日々、お客さまから・社内からの要望をスピーディに実現してくれるエンジニアのおかげで、MAGELLAN BLOCKSがすごく便利になってきています。
今日は便利になったMAGELLAN BLOCKSで、需要予測をどれだけ最小手でできるかやってみます。
需要予測の流れは大きく言うと、「❶データの準備」、「❷学習用と予測用データに分割」、「❸モデルを学習用データで学習」、「❹予測用データで予測」の流れになります。
一旦動画を見ていただくと全体の流れ、操作の流れを見ていただき続きを読んでいただくと掴みやすと思います。(すみません。無音で淡々とした動画です。)
動画を見ていただいたとおり、以前に比べてかなりシームレスな手順になりました。それでは、順に説明していきます。
1.データを準備する
データは、いつもの電力需要のデータです。
東京電力パワーグリッドの公開データが、やっと3年分たまりました。
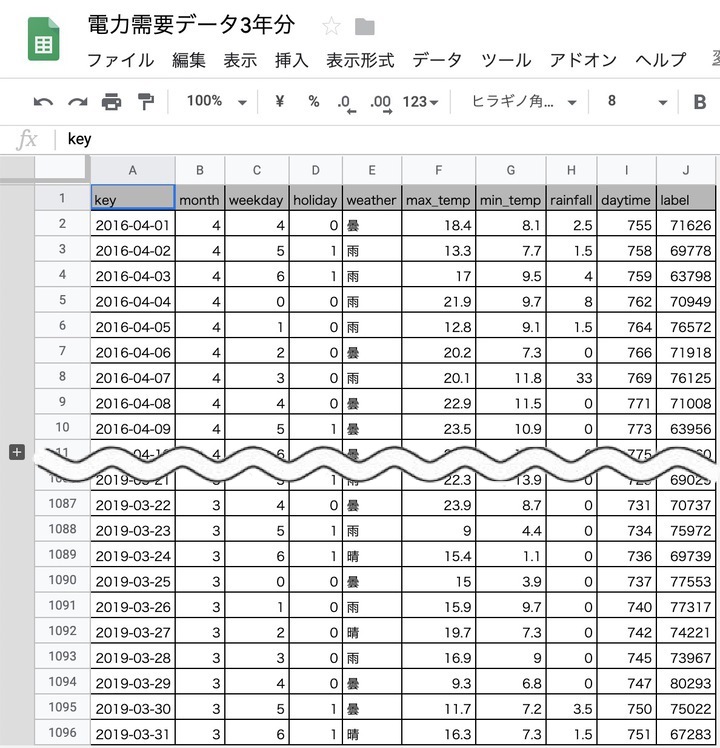
今回はこのデータを次のように2分割します。
・2016年4月1日〜2018年12月31日(学習用データ)
・2019年1月1日〜2019年3月31日(予測用データ)
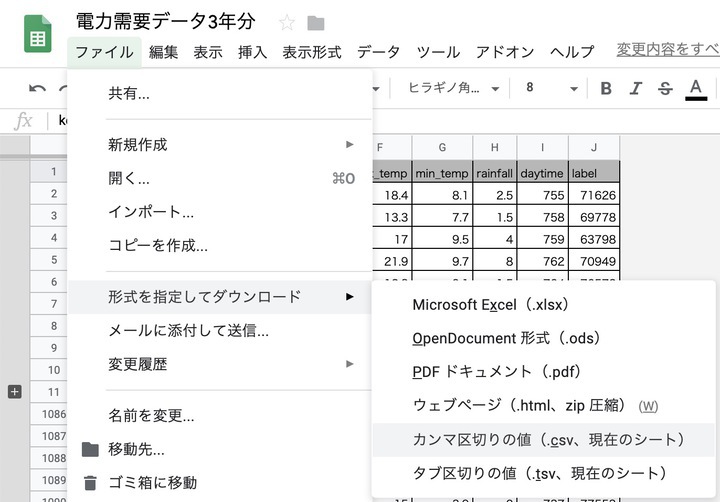
