Google Cloud
GCSから変数へロード
概要
このブロックは、Google Cloud Storage(GCS)上のファイルを読み取り(ロード)、その内容を変数に設定します。

たとえば、以下のテキストファイルがGCSのgs://magellan-sample/files.txtに記載されているとします。
sample1.png sample2.png
このファイルをこのブロックで処理すると、以下のようなデータが変数に設定されます。
{
"gcs_url": "gs://magellan-sample/files.txt",
"timestamp": 1480986550.0,
"content": "sample1.png\nsample2.png"
}
このように、変数にはファイルの内容だけでなく、付随する情報も含めてJSON形式のデータで設定します。「"content"」の「"codele1.png\ncodele2.png"」が、ファイル内容です(\nは改行です)。
ロードするファイルの形式は、(none)/YAML/JSON/改行区切りのJSON/バイナリ(Base64)/CSVから選択します。
| ファイル形式 | 説明 |
|---|---|
| (none) |
ファイル内容そのままを「 |
| YAML/JSON |
ファイル内容をそれぞれの形式で解析した結果を「 たとえば、以下のYAML形式のテキストファイルをロードさせるとします。 基本: -フローの開始 -並列分岐 - Slack通知 -ログへ出力 -オブジェクト生成 -フローの終了 API: - HTTP GET - HTTP POST - HTTP PUT - HTTP DELETE このファイルをこのブロックで処理すると、「
"content": {
"基本": [
"フローの開始",
"並列分岐",
"Slack通知",
"ログへ出力",
"オブジェクト生成",
"フローの終了"
],
"API": [
"HTTP GET",
"HTTP POST",
"HTTP PUT",
"HTTP DELETE"
]
}
|
| 改行区切りのJSON |
改行区切りのJSONを配列に変換し、「 たとえば、以下の改行区切りのJSONファイルをロードさせるとします。
{"name1": "value1", "name2": "value2"}
{"name1": "value3", "name2": "value4"}
このファイルをこのブロックで処理すると、「
"content": [
{
"name1": "value1",
"name2": "value2"
},
{
"name1": "value3",
"name2": "value4"
}
]
|
| バイナリ(Base64) |
ファイル内容をBase64でエンコードしたデータを「 たとえば、以下のように設定します。 "content": "ZkxhQwAA ... (中略) ... qqA55Q==" |
| CSV |
ファイル内容をCSV形式で解析し、オブジェクトの配列に変換して、「 CSV形式は、以下のようなフィールド名を持つヘッダー行があることを前提としています。フィールド名を持つヘッダー行とは、他の行と同じ個数のフィールドを持ち、フィールドの名称が列挙されている行のことです。 field_name_1,field_name_2,field_name_3 aaa,bbb,ccc xxx,yyy,zzz この形式のCSVを読み込むと、以下のようなオブジェクトの配列を「
"content": [
{
"field_name_1": "aaa",
"field_name_2": "bbb",
"field_name_3": "ccc"
},
{
"field_name_1": "xxx",
"field_name_2": "yyy",
"field_name_3": "zzz"
}
]
|
プロパティ
| プロパティ名 | 説明 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| ブロック名 |
編集パネルに配置した当該ブロックの表示名が変更できます。 ブロックリストパネル中のブロック名は変更されません。 |
||||||||
| GCPサービスアカウント | このブロックで使用するGCPサービスアカウントを選択します。 | ||||||||
| 読込データのファイルGCS URL |
変数へ読み込むファイルのGCS URLを指定します。例えば、 |
||||||||
| ファイル形式 | GCSから読み取るファイルのファイル形式を(none)/YAML/JSON/改行区切りのJSON/バイナリ(Base64)/CSVから選択します。 |
||||||||
| ブロックメモ | このブロックに関するメモが記載できます。このブロックの処理に影響しません。 | ||||||||
| CSVの区切り文字 |
「 「 |
||||||||
| 読み飛ばし行数 |
「 |
||||||||
| クオート記号を指定 |
「 |
||||||||
| 結果を格納する変数 |
GCS上のファイル内容を設定する変数を指定します。変数に設定されるデータの形式は、以下のとおりです。
{
"gcs_url": "...",
"timestamp": ...,
"content": ...
