はじめに
本ドキュメントでは、文書検索エンジンの作成から検索を試すところまでを解説しています。サンプルデータを使って試していくことで、以下のことが学べるようになっています。
- 文書検索エンジンの作り方が学べます。
- 付属の簡易検索アプリの使い方が学べます。
最後に、[Web APIの紹介]と題し文書検索エンジンを利用するAPIについて簡単に解説しています。文書検索エンジンを使ったアプリを開発する際の参考としてお使いください。
文書検索エンジン(文書検索タイプ)とは何か
文書検索エンジン(文書検索タイプ)では、お客さま専用の文書検索エンジンをお客さまのGoogle Cloud Platform(GCP)上に構築し提供します。
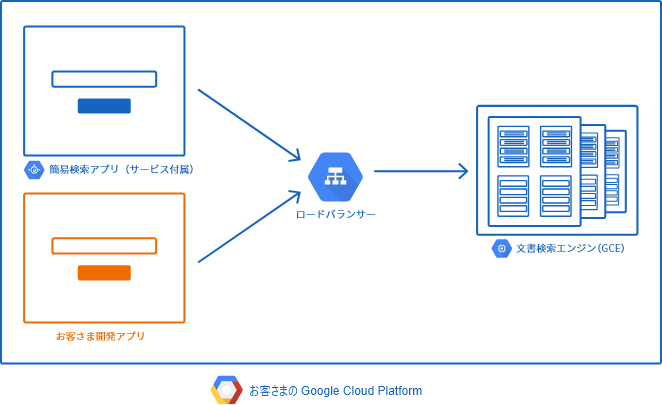
この文書検索エンジンは、知りたい事柄や質問を日常使っている自然な形の文章で入力すると、登録済みの文書の中からその質問の回答として可能性の高い文章を返します。
この文書検索エンジンを使うことで、プライベートはもちろんのことパブリックな検索サービスを簡単かつスピーディに立ち上げることが可能となります。
特徴
文書検索エンジン(文書検索タイプ)には、以下の特徴があります。
- 簡単に文書検索エンジンが構築できる
BLOCKSで文書検索エンジン(文書検索タイプ)を作成すると、文書検索エンジンの環境を自動で構築します。専門的な知識は不要です。構築先となるGCPプロジェクト・文書検索エンジン用仮想マシンの台数・仮想マシンのタイプ・ディスクサイズなどを指定するだけで、用途に合わせた構成での環境構築が可能です。
- Q&A形式の文書検索に強い
問い合わせをまとめたQ&A形式の文書検索において、高い検索精度が得られやすいです。
- JSON形式のRESTful API
文書検索エンジンには、JSON形式のRESTful API(API)を使ってアクセスできます。このAPIを使って、文書検索エンジンを活用した検索アプリや検索ボットなどのアプリケーションの開発が可能です。
- 簡単データ登録
検索対象となる文書は、CSV形式のテキストファイルとして用意しておくことで、文書検索エンジン(文書検索タイプ)を使って簡単に登録ができます。
- カスタマイズ
3種類の辞書(ユーザー辞書・同義語辞書・除外ワード辞書)による検索のカスタマイズができます。
- 簡易検索アプリが付属
簡易検索アプリが付属しています。この簡易検索アプリを使って、簡単に検索エンジンの性能が確認できます。
試してみよう
実際に文書検索エンジンを作り、付属の簡易検索アプリを使って、文書を検索してみます。
おおまかな流れは以下のとおりです。

- データの準備
サンプルの文書と辞書のデータを用意しています。まず、このデータをダウンロードします。
- 文書検索エンジンの作成
文書検索エンジンを作成します。マウスのボタンを数回クリックするだけの簡単操作で文書検索エンジンが作成できます。
- データのアップロード
文書検索エンジンへ登録するデータは、あらかじめGCS上の所定の場所にアップロードしておく必要があります。ここで、1.のステップで準備したデータ(文書と辞書)をGCSへアップロードします。
- インデックスの作成
文書検索エンジンは、1つの文書検索エンジンで複数の検索サービスの提供が可能です。インデックスは、1つの検索サービスに対応します。データ(文書と辞書)は、このインデックスに登録します。ここでは、インデックスを1つ作成し、同時に辞書データを登録します。
info_outline1つでもインデックスがないと検索サービスは使えません。
- データの登録
4.で作成したインデックスに文書データを登録します。データの登録が完了すると、文書検索エンジンを使った検索サービスが利用可能となります。
- 簡易検索
付属の簡易検索アプリを使って、文書検索エンジンが提供する検索サービスを簡単に試せます。
1.データの準備
サンプルの文書と辞書のデータを用意しています。まず、このデータをダウンロードします。
今回用意したサンプルデータは、厚生労働省が公開しているインフルエンザQ&A open_in_newを文書検索エンジン用に加工したものです。
このサンプルデータは以下のURLで公開しています。ZIP圧縮していますので、ダウンロード後、 解凍してください。
https://storage.googleapis.com/blocks-docs/search-board-howto/text-search-sample.zipファイルを解凍すると、以下の構成でファイルとフォルダーが展開されているはずです。
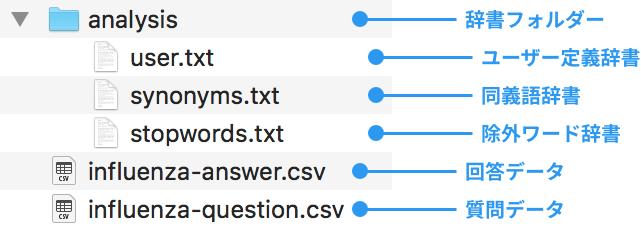
以下、各データについて簡単に確認しておきます。
辞書フォルダー
辞書は、必ずanalysisというフォルダーの中に配置しなければなりません。各辞書のファイル名は自由です。
- ユーザー定義辞書
ユーザー辞書は、標準の辞書では正しく認識されない単語を登録するための辞書です。 ユーザー定義辞書について詳しくは、ヘルプを参照してください。
user.txtの内容:感染症例,感染 症例,カンセン ショウレイ,カスタム品詞 鳥インフルエンザ,鳥 インフルエンザ,トリ インフルエンザ,カスタム品詞
- 同義語辞書
同義語辞書は、あいまい検索のための辞書です。同義語辞書について詳しくは、ヘルプを参照してください。
synonyms.txtの内容:インフル => インフルエンザ こども,子供,幼児,赤ちゃん,小学生 => 小児・未成年者
- 除外ワード辞書
除外ワード辞書は、検索の対象としない語句を登録するための辞書です。除外ワード辞書について詳しくは、ヘルプを参照してください。
stopwords.txtの内容:中国 歴史
info_outlineこのサンプル辞書データは、辞書の書き方を紹介する目的のものであり、検索結果に影響を与えるものではありません。
検索文書
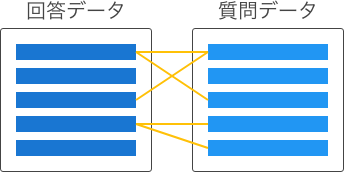
文書検索エンジン(文書検索タイプ)では、検索対象となる文書を過去の質問と回答のデータに分けておき、これらを関連付けて管理する方式をとっています。なお、データを分けずに、すべての文書を回答データにまとめての登録もできます。
|
|
| 通常のケース | データを分けないケース |
質問データと回答データの関連付けは、関連付け方によって以下のタイプに分けられます。
| 関連付けのタイプ (回答:質問) |
イメージ図 | 説明 |
|---|---|---|
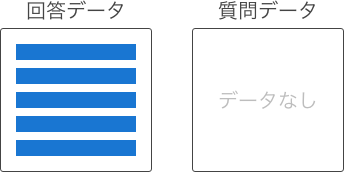
| 1対0 |
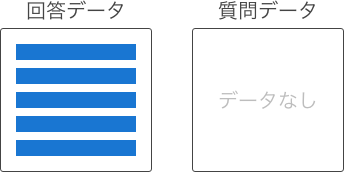 |
回答データのみのため、関連はない。 |
| 1対1 |
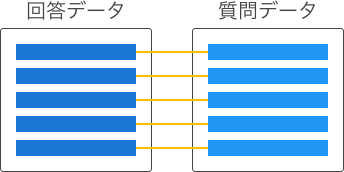 |
双方のデータが1対1に対応している。 |
| 1対多 |
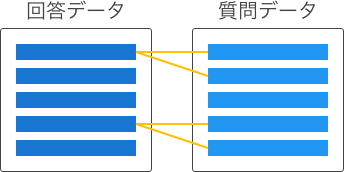 |
回答データは複数の質問に関連する可能性があるが、質問データは1件の回答にのみ関連する。 |
| 多対1 |
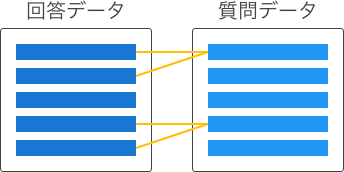 |
回答データは1件の質問にのみ関連するが、質問データは複数の回答に関連する可能性がある。 |
| 多対多 |
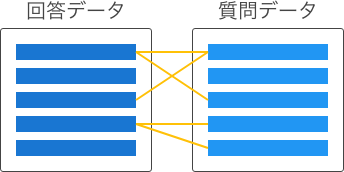 |
回答データは複数の質問に関連する可能性があり、質問データも複数の回答に関連する可能性がある。 |
サンプルでは、1対1のデータを用意しています。以下に、各データの抜粋内容を掲載します。
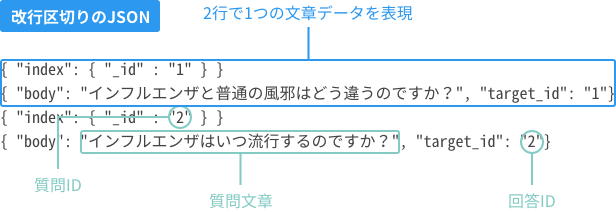