今回は、Excelをお使いの方も同じ流れでできるように、CSVでダウンロードします。
これで準備ができました。
続いて、データを分割します。ここからは、MAGELLAN BLOCKSのDataEditorを使っていきます。まずは、メニューからDataEditorを開きます。

DataEditorを開いたら、先ほど準備したCSVファイルを読み込むために、右上のインポートをクリックします。
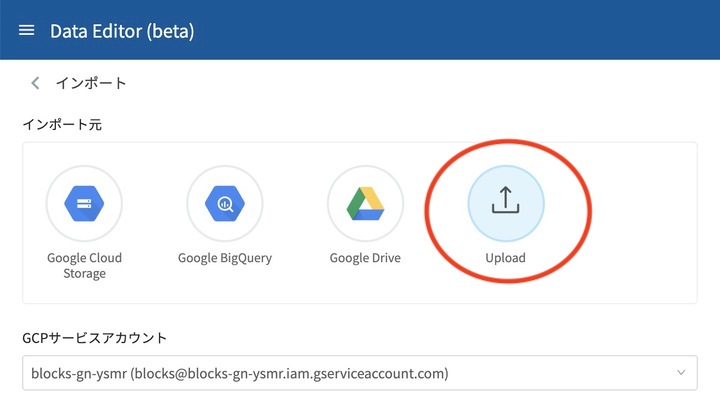
するとインポート操作をする画面が表示されるので、まず、インポート元の種類を選択します。
今回は、Uplaod を選択します。
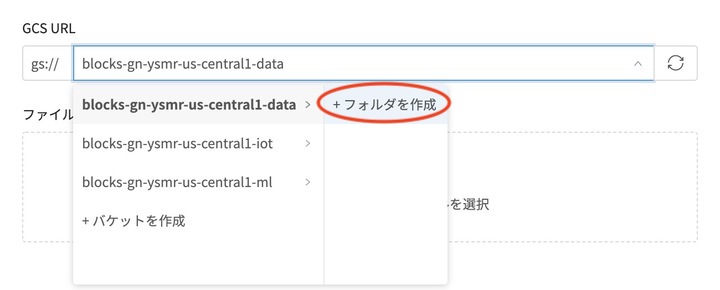
続いて、アップロード先のGCS URLを指定します。
-data で終わるバケットを選択しフォルダを作成します。
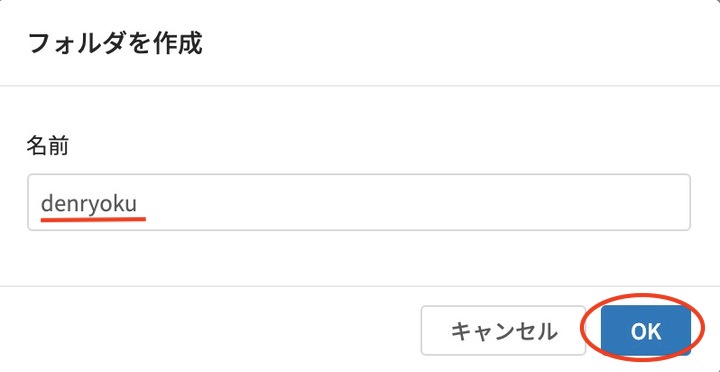
次に、表示されるウィンドウにフォルダ名を入力して、フォルダを作成します。
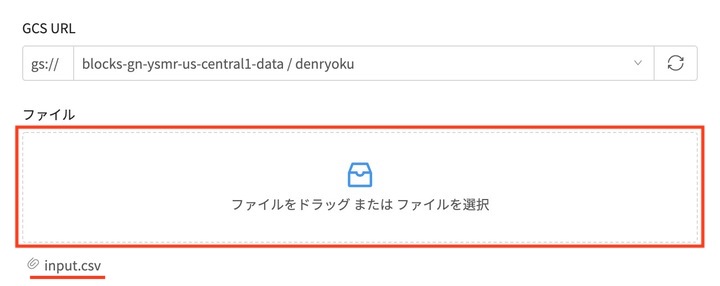
赤枠にCSVファイルをドラッグ&ドロップすると、インポートするファイルの指定が完了です。
