数値分類モデルを利用した分類
はじめに
MAGELLAN BLOCKS(BLOCKS)の機械学習サービスを活用すると、数値データを基にした分類が可能です。具体的には、さまざまな数値データから類似性に基づいた以下のようなグループ分けができます。
- オンラインショップの利用データから「リピーター(0)/非リピーター(1)」を分類
- スマートフォンアプリの使用状況から「アクティブユーザー(0)/非アクティブユーザー(1)」を分類
- スマートフォンアプリの使用状況から「アクティブユーザー(0)/非アクティブユーザー(1)」を分類
- 健康診断の結果から「リスクの低い健康状態(0)/リスクの高い健康状態(1)」を分類
ここでは、あやめのがく片と花びらのサイズからあやめの種類を「ロジスティック回帰(分類)」モデルを使って分類する方法を紹介します。
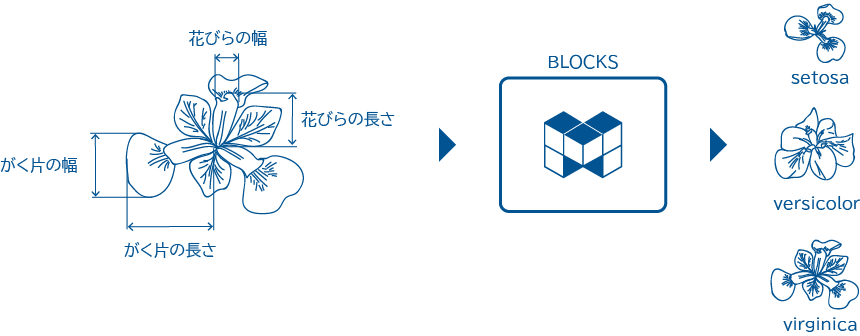
ロジスティック回帰は、データを2つ以上のグループに分類するシンプルながら効果的な手法で、あやめのデータの特徴を明確にし、異なる種類に効率的かつ正確に分類するのに最適です。
他にも「AutoML(分類)」「XGBoost(分類)」「Deep Neural Network(分類)」といったモデルがありますが、今回のケースではロジスティック回帰が適しています。
数値分類のおおまかな流れ
BLOCKSの機械学習では、DataEditorを使用します。下図は、今回の例における数値分類の流れです。
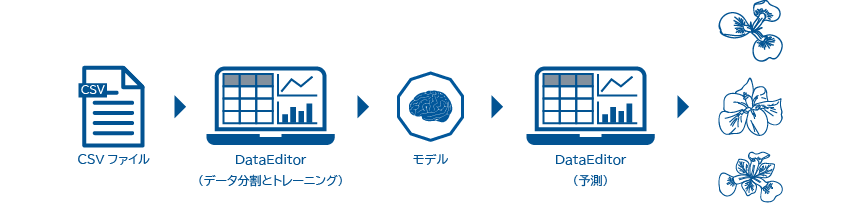
- DataEditorでCSVファイルを取り込み(インポート)、トレーニング用データと予測用データに分割