id,body 1," 一般的に、風邪は様々なウイルスによって起こりますが、普通の風邪の多くは、のどの痛み、鼻汁、くしゃみや咳等の症状が中心で、全身症状はあまり見られません。発熱もインフルエンザほど高くなく、重症化することはあまりありません。 一方、インフルエンザは、インフルエンザウイルスに感染することによって起こる病気です。38℃以上の発熱、頭痛、関節痛、筋肉痛、全身倦怠感等の症状が比較的急速に現れるのが特徴です。併せて普通の風邪と同じように、のどの痛み、鼻汁、咳等の症状も見られます。お子様ではまれに急性脳症を、御高齢の方や免疫力の低下している方では肺炎を伴う等、重症になることがあります。" 2,"季節性インフルエンザは流行性があり、いったん流行が始まると、短期間に多くの人へ感染が拡がります。日本では、例年12月~3月が流行シーズンです。"
id,body,target_id 1,インフルエンザと普通の風邪はどう違うのですか?,1 2,インフルエンザはいつ流行するのですか?,2
各データのフォーマットについて詳しくは、以下のヘルプを参照してください。
これでデータの準備が整いました。続いて、文書検索エンジンを作成します。
2.文書検索エンジンの作成
BLOCKSログイン直後の画面(ダッシュボード画面)から始めます。まだBLOCKSにログインしていない場合は、ログインを済ませてください。
グローバルナビゲーションからメニューアイコン(menu)をクリックし、さらに[文書検索エンジン]をクリックします。
「文書検索エンジンとは」の画面から[利用開始]ボタンをクリックして、文書検索エンジンの作成を開始します。
info_outlineライセンス不足の場合は、その旨のメッセージが表示されます(管理者の場合は、ライセンス購入画面を表示)。メッセージが表示された場合は、組織の管理者に問い合わせてください(管理者の場合は、ラインセンスを購入してください)。
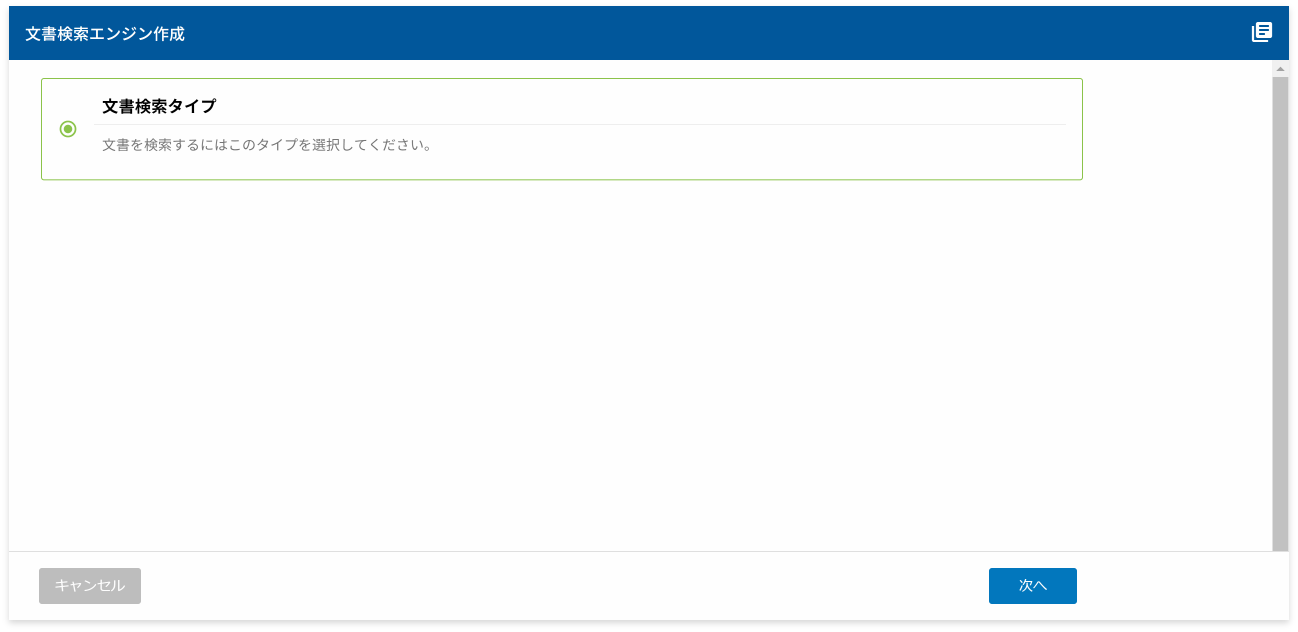
[文書検索タイプ]をクリックして、[次へ]ボタンをクリックします。
名前を設定する画面が表示されます。
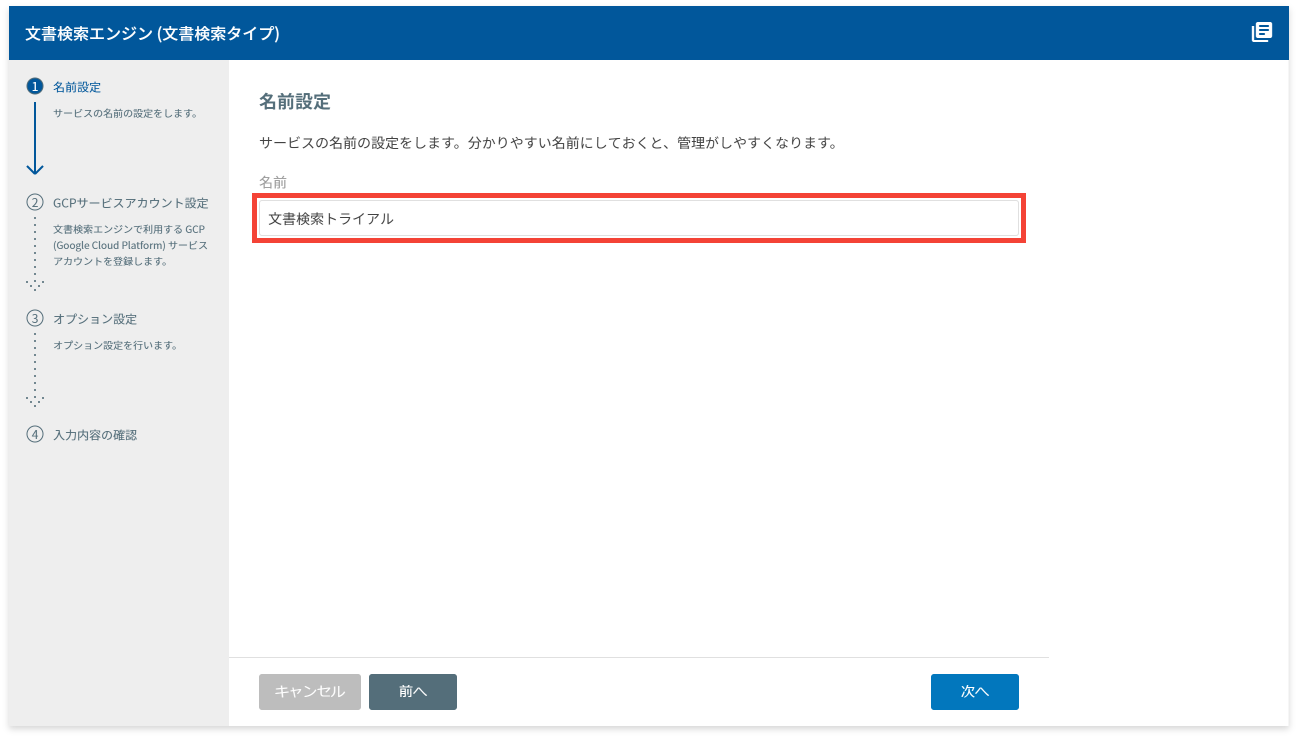
名前を入力し、[次へ]ボタンをクリックします。
GCPサービスアカウント設定の画面が表示されます。ただし、この画面が表示されるのは、トライアルユーザーおよびセルフサービスプランの方のみです。フルサービスプランの場合は、この画面は表示されませんので、この画面の操作部分は読み飛ばしてください。
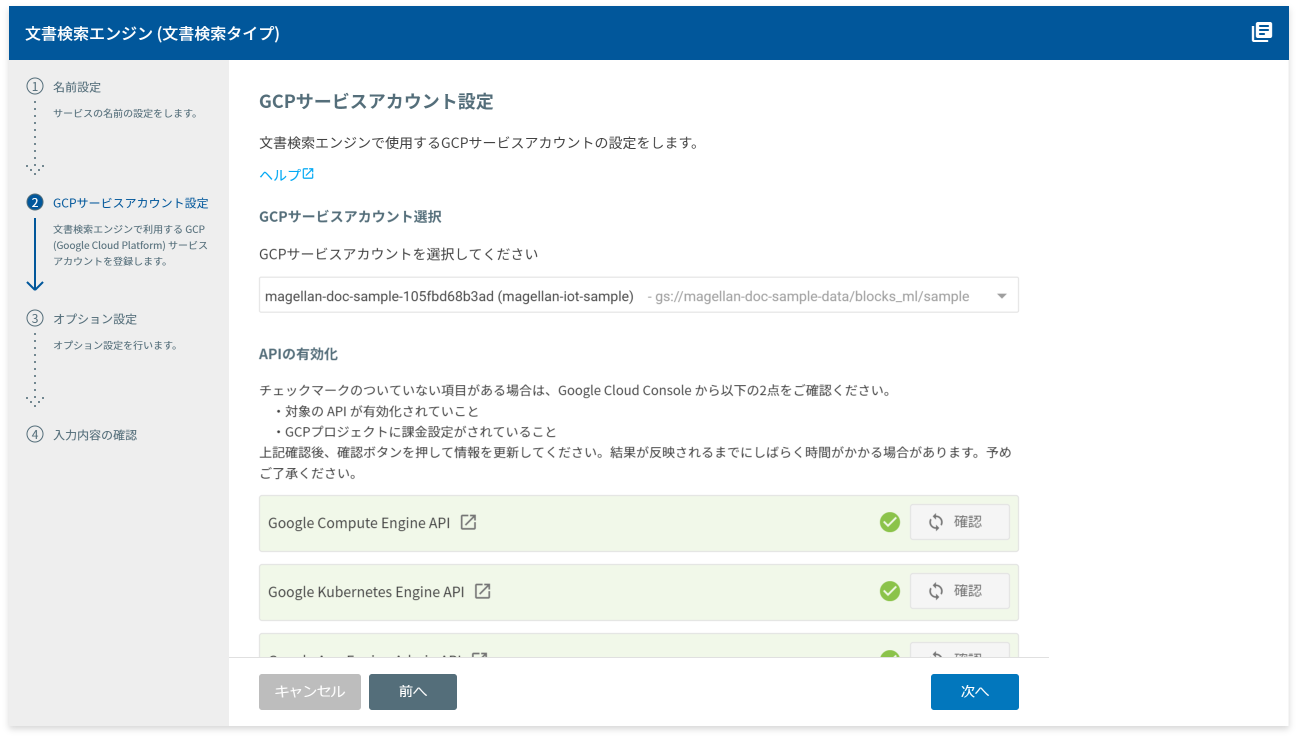
この画面では、GCPサービスアカウントの選択と、GCPの各種APIの有効化を行います。
まず、選択されているGCPサービスアカウントを確認します。複数のGCPサービスアカウントをお持ちの場合は、適切なGCPサービスアカウントに切り替えてください。
続いて、[APIの有効化]項目を確認します。
[loop確認]ボタンの前にチェックマーク(check_circle)が付いていないAPIがある場合は、以下の操作を行います。
- [APIをまとめて有効化する]ボタンをクリックします。
- 別タブにGCPコンソールの画面が開きます。
- GCPコンソール画面内の[続行]ボタンをクリックします。
- 「APIは有効になっています」というメッセージが表示されたら、GCPコンソールの画面を閉じて、BLOCKSの画面に戻ります。
上記操作が終わったら、check_circleが付いていないAPIの[loop確認]ボタンをクリックします。[loop確認]ボタンの前にcheck_circleが付くことを確認してください。この操作をcheck_circleが付いていないすべてのAPIに対して繰り返してください。
もし、check_circleが付かない場合は、しばらく時間をおいてから[loop確認]ボタンをクリックしてください。状況によっては、すぐにはcheck_circleが付かない場合もあります。その場合は、 check_circleが付くまで、以下の操作を繰り返してください。
- しばらく時間をおく
- [loop確認]ボタンをクリックする
error_outlineが表示され続ける原因としては、APIが有効化されていないことの他に、以下のことが考えられます。
-
対象のGCPプロジェクトの課金が有効になっていない。
GCPコンソールのメニュー(GCPコンソール左上のmenu)の[お支払い]で確認します。もし、課金が有効になっていない場合は、課金を有効にします。
APIの有効化がすべて完了したら、[アカウントの確認]項目を確認します。
[loop確認]ボタンをクリックして、このボタンの前にcheck_circleが付くことを確認します。
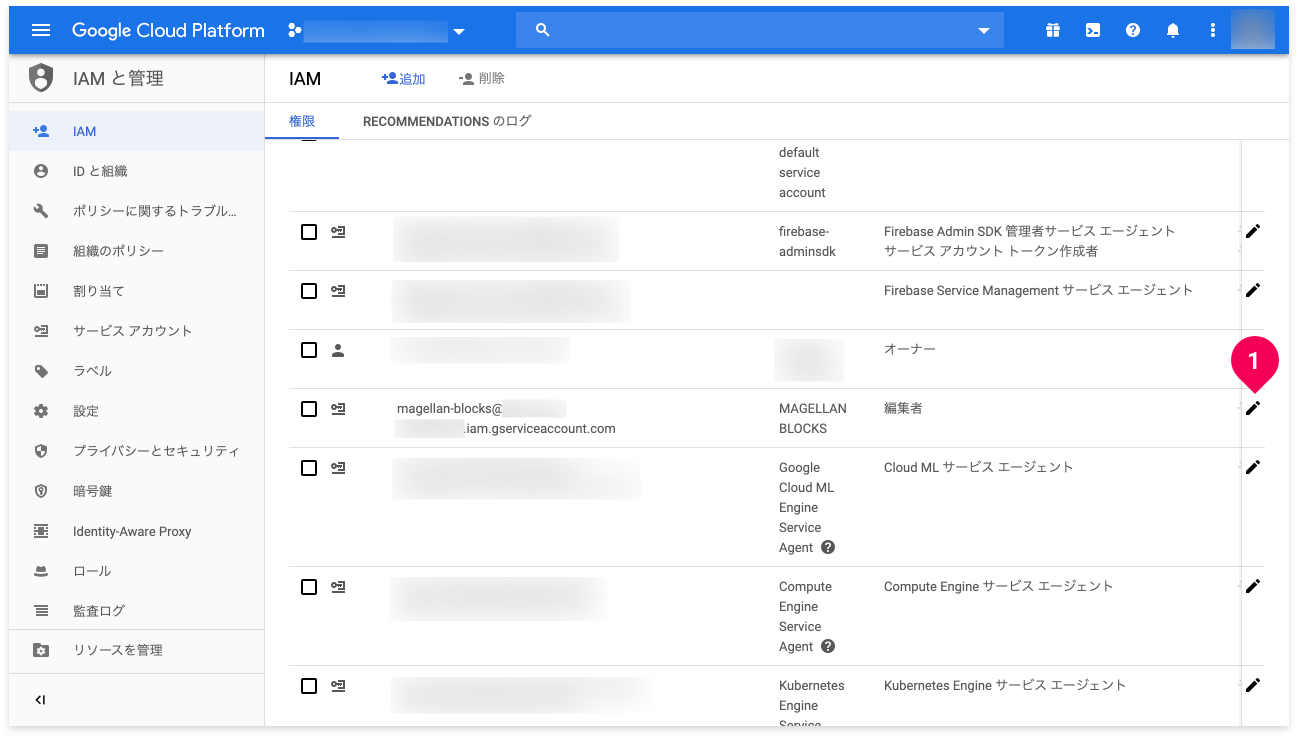
もし、check_circleが付かない場合は、以下の手順でGCPサービスアカウントにオーナー権限を付与してください。
- [アプリケーション作成権限open_in_new]をクリックします。
- 別タブにGoogleコンソール画面が開きます。
- 当該GCPサービスアカウントの鉛筆アイコン(create)をクリックします。
-
[権限の編集]画面から[役割]を変更します(図の1→2→3の順)。
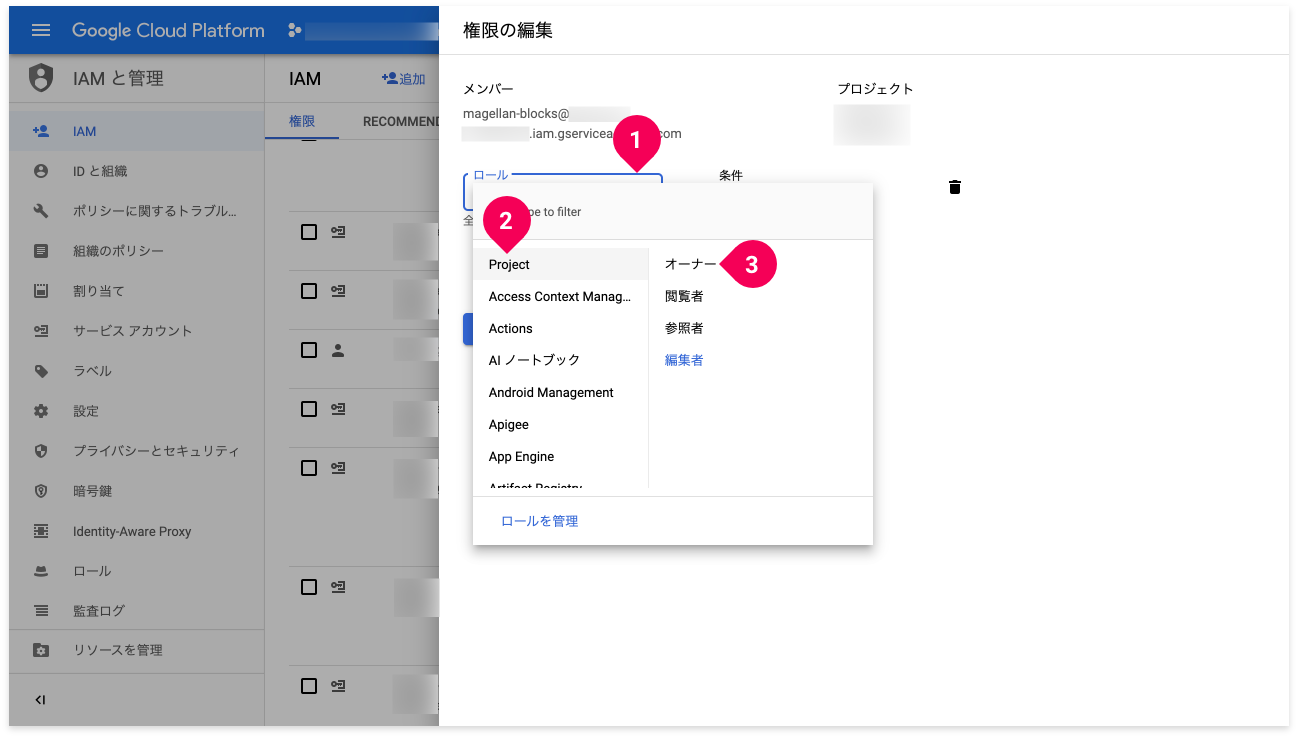
アカウントの確認が完了したら、最後に[Firebaseの有効化]項目を確認します。
[loop確認]ボタンの前にチェックマーク(check_circle)が付いていない場合は、以下の操作を行います。
- この項目の案内文の「Firebaseプロジェクト名は、必ず*****を選択してください」の*****を覚えておきます。
- [Firebase Management API]横のopen_in_newをクリックします。
- 別タブにFirebaseコンソール画面が開きます。
- [プロジェクトを追加]をクリックします。
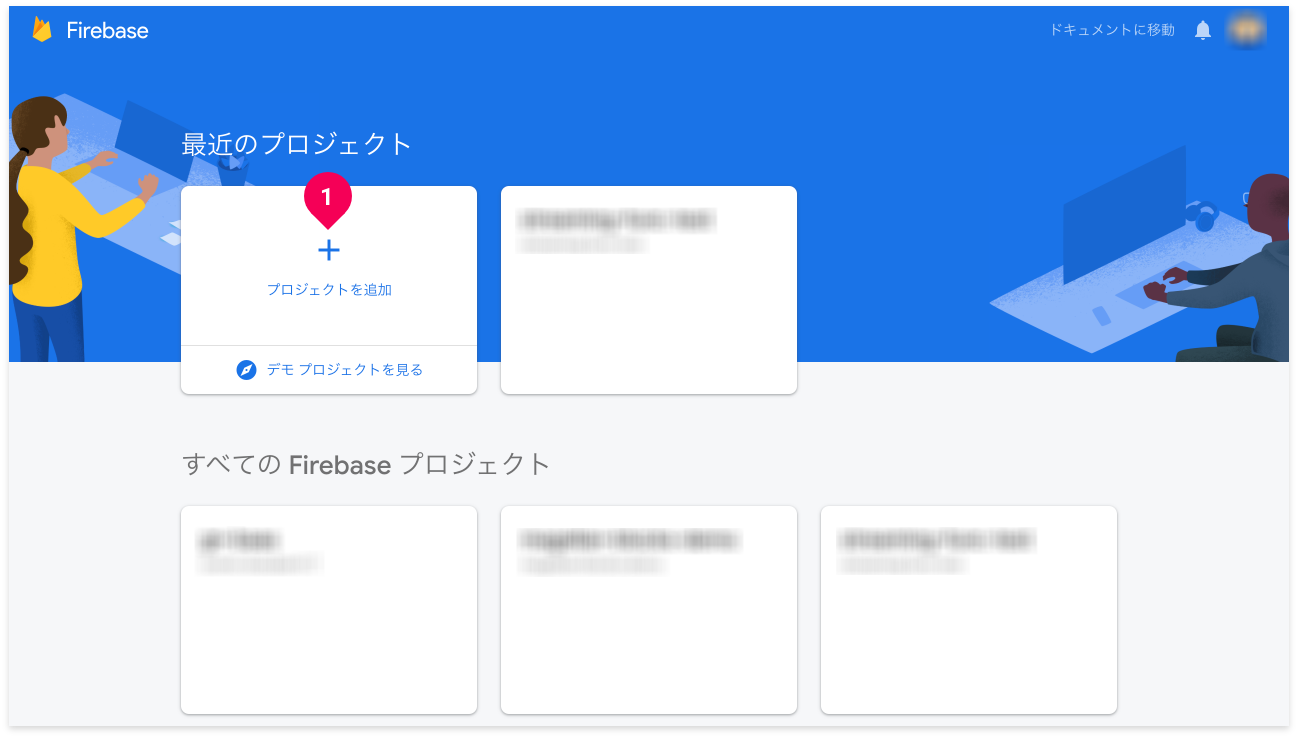
- プロジェクト名の選択リストから、先ほど覚えておいた*****を選択します。
- [続行]ボタンをクリックします。
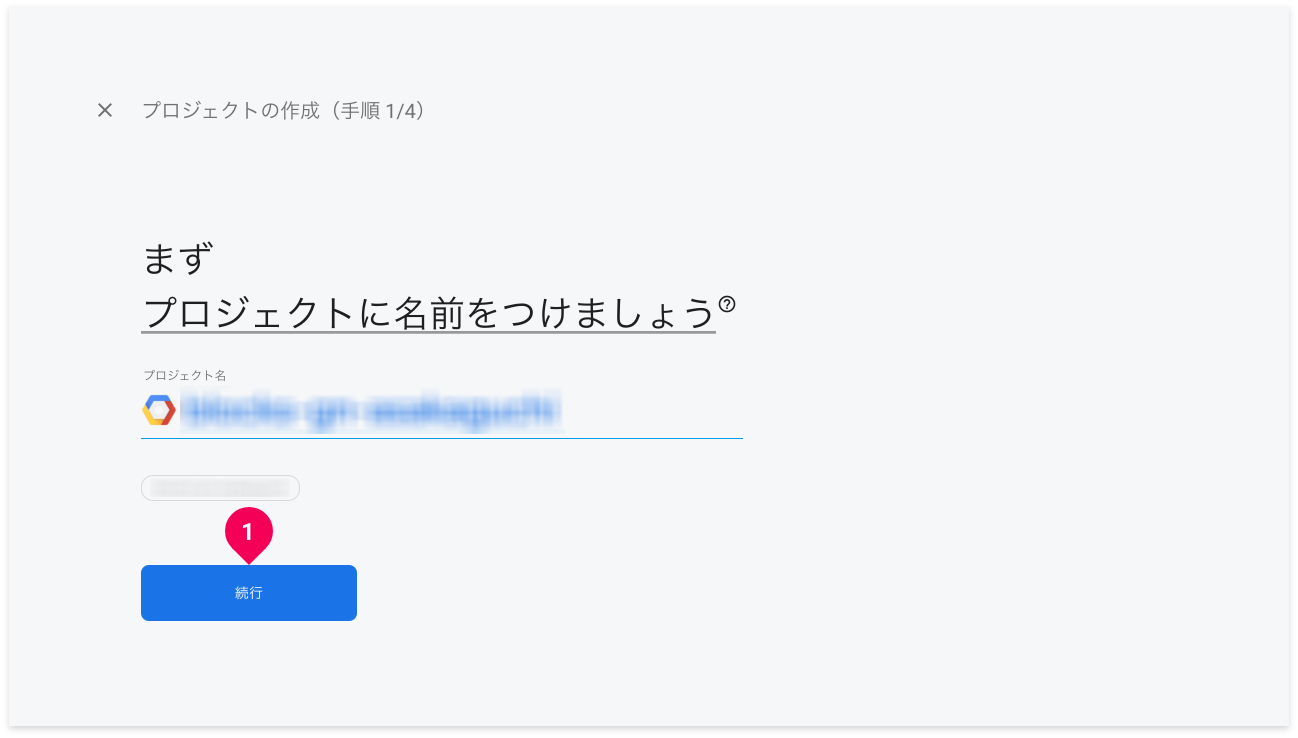
- 以降、画面の案内に沿ってFirebaseプロジェクトの作成を進めてください。
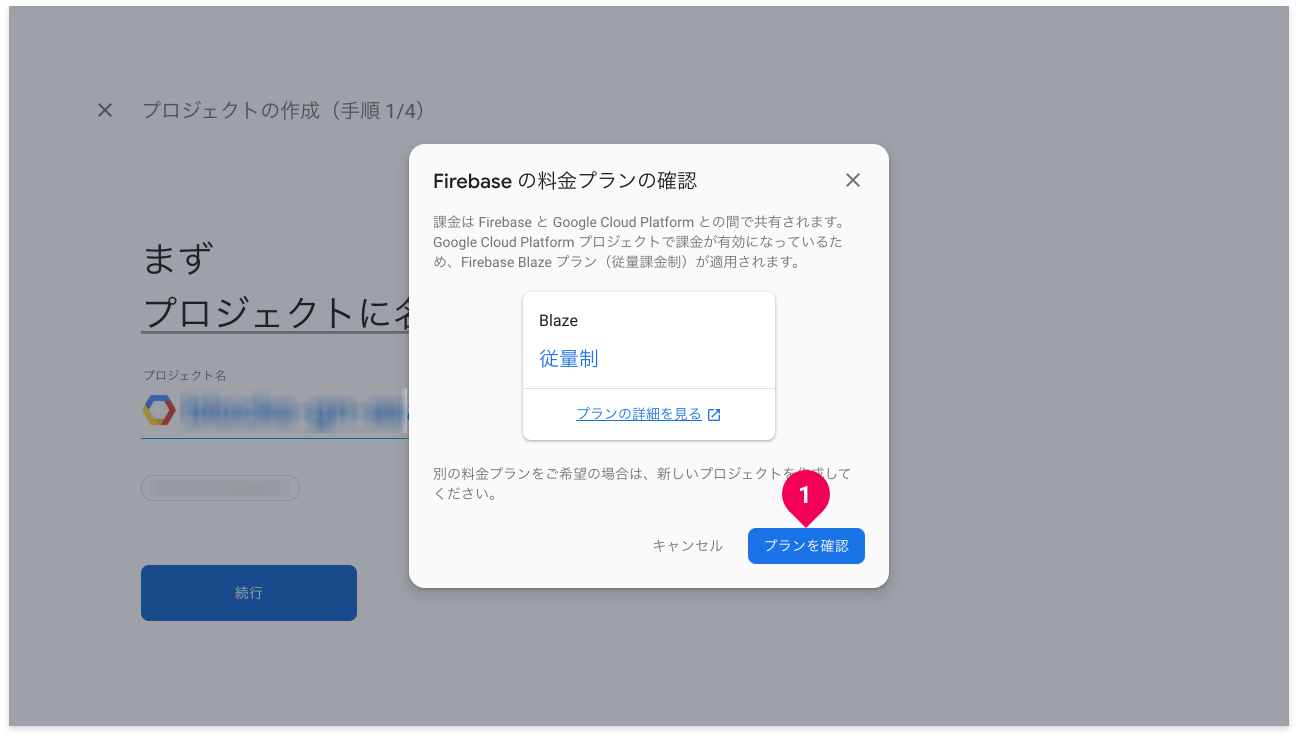
[プランを確認]ボタンをクリックします。
この例では従量課金制プランが選択されていますが、どのようなプランであってもFirebaseプロジェクトの作成および文書検索アプリの利用範囲において、料金は発生しません。
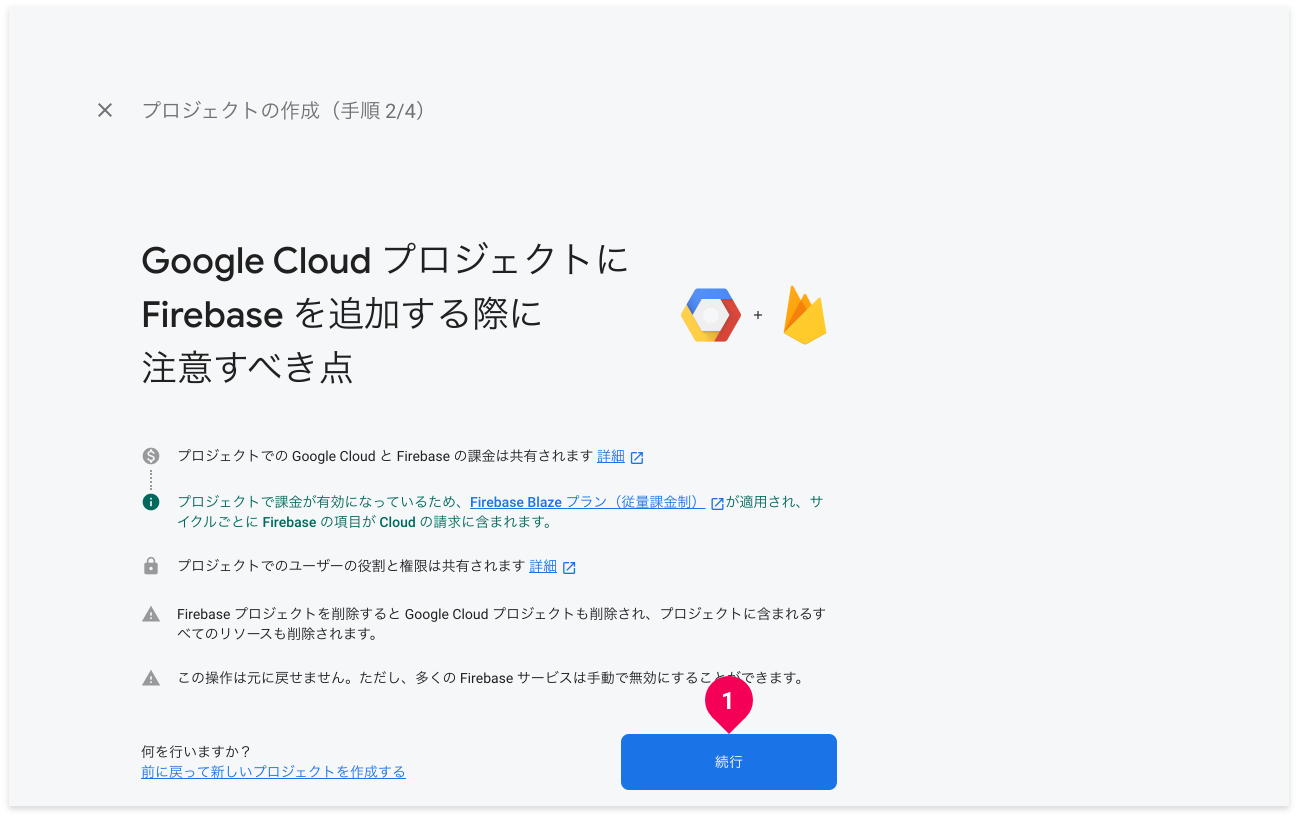
[続行]ボタンをクリックします。
画面内に記載されているとおり、ここで作成するFirebaseプロジェクトを削除すると、GCPプロジェクトも削除されてしまいます。このFirebaseプロジェクトは絶対に削除しないでください。
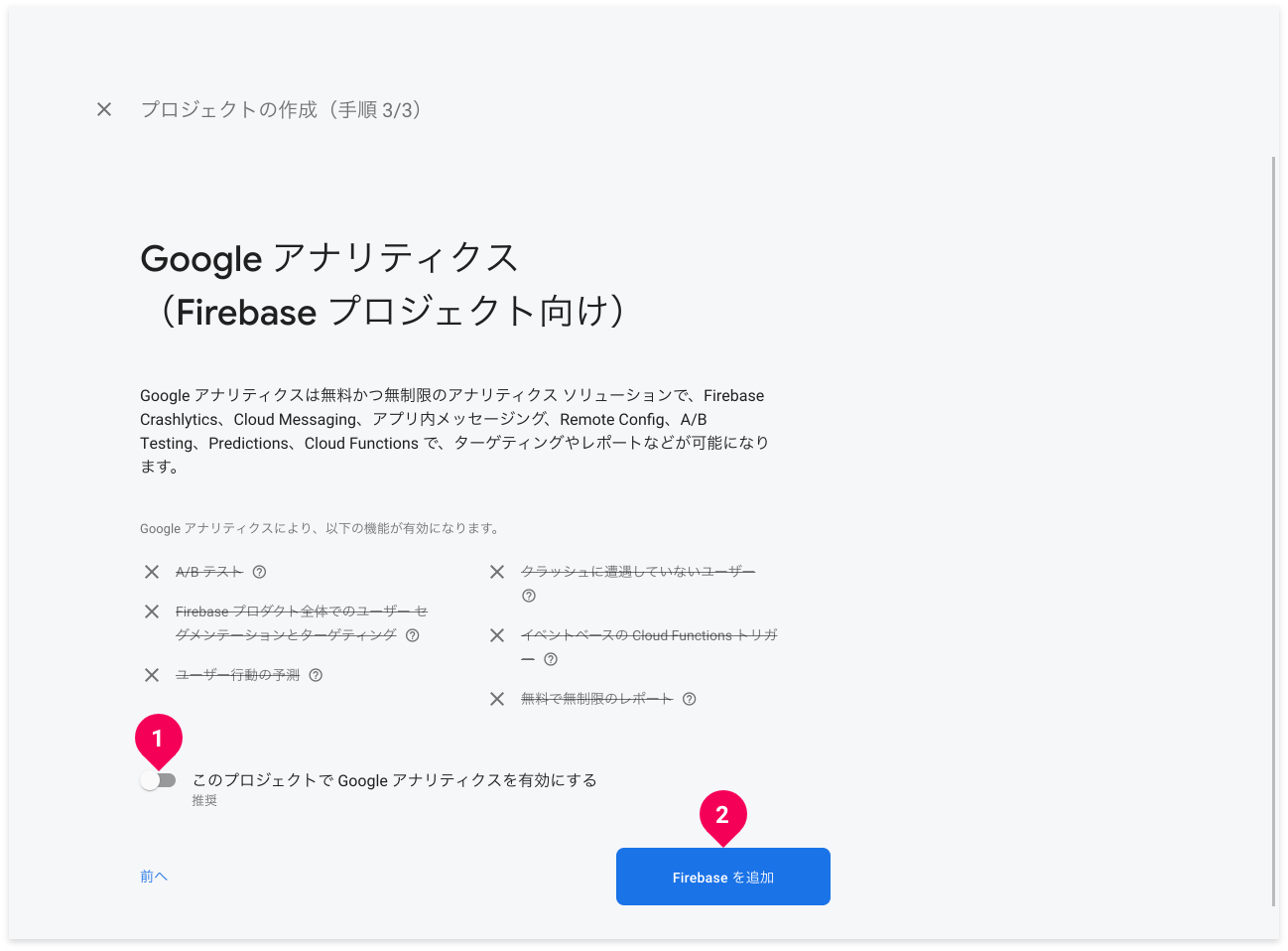
Googleアナリティクスを無効にし、[Firebaseを追加]ボタンをクリックします。
これで、Firebaseプロジェクトの作成が始まります。しばらく時間がかかるので待ちます。

[続行]ボタンをクリックします。
以上で、Firebaseプロジェクトの作成は完了です。
-
Firebaseプロジェクトの作成が完了したら、MAGELLAN BLOCKSの画面に切り替えます。
Firebaseコンソール画面は、閉じて構いません。
上記操作が終わったら、[loop確認]ボタンをクリックして、check_circleが付くことを確認します。