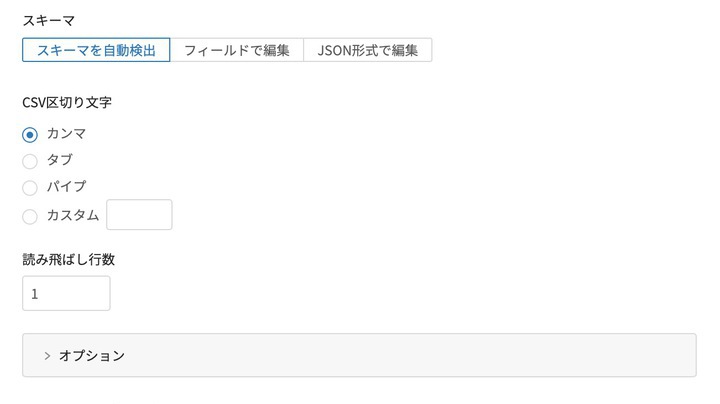
スキーマ設定は、今回はデフォルト設定のままで大丈夫です。
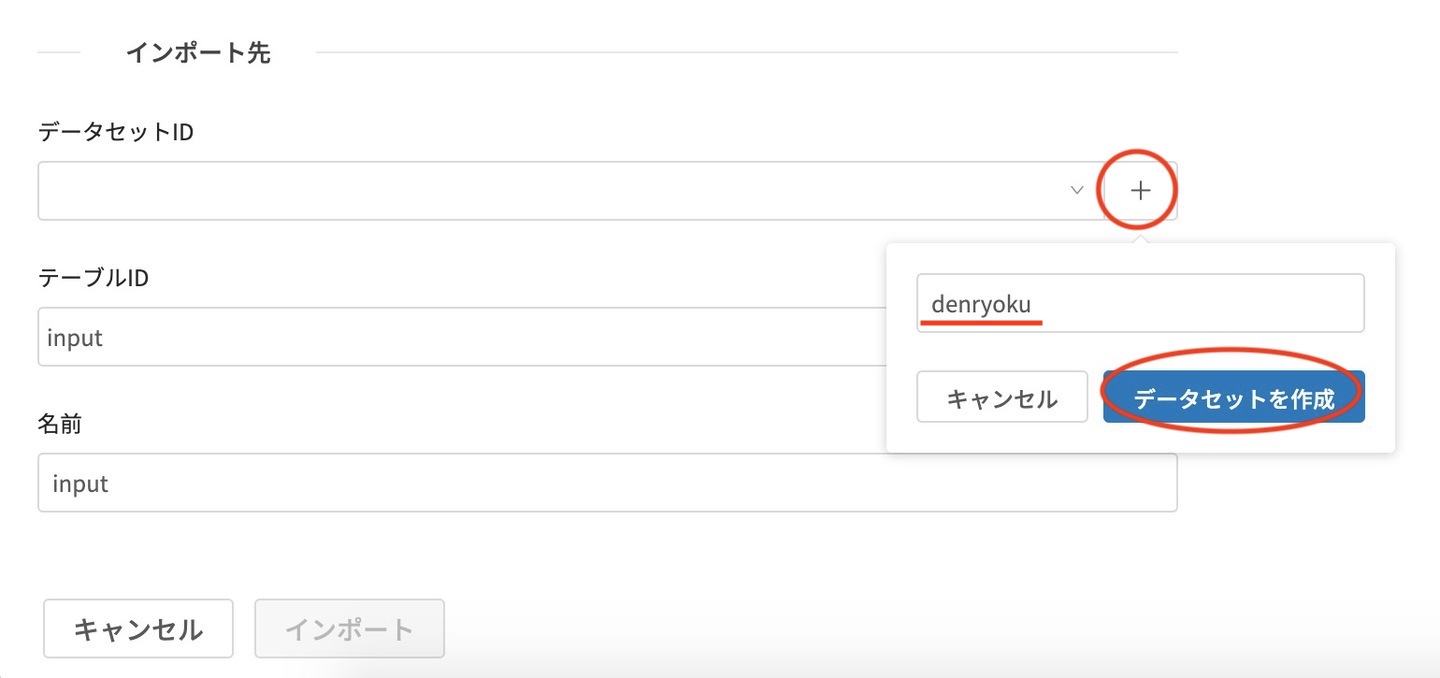
インポート先の設定として、データセットを作成します。
+ボタンをクリックし、データセットIDを入力して、データセットを作成 をクリックします。
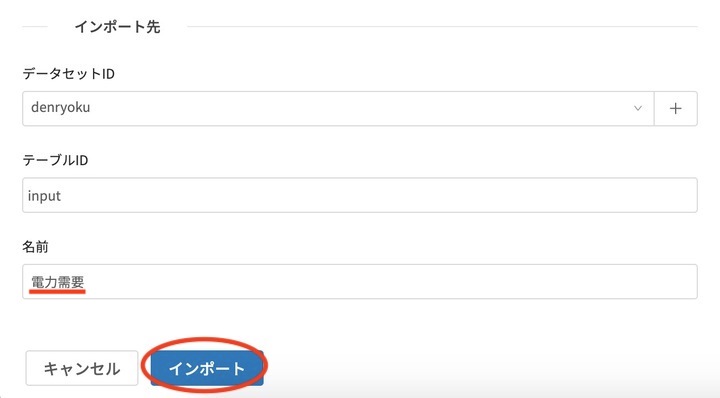
名前には、日本語の名前を入力して インポート をクリックします。
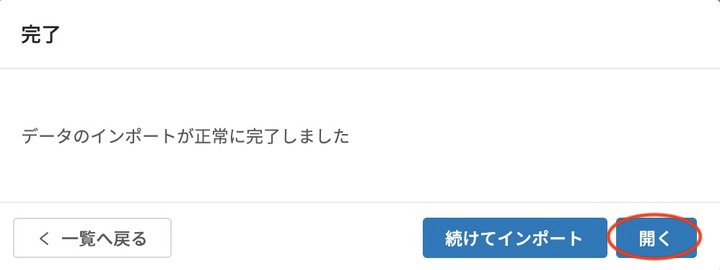
インポート完了のメッセージが表示されるので、 開く をクリックします。
2.学習用データと予測用データに分割する
データをインポートして準備ができたら、学習用データと予測用データに分割を行います。
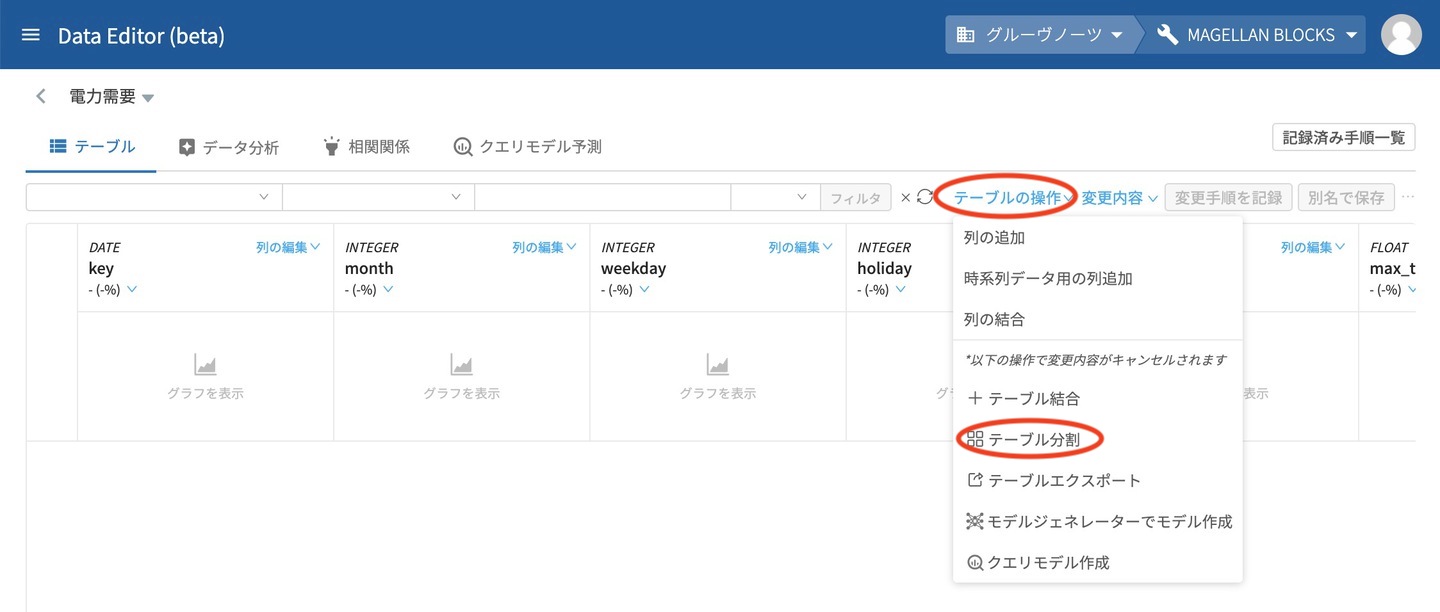
DataEditorのテーブル表示画面の テーブルの操作 から、テーブル分割 をクリックします。
分割の画面が表示されたら、条件を指定します。分割方法は カスタム を選択し、分割条件には key の項目を選択して、期間に 2016-04-01 〜 2018-12-31 を指定します。