CSVファイルには、あやめのがく片の長さ・がく片の幅・花びらの長さ・花びらの幅とあやめの種類がまとめられています。 - DataEditorで学習(トレーニング)
あやめのがく片の長さ・がく片の幅・花びらの長さ・花びらの幅とあやめの種類との因果関係を学ばせます。
このトレーニングの結果として、モデルと呼ばれる学習成果が得られます。 - DataEditorであやめの種類を予測
今回予測するあやめの種類は、以下の3種類です。- Iris-versicolor(バージカラー)
- Iris-setosa(セトサ)
- Iris-virginica(バージニカ)
数値分類を試してみよう
このチュートリアルでは、下図のステップで数値分類の一連の流れを解説します。

機械学習では、まとまったデータが必要不可欠です。機械学習では、まとまったデータを元に学習を行うことで、予測が可能となります。このため、機械学習においてデータの収集と加工が最初の作業となります。
なお、チュートリアルを進めるにあたって、BLOCKS推奨のウェブブラウザーGoogle Chromeを準備してください。Firefoxでも構いませんが、このチュートリアルでは、Google Chromeの使用を前提にしています。
CSVファイルを準備しよう
まず、数値分類のトレーニングと予測に必要なデータを準備します。データは、カンマ(,)区切りのCSVファイル(BOMなし・UTF-8)で用意します。
あやめの情報をまとめたCSVファイルは、カルフォルニア大学アーバイン校のサイトからダウンロードできます。
| データセットの詳細 | |
|---|---|