Firebaseの有効化が完了したら、[次へ]ボタンをクリックします。
文書検索エンジンのオプションを設定する画面が表示されます。
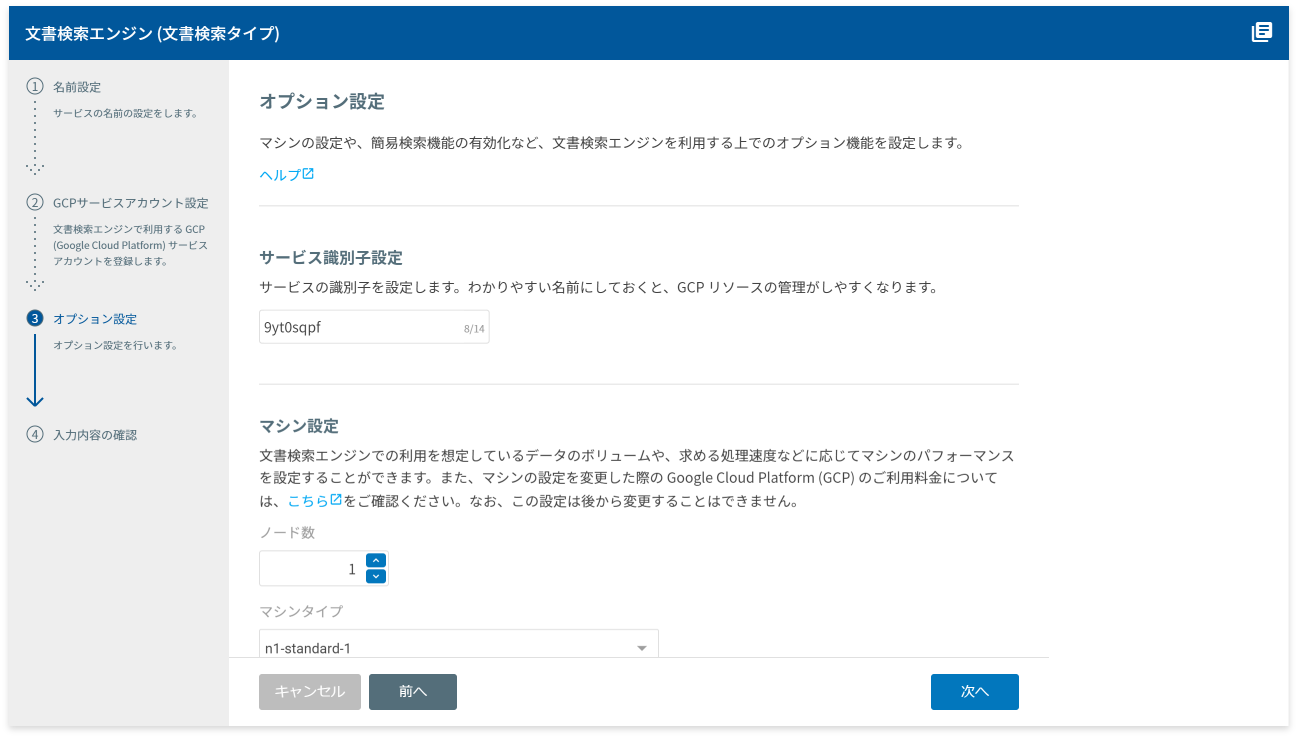
この画面では、GCP上に構築する文書検索エンジン用のマシンスペックを設定します。
ここでは、デフォルト設定のままで進めます。[次へ]ボタンをクリックします。
入力内容の確認画面が表示されます。
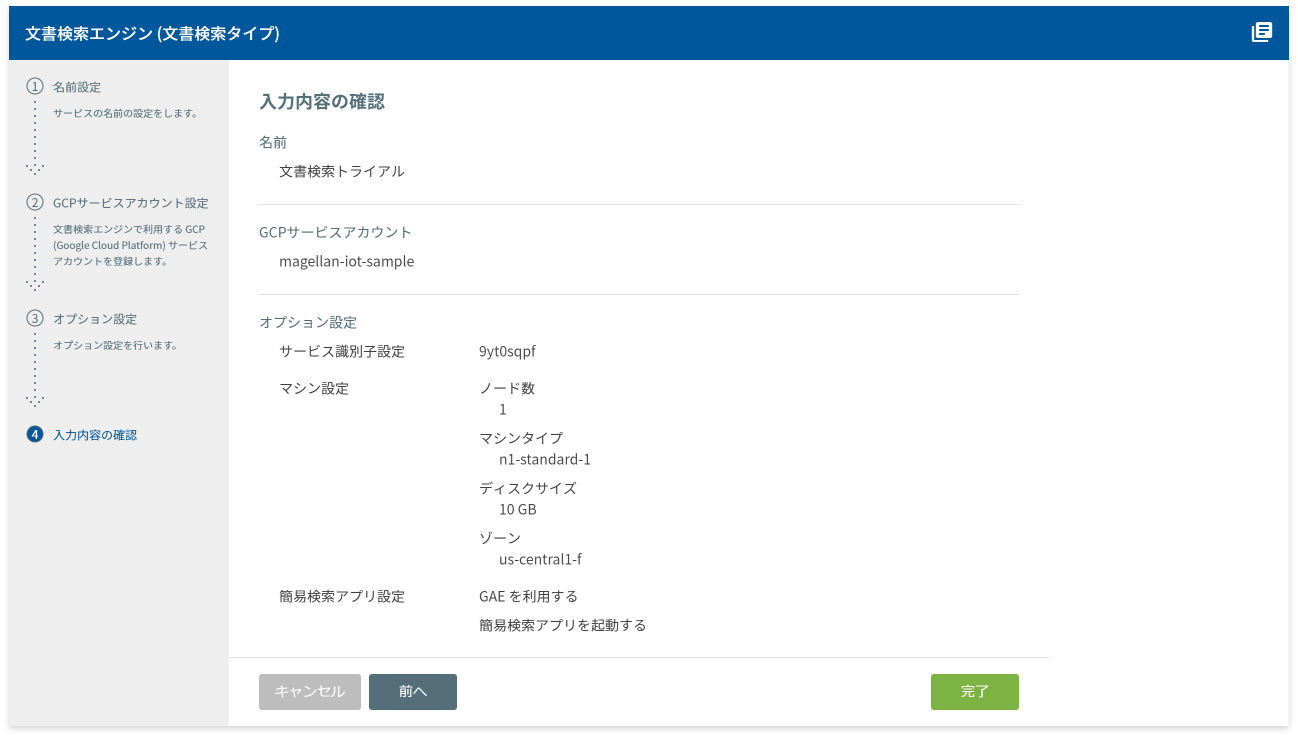
[完了]ボタンをクリックします。
文書検索エンジン(文書検索タイプ)作成の確認画面が表示されます。
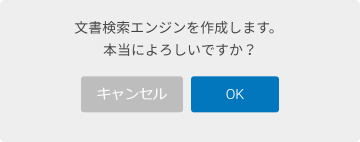
ここで、[OK]ボタンをクリックすると、文書検索エンジンが作成されます。作成には、しばらく時間がかかります。作成が完了するまで、BLOCKSの操作はできません。作成が完了するまで、そのままお待ちください。
作成が完了すると、文書検索エンジンの詳細画面が表示されます。
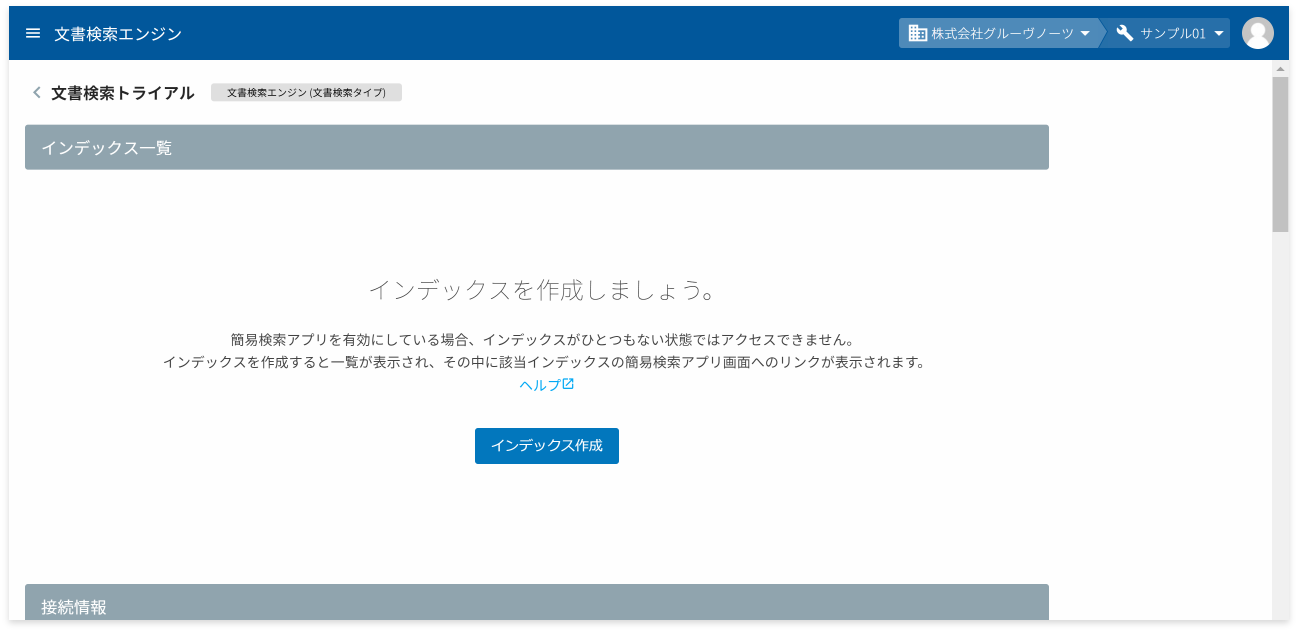
これで、文書検索エンジンの作成は完了です。
info_outline文書検索アプリの利用を予定している方は、更に以下の操作が必要です。
Firebaseのコンソールopen_in_newを開きます。
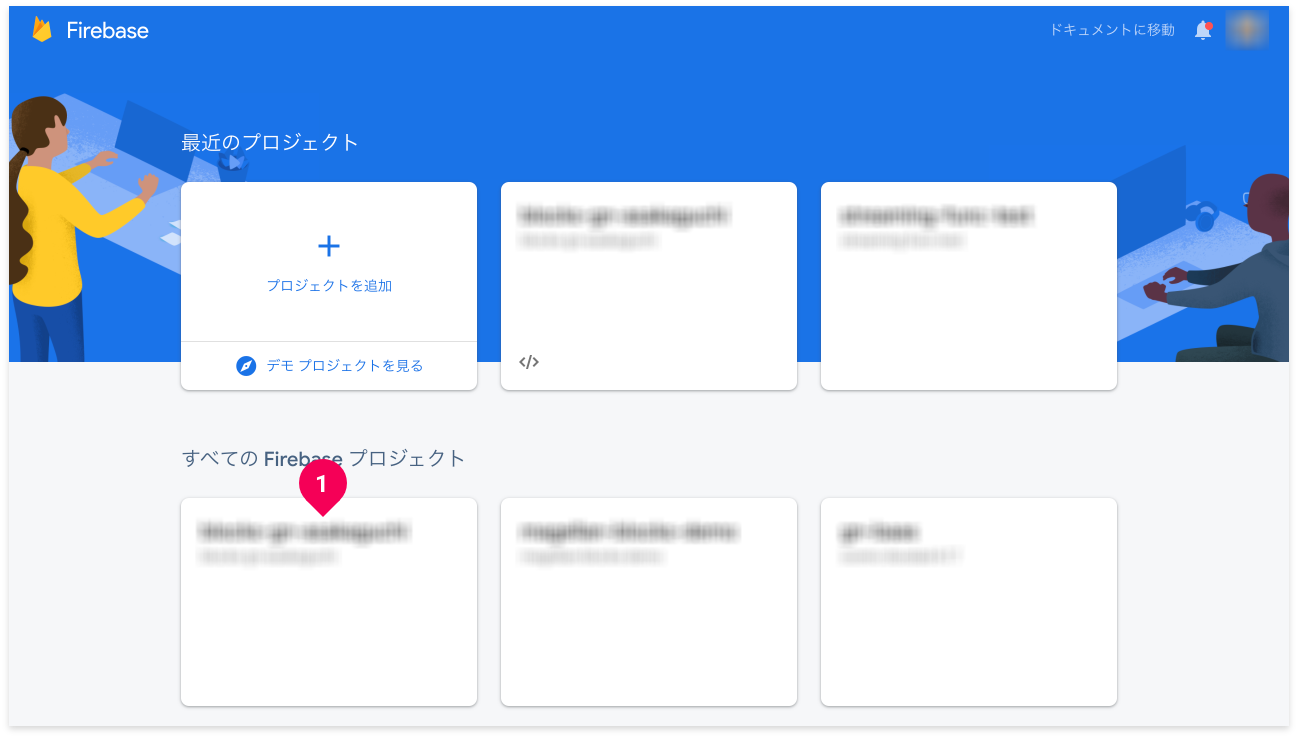
作成した文書検索エンジンのGCPプロジェクトIDが表示されているボックス(❶)をクリックします。
info_outlineGCPプロジェクトIDは、作成した文書検索エンジンの詳細画面の「設定情報」で確認できます。
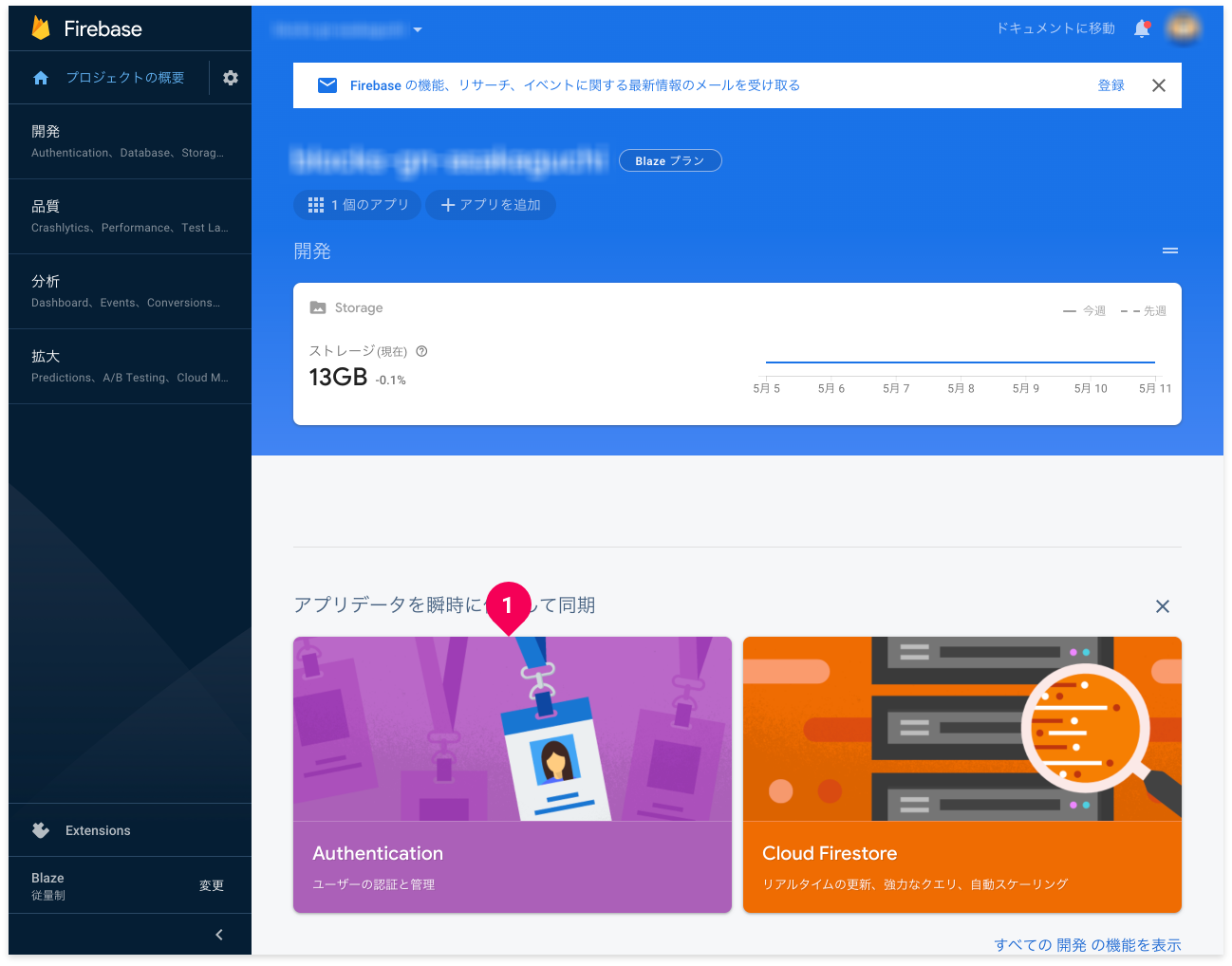
Firebaseプロジェクトの画面から[Authentication]ボックス(❶)をクリックします(画面サイズによっては下への画面スクロールが必要)。
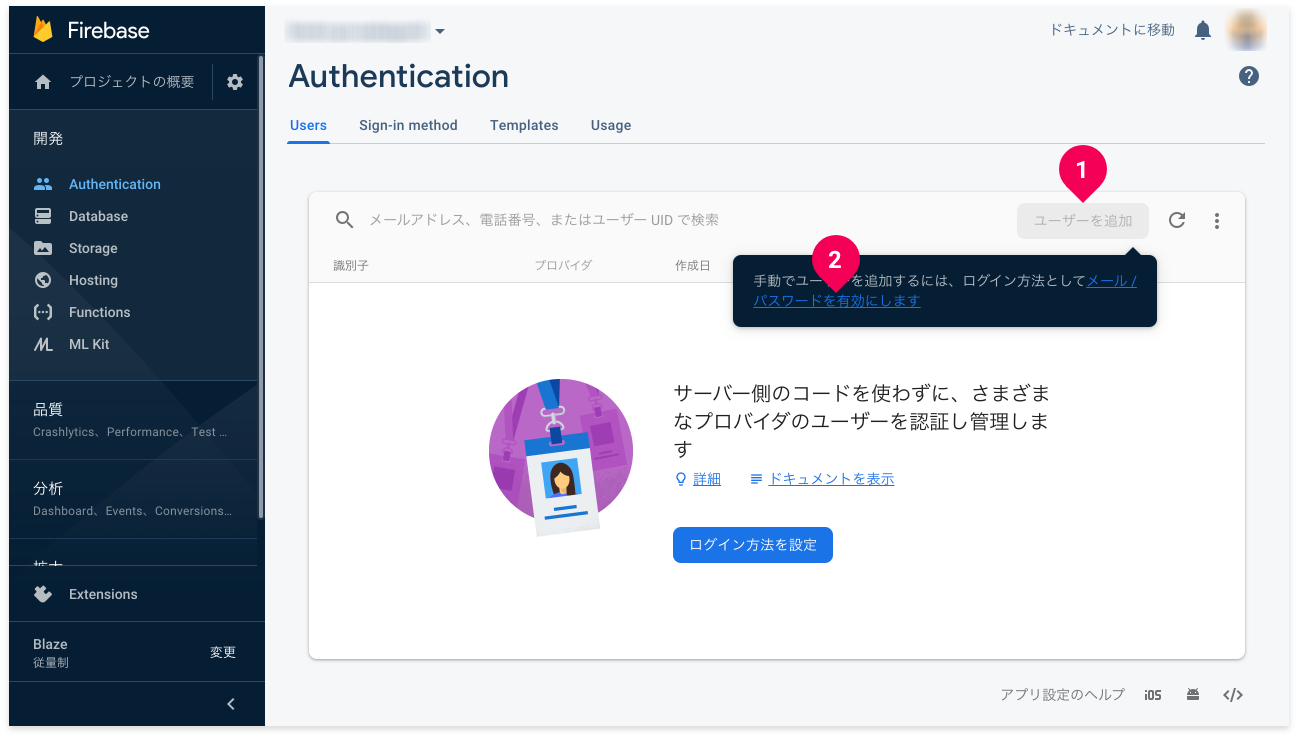
[ユーザーを追加]ボタン(❶)にマウスカーソルを重ねて、[メール/パスワードを有効にします](❷)をクリックします。
以上で操作は完了です。
3.データをGCSへアップロード
文書検索エンジンへ登録するデータは、あらかじめGCS上の所定の場所にアップロードしておく必要があります。ここで、1.のステップで準備したデータ(文書と辞書)をGCSへアップロードします。
GCSのアップロード先は、詳細画面の「このサービスで使用しているリソース」>「Cloud Storage」>「バケット」に記載されているバケットです。
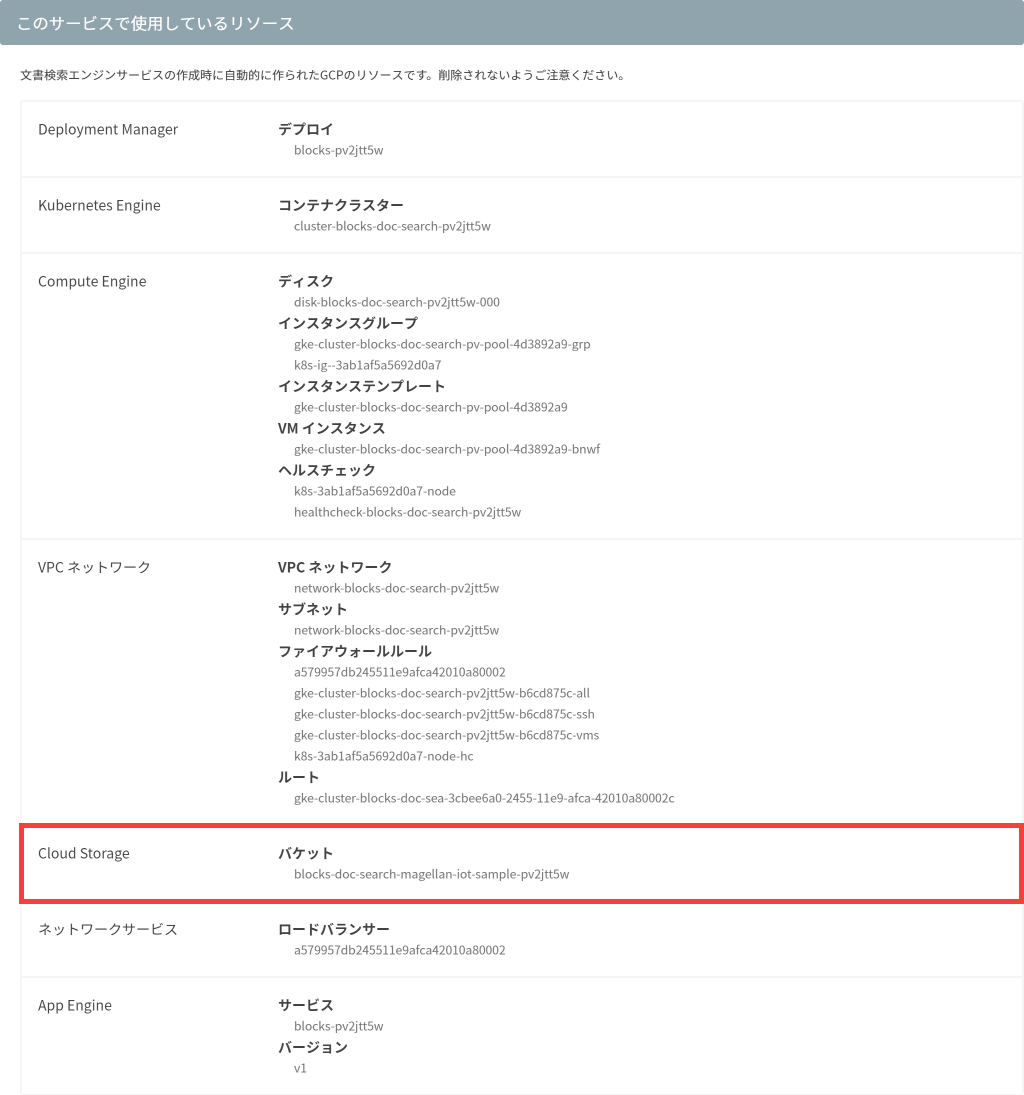
なお、表示されるバケットは作成する文書検索エンジンごとに異なります(上図と同じバケットにはなりません)。
データのアップロードは、BLOCKSのGCS Explorerを使うと簡単です。ここでは、GCS Explorerを使ったデータのアップロード方法を紹介します。
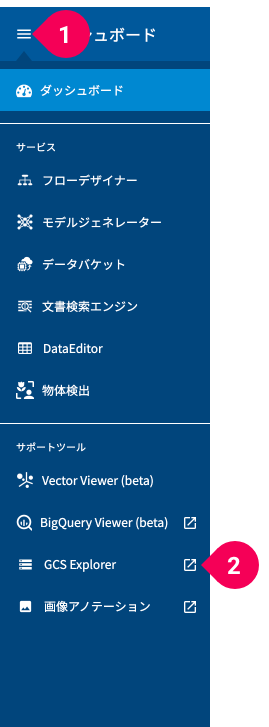
グローバルナビゲーションのメニューアイコン(menu)をクリックし(❶)、表示されるメニューから[GCS Explorer]のopen_in_newをクリックすると(❷)、新しいタブにGCS Explorerが表示されます。
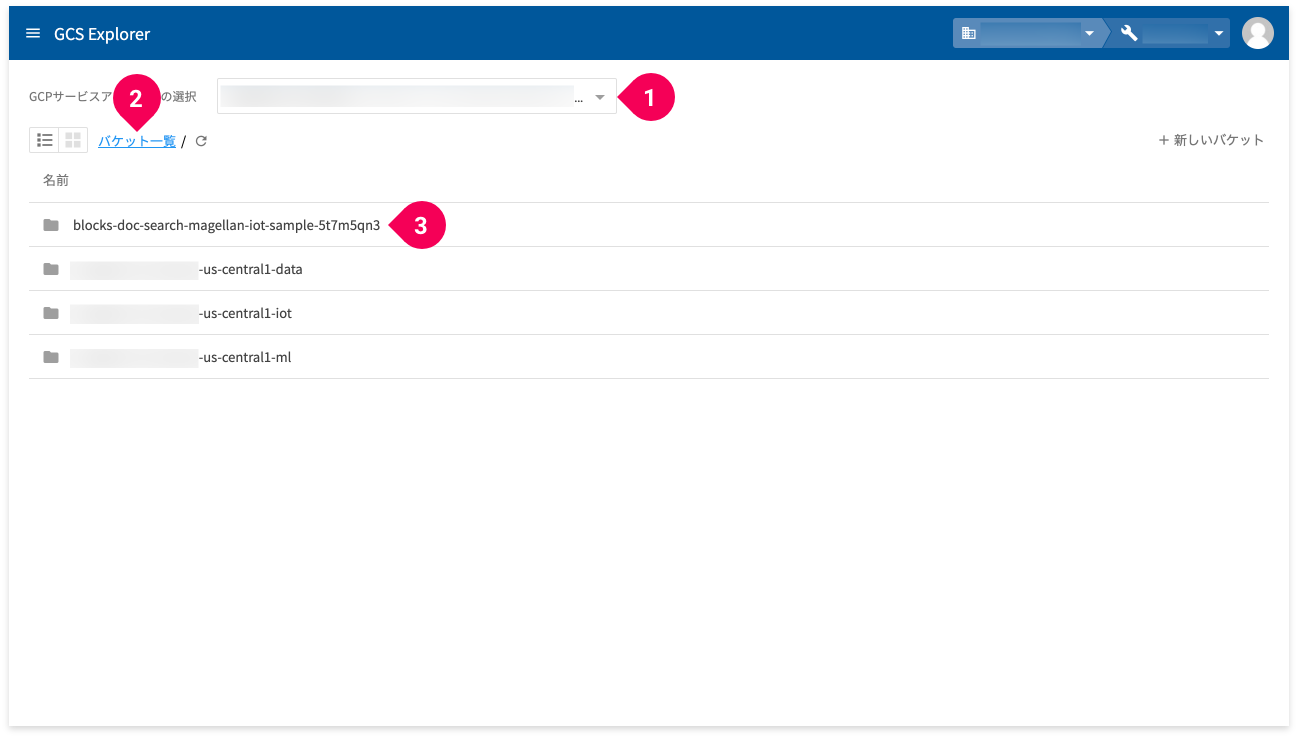
GCPサービスアカウントを選択し(❶)、[バケット一覧]をクリックします(❷)。バケット一覧から、先ほど確認したバケットを選択します(❸)。
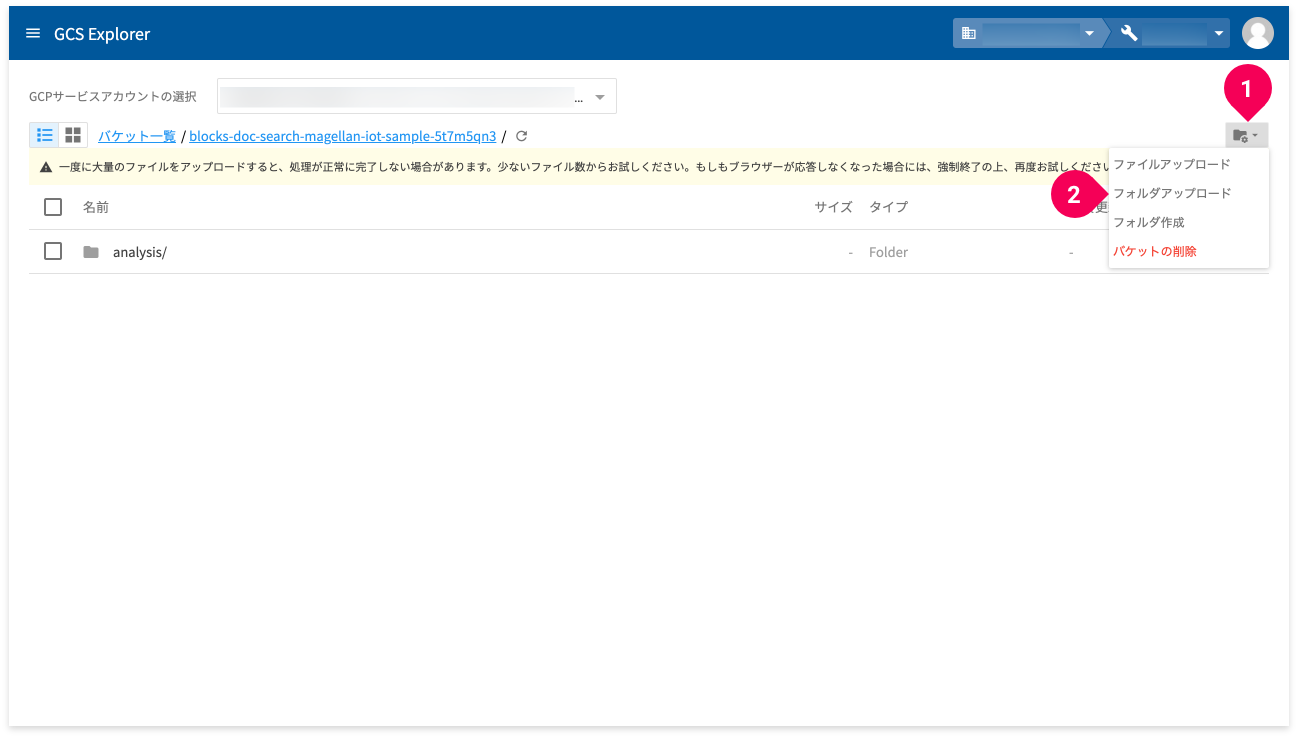
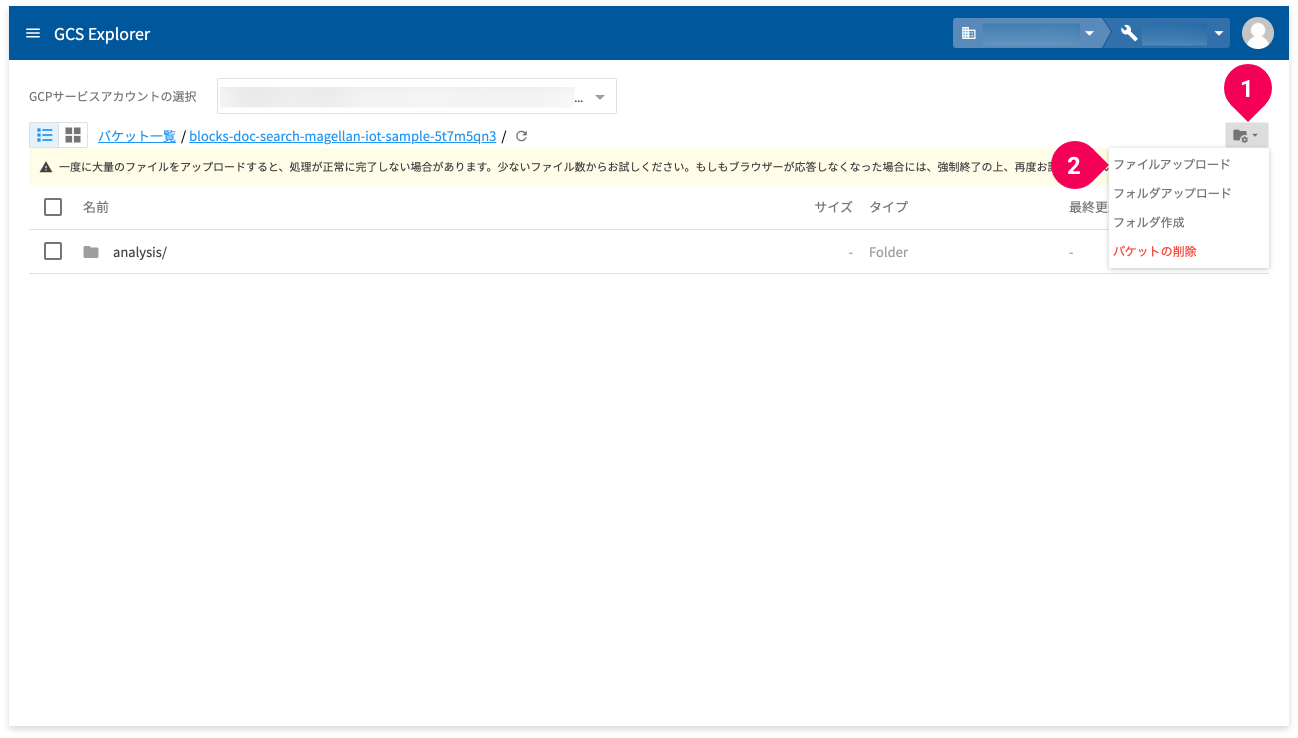
辞書は、フォルダーごとアップロードします。フォルダーと歯車の絵柄のボタンをクリックし(❶)、[フォルダーアップロード]をクリックします(❷)。
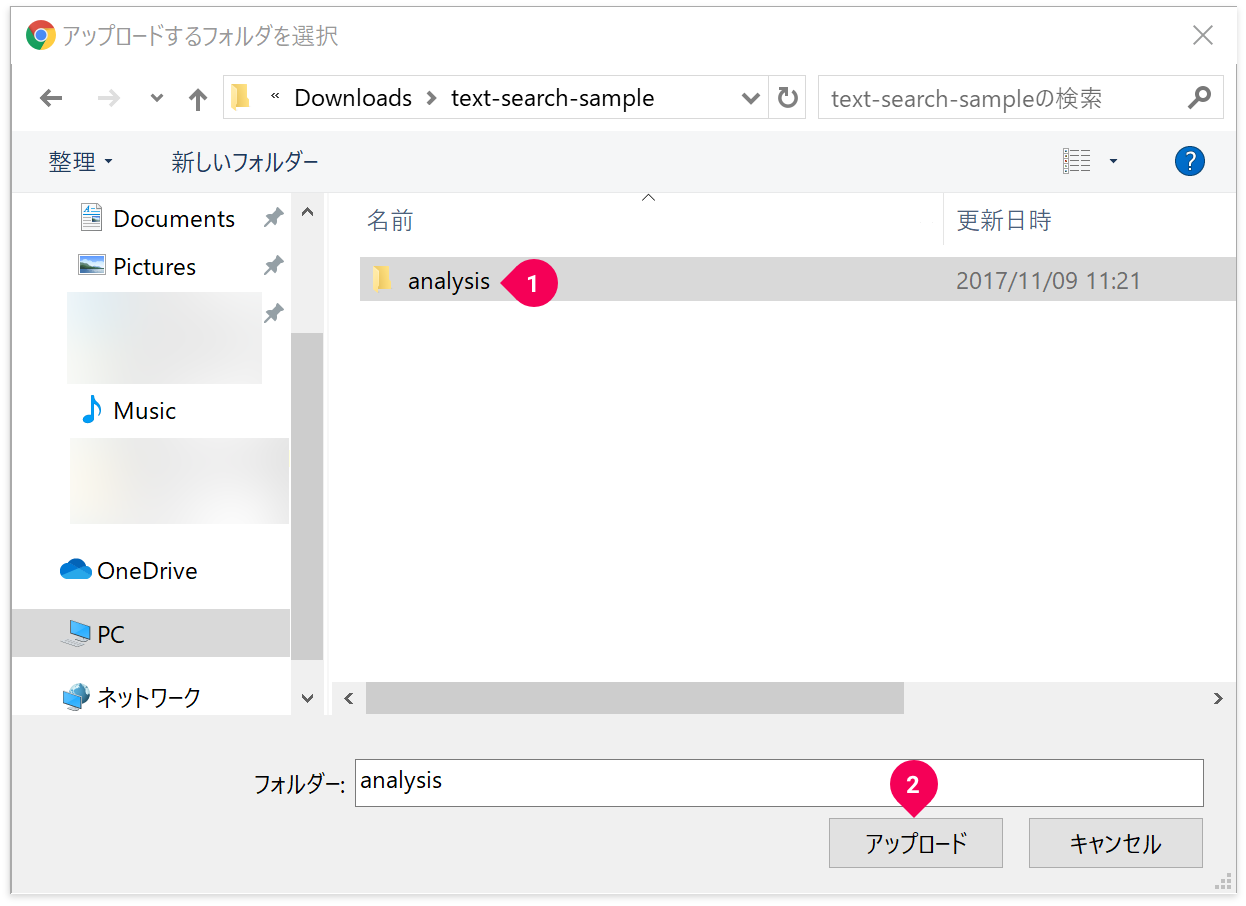
解凍したサンプルデータの[analysis]フォルダーをクリックし(❶)、[アップロード]ボタンをクリックします(❷)。
アップロードの確認画面で、[アップロード]ボタンをクリックします(❶)。
しばらくするとanalysisフォルダーがアップロードされます。
続いて、サンプルデータの質問データと回答データをアップロードします。フォルダーと歯車の絵柄のボタンをクリックし(❶)、[ファイルアップロード]をクリックします(❷)。
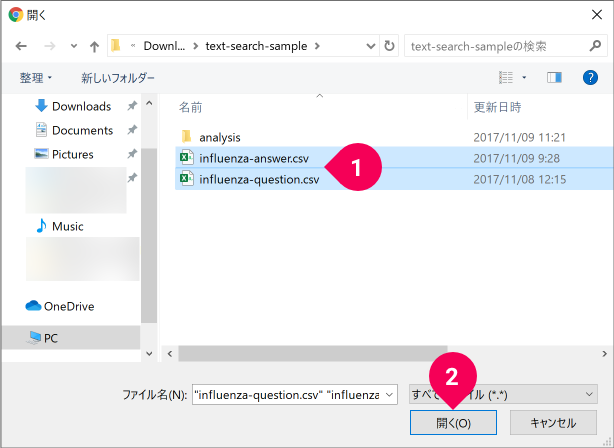
[influenza-answer.csv]と[influenza-question.csv]を選択して(❶)、[開く]ボタンをクリックします(❷)。
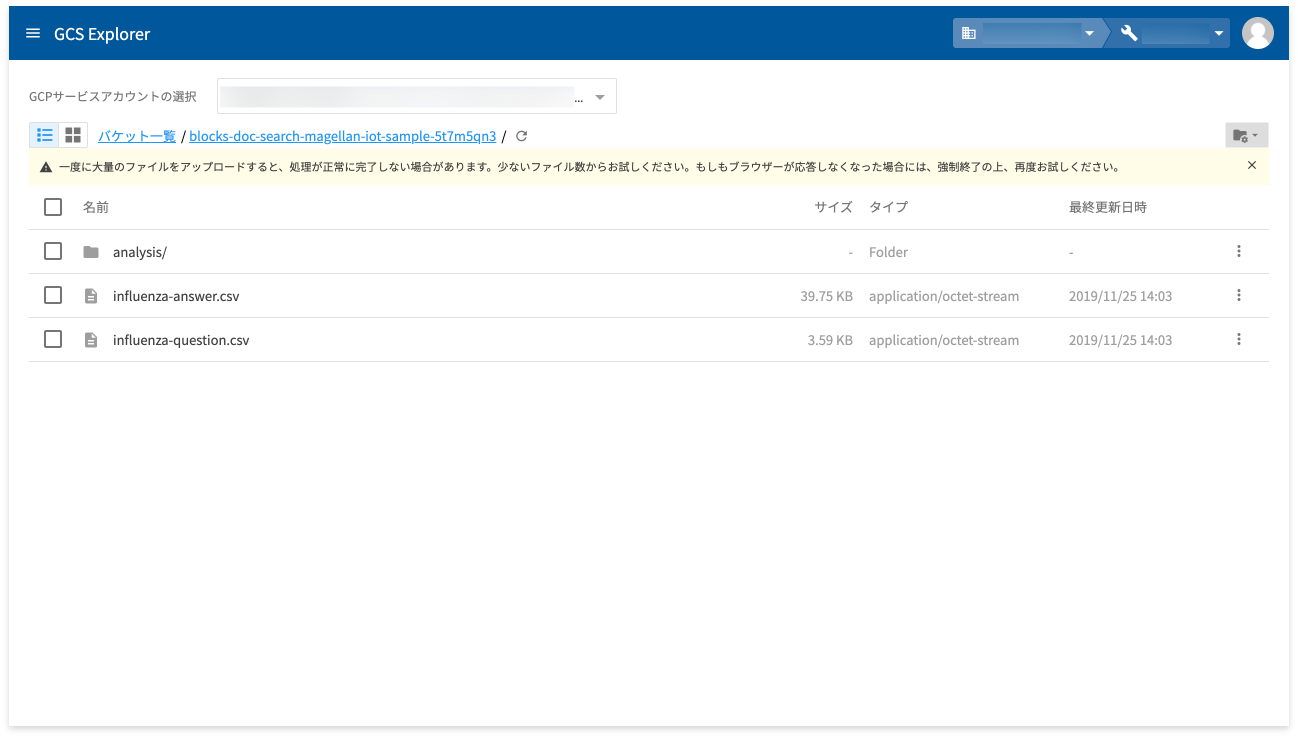
しばらくすると、ファイルがアップロードされます。
以上で、データのアップロードは完了です。
4.インデックスの作成
文書検索エンジンは、1つの文書検索エンジンで複数の検索サービスの提供が可能です。インデックスは、1つの検索サービスに対応します。データ(文書と辞書)は、このインデックスに登録します。ここでは、インデックスを1つ作成し、同時に辞書データを登録します。
[インデックス一覧]の[インデックス作成]ボタンをクリックします。
info_outlineインデックスを2つ以上作成する場合は、インデックス用の追加ライセンスが必要です。
インデックス作成画面が表示されます。
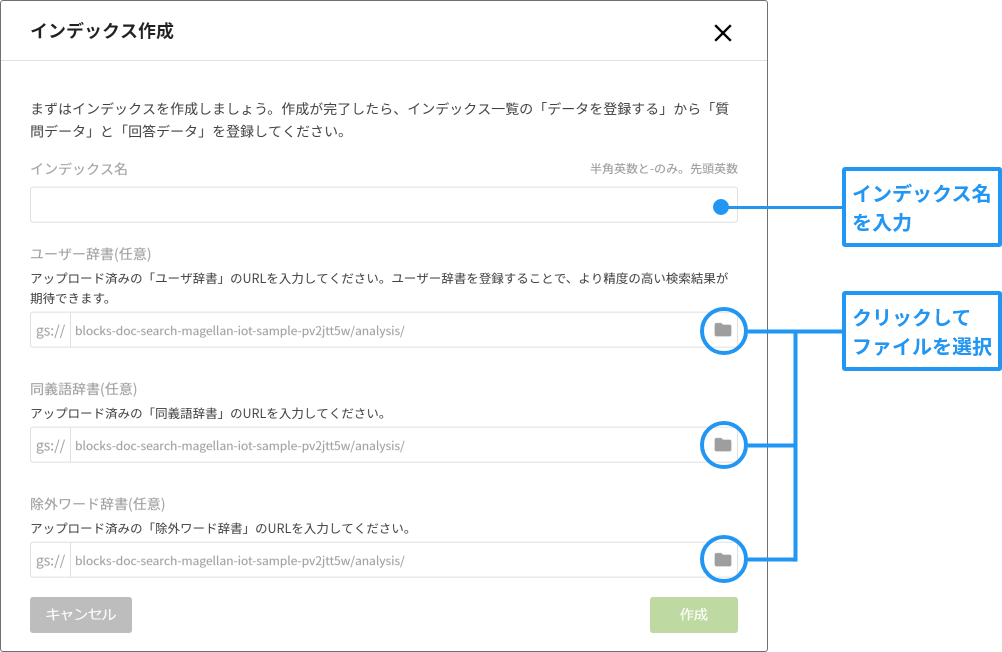
この画面で、インデックス名と先ほどアップロードしたGCS上の辞書を指定します。
インデックス名には、小文字の半角英数とハイフン(-)が指定できます。ただし、先頭は英数のみです(入力例:influenza-faq)。
辞書は、フォルダーのアイコンをクリックすると表示されるGCSファイルセレクターを使って、GCS上のファイルを指定します。
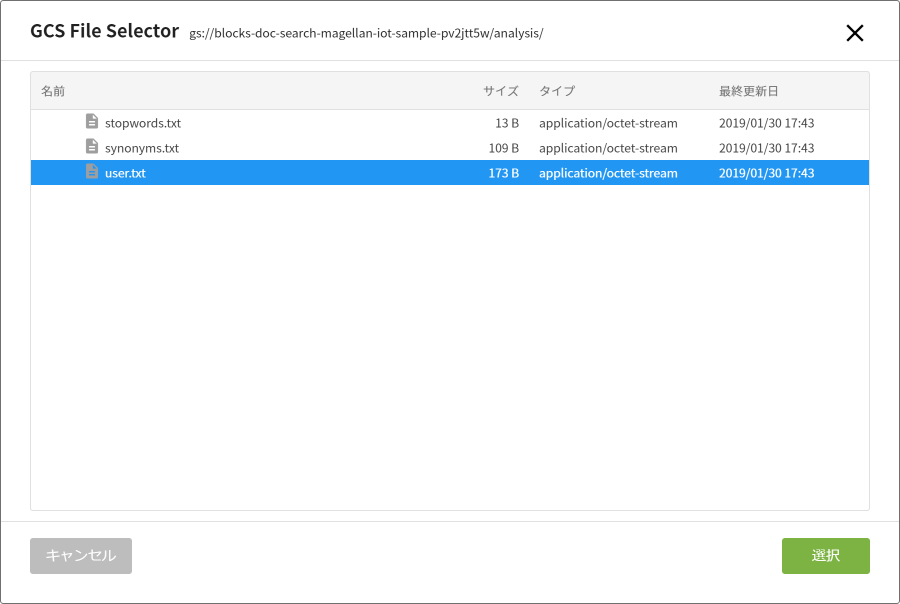
辞書の指定は、該当する辞書ファイルをクリックし、[選択]ボタンをクリックします。
辞書とファイルの対応は、以下のとおりです。
| ユーザー辞書 | user.txt |
| 同義語辞書 | synonyms.txt |
| 除外ワード辞書 | stopwords.txt |
インデックス名の入力と辞書の指定が終わると、以下のような表示になります。
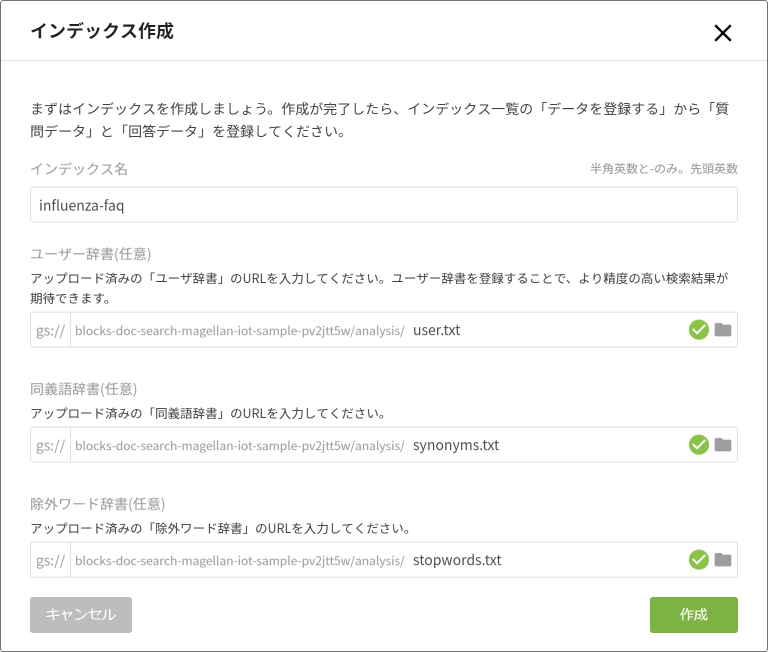
[作成]ボタンをクリックすると、インデックスの作成が始まります。
インデックス一覧の表示が以下のように変わります。

インデックスの作成には、しばらく時間がかかります。完了するまで、しばらくお待ちください。
ステータスが[インデックス作成中]から[インデックス作成済み]に変わったら完了です。

以上で、インデックスの作成は完了です。
5.データの登録
4.で作成したインデックスに文書データを登録します。データの登録が完了すると、文書検索エンジンを使った検索サービスが利用可能となります。

[データを登録する]をクリックします。
データ登録の画面が表示されます。
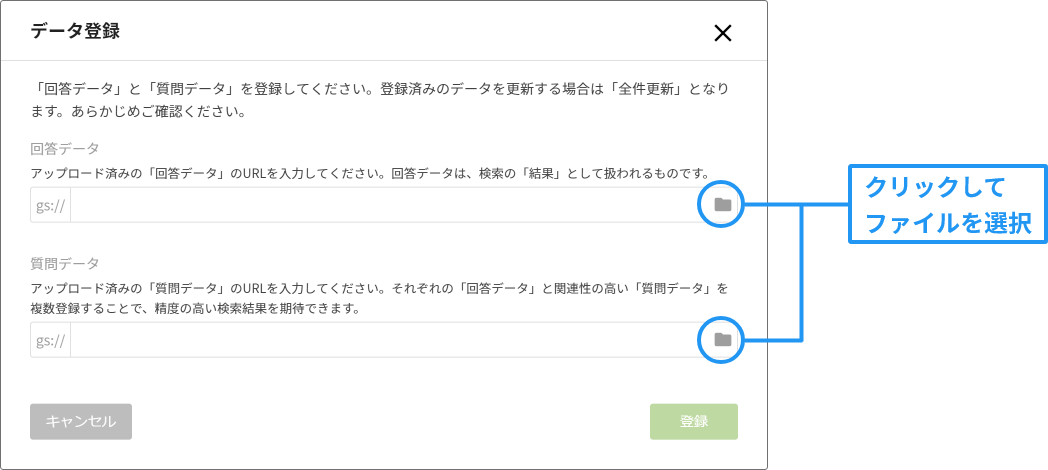
データの指定は、バケットを展開し、該当するファイルをクリックし、[選択]ボタンをクリックします。
データとファイルの対応は、以下のとおりです。
| 回答データ | influenza-answer.csv |
| 質問データ | influenza-question.csv |
データの指定が終わると、以下のような表示になります。