続いて、分割条件を満たす行の出力先 に関する設定を行います。
出力する列の設定で、key のチェックを外します。(予測因子として不要のため)
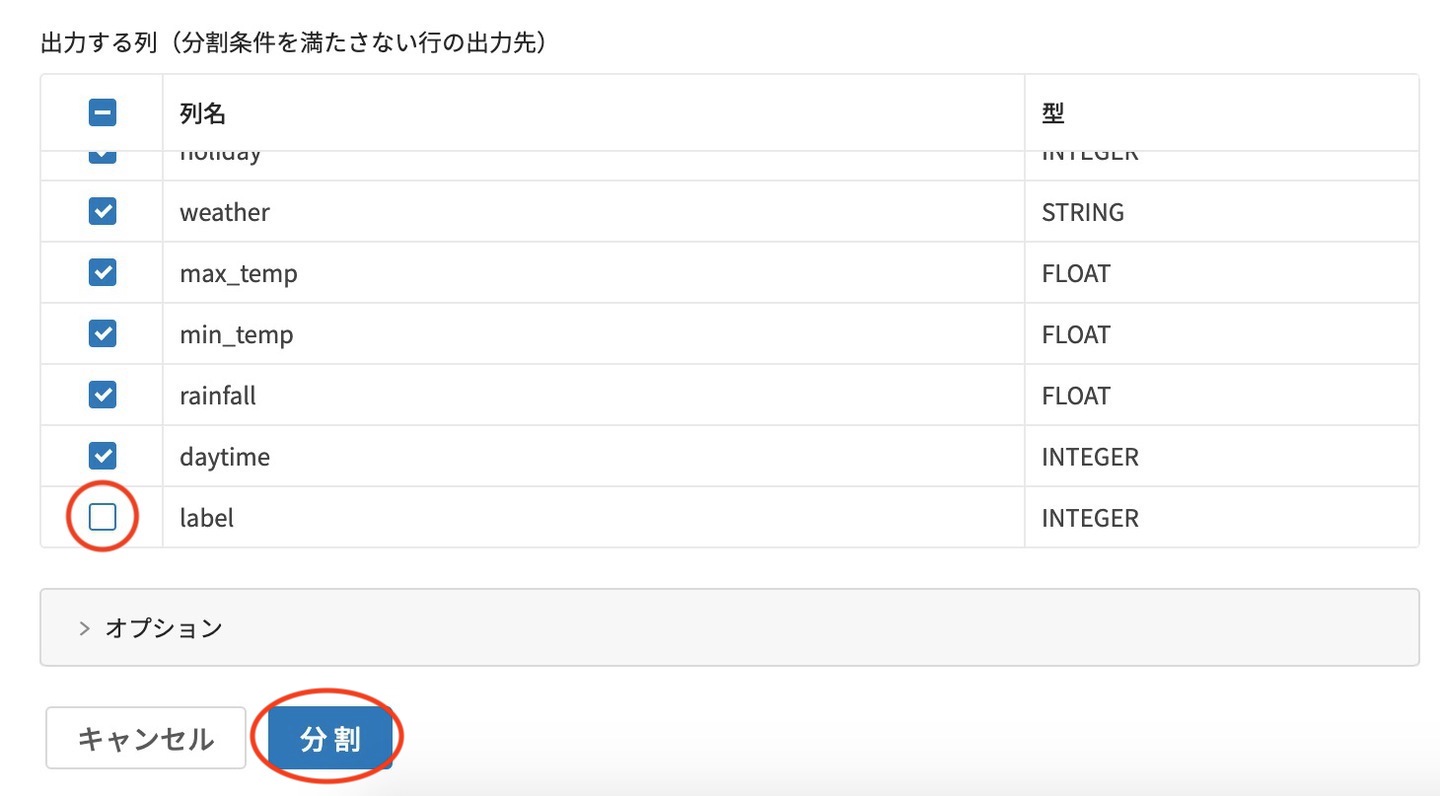
最後に、分割条件を満たさない行の出力先 に関する設定を行います。
出力する列の設定で、末尾の label のチェックを外します。(予測実行時に不要のため)
各種設定ができたら、分割 をクリックします。

分割が完了すると、完了メッセージが表示されます。
3.モデルを作って学習用データで学習させる
分割が完了したら、機械学習のモデルを作って学習させます。
モデルを作るには、DataEditorのテーブルからモデルジェネレーターを作成します。

まずはDataEditorで、インポートしたテーブルを開きます。
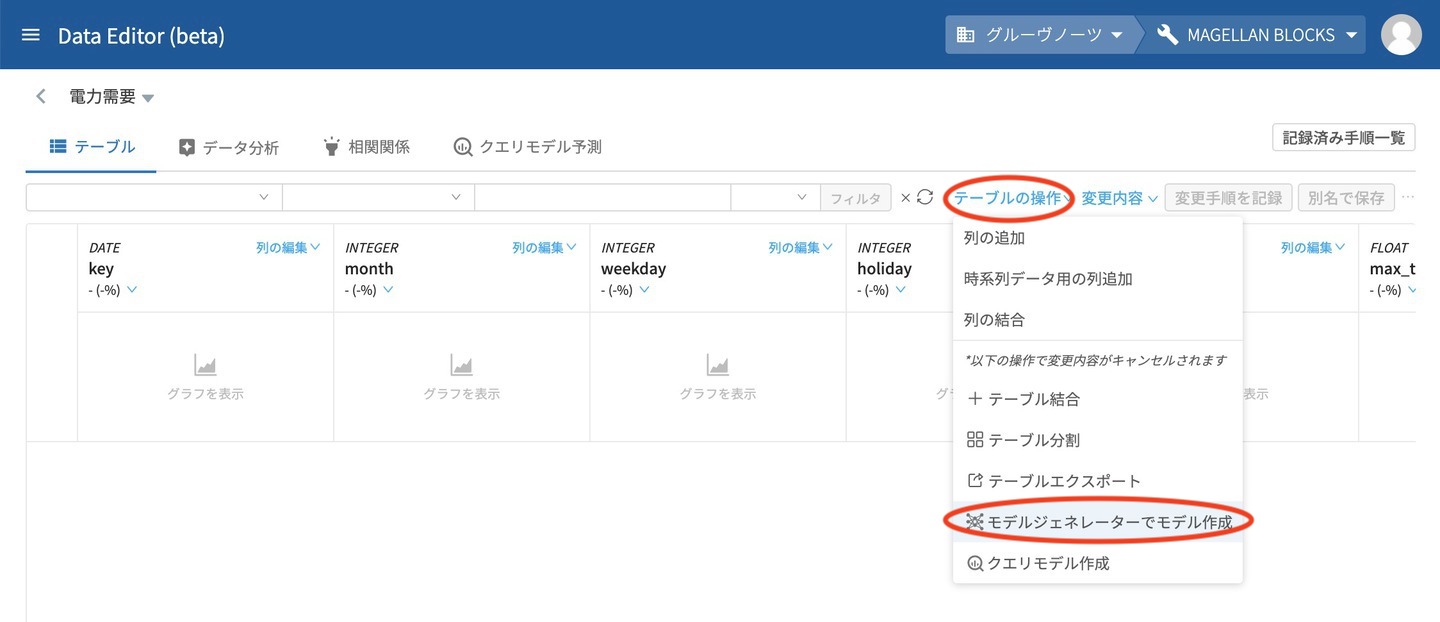
DataEditorのテーブル表示画面の テーブルの操作 から、モデルジェネレーターでモデル作成 をクリックします。
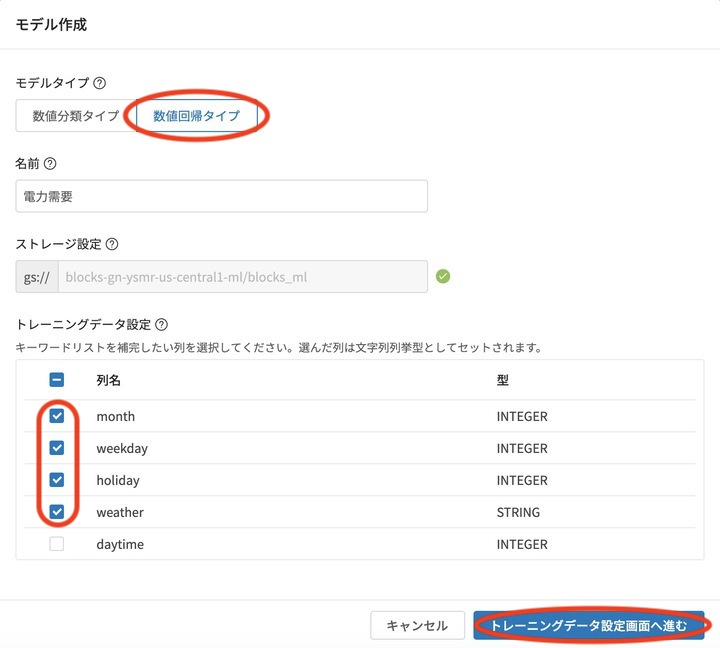
モデル作成の画面が表示されます。
数値回帰 を選択し、トレーニングデータ設定のキーワードリスト補完の設定で上の4項目にチェックを入れて、 トレーニングデータ設定画面へ進む をクリックします。