| 著作者 | R.A. Fisher |
| 提供元 | UCI Machine Learning Repository |
| データセットタイトル | Iris Data Set |
| ダウンロードリンク | bezdekIris.dataダウンロード |
上記bezdekIris.dataダウンロードをマウスの右ボタンクリックで、ファイルがダウンロードできます。
ダウンロードしたファイルは、カンマ(,)区切りのCSVファイルで、以下の5項目で構成されています。
- あやめのがく片の長さ(単位:cm)
- あやめのがく片の幅(単位:cm)
- あやめの花びらの長さ(単位:cm)
- あやめの花びらの幅(単位:cm)
- あやめの花の種類(Iris-versicolor・Iris-setosa・Iris-virginica)
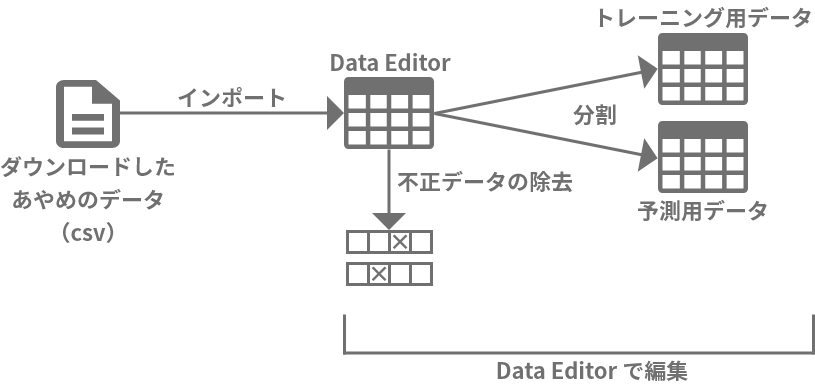
DataEditorでデータを分割しよう
このデータをDataEditorに取り込んで、トレーニング用データと予測用データに分割して利用します。
警告
ダウンロードしたあやめのデータには、不正なデータが混在している可能性があります。DataEditorによるデータの加工では、不正なデータをチェックし不正なデータがあればそれを除去した上で、トレーニング用データと予測用データに分割する手順を踏むことにします。
まず、ウェブブラウザーで、BLOCKSにログインしてください。
以下は、BLOCKSにログイン後の操作解説です。

- グローバルナビゲーション左端のメニューアイコン(menu)をクリック
- [
DataEditor]をクリック