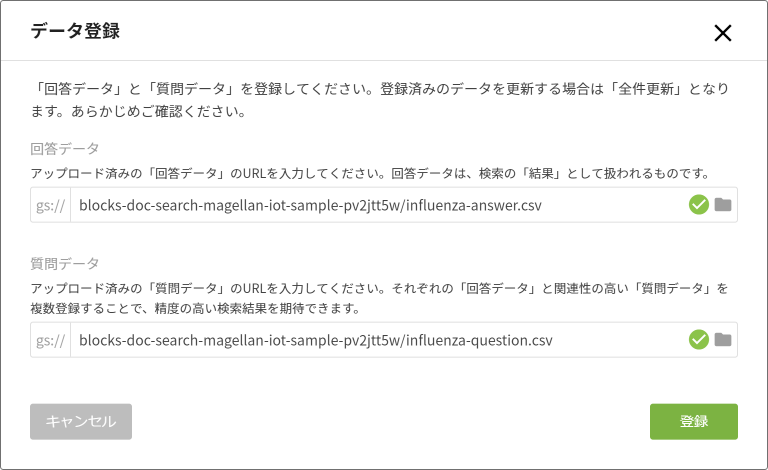
[登録]ボタンをクリックすると、データの登録が始まります。
インデックス一覧の表示が以下のように変わります。

データの登録には、しばらく時間がかかります。完了するまで、しばらくお待ちください。
ステータスが[データ登録中]から[データ登録成功]に変わったら完了です。
インデックス一覧の表示が以下のように変わります。

以上でデータの登録は完了です。
6.簡易検索アプリを使って検索を試す
データの登録が完了すると、付属の簡易検索アプリを使って、文書検索エンジンが提供する検索サービスを簡単に試せます。
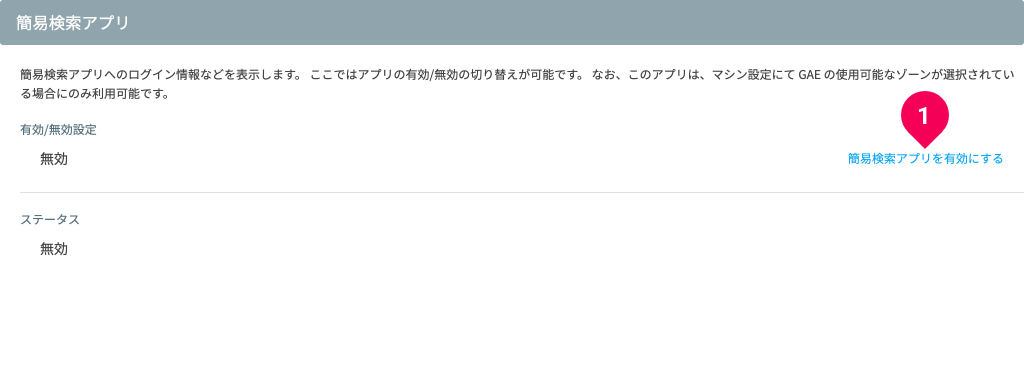
まず、[簡易検索アプリ]項目内の[簡易検索アプリを有効にする](❶)をクリックします。
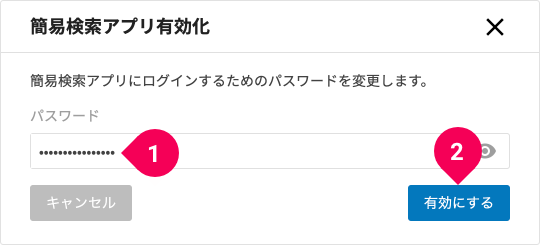
簡易検索アプリ用のパスワード(❶)を入力して、[有効にする]ボタン(❷)をクリックします。
簡易検索アプリが使えるようになるまでには、しばらく時間がかかります。
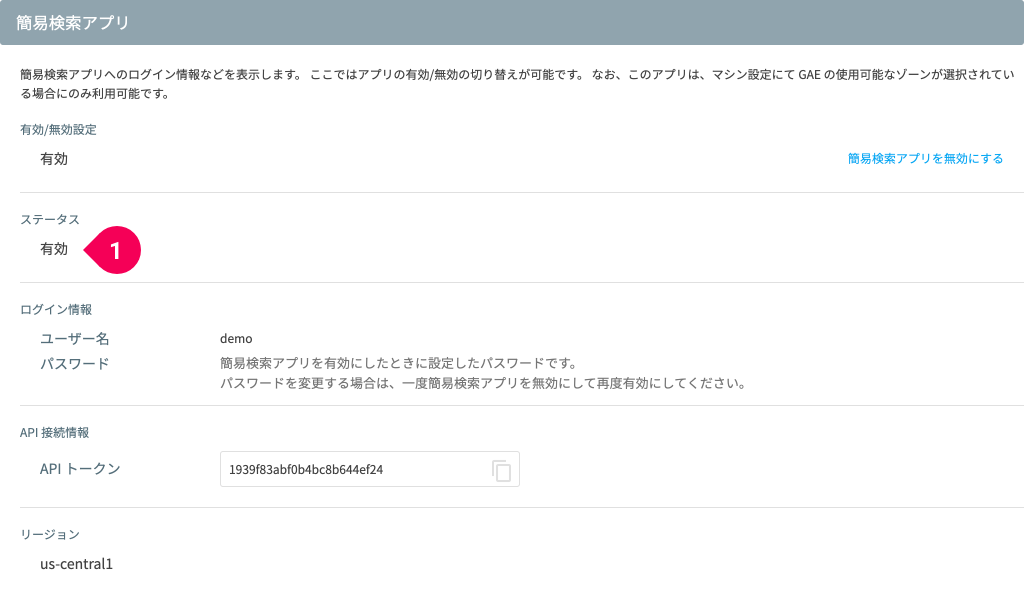
ステータスが[有効](❶)になったら準備完了です。

インデックス一覧の当該インデックスの[開く]をクリックします。
認証画面が表示されます。
以下のユーザー名とパスワードを入力して、[ログイン]ボタンをクリックします。
| ユーザー名 | demo |
| パスワード | 先ほど設定したパスワード |
簡易検索アプリが表示されます。

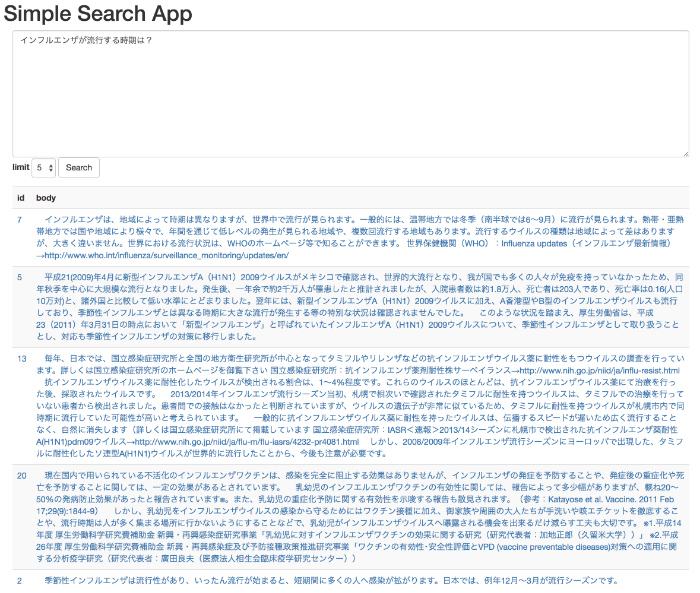
簡易検索アプリの使い方は簡単です。ボックス内に質問文章を入力し、[Search]ボタンをクリックするだけです。即座に結果が[Search]ボタンの下に表示されます。
[Search]ボタン左のlimitは、検索結果の表示件数の最大数です。limitの数値部分をクリックすると、5・10・20・30件の中から切り替えできます。
以下は、「インフルエンザが流行する時期は?」と入力して検索した例です。
以上ですべてのステップの完了です。
文書検索エンジンを使いこなすコツ
このようにデータさえあれば、簡単に文書検索エンジンのサービスが立ち上げられます。
ただし、文書検索エンジンの作り方を覚えてもそれだけで効果的な文書検索サービスが立ち上げられるわけではありません。
そこで、最後に効果的な文書検索サービスを立ち上げるための、文書検索エンジンを使いこなす3つのコツを紹介します。
- コツ1:1つの文書に複数のテーマが含まれないようにする
1つの文書に複数のテーマが含まれていると検索精度が良くない傾向にあります。
1つの文章に複数のテーマが含まれている場合は、1文章1テーマとなるように分割してください。 これにより検索精度の向上が見込めます。
- コツ2:文字数が少ない文章を精査する
登録されているデータの文字数が少ないものは検索に引っかからないか、上位表示されにくい傾向にあります。
文字数が少ないとその文書(質問や回答)の特徴を示す言葉が書かれていないことが多く、適切な検索結果を得ることができません。
このような場合は、文書の特徴を示す文言が含まれるように加筆・修正することで、検索精度の向上が見込めます。
- コツ3:検索結果の評価を反映する
お客さま開発アプリの検索結果の詳細を表示する画面に、「この結果はお役に立ちましたか」のような質問を表示し、その回答で良い評価が得られた場合は質問と回答の関連付けを更新します。
このようにしておくと、次に同じような質問が来たときに、今回の回答が上位に表示されやすくなります。
バックアップとリストア
インデックスは、バックアップやリストアが可能です。ここでは、GCS上でのバックアップとリストアの方法について解説します。
info_outlineここで紹介するバックアップとリストアの方法は、文書検索エンジンを構築した同一ネットワーク上の仮想マシンからの実行を前提としています。
バックアップ
ここでは、バックアップをcronを使って定期的に実行させる方法を解説します。
事前準備
まず事前準備として、バックアップ・リストア先のGCS上のバケットを文書検索エンジンに登録します。
以下のコマンドを実行します。
url -XPUT <文書検索エンジンの接続情報>/_snapshot/my-bucket-data -d '
{
"type": "gcs",
"settings": {
"bucket": "my-bucket-data",
"service_account": "_default_"
}
}'
<文書検索エンジンの接続情報>:文書検索エンジン詳細画面の「接続情報」に置き換えます。my-bucket-data:バックアップ・リストアで使用するバケット名に置き換えます(2か所)。
info_outlineバケット配下の特定フォルダー以下にバックアップしたい場合は、以下のように実行します。
curl -XPUT <文書検索エンジンの接続情報>/_snapshot/my-bucket-data -d '
{
"type": "gcs",
"settings": {
"bucket": "my-bucket-data",
"base_path": "text-search-engine-backup",
"service_account": "_default_"
}
}'
<文書検索エンジンの接続情報>:文書検索エンジン詳細画面の「接続情報」に置き換えます。my-bucket-data:バックアップ・リストアで使用するバケット名に置き換えます(2か所)。text-search-engine-backup:バケット配下のフォルダー名に置き換えます。
バックアップを実行するApp Engineハンドラの実装とデプロイ
続いて、バックアップを実行するApp Engineハンドラを実装し、デプロイします。
以下に、App EngineハンドラのJava Servletによる実装サンプルを掲載します。コメント記載行は、コメントの内容に従い環境に合わせて、文字列値を書き替えてください。
/*
* Copyright 2016 Google Inc. All Rights Reserved.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package myapp;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLEncoder;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.json.JSONObject;
import java.text.SimpleDateFormat;
import java.util.Date;
public class BackupServlet extends HttpServlet {
@Override
public void doGet(HttpServletRequest req, HttpServletResponse resp)
throws IOException {
Date now = new Date();
SimpleDateFormat format = new SimpleDateFormat("yyyyMMdd-HHmmss");
String addr = "35.227.237.120"; // HTTPS LB のフロントエンドの IP アドレス
String repo = "my-bucket-data"; //バックアップ先となるバケット名
String name = "backup-" + format.format(now); //バックアップ名
