BigQuery
カラム値毎のテーブル分割
概要
このブロックは、BigQuery テーブルの指定したカラム値の種類ごとにテーブルを分割します。
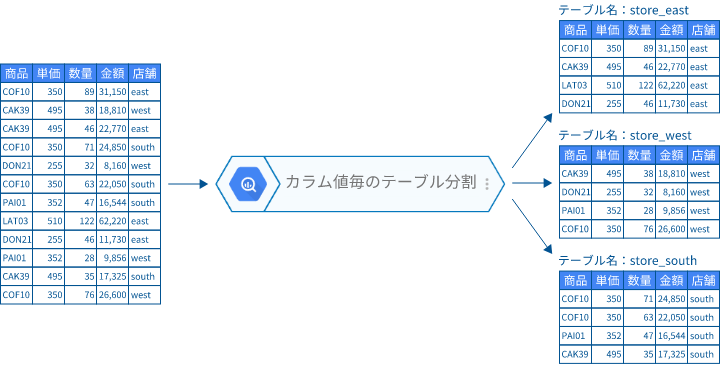
分割後のテーブル名は、「指定されたプリフィックス_分割のために指定したカラム値」という形式になります。上図は、プリフィックスに「store」が指定された例です。
留意事項
- 分割のために指定したカラム値の種類が 999 を超えると(1000 種類以上で)エラー
- 分割後、既存のテーブルがあれば上書き
プロパティ
| プロパティ名 | 説明 |
|---|---|
| ブロック名 | ブロックの名前を指定します。ブロックに表示されます。 |
| GCP サービスアカウント | このブロックで使用する GCP サービスアカウントを選択します。 |
| 分割元のデータセット |
分割元のデータセット ID を指定します。
[変数展開の指定が可能][% 形式の文字列書式の指定が可能]
|
| 分割元のテーブル |
分割元のテーブル ID を指定します。
[変数展開の指定が可能][% 形式の文字列書式の指定が可能]
|
| 分割基準のカラム名 | 分割の基準となる STRING 型のカラム名を指定します。 |
| 分割したテーブルのデータセット |
分割したテーブルの書き込み先データセット ID を指定します。
[変数展開の指定が可能][% 形式の文字列書式の指定が可能]
|
| 分割したテーブルのテーブル名 |
分割したテーブルのテーブル名のプリフィックスを指定します。 「分割基準のカラム名」の値を付加して最終的なテーブル名が決定します。テーブル名が重複する場合は、通し番号が付加されます。 「分割基準のカラム名」の値をテーブル名に利用する際は、以下の文字を削除します。
info_outline 「分割基準のカラム名」の値には、上記削除される文字を含まない値であることが望ましいです。すべて上記文字で構成されている場合、store_0・store_1 などのようにプリフィックスと通し番号のみとなってしまいます。
[変数展開の指定が可能][% 形式の文字列書式の指定が可能]
|
| クエリーの優先度 |
クエリの優先度を選択します。選択できる優先度は、次のいずれかです。
|
| ブロックメモ | ブロックに対するコメントを指定します。 |