ダウンロードしたあやめのデータをDataEditorにインポートします。
- [
インポート]ボタンをクリック
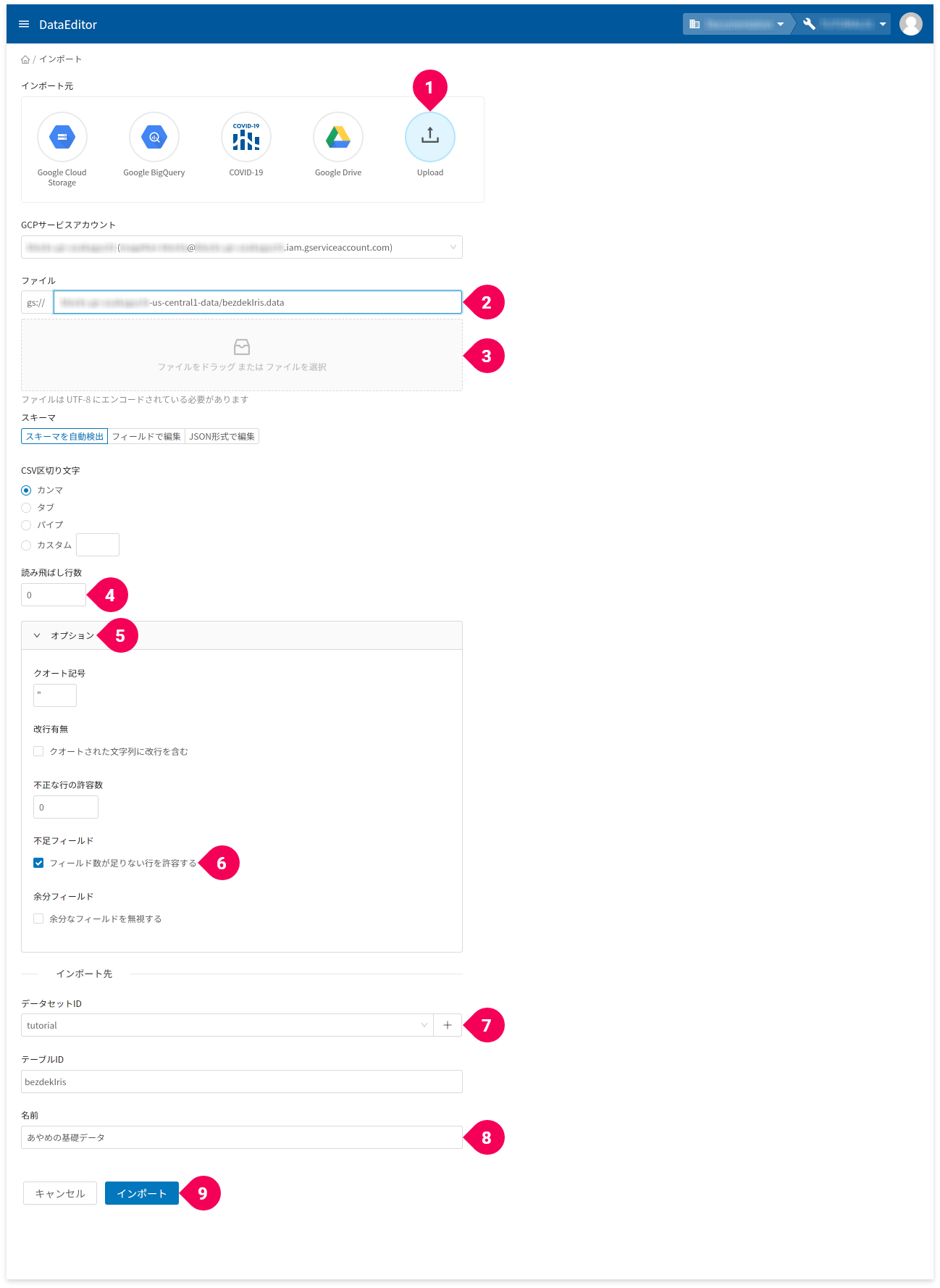
- インポート元から[
Upload]をクリック - GCS URLで
-dataで終わる項目をクリック - ファイル欄に、
bezdekIris.dataファイルをドラッグ・アンド・ドロップ - 読み飛ばし行数を
0に変更 - [
オプション]をクリック - [
フィールド数が足りない行を許容する]のチェックボックスをチェック - データセットIDの[
+]ボタンをクリックし、tutorialと入力
既にtutorialがある場合はそれを選択 - 名前欄に、
あやめの基礎データと入力 - [
インポート]ボタンをクリック
参考
DataEditorは、BigQuery上のデータを視覚的に操作できるツールです。BigQueryに関する知識は必要ありませんが、BigQuery上の重要な要素であるデータセットとテーブルは指定する必要があります。Microsoft Excelに例えると、データセットはブックで、テーブルはシートに対応する概念です。
[開く]をクリックします。
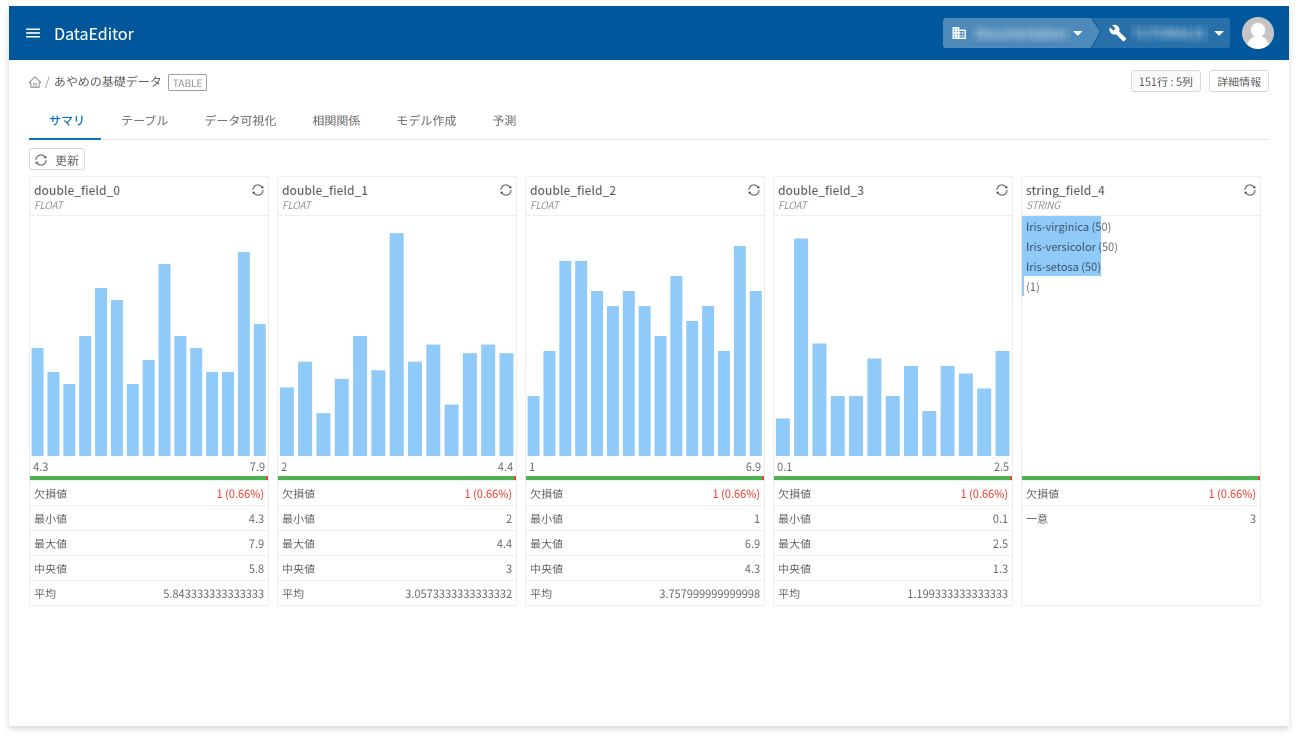
DataEditorにインポートしたデータを操作する画面が開きます。
データのインポートには成功しましたが、各列の見出しが自動付与されているため、どの列が何のデータが分かりづらくなっています。これを分かりやすい名前に変更します。
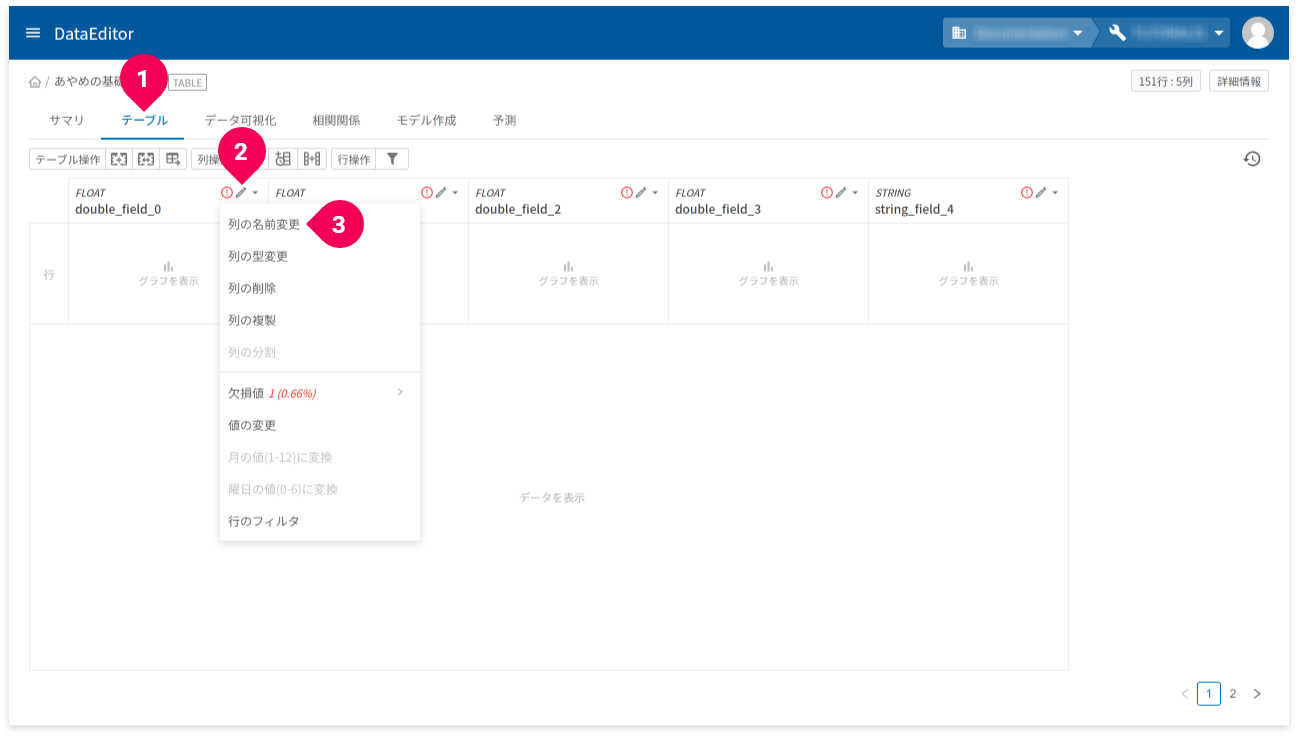
- [
テーブル]タブをクリック - [