URL url = new URL(String.format("http://%s/_snapshot/%s/%s", addr, repo, name));
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setDoOutput(true);
conn.setRequestMethod("PUT");
conn.setRequestProperty("Content-Type", "application/json");
int respCode = conn.getResponseCode();
StringBuffer response = new StringBuffer();
String line;
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
while ((line = reader.readLine()) != null) {
response.append(line);
}
reader.close();
resp.setStatus(respCode);
resp.setContentType("application/json");
resp.getWriter().println(response.toString());
}
}
info_outlineCloud IAPによる認証は省略しています。
以下は、Java Servletのデプロイ記述ファイルweb.xmlのサンプルです。
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE web-app PUBLIC
"-//Oracle Corporation//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app xmlns="http://java.sun.com/xml/ns/javaee" version="2.5">
<servlet>
<servlet-name>backup</servlet-name>
<servlet-class>myapp.BackupServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>backup</servlet-name>
<url-pattern>/backup</url-pattern>
</servlet-mapping>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
</welcome-file-list>
<security-constraint>
<web-resource-collection>
<web-resource-name>backup</web-resource-name>
<url-pattern>/backup</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>admin</role-name>
</auth-constraint>
</security-constraint>
</web-app>
info_outlineauth-constraintのrole-nameにadminを指定することで、cron・アプリケーションのデベロッパー(App Engine管理者)・Projectオーナー・Project編集者・Project閲覧者だけが、App Engineのハンドラにアクセスできます。
デプロイは、以下のコマンドを実行します(Mavenの場合の例)。
mvn appengine:deploy
cronジョブの設定
最後に、cronを使用してデプロイしたバックアップのアプリケーションを定期実行させます。このために、cron.xmlファイルopen_in_newを使用します。
cron.xmlファイルの例を以下に示します(毎日22:05にバックアップを実行する例)。
<?xml version="1.0" encoding="UTF-8"?>
<cronentries>
<cron>
<url>/backup</url>
<description>backup</description>
<schedule>every day 22:05</schedule>
<target>backup</target>
<timezone>Asia/Tokyo</timezone>
</cron>
</cronentries>
以下のコマンドでcronジョブをデプロイし、バックアップを定期実行させます(Mavenの場合の例)。
mvn appengine:deployCron
info_outlinecronリクエストはIPアドレス0.1.0.1から呼び出されるため、Google App Engineのファイアウォールで制限している場合は、アクセスできるように以下のコマンドを実行する必要があります。
PROJECT=<GCPプロジェクト> PRIORITY=<優先度> gcloud app --project $PROJECT firewall-rules create $PRIORITY --action ALLOW --source-range 0.1.0.1
リストア
以下のコマンドを実行して、リストアします。
curl -XPOST "<文書検索エンジンの接続情報>/_snapshot/my-bucket-data/<バックアップ名>/_restore"
info_outlineリストア先にインデックスが存在していると失敗します。
info_outlineバックアップ情報取得の便利コマンドを2つ紹介します。
- バックアップ一覧の表示:
curl "<文書検索エンジンの接続情報>/_snapshot/my-bucket-data/_all"
- バックアップの情報表示:
curl "<文書検索エンジンの接続情報>/_snapshot/my-bucket-data/<バックアップ名>"
出力例:{ "snapshots" : [ { "snapshot" : "test", "uuid" : "Eg9jO9ZWR4iqPHdkVIKPnQ", "version_id" : 5010199, "version" : "5.1.1", "indices" : [ "myindex" ], "state" : "SUCCESS", "start_time" : "2018-01-26T10:09:34.211Z", "start_time_in_millis" : 1516961374211, "end_time" : "2018-01-26T10:09:37.722Z", "end_time_in_millis" : 1516961377722, "duration_in_millis" : 3511, "failures" : [ ], "shards" : { "total" : 1, "failed" : 0, "successful" : 1 } } ] }"state"値からバックアップの状態が分かります。- "IN_PROGRESS":バックアップ作成中
- "SUCCESS":バックアップ作成完了
- "FAILED":バックアップ作成失敗
- "PARTIAL":バックアップの一部のデータの保存に失敗
- "INCOMPATIBLE":現在の文書検索エンジンと互換性がないバックアップ
Web APIの紹介
文書検索エンジン(文書検索タイプ)の文書検索エンジンには、JSON形式のRESTful API(API)を使ってアクセスできます。このAPIを使って、検索エンジンを活用した検索アプリや検索ボットなどのアプリケーションの開発が可能です。
ここでは、現在公開している14種類のAPIについて簡単に解説しています。文書検索エンジンを使ったアプリを開発する際の参考としてお使いください。