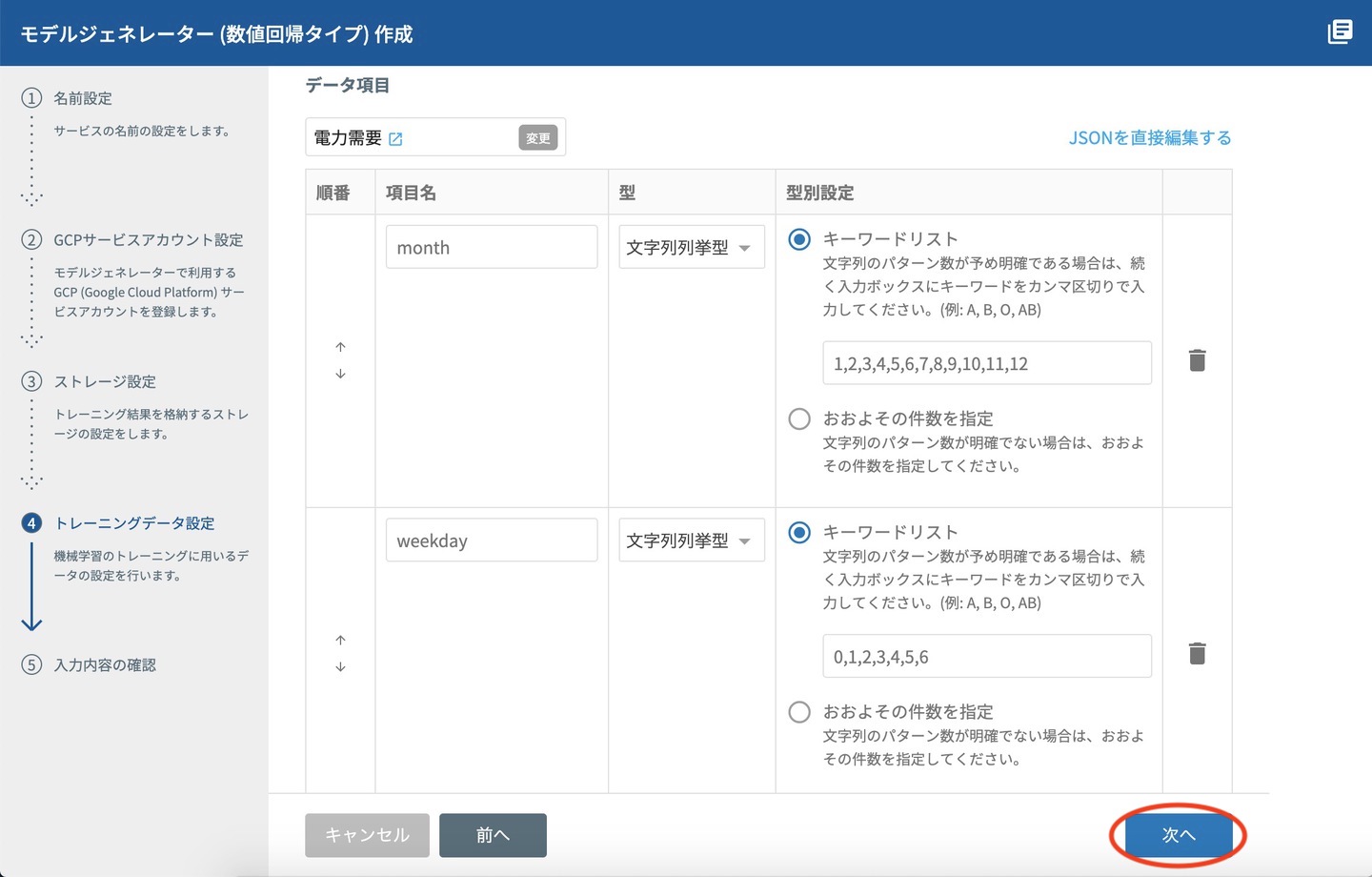
トレーニングデータ設定画面が表示されたら、そのまま 次へ をクリックします。
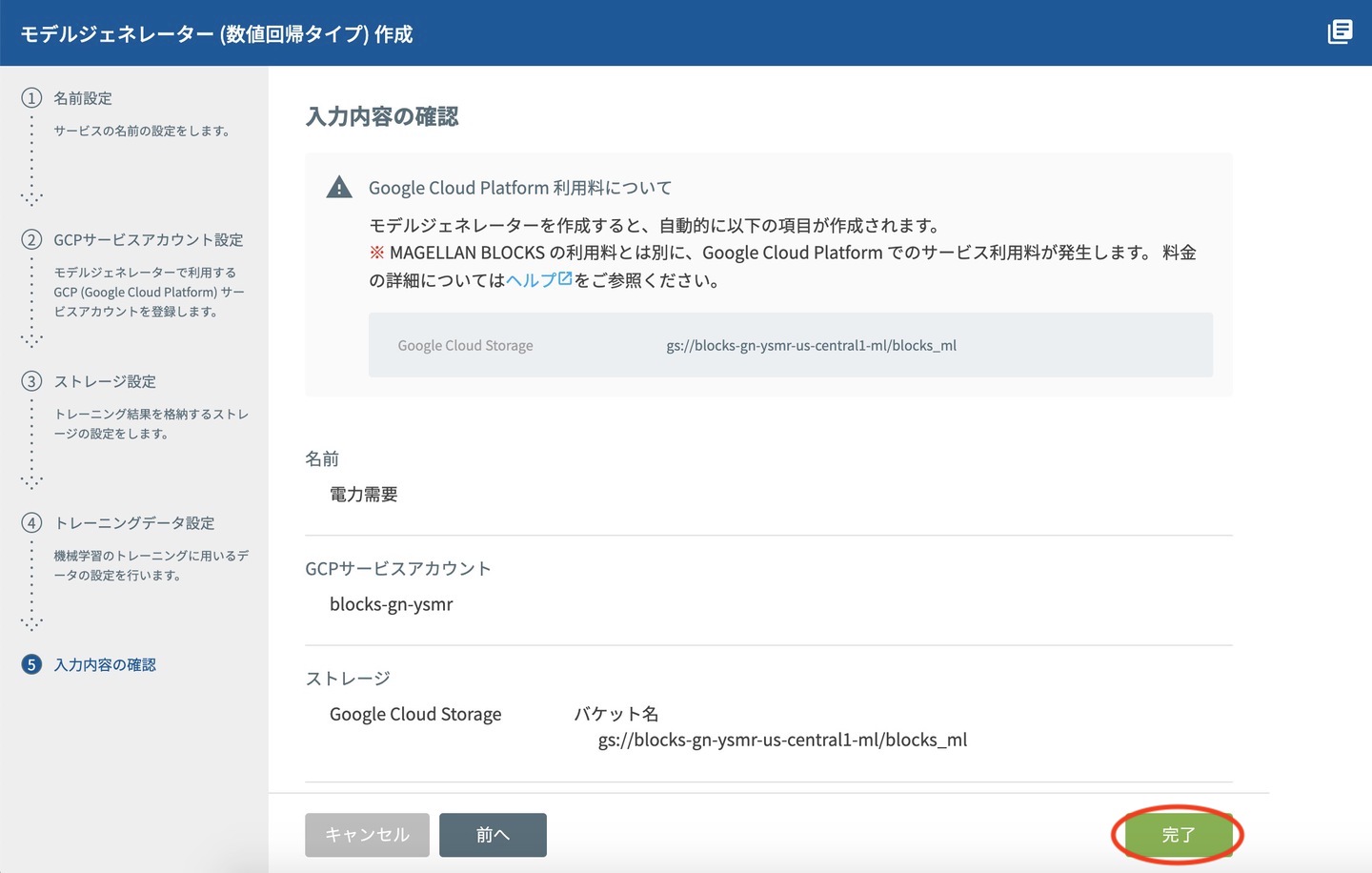
入力内容確認画面が表示されるので、完了 をクリックし、確認画面でOKを押すと、モデルジェネレーターができあがります。
モデルジェネレーターができあがったら、トレーニング開始 をクリックします。
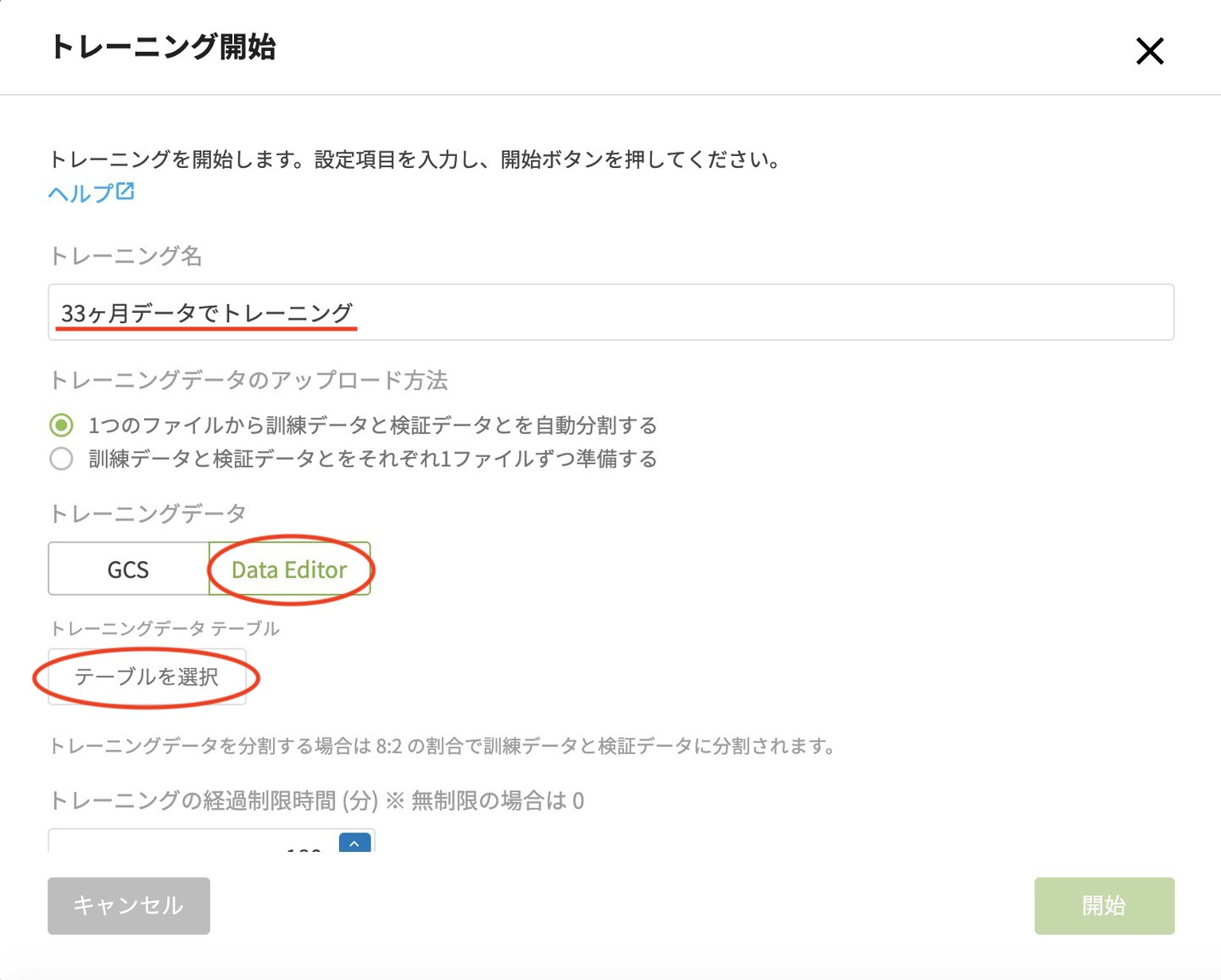
トレーニング名を入力し、トレーニングデータで DataEditor を選んだら、テーブルを選択 をクリックします。
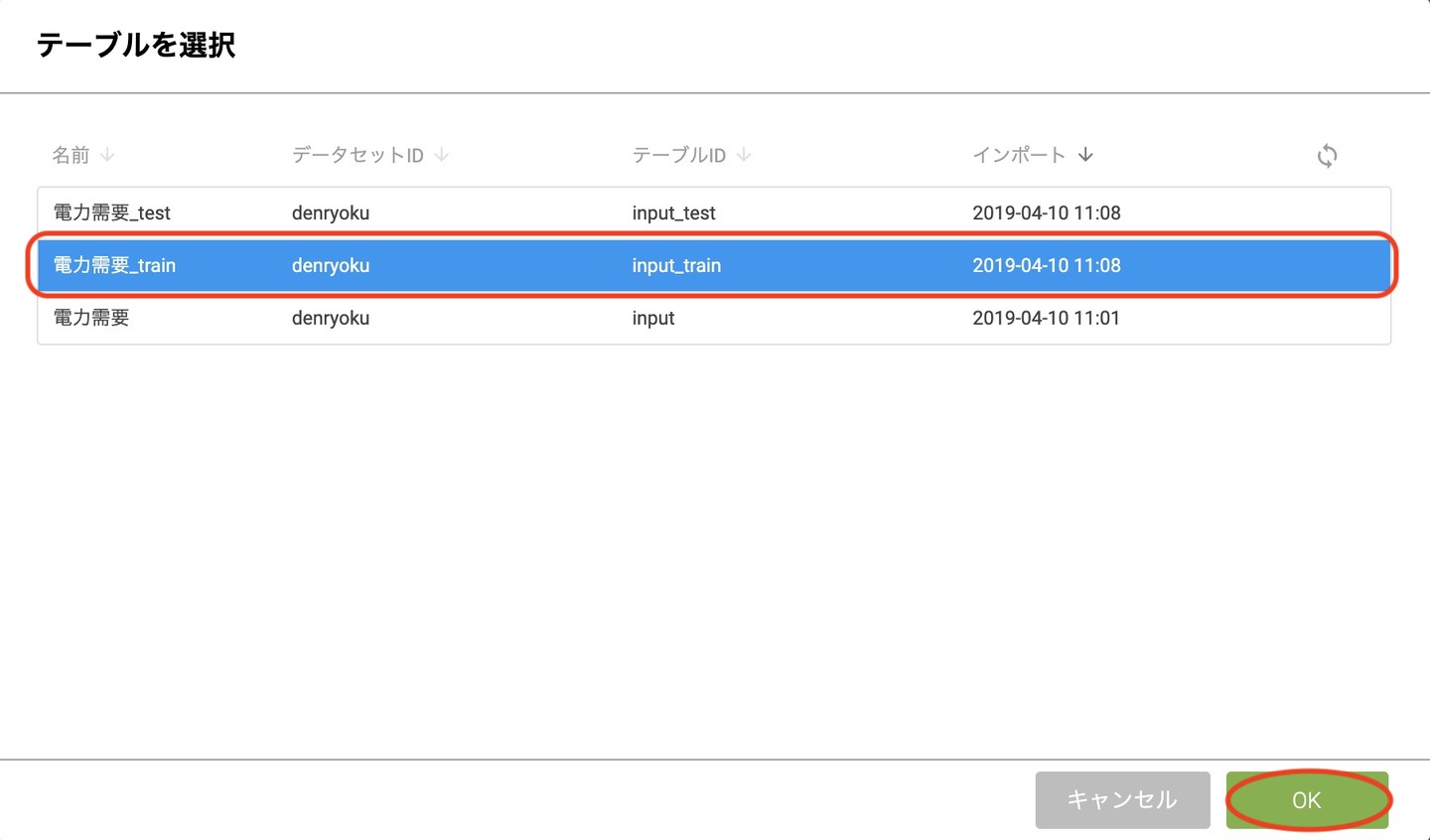
テーブルの選択画面では、 _train で終わるテーブルを選択します。
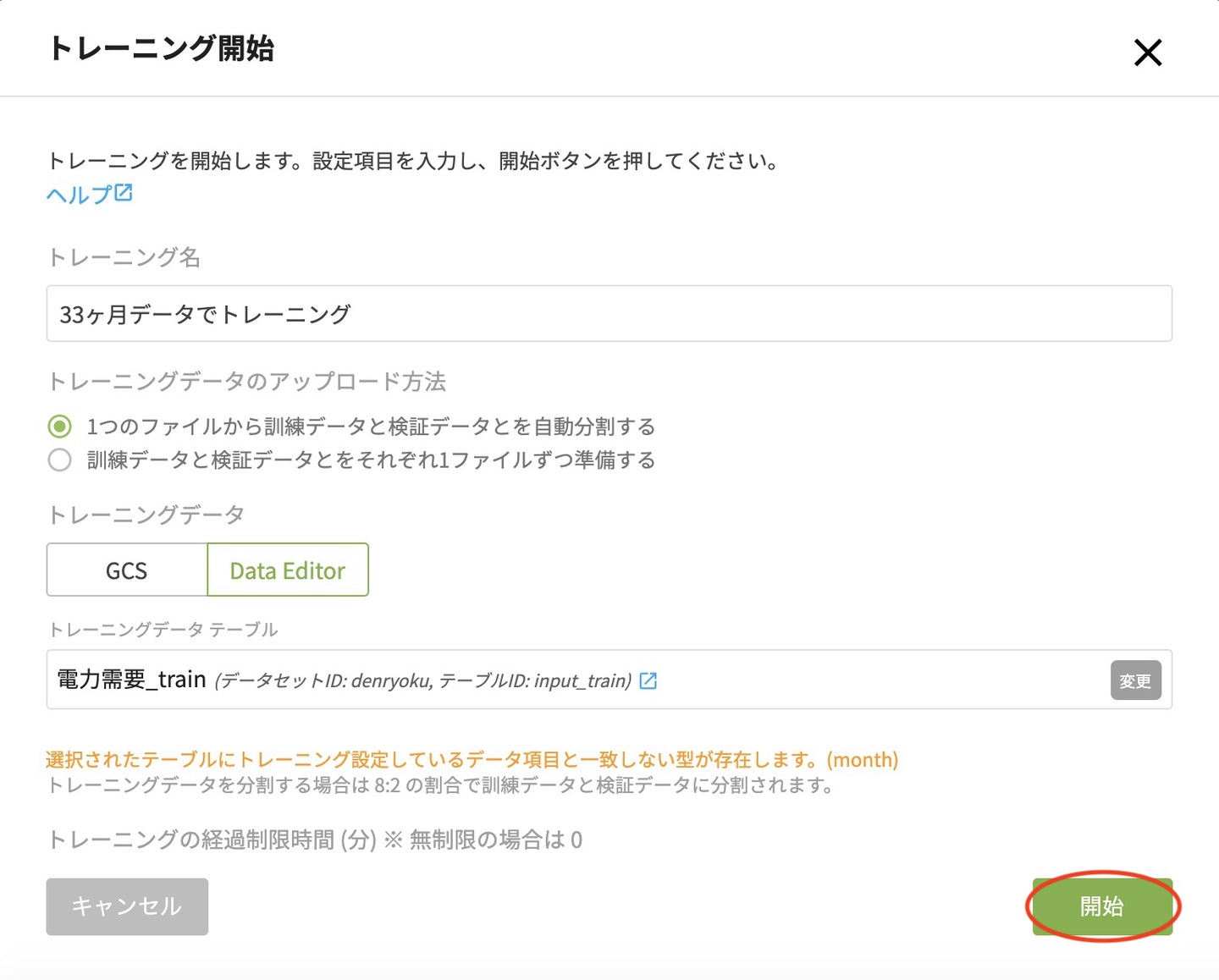
トレーニング開始画面に戻ったら、開始 をクリックしてトレーニングを開始させます。
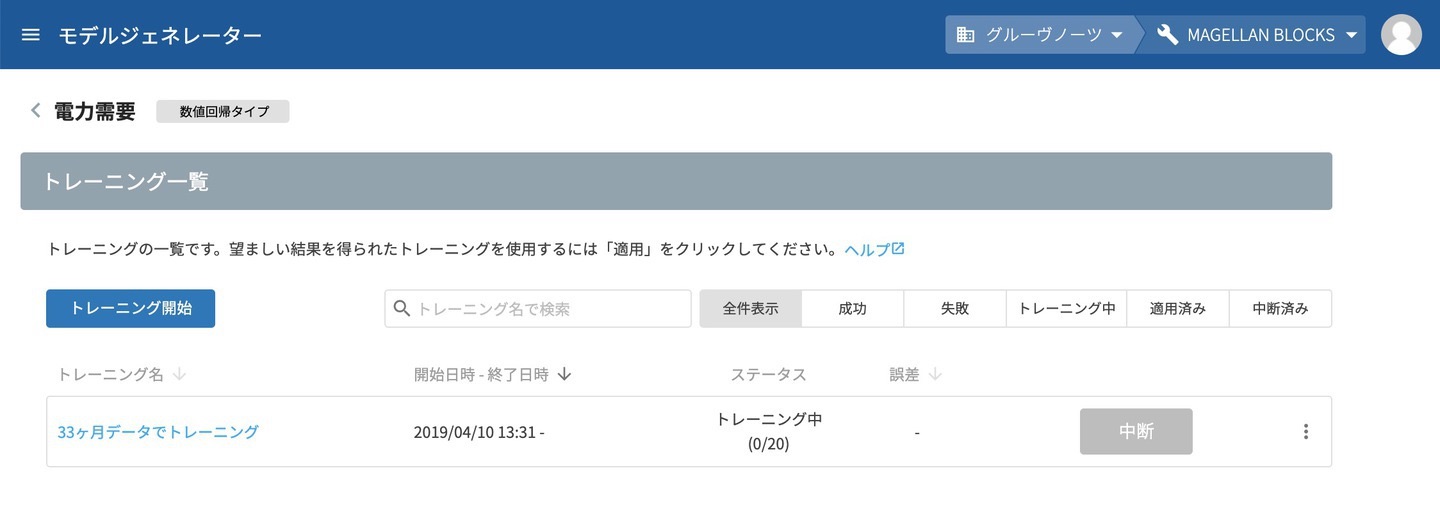
トレーニングが開始されると、トレーニング一覧に表示されます。