edit]をクリック - [
列の名前変更]をクリック
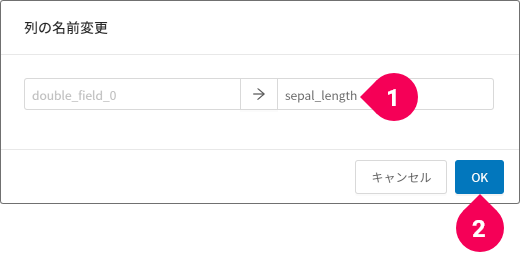
- 変更後の列の名前を入力
- [
OK]ボタンをクリック
この操作をすべての列に対して行います。名前は、左から順に以下の名前に変更します。
sepal_lengthsepal_widthpetal_lengthpetal_widthclass
続いて、不正データの除去を行います。
不正データを含む行は、使い物にならないため、行ごと削除します。
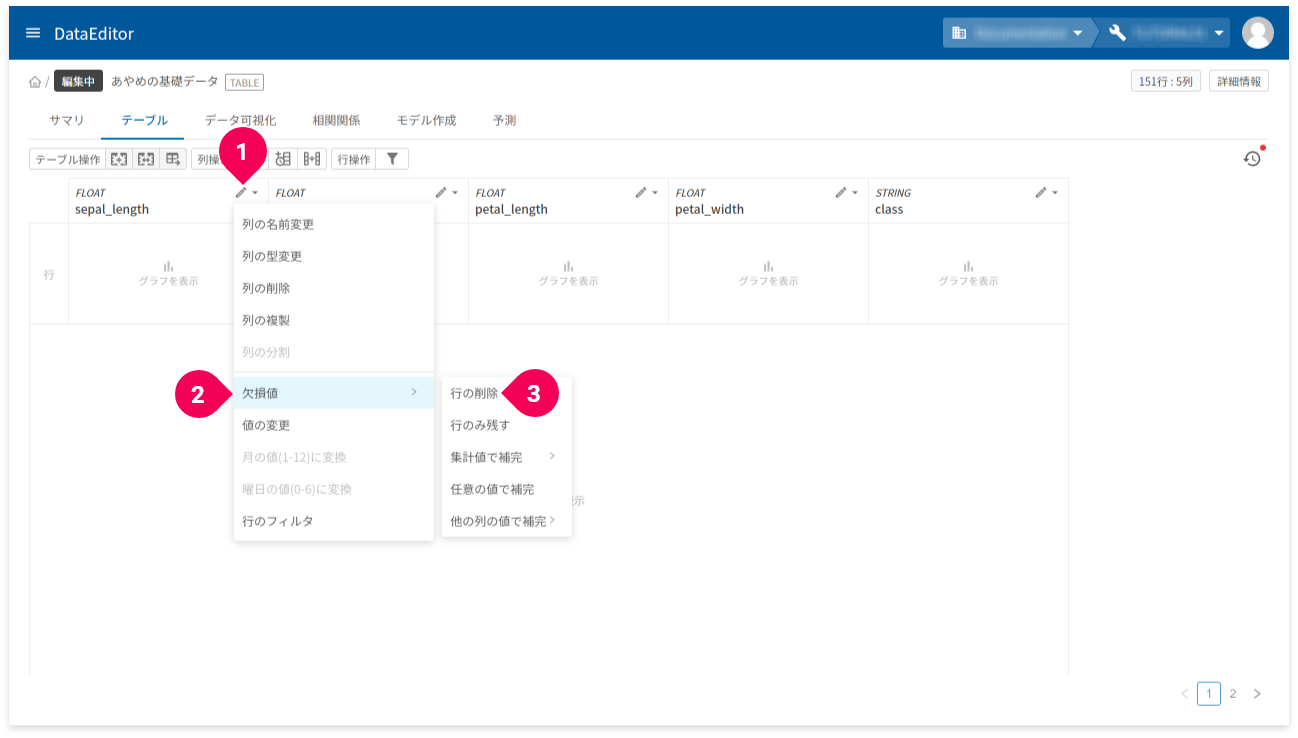
sepal_length列の[edit]をクリック- [
欠損値]をクリック - [
行の削除]をクリック
この操作を他のすべての列に対しても行います。
上記操作が完了したら、データを保存します。
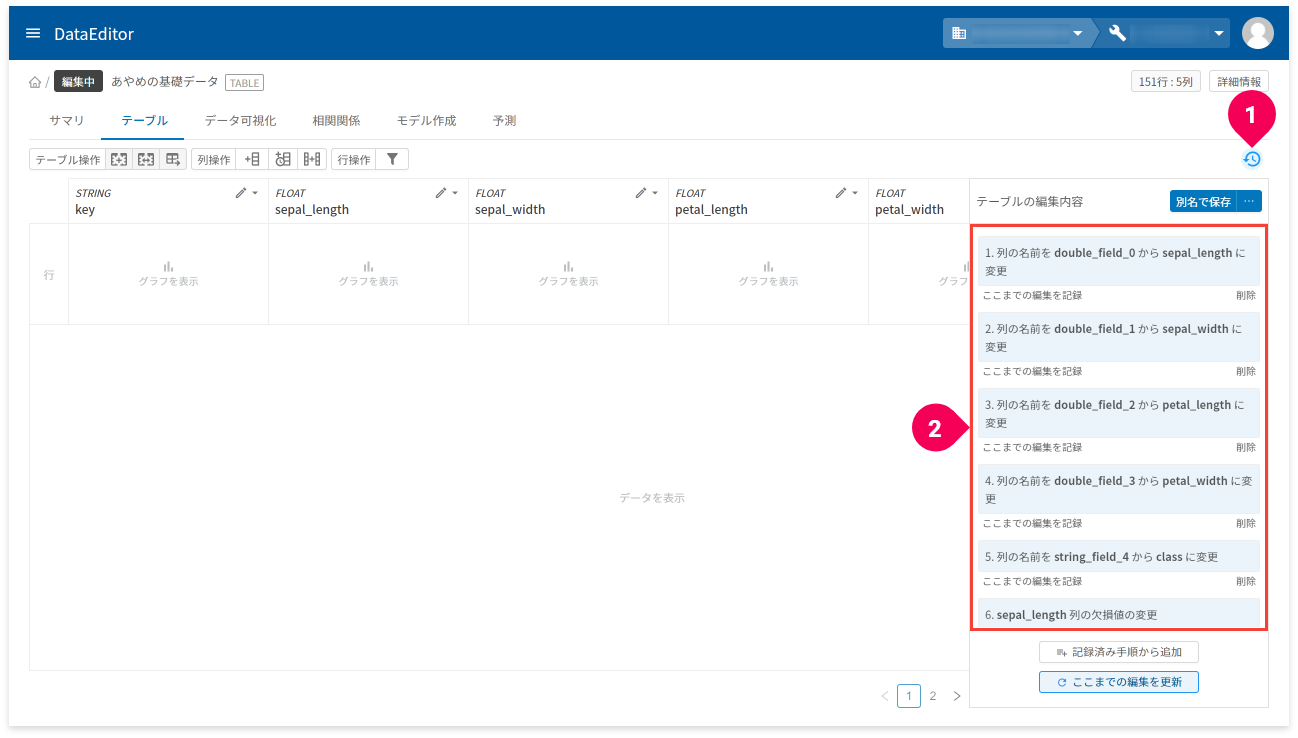
- [
history]をクリック - 表示される内容を確認
以下の内容が表示されていれば問題ありません。
列の名前をdouble_field_0からsepal_lengthに変更列の名前をdouble_field_1からsepal_widthに変更列の名前をdouble_field_2からpetal_lengthに変更列の名前をdouble_field_3からpetal_widthに変更列の名前をstring_field_4からclassに変更sepal_length列の欠損値の変更sepal_width列の欠損値の変更petal_length列の欠損値の変更petal_width列の欠損値の変更class列の欠損値の変更