APIの解説中に表れる<>で囲まれた記述は、以下の説明にしたがって読み替えてください。
<IPアドレス:ポート番号> |
文書検索エンジン詳細画面の「接続情報」で示されるIPアドレスとポート番号です。 |
<インデックス名> |
API発行対象のインデックス名です。 |
<回答ID> |
回答文書のIDです。 |
<質問ID> |
質問文章のIDです。 |
APIの解説中の「curlコマンド例」の実行例は、文書検索エンジンを構築した同一ネットワーク上の仮想マシンから実行した例です。
1.質問から回答を検索(回答データのみのケース)
| 概要 |
質問文章からその回答として近い回答データを返します。返ってくる回答データの順番は、質問文章に回答として近しい順です。 対象:回答データと質問データの関係が1:0(回答データのみ)のケース |
| エンドポイント | <IPアドレス:ポート番号>/<インデックス名>/target,hint/_search |
| メソッド | GET |
| リクエスト例 |
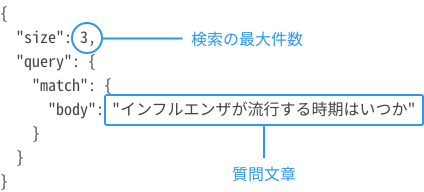
|
| レスポンス例 |
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits": {
"total": 32,
"max_score": 4.0507264,
"hits": [
{
"_index": "influenza-faq",
"_type": "target",
"_id": "7",
"_score": 4.0507264,
"_source": {
"body": "インフルエンザは、地域によって時期は異なりますが、世界中で流行が見られます。一般的には、温帯地方では冬季(南半球では6~9月)に流行が見られます。熱帯・亜熱帯地方では国や地域により様々で、年間を通じて低レベルの発生が見られる地域や、複数回流行する地域もあります。流行するウイルスの種類は地域によって差はありますが、大きく違いません。世界における流行状況は、WHOのホームページ等で知ることができます。\n\n世界保健機関(WHO):Influenza updates(インフルエンザ最新情報)→http://www.who.int/influenza/surveillance_monitoring/updates/en/",
"target_id": "7"
}
},
{
"_index": "influenza-faq",
"_type": "target",
"_id": "5",
"_score": 3.4223063,
"_source": {
"body": "平成21(2009)年4月に新型インフルエンザA(H1N1)2009ウイルスがメキシコで確認され、世界的大流行となり、我が国でも多くの人々が免疫を持っていなかったため、同年秋季を中心に大規模な流行となりました。発生後、一年余で約2千万人が罹患したと推計されましたが、入院患者数は約1.8万人、死亡者は203人であり、死亡率は0.16(人口10万対)と、諸外国と比較して低い水準にとどまりました。翌年には、新型インフルエンザA(H1N1)2009ウイルスに加え、A香港型やB型のインフルエンザウイルスも流行しており、季節性インフルエンザとは異なる時期に大きな流行が発生する等の特別な状況は確認されませんでした。\n\nこのような状況を踏まえ、厚生労働省は、平成23(2011)年3月31日の時点において「新型インフルエンザ」と呼ばれていたインフルエンザA(H1N1)2009ウイルスについて、季節性インフルエンザとして取り扱うこととし、対応も季節性インフルエンザの対策に移行しました。",
"target_id": "5"
}
},
{
"_index": "influenza-faq",
"_type": "target",
"_id": "13",
"_score": 3.0334578,
"_source": {
"body": "毎年、日本では、国立感染症研究所と全国の地方衛生研究所が中心となってタミフルやリレンザなどの抗インフルエンザウイルス薬に耐性をもつウイルスの調査を行っています。詳しくは国立感染症研究所のホームページを御覧下さい\n\n国立感染症研究所:抗インフルエンザ薬剤耐性株サーベイランス→http://www.nih.go.jp/niid/ja/influ-resist.html\n\n抗インフルエンザウイルス薬に耐性化したウイルスが検出される割合は、1~4%程度です。これらのウイルスのほとんどは、抗インフルエンザウイルス薬にて治療を行った後、採取されたウイルスです。\n\n 2013/2014年インフルエンザ流行シーズン当初、札幌で相次いで確認されたタミフルに耐性を持つウイルスは、タミフルでの治療を行っていない患者から検出されました。患者間での接触はなかったと判断されていますが、ウイルスの遺伝子が非常に似ているため、タミフルに耐性を持つウイルスが札幌市内で同時期に流行していた可能性が高いと考えられています。\n\n一般的に抗インフルエンザウイルス薬に耐性を持ったウイルスは、伝播するスピードが遅いため広く流行することなく、自然に消失します(詳しくは国立感染症研究所にて掲載しています\n\n国立感染症研究所:IASR<速報>2013/14シーズンに札幌市で検出された抗インフルエンザ薬耐性A(H1N1)pdm09ウイルス→http://www.nih.go.jp/niid/ja/flu-m/flu-iasrs/4232-pr4081.html\n\nしかし、2008/2009年インフルエンザ流行シーズンにヨーロッパで出現した、タミフルに耐性化したソ連型A(H1N1)ウイルスが世界的に流行したことから、今後も注意が必要です。",
|
| curlコマンド例 |
curl -X GET 10.128.0.3:9200/influenza-faq/target,hint/_search -H 'Content-Type:application/json' --data '{ "size": 5, "query": { "match": { "body": "インフルエンザが流行する時期はいつか" } } }'
|
| 備考 |
2.質問から回答IDを検索(回答と質問が1:多のケース)
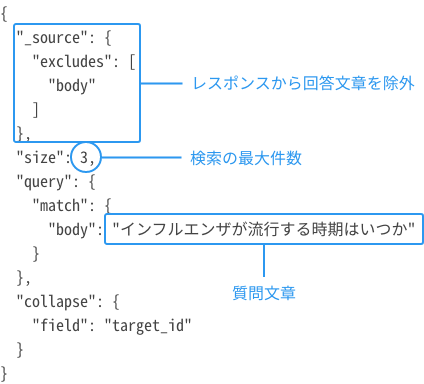
| 概要 |
質問文章からその回答として近い回答データのID("target_id")を返します。返ってくるIDの順番は、質問文章に回答として近しい順です。 対象:回答データと質問データの関係が1:多のケース |
| エンドポイント | <IPアドレス:ポート番号>/<インデックス名>/target,hint/_search |
| メソッド | GET |
| リクエスト例 |
|
| レスポンス例 |
{
"took": 94,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits": {
"total": 61,
"max_score": null,
"hits": [
{
"_index": "influenza-faq",
"_type": "target",
"_id": "7",
"_score": 5.2207584,
"_source": {
"target_id": "7"
},
"fields": {
"target_id": [
"7"
]
}
},
{
"_index": "influena-faq",
"_type": "target",
"_id": "5",
"_score": 4.3226757,
"_source": {
"target_id": "5"
},
"fields": {
"target_id": [
"5"
]
}
},
{
"_index": "influenza-faq",
"_type": "target",
