はじめに
このドキュメントは、文書検索エンジン(文書検索タイプ)作成時の各画面について解説しています。各画面に「ヘルプ」と書かれたリンクがあり、そのリンク先がこのドキュメントです。
文書検索エンジンの使い方については、「文書検索エンジンの使い方(文書検索タイプ)」を参照願います。
GCPサービスアカウント設定
info_outlineこのステップ(画面)は、セルフサービスプランのみの機能です。フルサービスプランでは、このステップ(画面)は、ありません。
この画面では、以下の設定を行います。
- Google Cloud Platform(GCP)のサービスアカウントの選択
- 文書検索エンジンの作成に必要なGoogle各種APIの有効化
- GCPサービスアカウントの権限確認と適切な権限付与
- 文書検索アプリ用Firebase open_in_newの有効化
GCPサービスアカウント選択
文書検索エンジン(文書検索タイプ)は、お客さまのGCPプロジェクトに、BLOCKSが環境を自動で構築し運用します。BLOCKSからGCPプロジェクトを操作するためには、そのプロジェクトに対してオーナー権限を持つGCPサービスアカウントが必要です。
ここでは、GCPプロジェクトに対してオーナー権限を持つGCPサービスアカウントを選択してください。
info_outlineGCPサービスアカウントの作成については、基本操作ガイドの「Google Cloud Platformのサービスアカウントキーを作成する」を参考にしてください。このページの作成例では、編集権限を指定していますが、その部分でオーナー権限を指定してください。
APIの有効化
[loop確認]ボタンの前にチェックマーク(check_circle)が付いていないAPIがある場合は、以下の操作を行います。
- [APIをまとめて有効化する]ボタンをクリックします。
- 別タブにGCPコンソールの画面が開きます。
- GCPコンソール画面内の[続行]ボタンをクリックします。
- 「APIは有効になっています」というメッセージが表示されたら、GCPコンソールの画面を閉じて、BLOCKSの画面に戻ります。
上記操作が終わったら、check_circleが付いていないAPIの[loop確認]ボタンをクリックします。[loop確認]ボタンの前にcheck_circleが付くことを確認してください。この操作をcheck_circleが付いていないすべてのAPIに対して繰り返してください。
もし、check_circleが付かない場合は、しばらく時間をおいてから[loop確認]ボタンをクリックしてください。状況によっては、すぐにはcheck_circleが付かない場合もあります。その場合は、 check_circleが付くまで、以下の操作を繰り返してください。
- しばらく時間をおく
- [loop確認]ボタンをクリックする
error_outlineが表示され続ける原因としては、APIが有効化されていないことの他に、以下のことが考えられます。
-
対象のGCPプロジェクトの課金が有効になっていない。
GCPコンソールのメニュー(GCPコンソール左上のmenu)の[お支払い]で確認します。もし、課金が有効になっていない場合は、課金を有効にします。
アカウントの確認
[loop確認]ボタンの前にチェックマーク(check_circle)が付いていない場合は、以下の操作を行います。
- [アプリケーション作成権限]横のopen_in_newをクリックします。
- 別タブにGCPのIAMの画面が開きます。
- 対象となるGCPサービスアカウント右端のcreateをクリックします。