変更した内容を保存します。
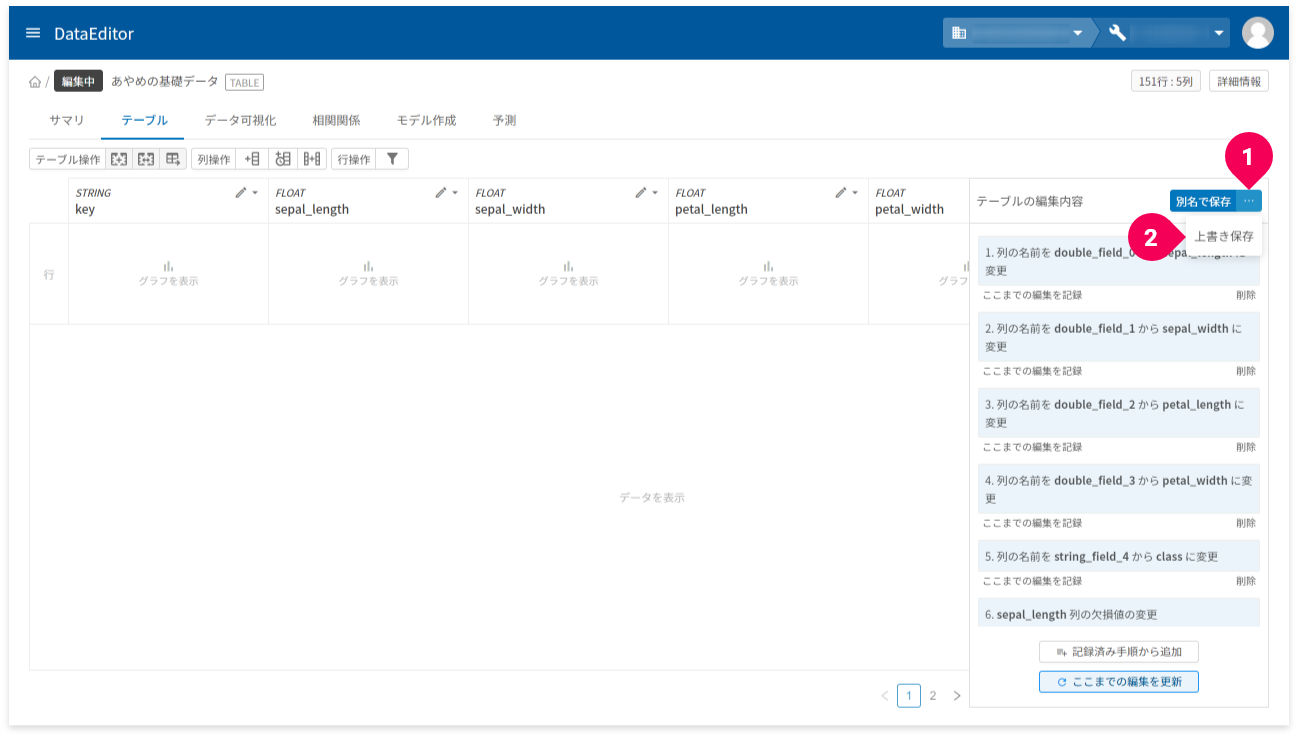
- [
別名で保存]ボタン横の[more_horiz]ボタンをクリック - [
上書き保存]をクリック
これで、あやめの基礎データが仕上がりました。続いて、このデータを元にトレーニング用データと予測用データに分割します。
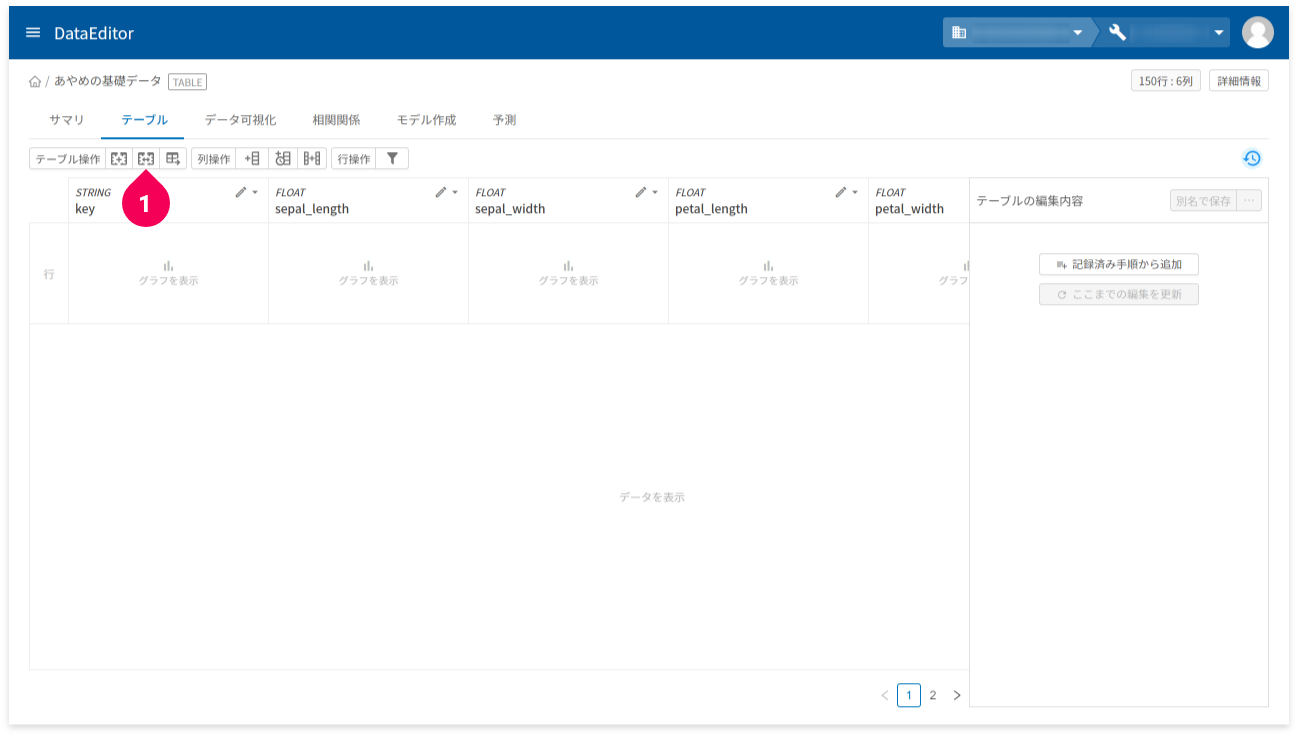
- テーブル分割のアイコンをクリック
トレーニング用データと予測用データは、8:2の割合でランダムに分割します(DataEditor分割機能の初期値)。データ分割時に、データ列の取捨選択ができるため、トレーニング用データと予測用データでそれぞれ適切なデータ列の取捨選択を行います。
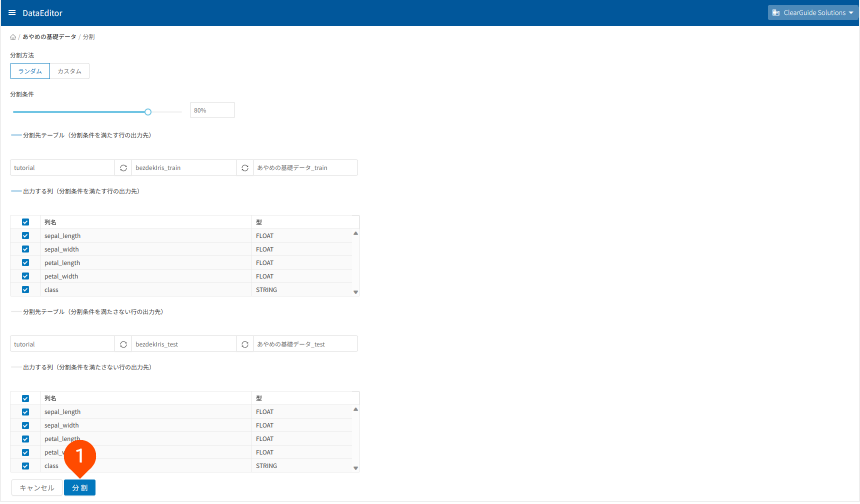
- [
分割]ボタンをクリック

- [
戻る]ボタンをクリック
これで、数値分類のトレーニングと予測に必要なデーターの準備ができました。
DataEditorでトレーニングしよう
先ほど準備したトレーニング用データを使いDataEditorでトレーニングを行います。
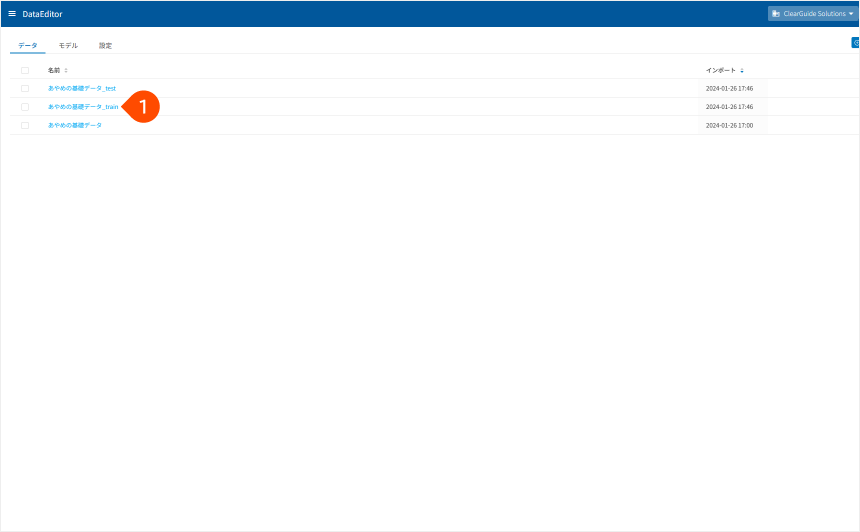
- [
あやめの基礎データ_train]をクリック
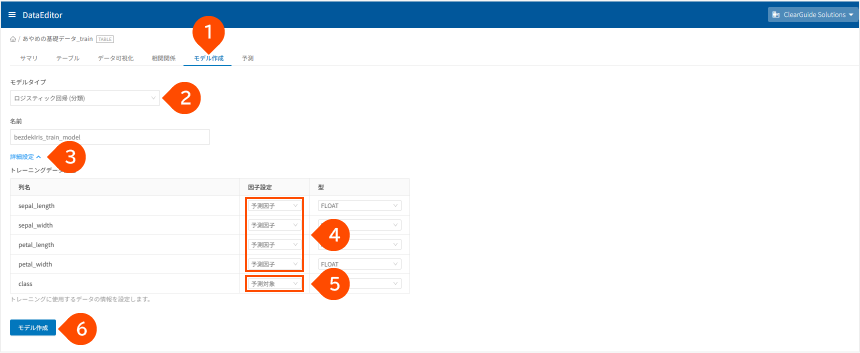
- [
モデル作成]タブをクリック - [
ロジステック回帰(分類)]をクリック - 「
詳細設定」をクリック - 列名
sepal_length、sepal_width、petal_length、petal_widthの因子設定が「予測因子」であることを確認 - 列名