"_id": "13",
"_score": 3.787116,
"_source": {
"target_id": "13"
},
"fields": {
"target_id": [
"13"
]
}
}
]
}
}
|
| curlコマンド例 |
curl -X GET 10.128.0.3:9200/influenza-faq/target,hint/_search -H 'Content-Type:application/json' --data '{ "_source": {"excludes": ["body"] }, "size": 3, "query": { "match": { "body": "インフルエンザが流行する時期はいつか" } }, "collapse": { "field": "target_id" } }'
|
| 備考 |
3.質問から回答IDを検索(回答と質問が多:多のケース)
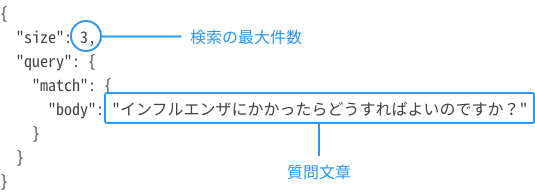
| 概要 |
質問文章からその回答として近い回答データのID("target_id")を返します。返ってくるIDの順番は、質問文章に回答として近しい順です。 対象:回答データと質問データの関係が多:多のケース |
| エンドポイント | <IPアドレス:ポート番号>/<インデックス名>/target,hint/_search |
| メソッド | GET |
| リクエスト例 |
|
| レスポンス例 |
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits": {
"total": 63,
"max_score": 13.286041,
"hits": [
{
"_index": "influenza-faq",
"_type": "hint",
"_id": "10",
"_score": 13.286041,
"_source": {
"body": "インフルエンザにかかったらどうすればよいのですか?",
"target_ids": [
"10",
"14",
"15"
]
}
},
{
"_index": "influenza-faq",
"_type": "hint",
"_id": "9",
"_score": 10.997316,
"_source": {
"body": "インフルエンザにかからないためにはどうすればよいですか?",
"target_ids": [
"9"
]
}
},
{
"_index": "influenza-faq",
"_type": "hint",
"_id": "17",
"_score": 8.525941,
"_source": {
"body": "インフルエンザにかかったら、どのくらいの期間外出を控えればよいのでしょうか?",
"target_ids": [
"17"
]
}
}
]
}
}
|
| curlコマンド例 |
curl -X GET 10.128.0.3:9200/influenza-faq/target,hint/_search -H 'Content-Type:application/json' --data '{ "size": 3, "query": { "match": { "body": "インフルエンザにかかったらどうすればよいのですか?" } } }'
|
| 備考 |
|
4.特定の回答を取得
| 概要 | 回答IDを指定して、その回答文書を取得します。 |
| エンドポイント | <IPアドレス:ポート番号>/<インデックス名>/target/<回答ID> |
| メソッド | GET |
| リクエスト例 | (リクエストボディなし) |
| レスポンス例 |
{
"_index": "influenza-faq",
"_type": "target",
"_id": "10",
"_version": 1,
"found": true,
"_source": {
"body": "(1) 具合が悪ければ早めに医療機関を受診しましょう。\n\n(2) 安静にして、休養をとりましょう。特に、睡眠を十分にとることが大切です。\n\n(3) 水分を十分に補給しましょう。お茶でもスープでも飲みたいもので結構です。\n\n(4) 咳やくしゃみ等の症状のある時は、周りの方へうつさないように、不織布製 マスクを着用しましょう。\n\n(5) 人混みや繁華街への外出を控え、無理をして学校や職場等に行かないようにしましょう。\n\nまた、小児、未成年者では、インフルエンザの罹患により、急に走り出す、部屋から飛び出そうとする、ウロウロと歩き回る等の異常行動を起こすおそれがあるので、自宅において療養を行う場合、少なくとも発症から2日間、小児・未成年者が一人にならないよう配慮しましょう(Q14、15を参照)。",
"target_id": "10"
}
}
|
| curlコマンド例 |
curl -X GET 10.128.0.3:9200/influenza-faq/target/10 |
| 備考 |
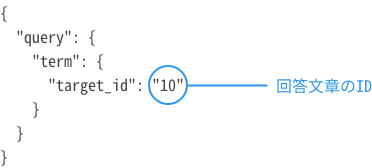
5.回答に関連した質問を取得(回答と質問が1:多のケース)
| 概要 |
回答データに関連付けられた質問データを取得します。 対象:回答データと質問データの関係が1:多のケース |
| エンドポイント | <IPアドレス:ポート番号>/<インデックス名>/hint/_search |
| メソッド | GET |
| リクエスト例 |
|
| レスポンス例 |
{
"took": 44,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 3.2580965,
"hits": [
{
"_index": "influenza-faq",
"_type": "hint",
"_id": "10",
"_score": 3.2580965,
"_source": {
"body": "インフルエンザにかかったらどうすればよいのですか?",
"target_id": "10"
}
}
]
}
}
|
| curlコマンド例 |
curl -X GET 10.128.0.3:9200/influenza-faq/hint/_search -H 'Content-Type:application/json' --data '{ "query": { "term": { "target_id": "10" } } }'
|
| 備考 |
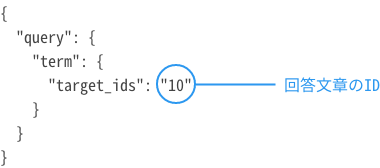
6.回答に関連した質問を取得(回答と質問が多:多のケース)
| 概要 |
回答データに関連付けられた質問データを取得します。 対象:回答データと質問データの関係が多:多のケース |
| エンドポイント | <IPアドレス:ポート番号>/<インデックス名>/hint/_search |
| メソッド | GET |
| リクエスト例 |
|
| レスポンス例 |
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1.4505018,
"hits": [
{
"_index": "influenza-faq",
"_type": "hint",
"_id": "10",
"_score": 1.4505018,
"_source": {
"body": "インフルエンザにかかったらどうすればよいのですか?",
"target_ids": [
"10",
"14",
"15"
]
}
}
]
}
}
|
| curlコマンド例 |
curl -X GET 10.128.0.3:9200/influenza-faq/hint/_search -H 'Content-Type:application/json' --data '{ "query": { "term": { "target_ids": "10" } } }'
