文書(限定公開)
文書のクラスタリング(DBSCAN)
notificationsこのカテゴリーのブロックは限定公開です。利用にあたってはライセンス購入申請が必要です。このカテゴリーのブロックを使用したい場合は、MAGELLAN BLOCKSのお問い合わせ機能からライセンス購入申請をお願いします。
概要
このブロックは、DBSCAN方式で文書をクラスタリングします。ここで言う文書とは、[文書のベクトル化(TF-IDF)]ブロックや[文書のベクトル化(doc2vec)]ブロックで、ベクトル化された値を指します。
対応する言語は、日本語と英語のみです。
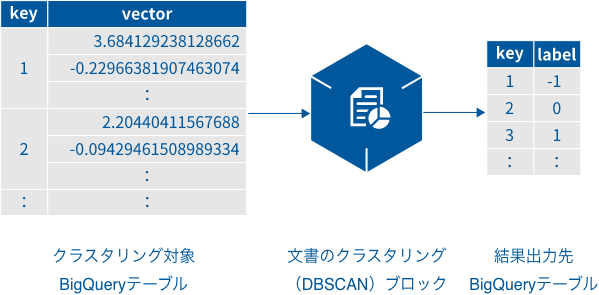
- 「クラスタリング対象BigQueryテーブル」には、文書を特定するキーを持つ列と文書のベクトル値を持つ列が必要です。
-
「結果出力先BigQueryテーブル」は、key列とlabel列で構成されます。
- key列:各文書へのキーです。
- label列:keyが示す文書のクラスタリング結果のラベルです。ラベル値の意味は、以下の通りです。
- -1:ノイズ(外れ値、どのクラスタにも属さない)
- 0〜:クラスタごとの番号
セルフサービスプランの場合は、このブロックを使用する前に、Dataflow APIを有効にしてください。詳しくは、「基本操作ガイド>ヒント> Google APIを有効にする」を参照してください。
プロパティ
| プロパティ名 | 説明 |
|---|---|
| ブロック名 | ブロックの名前を指定します。ブロックに表示されます。 |
| GCPサービスアカウント | このブロックで使用するGCPサービスアカウントを選択します。 |
| クラスタリング対象BigQueryデータセット |
[クラスタリング対象BigQueryテーブル]プロパティで指定するBigQueryテーブルが属するBigQueryデータセットのIDを指定します。 warning「クラスタリング対象BigQueryデータセット」・「結果出力先BigQueryデータセット」・「一時フォルダーGCS URL」のロケーションは合わせる必要があります。BigQueryのデータセットがUSマルチリージョンの場合は、この限りではありません。 |
| クラスタリング対象BigQueryテーブル |
クラスタリングしたい文書(ベクトルデータ)が格納されているBigQueryテーブルのIDを指定します。 |
| 結果出力先BigQueryデータセット |
[結果出力先BigQueryテーブル]プロパティで指定するBigQueryテーブルが属するBigQueryデータセットのIDを指定します。 warning「クラスタリング対象BigQueryデータセット」・「結果出力先BigQueryデータセット」・「一時フォルダーGCS URL」のロケーションは合わせる必要があります。BigQueryのデータセットがUSマルチリージョンの場合は、この限りではありません。 |