トレーニングが完了すると 成功 と表示されます。

適用対象を 本番用 に変更して 適用 をクリックします。

適用処理が終了すると 本番用(適用済み) と表示され、予測に利用することができるようになります。
4.予測用データで予測する
学習済みのモデルができたので、予測用データを利用して予測します。
まずは、フローデザイナーに名前をつけて作成します。

作成したフローデザイナーをクリックして開きます。
フローデザイナーが開いたら、ヘッダーにある フローテプレート作成 をクリックします。
ここからはウィザードに従い、フローを作成します。
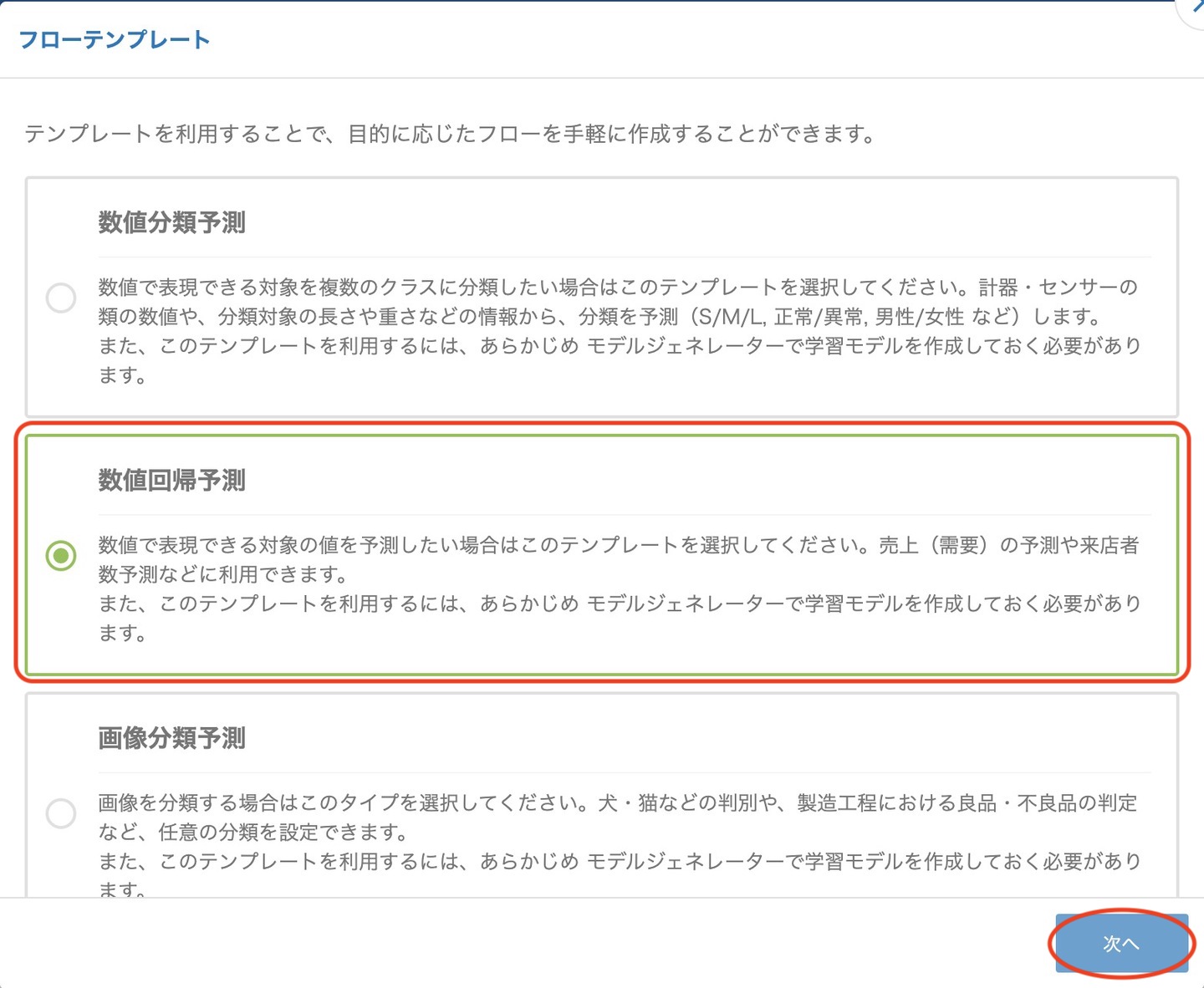
まずは、予測モデルのタイプを選択します。ここでは 数値回帰予測 を選択します。
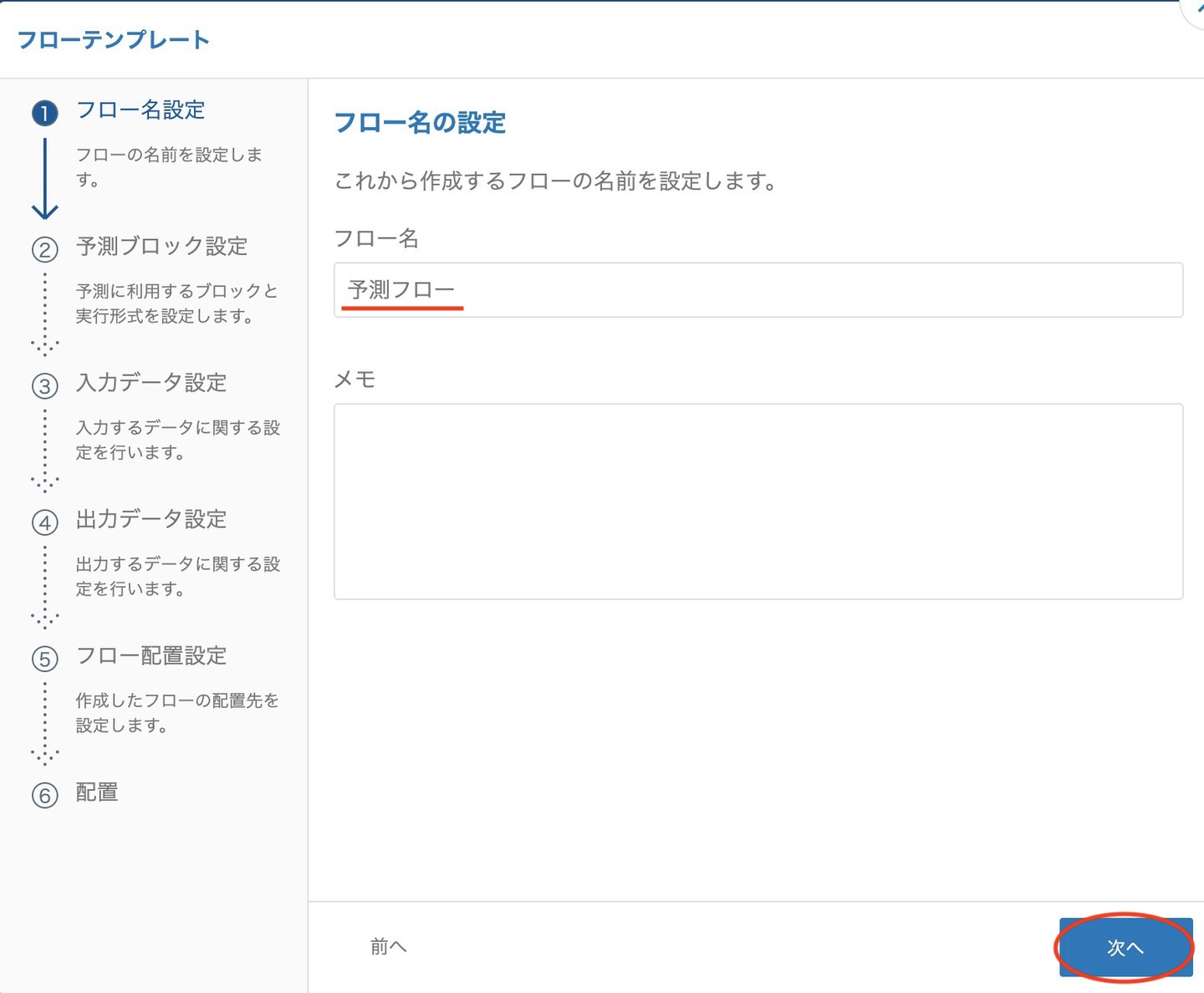
続いて、フロー名を入力します。
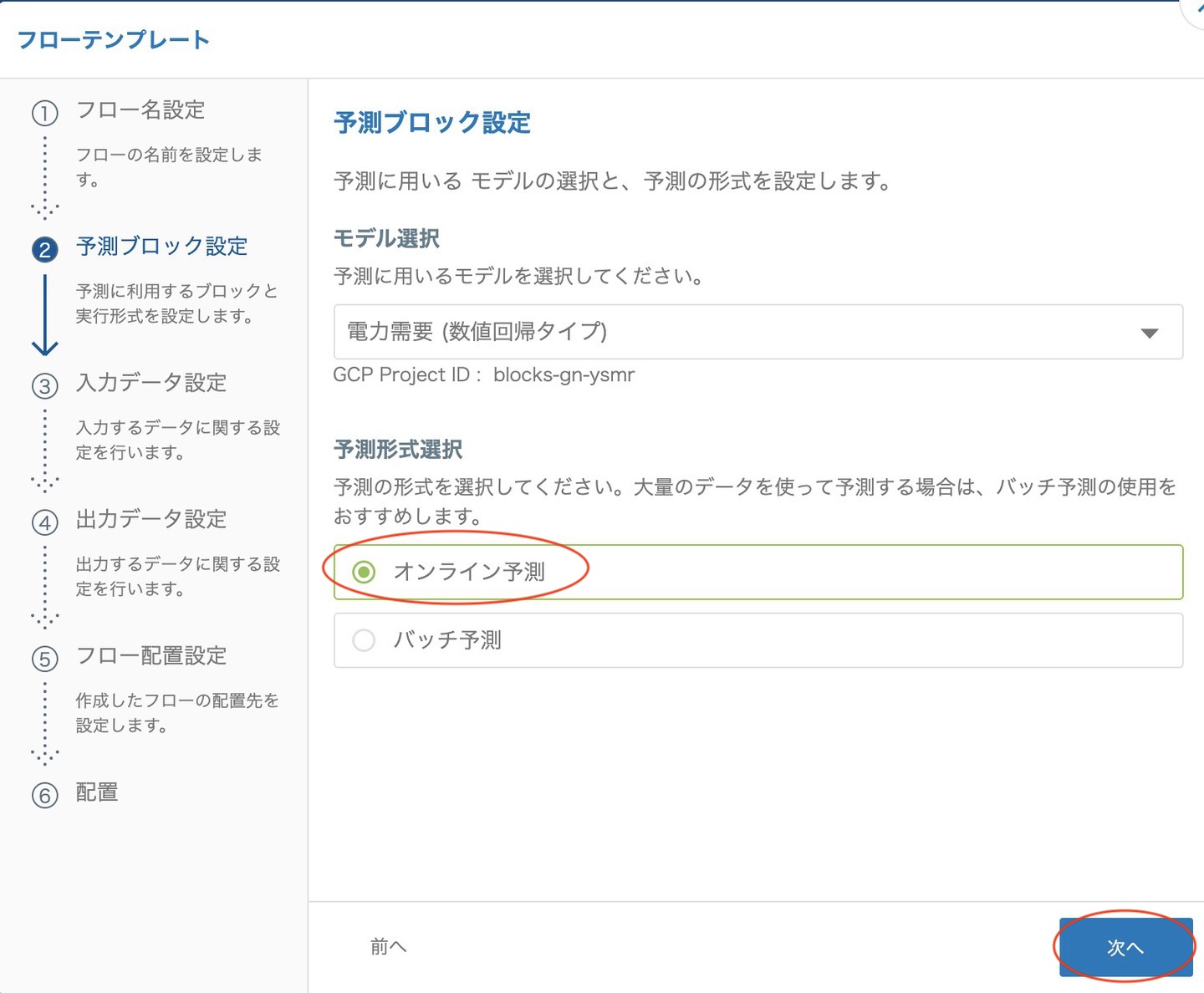
作成した予測モデルを選択し、予測形式には オンライン予測 を選択します。
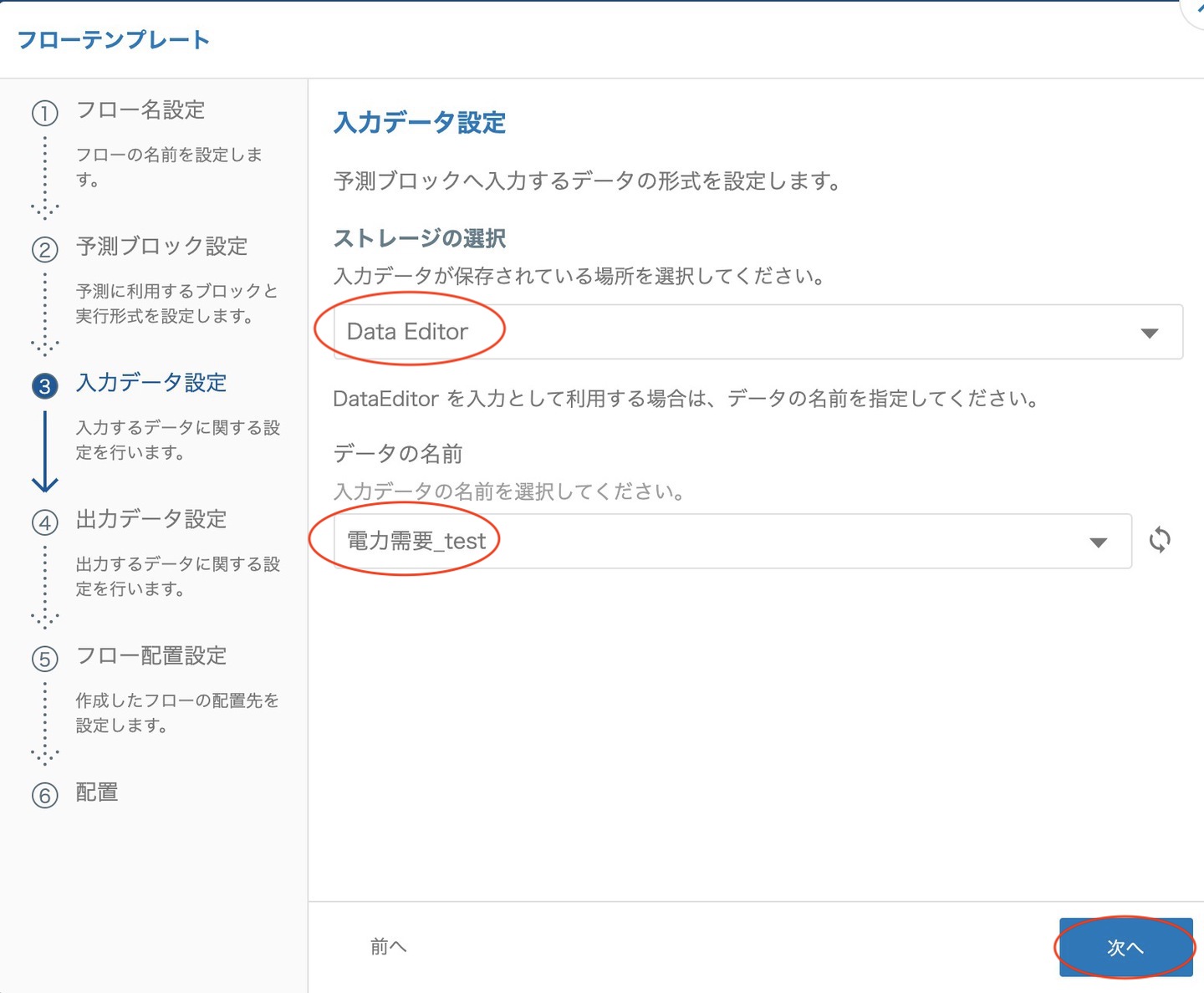
入力データ設定では DataEditor を指定し、 _test で終わるテーブルを選択します。