- 役割をProjectの[オーナー]に変更します。
- [保存]ボタンをクリックします。
- GCPのIAM画面を閉じて、BLOCKSの画面に戻ります。
上記操作が終わったら、[loop確認]ボタンをクリックして、check_circleが付くことを確認します。
もし、check_circleが付かない場合は、しばらく時間をおいてから[loop確認]ボタンをクリックしてください。状況によっては、すぐにはcheck_circleが付かない場合もあります。その場合は、 check_circleが付くまで、以下の操作を繰り返してください。
- しばらく時間をおく
- [loop確認]ボタンをクリックする
Firebaseの有効化
ここでは、文書検索アプリの利用で必要となるFirebase open_in_newにおいて、文書検索アプリ専用のFirebaseプロジェクトを作成します。このステップは、文書検索アプリの利用有無に関わらず必要です。
なおFirebaseは、文書検索アプリのユーザー管理(ログイン認証)で使用してます。
info_outlineFirebaseプロジェクトは、お客さまのGCPプロジェクトに関連付けられます。このプロジェクトの作成および文書検索アプリの利用範囲内においては、料金は発生しません。
error_outlineここで作成したFirebaseプロジェクトは絶対に削除しないでください。ここで作成したFirebaseプロジェクトを削除すると、関連付けられたGCPプロジェクトも削除されてしまいます。例え、文書検索エンジンを削除したとしてもFirebaseプロジェクトは絶対に削除しないでください。
[loop確認]ボタンの前にチェックマーク(check_circle)が付いていない場合は、以下の操作を行います。
- この項目の案内文の「Firebaseプロジェクト名は、必ず*****を選択してください」の*****を覚えておきます。
- [Firebase Management API]横のopen_in_newをクリックします。
- 別タブにFirebaseコンソール画面が開きます。
- [プロジェクトを追加]をクリックします。
- プロジェクト名の選択リストから、先ほど覚えておいた*****を選択します。
- [続行]ボタンをクリックします。
- 以降、画面の案内に沿ってFirebaseプロジェクトの作成を進めてください。
[プランを確認]ボタンをクリックします。
この例では従量課金制プランが選択されていますが、どのようなプランであってもFirebaseプロジェクトの作成および文書検索アプリの利用範囲において、料金は発生しません。
[続行]ボタンをクリックします。
画面内に記載されているとおり、ここで作成するFirebaseプロジェクトを削除すると、GCPプロジェクトも削除されてしまいます。このFirebaseプロジェクトは絶対に削除しないでください。
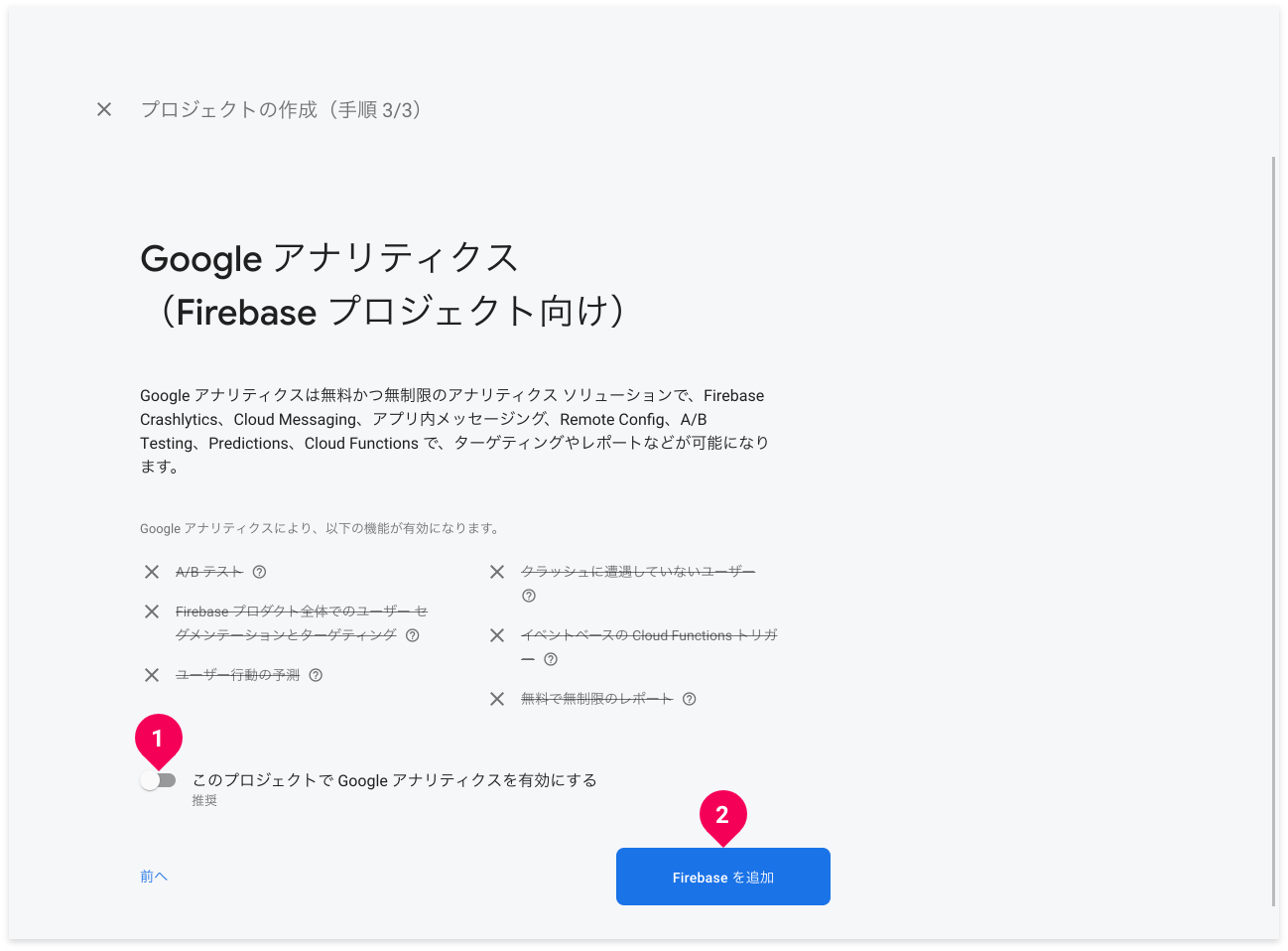
Googleアナリティクスを無効にし、[Firebaseを追加]ボタンをクリックします。
これで、Firebaseプロジェクトの作成が始まります。しばらく時間がかかるので待ちます。

[続行]ボタンをクリックします。
以上で、Firebaseプロジェクトの作成は完了です。
- 文書検索アプリを利用する方のみ:
文書検索アプリの利用を予定している方は、更に以下の操作が必要です。
Firebaseのコンソールopen_in_newを開きます。
作成した文書検索エンジンのGCPプロジェクトIDが表示されているボックス(❶)をクリックします。