}
|
使用例
この使用例では、GCS上のCSVファイルを読み込み、その内容を変数に格納し、さらにその変数を使ってGoogleスプレッドシートを更新するフローを紹介します。このフローにより、GCSからGoogleスプレッドシートまでのデータ処理を完全に自動化でき、「結果を格納する変数」プロパティの重要性と活用方法を理解できます。
補足
この使用例で示すブロックの設定値は、理解を助けるためのサンプルです。実際の利用に際しては、ご自身の環境やニーズに合わせて適切に変更してください。また、各ブロックの説明では、変更が必要な主要な設定項目のみを記載しています。デフォルト値のままで問題ない項目や、特に言及のない設定項目は省略しています。フローを構築する際は、各ブロックの全ての設定項目を確認し、必要に応じて調整することをお勧めします。
フローの概要は以下の通りです。
- GCSの特定バケットに新しいCSVファイルが配置されたらフローを自動的に開始
- GCS上のファイルの内容を変数に読み込む
- 読み込んだデータをGoogleスプレッドシートの「RawData」シートに反映
- 処理完了をSlackで通知
このフローの実装例は、以下のとおりです。
- 「フローの開始」ブロックで、GCSに新しいCSVファイルが配置されたときにフローが実行されるよう設定します。

プロパティ名 値 ID load-var-from-gcs-flowブロック名 GCSから変数へロードの使用例GCSへのファイル配置をトリガーとするように設定します。
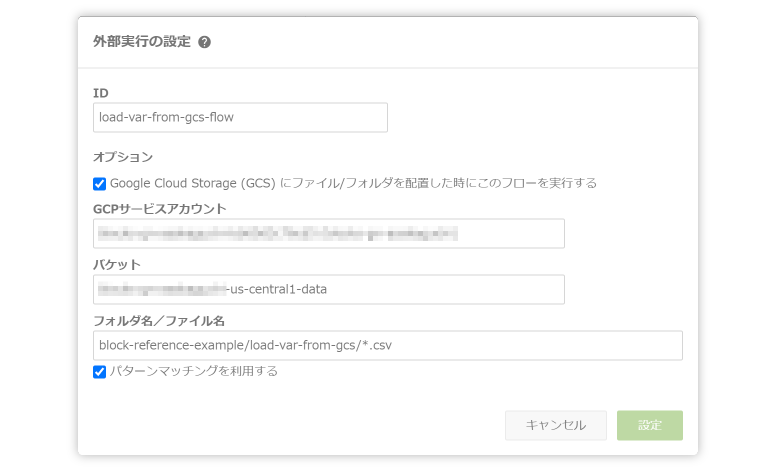
プロパティ名 値 Google Cloud Storage(GCS)上にファイル/フォルダを配置したときにフローを実行する バケット アップロード先のGCSバケットを設定 フォルダ名/ファイル名 block-reference-example/load-var-from-gcs/*.csv - 「GCSから変数へロード」ブロックで、GCS上のファイルの内容を変数に読み込みます。