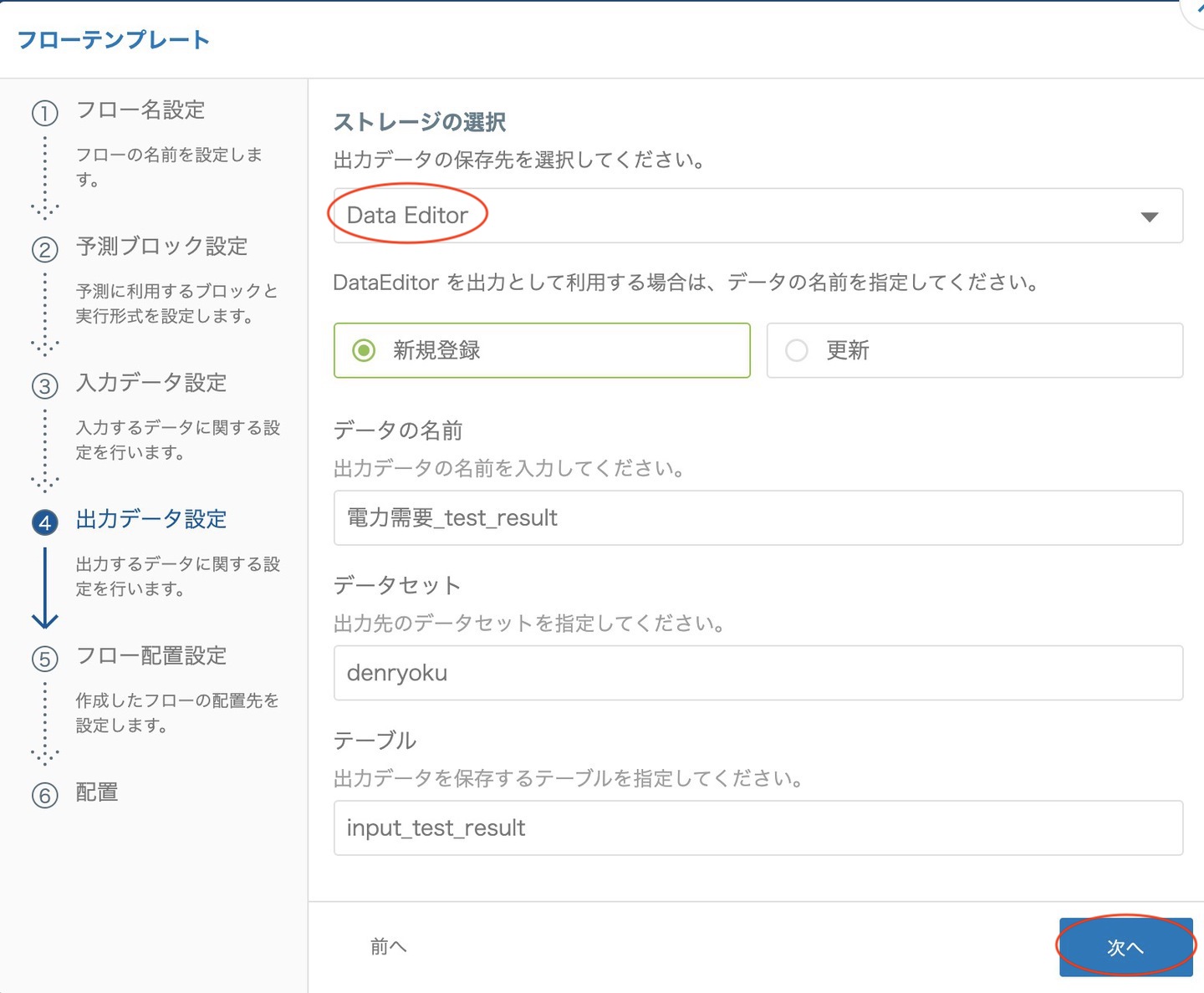
出力データ設定では DataEditor を指定すると、自動的に出力先の設定が行われます。
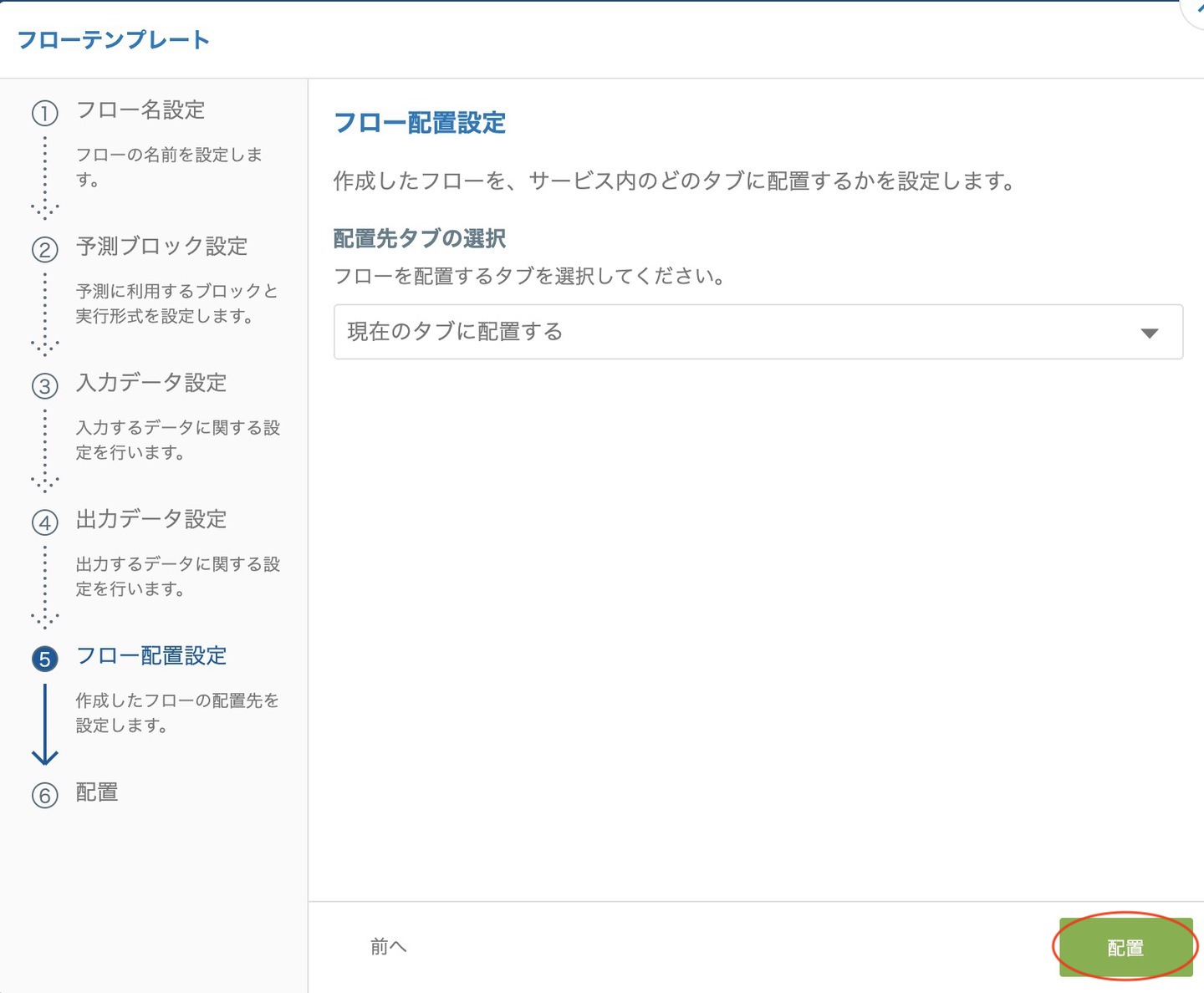
配置先はそのままに 配置 をクリックします。
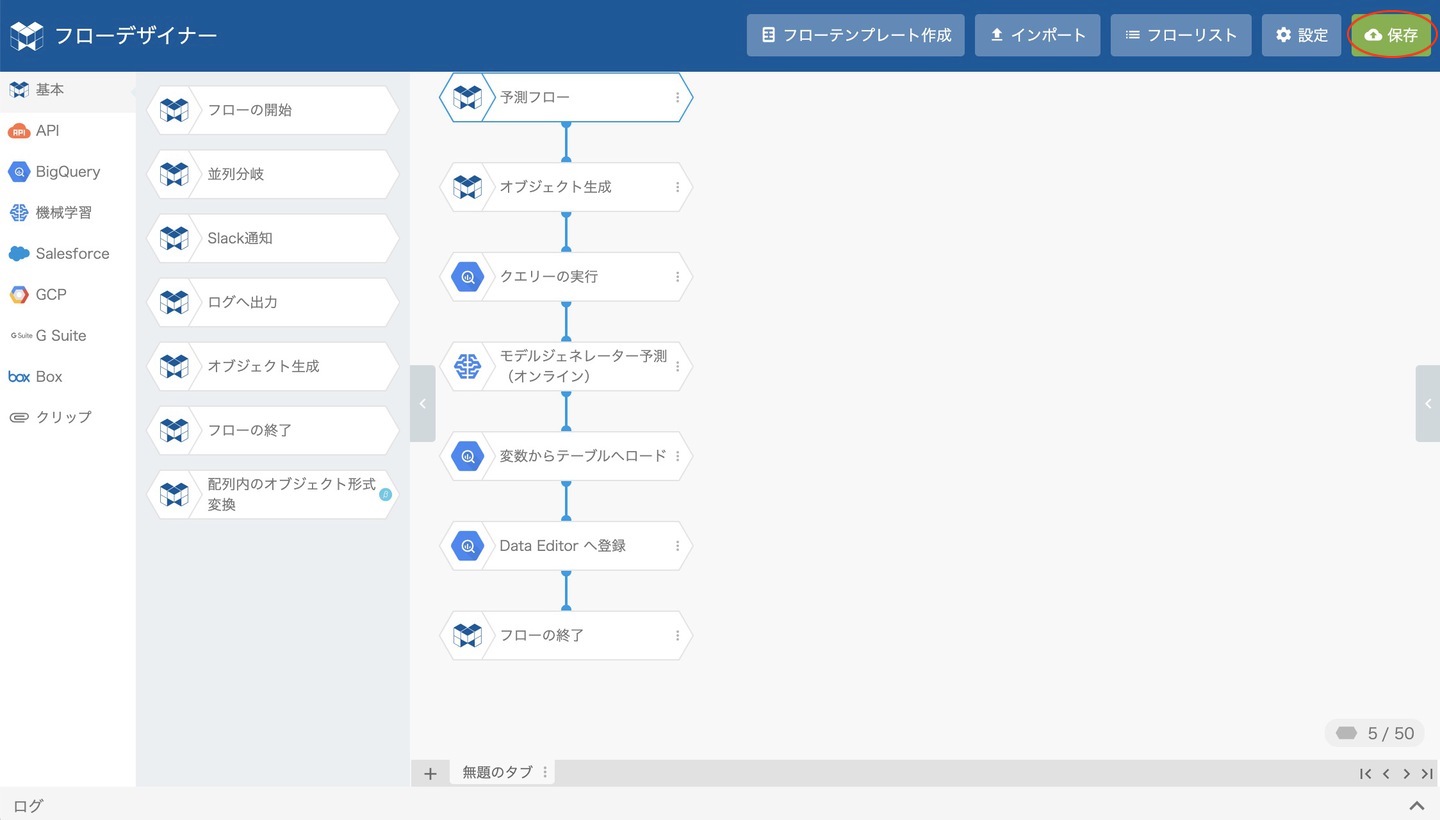
フローデザイナーの編集パネルにフローが配置されるので、ヘッダーの 保存 をクリックします。
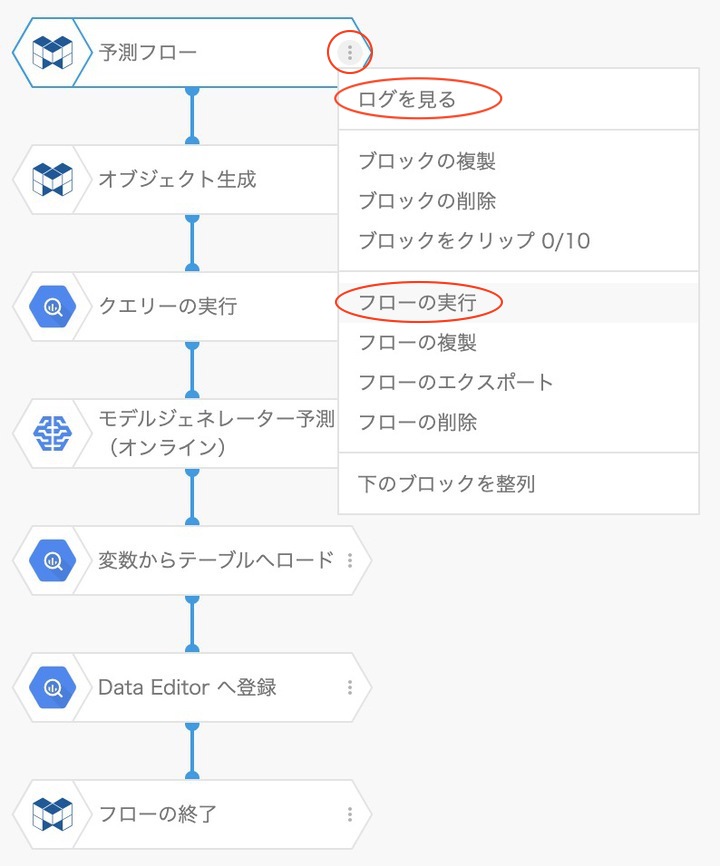
フローが保存されたら、フローのブロックメニューから フローの実行 をクリックして処理を開始します。
続いて、同メニューの上にある ログを見る をクリックしてログパネルを表示します。
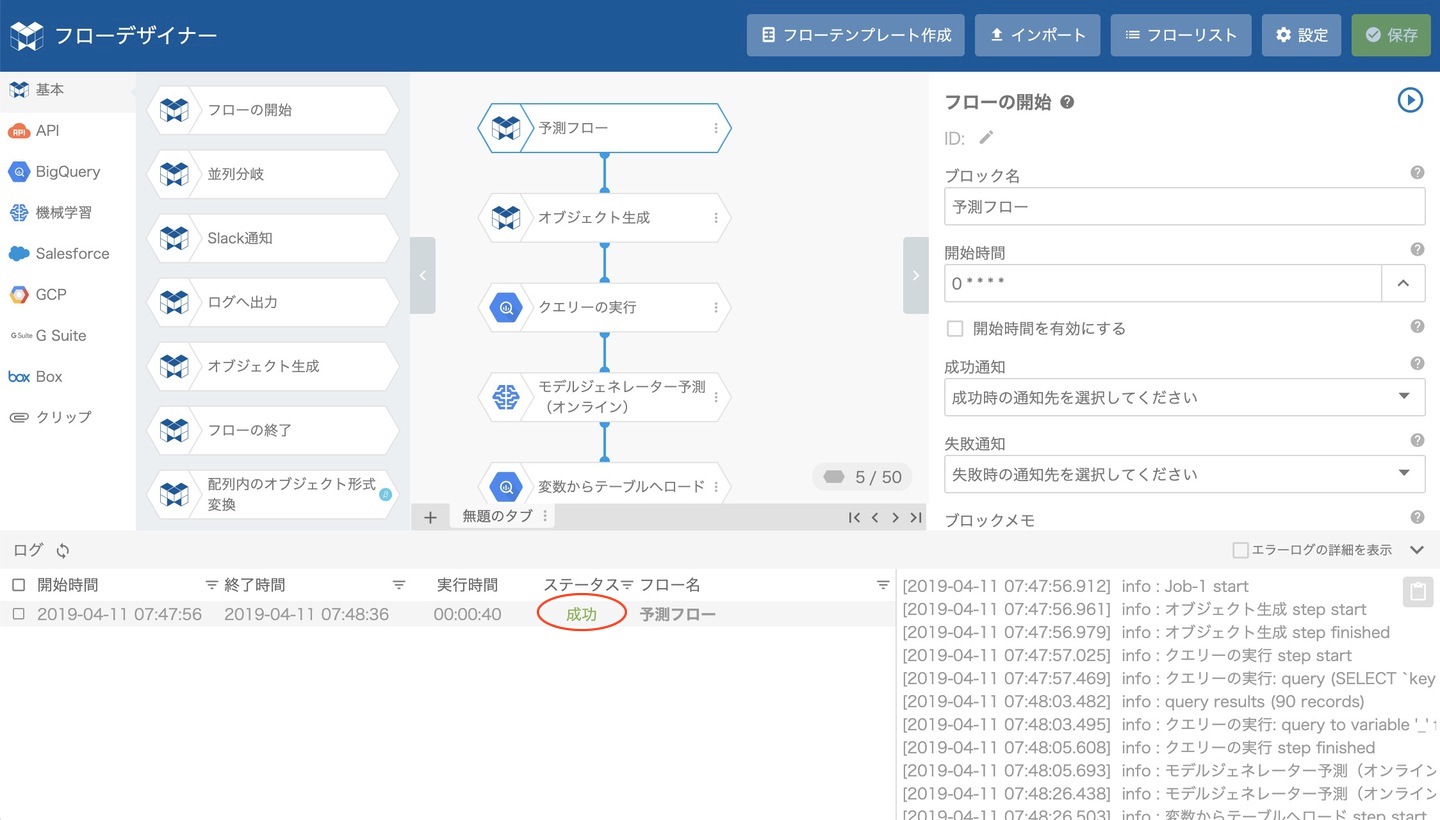
ログパネルでステータスが成功になったのを確認したら、予測完了です。予測結果を確認します。
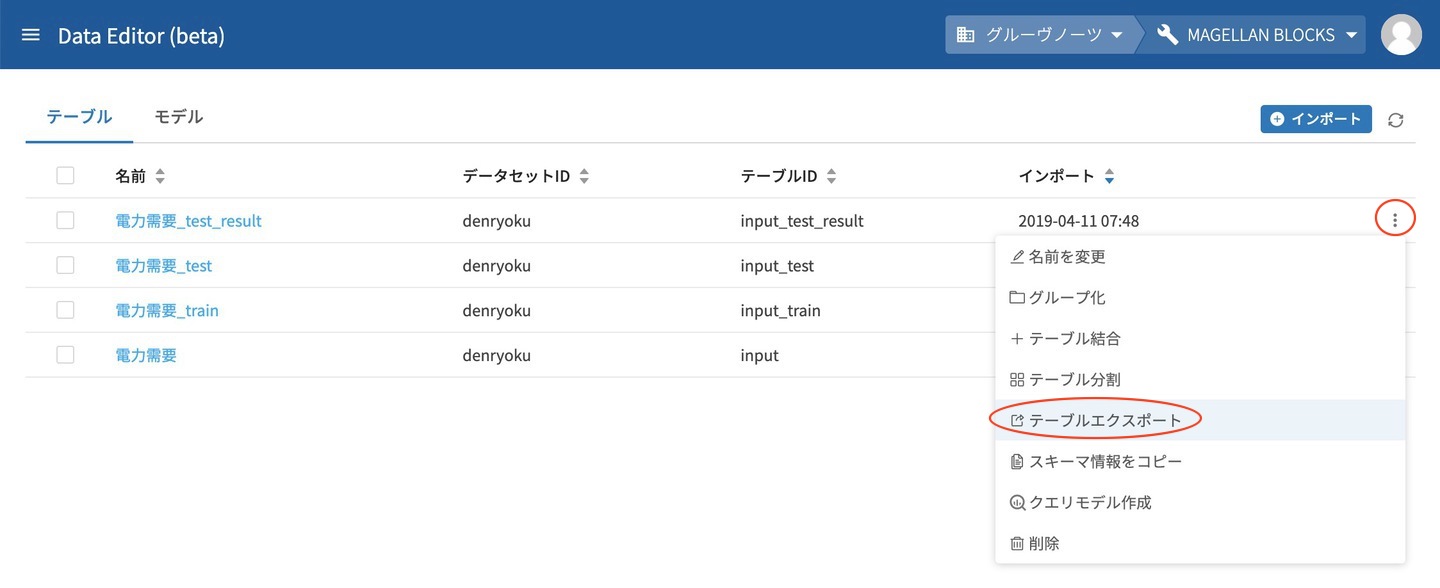
DataEditorを開くと予測結果のテーブルが出力されています。