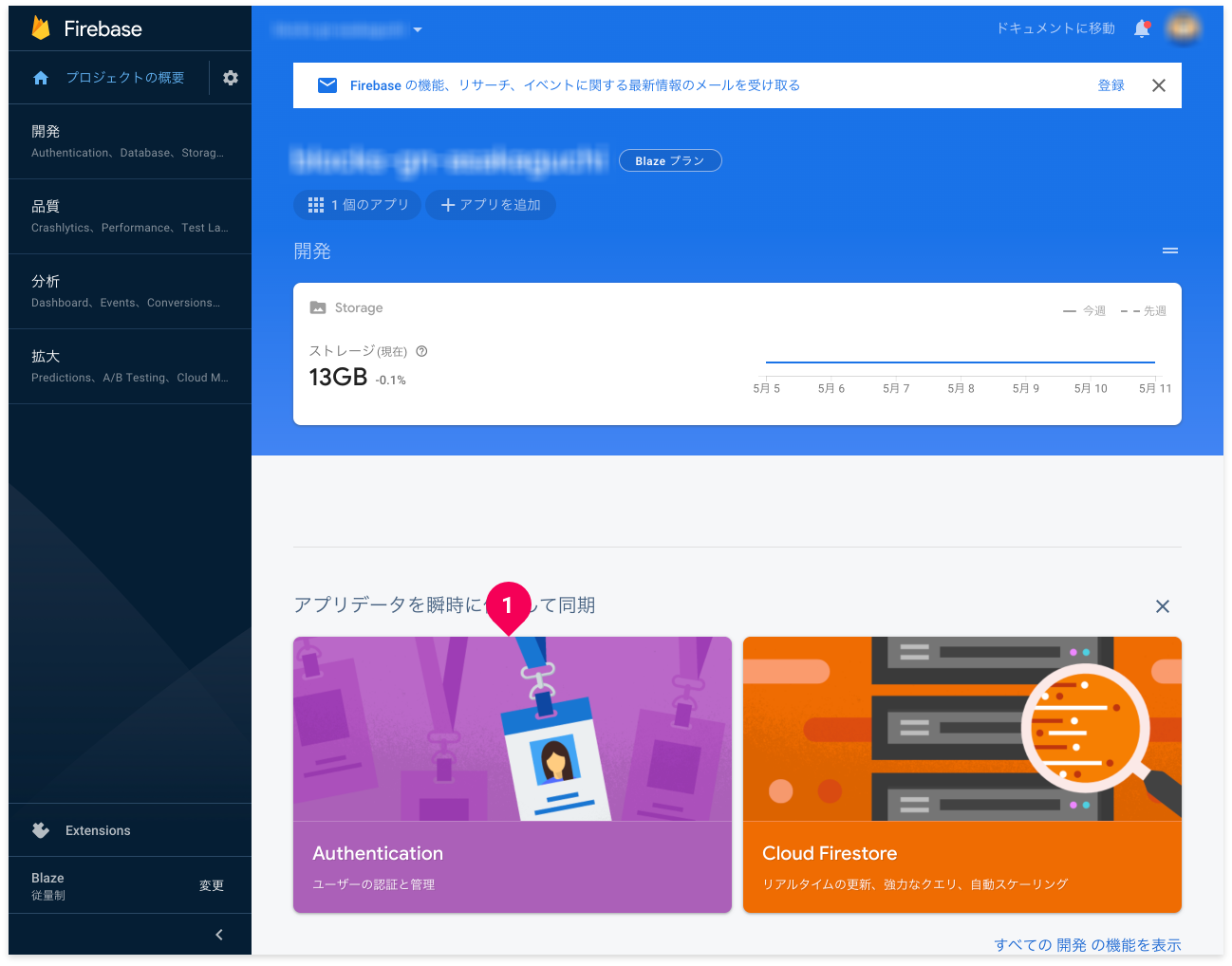
Firebaseプロジェクトの画面から[Authentication]ボックス(❶)をクリックします(画面サイズによっては下への画面スクロールが必要)。
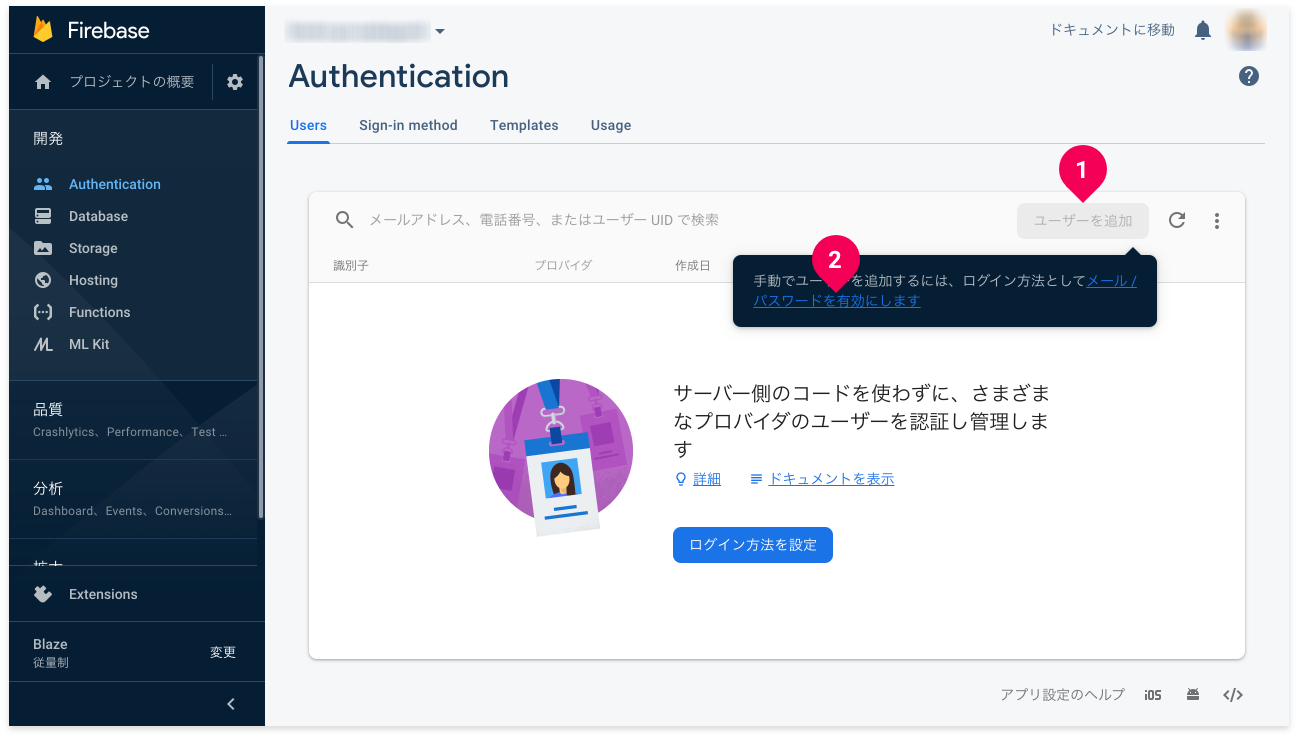
[ユーザーを追加]ボタン(❶)にマウスカーソルを重ねて、[メール/パスワードを有効にします](❷)をクリックします。
- Firebaseコンソール画面を閉じてMAGELLAN BLOCKSの画面に切り替えます。
上記操作が終わったら、[loop確認]ボタンをクリックして、check_circleが付くことを確認します。
オプション設定
この画面では、Google Cloud Platform(GCP)上に構築する検索エンジン用のマシンスペックや簡易検索アプリの利用有無などが設定できます。
サービス識別子設定
BLOCKSが自動で構築するGCP上の各種リソースに付与する識別子を設定します。管理しやすいように、わかりやすい名前を付けてください。なお、省略はできません。
識別子の入力規則は、以下のとおりです。
- 英小文字と数字のみ
- 1文字以上14文字以内
warning識別子は、同一GCPプロジェクト内で重複しないように命名してください。
マシン設定
以下の説明を参考に各値を設定してください。
| 項目 | 説明 |
|---|---|
| ノード数 |
マシン数を1以上の奇数数(1・3・5・7 . . .)で設定します。 開発時やお試し時はノード数1で構いませんが、本運用時はシステムの可用性を高めるために、単一ゾーンでノード数3以上か複数ゾーンの選択を推奨します。複数ゾーンの場合はノード数1でも構いません(ゾーンごとにノードが起動するため、可用性が高くなります)。 |
| マシンタイプ |
メモリサイズや仮想CPU数などの仮想マシンの構成を選択します。 マシンタイプについて詳しくは、Googleのマシンタイプについてのドキュメントopen_in_newを参照願います。 info_outlineGoogleのマシンタイプについてのドキュメントopen_in_newで紹介されているf1-micro/g1-small/n1-highcpu-2は選択できません(マシンタイプの選択リストにありません)。 |
| ディスクサイズ |
ディスクサイズを10から65536の範囲の整数で設定してください。単位は、ギガバイト(GB)です。 |
| ゾーン |
検索エンジン用仮想マシンのゾーンopen_in_newを設定します。 ゾーンは、単一ゾーンでの利用か、複数ゾーンでの利用かが選べます。単一ゾーン利用ではゾーンを選択し、複数ゾーン利用ではリージョンを選択します(複数ゾーン利用ではリージョン内の3つのゾーンが自動選択される)。 複数ゾーンの場合は、選択したリージョン内の3つのゾーンそれぞれに、指定されたノード数分のノードが立ち上がります。 warning複数ゾーンの利用には、別途ライセンスが必要です。複数ゾーンの利用を希望される方は、「お問い合わせ」ページから問い合わせください。 info_outline複数ゾーンで選択できるリージョンは、Googleドキュメントの使用可能なリージョンとゾーンopen_in_newに記載されたリージョンのみです(最新のリストは英語ページを参照)。また、Google App Engine(GAE)起動済みのGCPプロジェクトの場合、既選択済みのリージョンしか選択できません。 現時点では、自作アプリから検索エンジンへのアクセスは、内部向けロードバランサー(Internal LB)経由となります。このため、自作アプリと検索エンジンは、同一ネットワーク・同一リージョン内のゾーンに配置されなければなりません。この点に留意して、ゾーンを選択してください。将来的には、HTTP(S)ロードバランサー経由でのアクセスが可能となるため、この限りではありません。 GAE上で動くアプリと連携させる場合(簡易検索アプリおよび文書検索アプリも含む)は、上記に加えて以下の点に注意してください。