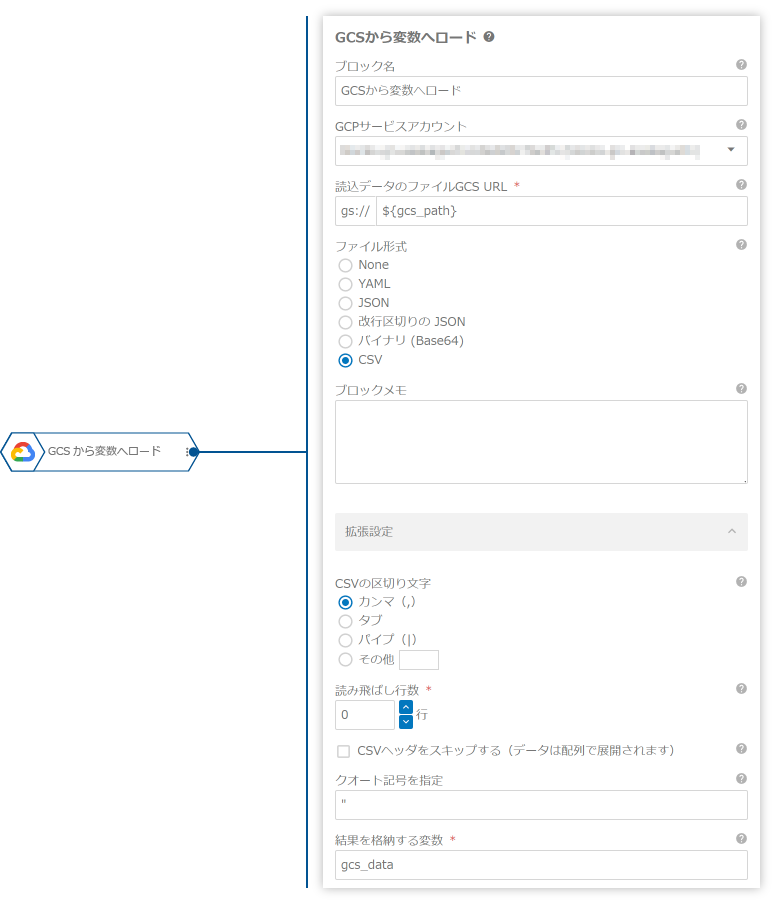
プロパティ名 値 読込データのファイルGCS URL ${gcs_path}ファイル形式 CSV結果を格納する変数 gcs_dataこのブロックでは、「結果を格納する変数」プロパティに
gcs_dataを指定しています。これにより、GCS上のCSVファイルの内容がgcs_data変数に格納されます。この変数は、次のブロックでスプレッドシートを更新する際に使用されます。 - 「スプレッドシートを更新」ブロックで、読み込んだデータをGoogleスプレッドシートの「
RawData」シートに反映します。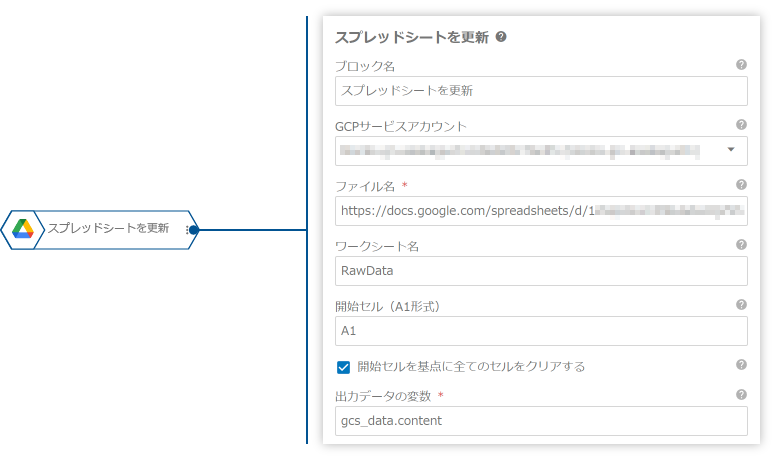
プロパティ名 値 ファイル名 https://docs.google.com/spreadsheets/d/1ABC...XYZ/edit?usp=sharingワークシート名 RawData開始セル(A1形式) A1開始セルを基点に全てのセルをクリアする 出力データの変数 gcs_data.contentここで、「出力データの変数」プロパティに
gcs_data.contentを指定していることに注目してください。これは、前のブロックでgcs_data変数に格納されたデータの中から、実際のファイル内容を参照しています。「GCSから変数へロード」ブロックは、ファイルの内容以外にもGCS URLやタイムスタンプなどの情報も変数に格納するため、ファイル内容だけを取り出すために.contentを使用しています。 - 「Slack通知」ブロックで、処理完了を通知します。