テーブル名の右端にあるメニューから テーブルエクスポート をクリックします。
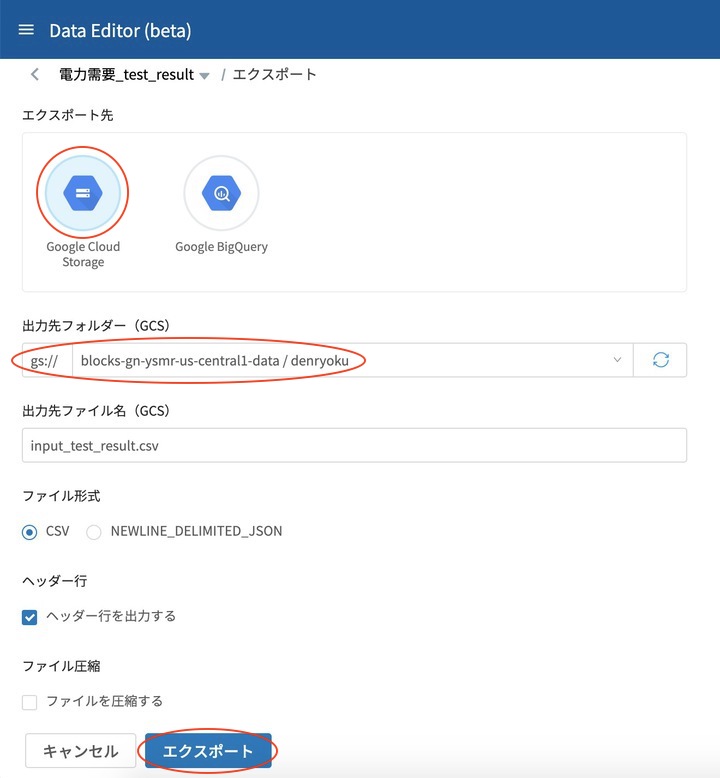
表示されたエクスポート画面から、エクスポート先にGoogle Cloud Storage を選び出力先フォルダーを指定したら、エクスポート をクリックします。
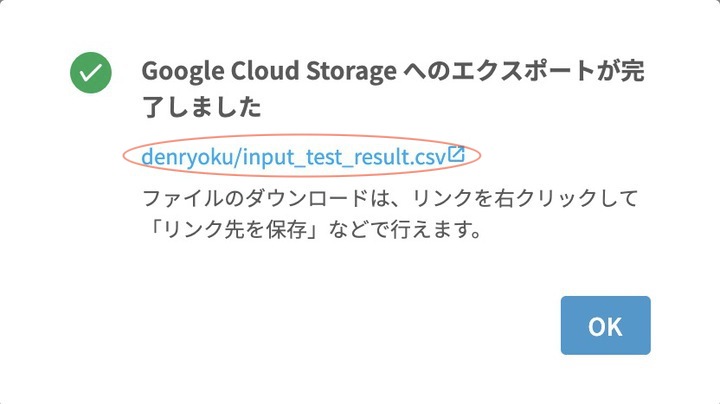
エクスポート完了画面に表示される 青字 のファイル名をクリックすると、CSVファイルがダウンロードされます。
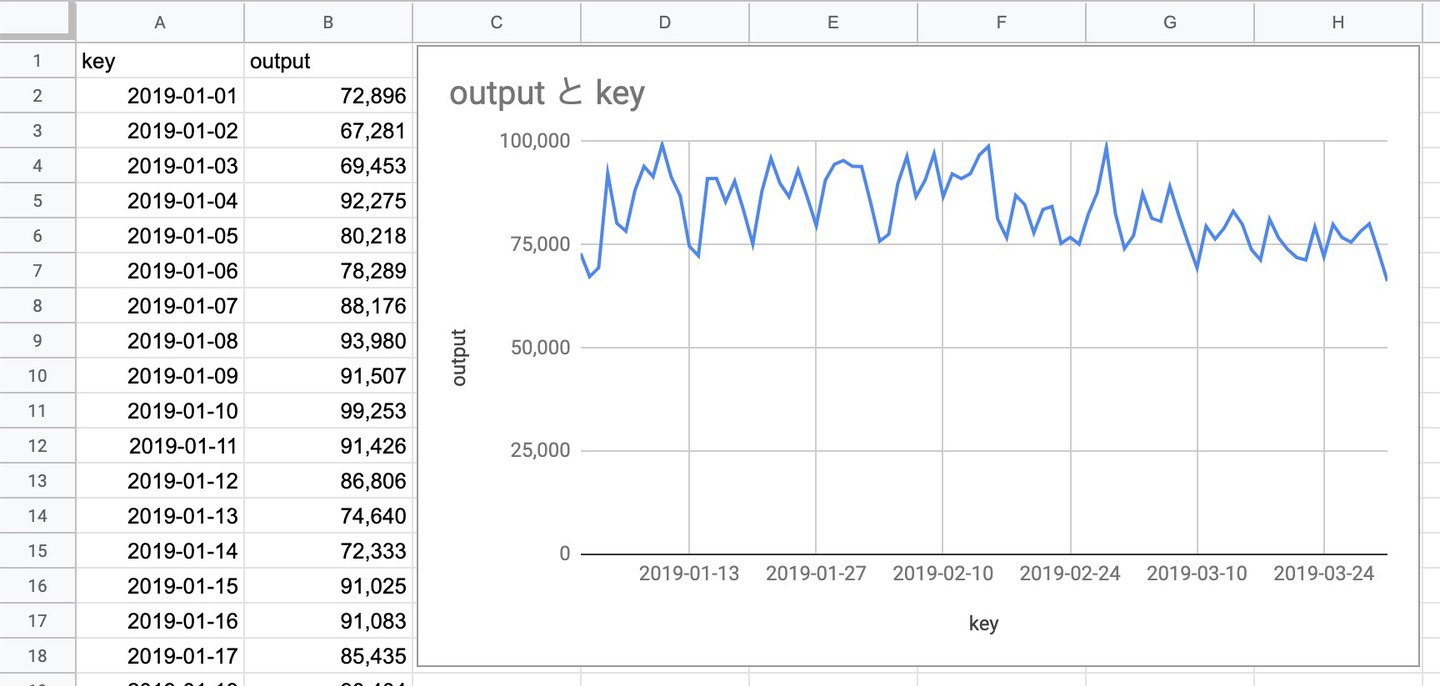
ダウンロードされたCSVファイルをExcelなどの表計算ソフトでグラフ化すると、3か月分の電力需要の予測ができたことがわかります。
終わりに
動画やこの記事を見ていただいたとおり、MAGELLAN BLOCKSを使って需要予測をする手順が非常にシンプルになってきました。
製品ができたばかりの頃は専門知識はいらないものの、手入力の部分も多く大変でしたがかなり楽になったと思います。
今後も、より使いやすいMAGELLAN BLOCKSにしていくように、お客さまと製品開発のエンジニアと橋渡しをしていこうと思います。
※本ブログの内容や紹介するサービス・機能は、掲載時点の情報です。