info_outline簡易検索アプリおよび文書検索アプリはGAE上で動作するため、簡易検索アプリおよび文書検索アプリを利用する場合は上記の点に注意願います。 |
文書検索エンジン詳細
この画面では、文書検索エンジン(文書検索タイプ)の文書の登録・更新や文書検索エンジン設定情報の確認、文書検索エンジンの削除などができます。
インデックス一覧
文書検索エンジンには、下図の概念図のように複数のインデックスが作れます。
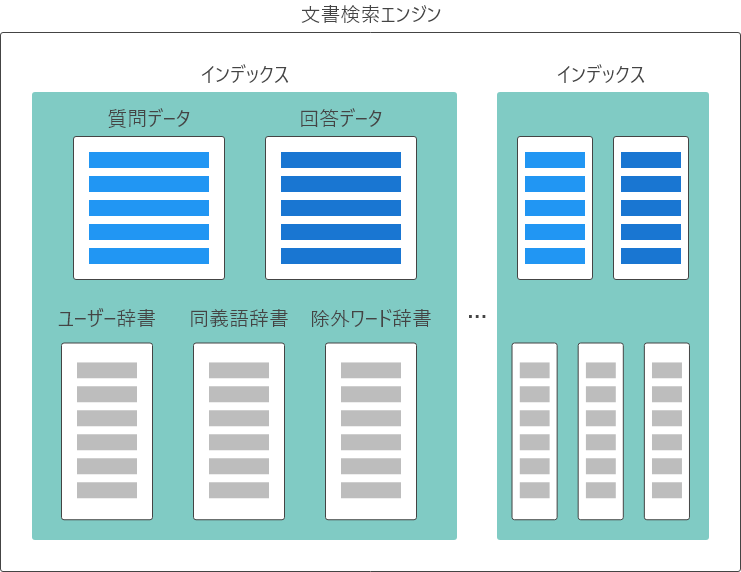
インデックスは、検索対象の文書(質問データ・回答データ)と検索精度を高めるための辞書(ユーザー辞書・同義語辞書・除外ワード辞書)で構成されます。
インデックス一覧では、このインデックスの作成やインデックスごとに以下の操作ができます。
-
ステータスを確認する。
インデックスのステータスが確認できます。ステータスの種類と意味は以下のとおりです。
ステータス 説明 インデックス作成中 インデックスの作成中です。インデックスの作成が始まると、このステータスになります。作成処理が完了するまで、しばらくお待ちください。
インデックス作成済み インデックスの作成が完了しました。このステータスになると、データの登録や簡易検索アプリを開くことができます。
インデックス作成失敗 インデックスの作成に失敗しました。失敗の原因を取り除き、インデックスを削除してから、インデックスを再度作成してください。
失敗の原因としては、以下のいずれかが考えられます。
- 辞書のパスが不正
- 辞書の内容が不正
- BLOCKSの障害
BLOCKSの障害の可能性が高い場合は、辞書はそのままにしてインデックスを削除後、インデックスを再度作成してください。
データ登録中 データ(質問データ・回答データ)の登録中です。データの登録が始まると、このステータスになります。データ登録の完了まで、しばらくお待ちください。
データ登録成功 データの登録が完了しました。このステータスになると、登録したデータによる検索ができます。
データ登録失敗 データの登録に失敗しました。失敗の原因を取り除き、データを再度登録してください。
失敗の原因としては、以下のいずれかが考えられます。
- データのパスが不正
- データの内容が不正
- BLOCKSの障害
インデックス詳細の更新履歴で、データ登録時のログが確認できます。原因究明時の参考にしてください。
BLOCKSの障害の可能性が高い場合は、データを再度登録してください。
インデックス削除中 インデックスの削除中です。インデックスの削除が始まると、このステータスになります。削除処理が完了するまで、しばらくお待ちください。
インデックス削除失敗 インデックスの削除に失敗しました。しばらく時間をおいてから再度削除ボタンをクリックしてください。
-
簡易検索アプリを開く。
[開く open_in_new]リンクをクリックすると、別タブで簡易検索アプリの画面が開きます。
-
インデックスの詳細を確認する。
[詳細を見る]リンクをクリックすると、インデックスの詳細が確認できます。詳しくは、「インデックス詳細」の項で解説しています。