プロパティ名 値 Webhook URL https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX通知メッセージ 新しいデータの処理が完了しました。スプレッドシートが更新されています。ここでは、通知メッセージに
gcs_data変数から GCS URL とタイムスタンプも含めています。これにより、処理されたファイルの詳細情報も確認できます。
完成したフローは以下のとおりです。
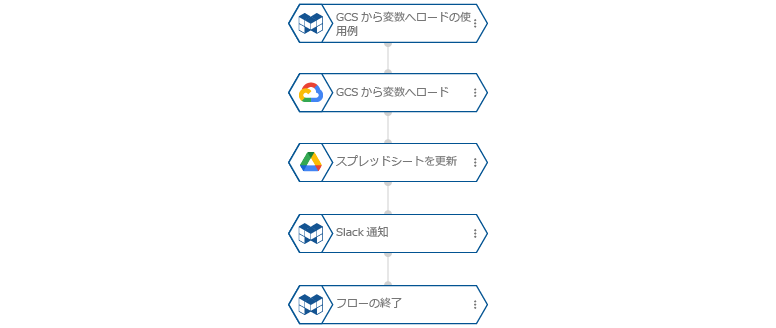
この使用例では、「GCSから変数へロード」ブロックの「結果を格納する変数」プロパティの重要性と活用方法を示しました。この変数を介して、GCS上のデータをGoogleスプレッドシートに反映し、さらにSlack通知にも利用することで、データの流れを効率的に管理できます。変数の扱い方を理解することで、より柔軟で強力なフローを構築することが可能になります。
Googleスプレッドシートの事前設定は以下のとおりです。
- 「RawData」シート:
- シートの作成のみ。事前設定不要。
- このシートは「GCSから変数へロード」ブロックで読み込んだCSVデータをそのまま格納するために使用。
- 「集計データ」シート:
- A1セル:
=ARRAYFORMULA(RawData!A1:D1)を入力してヘッダーを参照。 - A2セル:
=ARRAYFORMULA(IF(RawData!A2:A="","",DATEVALUE(RawData!A2:A))) - B2セル:
=ARRAYFORMULA(IF(RawData!B2:B="","",RawData!B2:B)) - C2セル:
=ARRAYFORMULA(IF(RawData!C2:C="","",VALUE(RawData!C2:C))) - D2セル:
=ARRAYFORMULA(IF(RawData!D2:D="","",VALUE(RawData!D2:D))) - この設定は、「GCSから変数へロード」ブロックがCSVファイルの各フィールドを文字列として扱うことへの対策。数値や日付を適切なデータ型に変換し、分析や可視化に適したフォーマットに整えるためのもの。
- A1セル:
- 「ダッシュボード」シート:
- 集計データシートのデータを使用したピボットテーブルやグラフの作成。
この設定の重要性は以下のとおりです。
- 「RawData」シート:元データの保持と参照性の確保。データ整合性の維持と過去データの追跡を実現。
- 「集計データ」シート:RawDataの文字列データの適切なデータ型への変換。正確な計算、ソート、フィルタリングによるデータ分析精度の向上。
- 「ダッシュボード」シート:変換データを用いた視覚化。意思決定者による正確かつ即時的なデータ把握の実現。
この3層構造(Raw Data→集計データ→ダッシュボード)により、データの整合性を保ちながら、効果的な分析と可視化を実現しています。また、この構造はデータの更新や修正が必要な場合にも柔軟に対応できる利点があります。
以下は、このフローによって生成されるダッシュボードの例です。
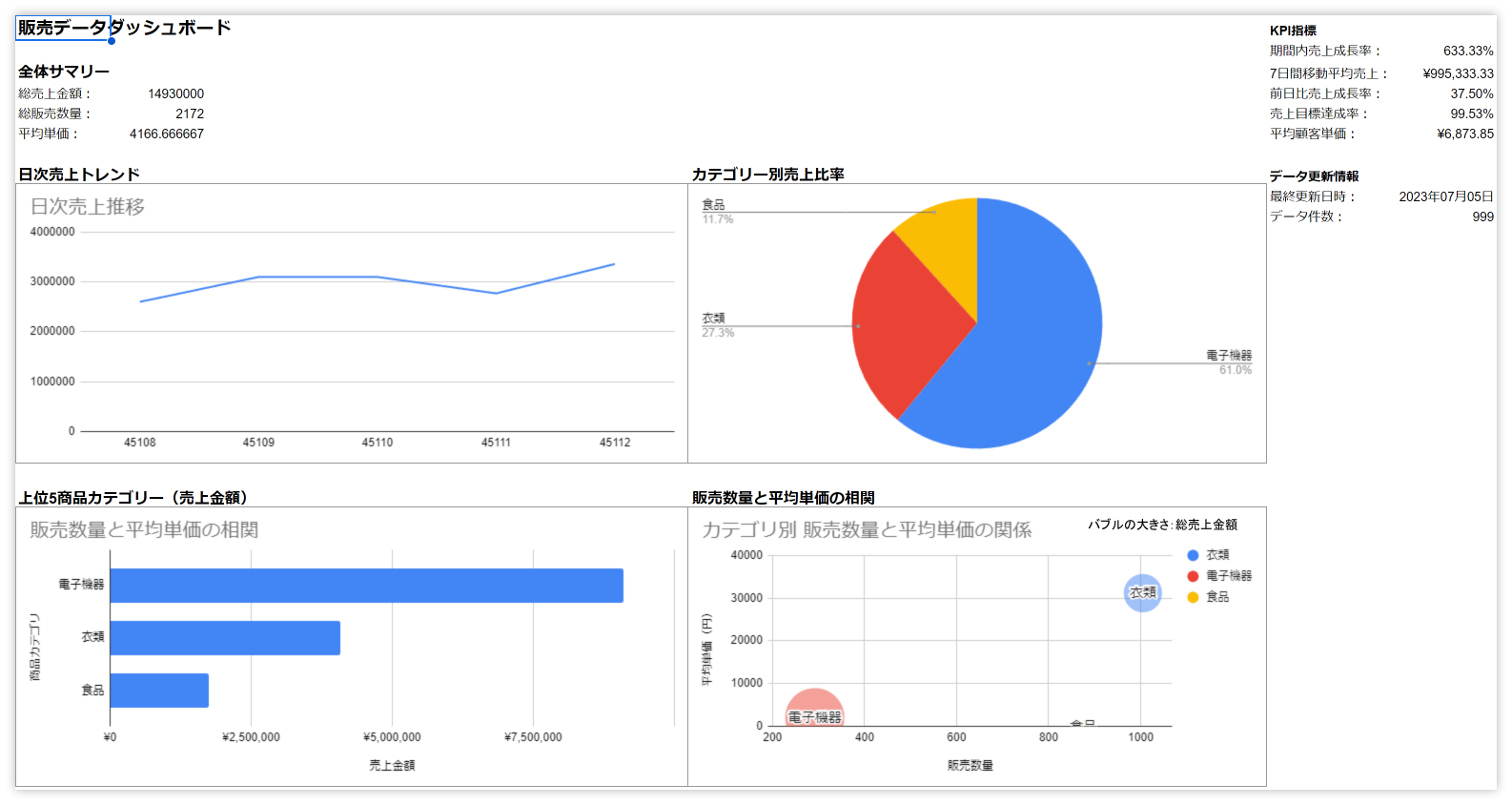
このダッシュボードは、日次売上トレンド、カテゴリー別売上比率、商品カテゴリーごとの売上金額、販売数量と平均単価の相関など、重要な販売データを視覚化しています。これにより、ビジネスの意思決定者は迅速にデータを解釈し、戦略的な判断を下すことができます。
この設定により、GCS、Googleスプレッドシートを効果的に連携させ、データの取り込みから処理、可視化までの一連のプロセスを自動化できます。ユーザーはデータの分析や意思決定に集中でき、データ処理の効率が大幅に向上します。「GCSから変数へロード」ブロックは、このプロセスの重要な始点となり、GCS上のデータを適切に変数に格納することで、後続の処理をスムーズに行えます。