classの因子設定が「予測対象」であることを確認 - [
モデル作成]ボタンをクリック

- [
閉じる]ボタンをクリック
これで、トレーニングが始まります。
トレーニングの状況は、モデル一覧画面およびモデルの詳細画面で確認できます。
- [
]をクリック
- [
モデル]タブをクリック

モデル名(❶)をクリックすると、そのモデルの詳細情報が確認できます。
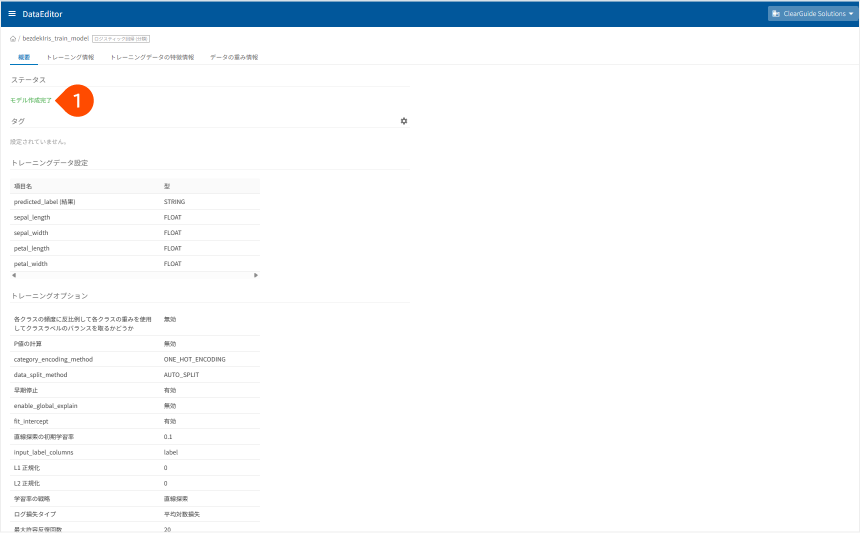
ステータスが「モデル作成完了」となるのを待ちます。
DataEditorで予測しよう
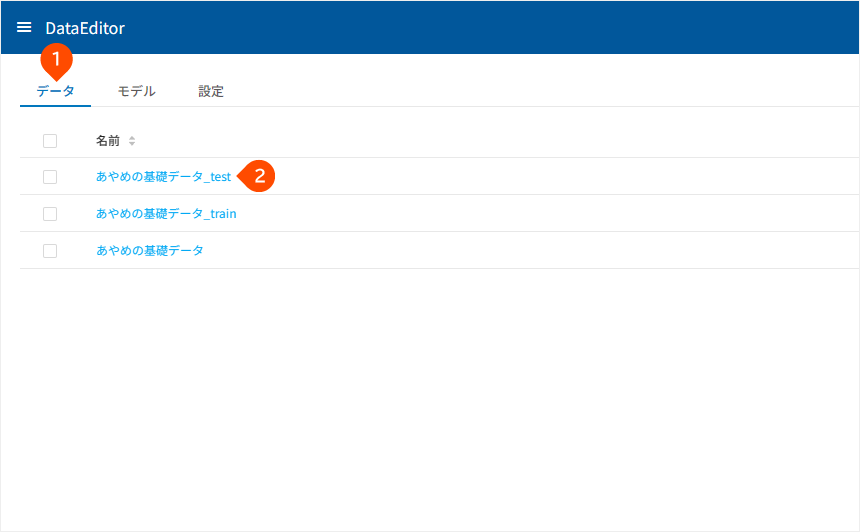
ここでは、分割した予測用のデータ(あやめの基礎データ_test)を使って予測します。
- [
]をクリック
- 「
データ」タブをクリック - 「
あやめの基礎データ_test」をクリック
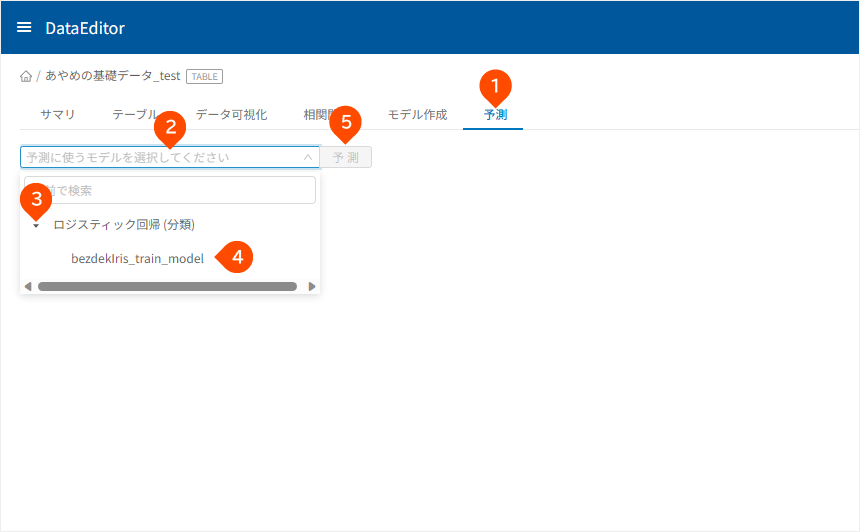
- [
予測]タブをクリック - 「
予測に使うモデルを選択してください」をクリック - 「
ロジスティック回帰(分類)」左横の「」をクリック - 「
bezdekIris_train_model」をクリック - [
予測]ボタンをクリック
しばらくすると予測結果が表示されます。
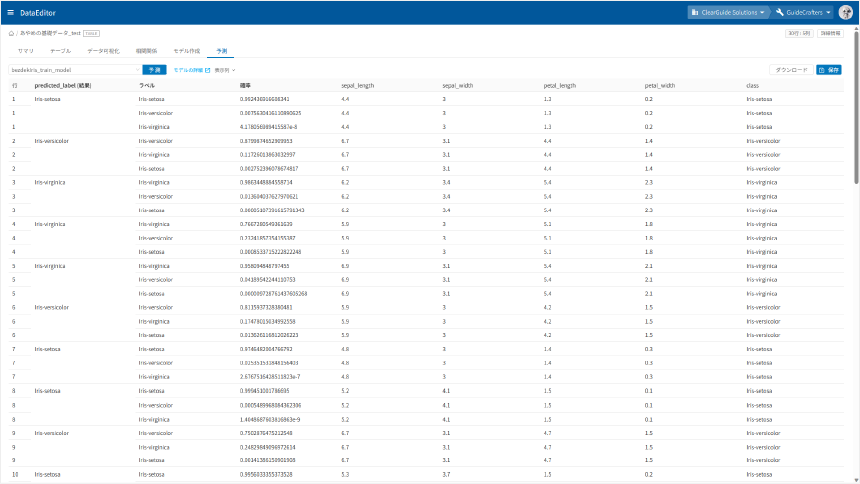
「predicted_label(結果)」列が予測結果です。
操作中にエラーとなったら
DataEditorのモデル作成時のエラー内容は、モデル詳細画面の「エラーログ」で確認できます。以下に、そのエラー内容の確認方法を紹介します。