-
検索対象の文書の登録する。
[データを登録する]リンクをクリックすると、検索対象となる文書の登録・更新ができます。詳しくは、「データ登録」の項で解説しています。
-
インデックスを削除する。
[delete削除]ボタンをクリックすると、削除の確認のあと、このインデックスが即刻削除されます。削除後のインデックスの復元はできません。
インデックス作成
インデックスの作成では、[インデックス作成]ボタンをクリックして、インデックス名と同時に辞書の登録も行います。
- インデックス名の規則
- 半角英数字とハイフン(
-)のみ - 先頭は英数字のみ
- 半角英数字とハイフン(
- 辞書
info_outlineインデックスを2つ以上作成する場合は、インデックス用の追加ライセンスが必要です。
ユーザー辞書
ユーザー辞書は、標準の辞書では正しく認識されない単語を登録するための辞書です。
たとえば、「コールセンター」という単語は、「コール」と「センター」に分割されます。これを「コールセンター」として1つの単語として認識させて検索したいときに使用します。また、1つの単語を複数の単語に分割させて認識させたいときにも使用します。
ユーザー辞書のフォーマットは、以下のとおりです。
- ファイル名はアスキー(ASCII)文字のみ指定可能
- テキストファイル
- 文字コードは、BOM open_in_newなしUTF-8のみ
- 改行コードは、CR+LFとLFに対応
- 1行で1つの単語について定義
- 行フォーマット:
複合語,複合語を分割した単語を列挙,分割後の各単語のフリガナを列挙,品詞
- 複合語を分割した単語を列挙では、各単語を空白で区切って列挙
- 分割後の各単語のフリガナを列挙も、同様に空白で区切って列挙
- 使用例
- 単語を分割させない例:
コールセンター,コールセンター,コールセンター,カスタム名詞
- 単語を分割させる例:
バズマーケティング,バズ マーケティング,バズ マーケティング,カスタム名詞
- 単語を分割させない例:
同義語辞書
同義語辞書は、あいまい検索のための辞書です。
たとえば、「検索エンジン」と「サーチエンジン」という単語は別の語句です。どちらの単語を指定しても、双方の単語とマッチさせたいときに使用します。
同義語辞書のフォーマットは、以下のとおりです。
- ファイル名はアスキー(ASCII)文字のみ指定可能
- テキストファイル
- 文字コードは、BOM open_in_newなしUTF-8のみ
- 改行コードは、CR+LFとLFに対応
- 1行で1つの同義語について定義
- 行フォーマット:
同義語 => 単語
- 同義語は、複数指定できます。複数指定する場合は、カンマ(
,)区切りで列挙します。 - 単語も複数指定できます。複数指定する場合は、カンマ(
,)区切りで列挙します。
- 同義語は、複数指定できます。複数指定する場合は、カンマ(
- 使用例
- 「日本経済新聞」を「日経新聞」「日経」でマッチさせる例:
日経新聞,日経 => 日本経済新聞
- 「日本経済新聞」を「日経新聞」「日経」でマッチさせる例:
除外ワード辞書
除外ワード辞書は、検索の対象としない語句を登録するための辞書です。
除外ワード辞書のフォーマットは、以下のとおりです。
- ファイル名はアスキー(ASCII)文字のみ指定可能
- テキストファイル
- 文字コードは、BOM open_in_newなしUTF-8のみ
- 改行コードは、CR+LFとLFに対応
- 1行に1つの除外ワードを定義
- 以下の品詞は検索対象から外れてるため、この辞書での設定は不要
