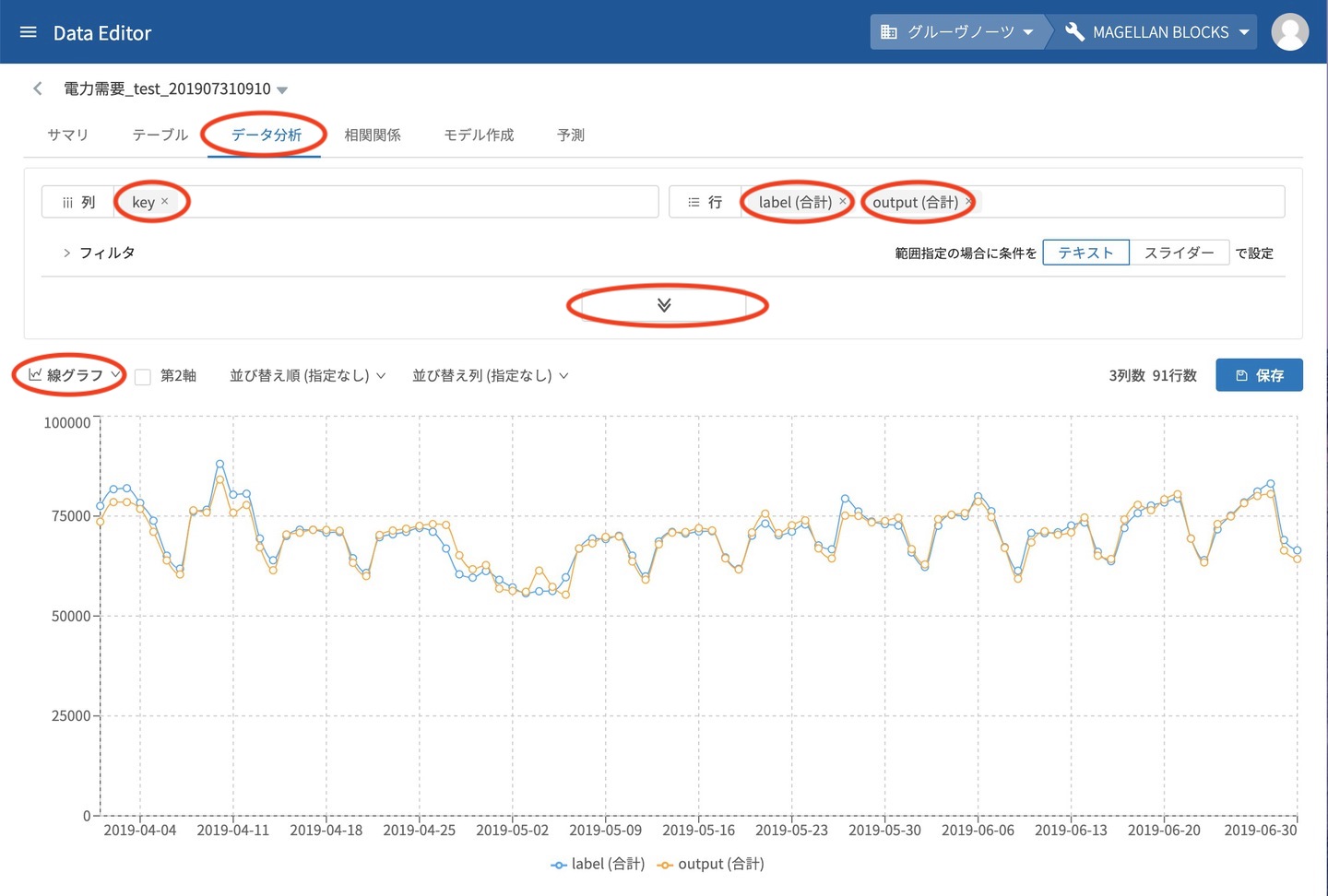
このようにMAGELLAN BLOCKSのDataEditorはここまでの進化を遂げて、かなり機械学習モデルを構築・検証することがスムーズになりました。
AI・機械学習はツールを使っても難しそうだと思われている方こそ、ここまで簡便に利用ができることを知っていただき新たな取り組みに一歩足を踏み出していただければと思います。
※本ブログの内容や紹介するサービス・機能は、掲載時点の情報です。