注意
画面は開発中のもののため、ご利用中の画面とは異なる場合がありますが、操作方法に違いはありません。
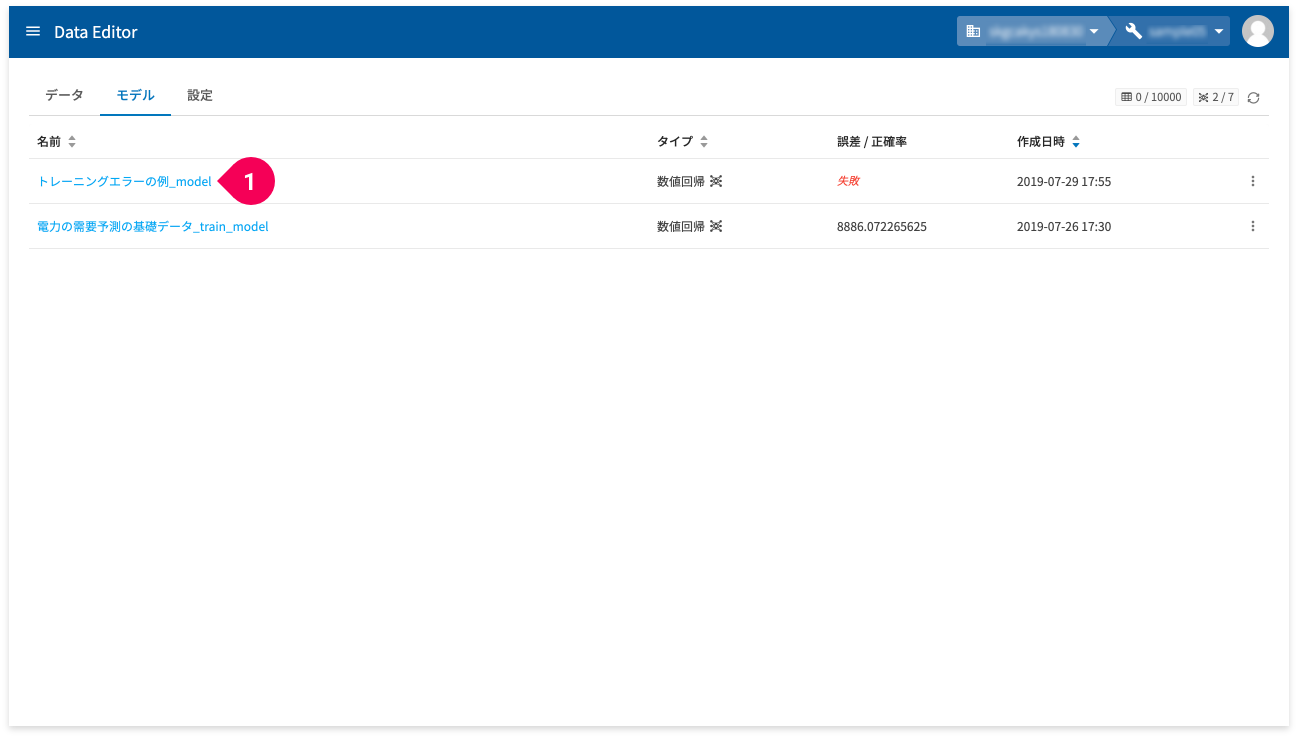
- モデル一覧の[
誤差/正確率]の欄が[失敗]と表示されている名前をクリック
- [
エラーログ]をクリック
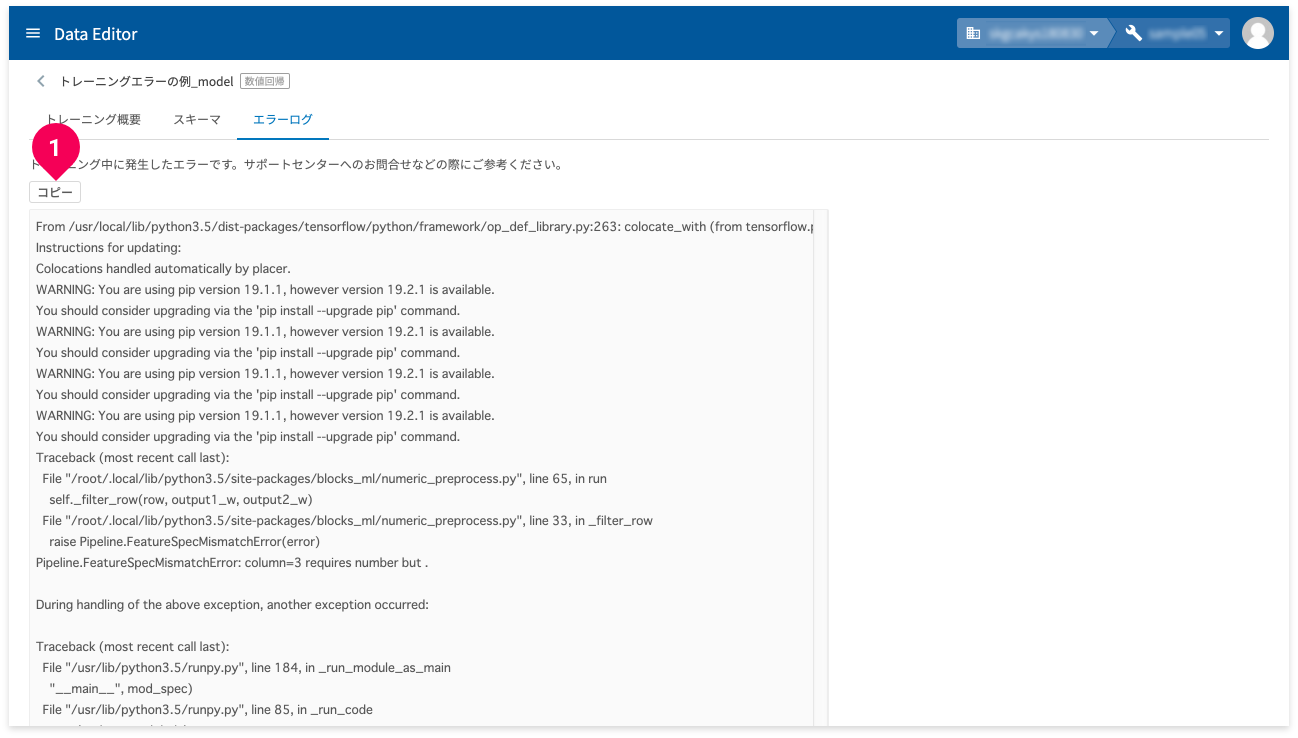
- [
コピー]ボタンをクリック
エラーの内容がクリップボードにコピーされます。
参考
お問い合わせについて詳しくは、基本操作ガイドの「お問い合わせ」を参考にしてください。
まとめ
このようにBLOCKSを使うと、データを準備するだけで、機械学習の専門的な知識は必要なく簡単に数値分類が利用できます。
ただし、データの準備に際し、留意点があります。準備するカンマ(,)区切りのCSVファイルは、BOMなし・UTF-8にしてください。これ以外だと、BLOCKSで扱うことができません。
参考
BOMなし・UTF-8について詳しくは、弊社ブログの「MAGELLAN BLOCKSを利用する上で文字コードのお話し」を参考にしてください。
重要
機械学習を使ってビジネスの課題を解決するには、チュートリアル同様にまずデータ収集から始めます。社内にある既存のデータを集めたり、新たにアンケートを採ってデータを集めたり、データを購入することもあります。更にそれらデータを精査し、データを選別したり、不正なデータを除去するなどのデータ加工の作業も必要です。このデータ収集と加工作業が、機械学習のステップの大半を占めると言っても過言ではありません。