- 接続詞
- 助詞
- 助詞-格助詞
- 助詞-格助詞-一般
- 助詞-格助詞-引用
- 助詞-格助詞-連語
- 助詞-接続助詞
- 助詞-係助詞
- 助詞-副助詞
- 助詞-間投助詞
- 助詞-並立助詞
- 助詞-終助詞
- 助詞-副助詞/並立助詞/終助詞
- 助詞-連体化
- 助詞-副詞化
- 助詞-特殊
- 助動詞
- 記号
- 記号-一般
- 記号-読点
- 記号-句点
- 記号-空白
- 記号-括弧開
- 記号-括弧閉
- その他-間投
- フィラー
- 非言語音
- 使用例
東京 福岡
インデックス詳細
インデックス一覧の[詳細を見る]ボタンをクリックすると表示される画面です。インデックスの詳細が確認できます。
インデックス詳細の画面では、以下の情報が確認できます。
- 基本情報
- 簡易検索アプリURL
簡易検索アプリのURLが確認できます。URLをクリックすると別タブで簡易検索アプリの画面が開きます。 - インデックス名
インデックス名が確認できます。 - ユーザー辞書
登録したユーザー辞書のGCS URLが確認できます。 - 同義語辞書
登録した同義語辞書のGCS URLが確認できます。 - 除外ワード辞書
登録した除外ワード辞書のGCS URLが確認できます。
- 簡易検索アプリURL
- データ更新履歴
データ更新履歴では、データの登録・更新の日時と、データ登録・更新時のログが確認できます。ログは、[ログを表示]リンクをクリックすると、確認できます。 - 作成ログ
インデックス作成時のログが確認できます。 - 削除ログ
インデックス削除時のログが確認できます。削除ログの確認は、インデックスの削除中とインデックスの削除に失敗した時のみ確認できます。
データ登録
[データを登録する]リンクをクリックして、検索対象の文書(データ)を登録します。
登録するデータは、GCS上の所定のバケット内へ事前にアップロードしておく必要があります。所定のバケットは、文書検索エンジン詳細の「このサービスで使用しているリソース」の「Cloud Storage」の項目で確認できます。
info_outline登録するデータは、バケット内にフォルダーを作成し、その中にアップロードできます。その場合、フォルダー名は、アスキー(ASCII)文字のみとしてください。
文書検索エンジン(文書検索タイプ)では、検索対象となる文書を過去の質問と回答のデータに分けておき、これらを関連付けて管理する方式をとっています。なお、データを分けずに、すべての文書を回答データにまとめての登録もできます。
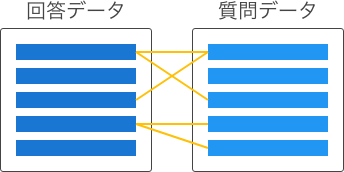
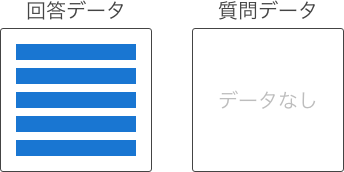
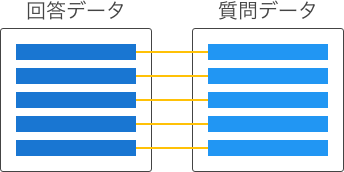
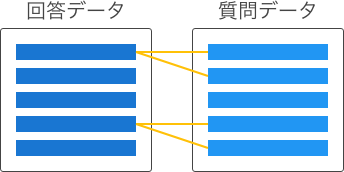
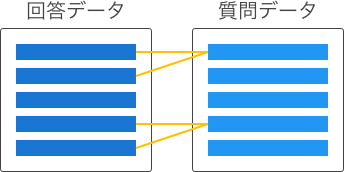
質問データと回答データの関連付けは、関連付け方によって以下のタイプに分けられます。
| 関連付けのタイプ | 説明 |
|---|---|
|
|
回答データのみのため、関連はない。 |
|
双方のデータが1対1に対応している。 |
|
回答データは複数の質問に関連する可能性があるが、質問データは1件の回答にのみ関連する。 |
|
回答データは1件の質問にのみ関連するが、質問データは複数の回答に関連する可能性がある。 |
|
|
回答データは複数の質問に関連する可能性があり、質問データも複数の回答に関連する可能性がある。 |