|
| 備考 |
7.回答の追加・更新
| 概要 | 回答データを追加・更新します。 |
| エンドポイント | <IPアドレス:ポート番号>/<インデックス名>/target/<回答ID> |
| メソッド | POST |
| リクエスト例 |

|
| レスポンス例 |
|
| curlコマンド例 |
curl -X POST 10.128.0.3:9200/influenza-faq/target/33 -H 'Content-Type:application/json' --data '{ "body": "回答データを追加するサンプル文章です。", "target_id": 33 }'
|
| 備考 |
8.質問の追加・更新(回答と質問が1:多のケース)
| 概要 |
質問データを追加・更新します。 対象:回答データと質問データの関係が1:多のケース |
| エンドポイント | <IPアドレス:ポート番号>/<インデックス名>/hint/<回答ID> |
| メソッド | POST |
| リクエスト例 |
|
| レスポンス例 |
|
| curlコマンド例 |
curl -X POST 10.128.0.3:9200/influenza-faq/hint/33 -H 'Content-Type:application/json' --data '{ "body": "質問データを追加するサンプル文章です。", "target_id": 33 }'
|
| 備考 |
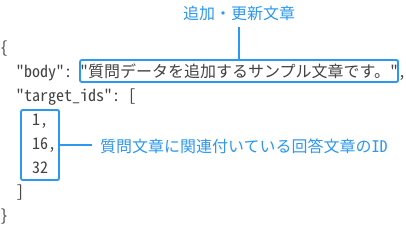
9.質問の追加・更新(回答と質問が多:多のケース)
| 概要 |
質問データを追加・更新します。 対象:回答データと質問データの関係が多:多のケース |
| エンドポイント | <IPアドレス:ポート番号>/<インデックス名>/hint/<回答ID> |
| メソッド | POST |
| リクエスト例 |
|
| レスポンス例 |
|
| curlコマンド例 |
curl -X POST 10.128.0.3:9200/influenza-faq/hint/33 -H 'Content-Type:application/json' --data '{ "body": "質問データを追加するサンプル文章です。", "target_ids": [1, 16, 32] }'
|
| 備考 |
10.質問に関連付ける回答を追加
| 概要 |
質問データに関連付ける回答IDを追加します。 |
| エンドポイント | <IPアドレス:ポート番号>/<インデックス名>/hint/<質問ID>/_update |
| メソッド | POST |
| リクエスト例 |

|
| レスポンス例 |
{
"_index": "influenza-faq",
"_type": "hint",
"_id": "5",
"_version": 2,
"result": "updated",
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
}
}
|
| curlコマンド例 |
curl -X POST 10.128.0.3:9200/influenza-faq/hint/5/_update -H 'Content-Type:application/json' --data '{ "script": "ctx._source.target_ids.add(\"20\")" }'
|
| 備考 |
11.質問文章・回答文章の更新
| 概要 |
質問文章もしくは回答文章を更新します。 |
| エンドポイント |
|
| メソッド | POST |
| リクエスト例 |

|
| レスポンス例 |
{
"_index": "influenza-faq",
"_type": "hint",
"_id": "5",
"_version": 3,
"result": "updated",
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
}
}
|
| curlコマンド例 |
curl -X POST 10.128.0.3:9200/influenza-faq/hint/5/_update -H 'Content-Type:application/json' --data '{ "doc": { "body": "これは質問文章を更新するサンプル文章です。" } }'
|
| 備考 |
12.特定の質問データ・回答データの削除
| 概要 |
質問IDもしくは回答IDを指定して、特定の質問データもしくは回答データを削除します。 |
| メソッド | DELETE |
| エンドポイント |
|
| メソッド | DELETE |
| リクエスト例 | (リクエストボディなし) |
| レスポンス例 |
{
"found": true,
"_index": "influenza-faq",
"_type": "hint",
"_id": "33",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
}
}
|
| curlコマンド例 |
curl -X DELETE 10.128.0.3:9200/influenza-faq/hint/33 |
| 備考 |
13.質問データ・回答データの全件削除
| 概要 |
質問データもしくは回答データを全件削除します。 |
| エンドポイント |
|
| メソッド | POST |
| リクエスト例 |
{
"query": {
"match_all": {}
}
}
|
| レスポンス例 |
{
"took": 72,
"timed_out": false,
"total": 32,
"deleted": 32,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}
|
| curlコマンド例 |
curl -X POST 10.128.0.3:9200/influenza-faq/hint/_delete_by_query -H 'Content-Type:application/json' --data '{ "query": { "match_all": {} } }'
|
| 備考 |
14.質問データ・回答データの一括登録
| 概要 |
質問データもしくは回答データを一括登録します。 |
エンドポイント |
|
| メソッド | POST |
| リクエスト例 |
|
| レスポンス例 |
{
"took": 37,
"errors": false,
"items": [
{
"index": {
"_index": "influenza-faq",
"_type": "hint",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"created": true,
"status": 201
}
},
{
"index": {
"_index": "influenza-faq",
"_type": "hint",
"_id": "2",
"_version": 1,
"result": "created",
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"created": true,
"status": 201
}
}
]
}
|
| curlコマンド例 |
curl -X POST 10.128.0.3:9200/influenza-faq/hint/_bulk -H 'Content-Type:application/x-ndjson' --data-binary @sample.json |
| 備考 |