質問データ
質問データのフォーマットは、以下のとおりです。
- ファイル名はアスキー(ASCII)文字のみ指定可能
- CSV形式のテキストファイル
- 文字コードは、BOM open_in_newなしUTF-8のみ
- 改行コードは、CR+LFとLFに対応
- 各レコード(行)は、3つのフィールドで構成
フィールド 省略 説明 質問ID 不可 質問を特定するための識別子です。
識別子に指定できる文字は、半角英数字・ハイフン(
-)・アンダースコア(_)です。文章 不可 質問の文章です。空文字の指定は可能です。
関連する回答ID 不可 質問に関連する回答データの回答IDを指定します。
複数の回答IDに関連する場合は、コロン(
:)区切りでIDを列挙します(例:a1:a3:a5)。 - ファイルの先頭にヘッダ行が必要
- 関連付けのタイプが「多対1」もしくは「多対多」の場合:
id,body,target_ids
- 関連付けのタイプが上記以外の場合:
id,body,target_id
- 関連付けのタイプが「多対1」もしくは「多対多」の場合:
- 例:
- 関連付けのタイプが「多対1」もしくは「多対多」の場合:
id,body,target_ids q1,"回答ID a1への質問文章その1",a1 q2,"回答ID a1への質問文章その2",a1 q3,"回答ID a2への質問文章",a2 q4,"回答ID a3, a4, a5への質問文章",a3:a4:a5
- 関連付けのタイプが上記以外の場合:
id,body,target_id q1,"回答ID a1への質問文章その1",a1 q2,"回答ID a1への質問文章その2",a1 q3,"回答ID a2への質問文章",a2 q4,"回答ID a3への質問文章",a3
- 関連付けのタイプが「多対1」もしくは「多対多」の場合:
回答データ
回答データのフォーマットは、以下のとおりです。
- ファイル名はアスキー(ASCII)文字のみ指定可能
- CSV形式のテキストファイル
- 文字コードは、BOM open_in_newなしUTF-8のみ
- 改行コードは、CR+LFとLFに対応
- 各レコード(行)は、2つのフィールドで構成
フィールド 省略 説明 回答ID 不可 回答を特定するための識別子です。
識別子に指定できる文字は、半角英数字・ハイフン(
-)・アンダースコア(_)です。文章 可 回答の文章です。
省略された場合は、空文字として扱います。
- ファイルの先頭にヘッダ行が必要
id,body
- 例:
id,body a1,"回答文章その1" a2,"回答文章その2" a3,"回答文章その3" a4,"回答文章その4" a5,"回答文章その5"
接続情報
検索エンジンにアクセスするためのIPアドレスが表示されます(ポート番号は、9200固定)。
IPアドレス横のcontent_copyをクリックすると、IPアドレスがクリップボードへコピーされます。
このIPアドレスは、内部向けロードバランサー(Internal LB)のアドレスです。このため、検索エンジンへのアクセスは、同一ネットワーク・同一リージョン内からのみ可能です。
文書検索アプリ
文書検索アプリのステータス確認や起動・停止の切り替えができます。
warningひとつのGCPプロジェクトで複数の文書検索アプリを起動すると、Firebaseのユーザー情報が共有されます。複数の文書検索アプリ間で、Firebaseのユーザー情報を共有したくない場合は、別のGCPプロジェクトで文書検索アプリを利用してください(文書検索エンジンを別のGCPプロジェクトIDで作成し利用)。
-
[文書検索アプリを起動する]をクリックすると、文書検索アプリを起動できます。
- 文書検索アプリの管理者ユーザーとなるメールアドレスを入力
ここで指定したユーザーには文書検索アプリ利用におけるすべての権限が付与されます。
文書検索アプリの利用には、BLOCKSのログインとは別に文書検索アプリへのログインが必要です。文書検索アプリのユーザー管理は、MAGELLAN BLOCKSのユーザー管理とは別です。文書検索アプリのユーザー管理(ログイン認証)は、FirebaseのAuthenticationサービスを利用しています。
- ライセンス(人数)を選択
- [起動する]ボタンをクリック
- 文書検索アプリの管理者ユーザーとなるメールアドレスを入力
-
[文書検索アプリを無効化する]をクリックすると、文書検索アプリを停止できます。
文書検索アプリが起動中の場合は、文書検索アプリのURLが表示されます。このURLをクリックすると、文書検索アプリが別タブに開きます。
簡易検索アプリ
簡易検索アプリの情報が確認できます。
簡易検索アプリの有効・無効の切り替えもできます。
-
簡易検索アプリが有効の状態では、[簡易検索アプリを無効にする]をクリックすると、簡易検索アプリを無効にできます。
-
簡易検索アプリが無効の状態では、[簡易検索アプリを有効にする]をクリックすると、簡易検索アプリを有効にできます。
簡易検索アプリを有効にする場合は、必ずパスワードの設定を求められます。一度、パスワードを設定していた場合でも、あらためて設定しなければなりません。
info_outline簡易検索アプリのパスワードを忘れた場合は、簡易検索アプリをいったん無効化して再び有効化することで、パスワードの再設定ができます。
ステータス欄で、簡易検索アプリの有効・無効の状態が確認できます。ステータスの種類と意味は以下のとおりです。
| ステータス | 説明 |
|---|---|
| 有効にしています |
簡易検索アプリを有効にしている最中です。簡易検索アプリの有効化が始まると、このステータスになります。 |
| 有効 |
簡易検索アプリが利用可能です。 |
| 有効化に失敗しました |
簡易検索アプリの有効化に失敗しました。以下の手順で、簡易検索アプリの有効化をやり直してください。
|
| 無効化しています |
簡易検索アプリを無効にしている最中です。簡易検索アプリの無効化が始まると、このステータスになります。 |
| 無効 | 簡易検索アプリは利用できません。 |
| 無効化に失敗しました |
簡易検索アプリの無効化に失敗しました。以下の手順で、簡易検索アプリの無効化をやり直してください。
|
設定情報
文書検索エンジン作成時の設定情報が確認できます。
名前については、[サービス名を変更する]をクリックして、名称の変更ができます。
このサービスで使用しているリソース
この文書検索エンジンで使用しているGCP上のリソースが確認できます。
これらのリソースは、お客さまのGCPプロジェクト上に作成されています。
errorこれらのリソースは削除しないでください。削除すると文書検索エンジン(文書検索タイプ)が機能しなくなります。
サービスの削除
[削除]をクリックすると、削除の確認のあと、この文書検索エンジンが即刻削除されます(関連するリソースも削除されます)。削除後の文書検索エンジンは復元できません。
削除は、簡易検索アプリの有効化・無効化中にはできません。
info_outline削除にはしばらく時間がかかります。削除が完了するまで、BLOCKSの操作はできません。削除が完了するまで、そのままお待ちください。