| 結果出力先BigQueryテーブル |
文書のクラスタリング結果のラベルを出力するBigQueryテーブルのIDを指定します。 空でないテーブルが存在する場合は、空にして上書きします。 |
| 一時フォルダーGCS URL |
このブロックの内部処理で一時的に使用するGCS上のフォルダーを指定します。 内部処理中に、このフォルダーに一時的なファイルが作成されますが、処理終了後は削除されます。 warning「クラスタリング対象BigQueryデータセット」・「結果出力先BigQueryデータセット」・「一時フォルダーGCS URL」のロケーションは合わせる必要があります。BigQueryのデータセットがUSマルチリージョンの場合は、この限りではありません。 |
| ブロックメモ | ブロックに対するコメントを指定します。 |
| キーの列名 |
[クラスタリング対象BigQueryテーブル]で各文書を一意に識別する値が格納された列名を指定します。 |
| ベクトルの列名 |
[クラスタリング対象BigQueryテーブル]で文書のベクトル値が格納された列名を指定します。 |
| 近傍探索半径ε |
近傍探索半径 ε を指定します。 DBSCANの特徴として、近傍半径 ε はクラスタリング結果に大きな影響を与える数値です。 一般的に、ε が非常に小さい値だと、データの大部分はクラスタリングされません(0.0や負の値は指定できません)。一方で大きな値だと、クラスタは併合され、データの多くが同一のクラスタに属することとなります。 このため、ε 値は小さな値が好ましいといえます。 具体的にどのような値にすべきかは、対象データの分布によるため、各データ間の相互距離(密度)がどのくらいなのかを分析する必要があります。 これは、Vector ViewerでEUCLIDEANでの近傍距離を調べることで、おおよその密度を知ることができます。ただし、文書のベクトル化(TF-IDF)ブロックでベクトル化したデータは参照できません。 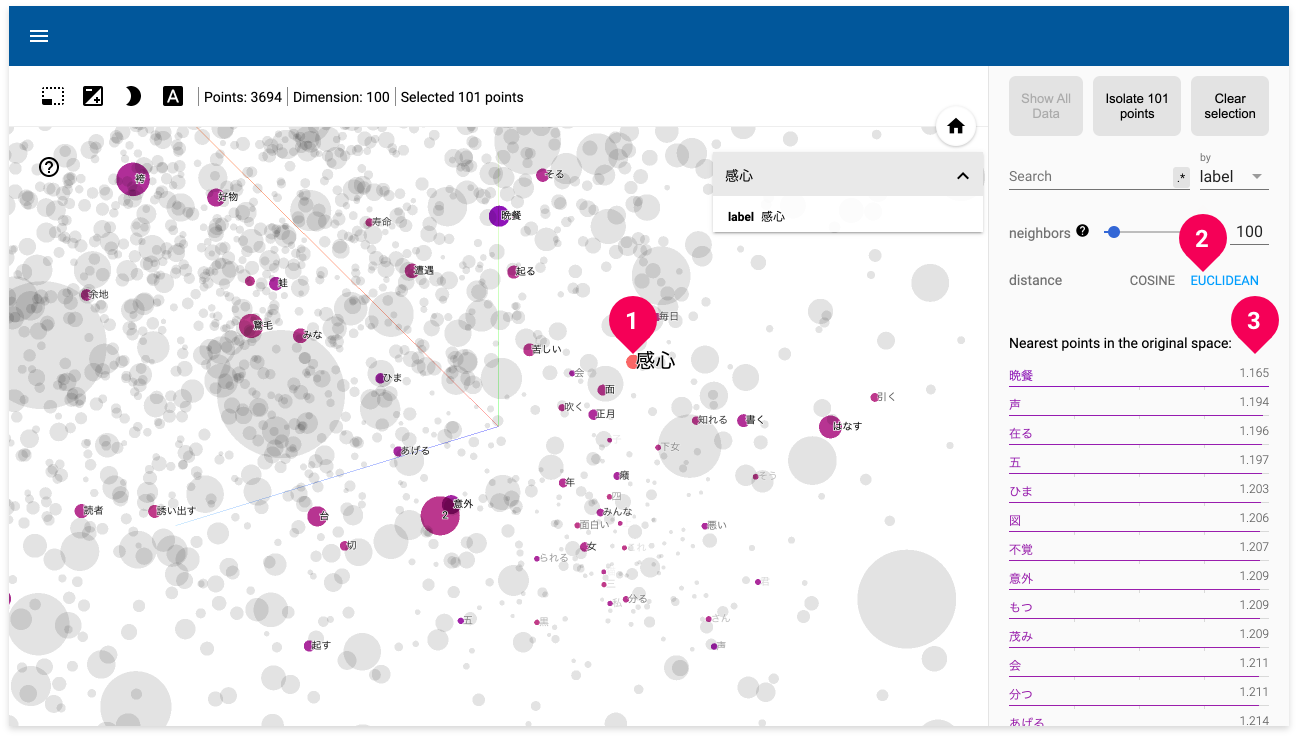
ここで得た値を参考に基準値を決め ε 値を設定し、適切なクラスタリング結果となるよう試行を繰り返して、値を調整していく必要があります。 |
関連情報
- DBSCANとはopen_in_new
- DBSCANについての簡単な説明:
DBSCANによるクラスタリングでは、ベクトル化された数値の集合から各クラスターのコアとなる点を探し、コアとなる点から一定の範囲にある点をまとめてひとつのクラスターを構成します。
例えば、以下のような集合があるとします。
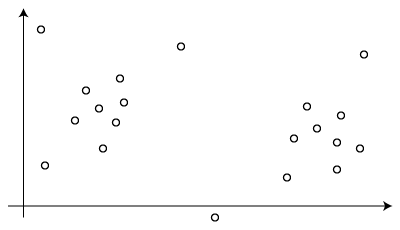
コアとなる点は、ある点から半径 ε 内にある点が、定めた数以上存在するときに成立します。下図は、定めた数を3とした場合のコアとなる点の例です。
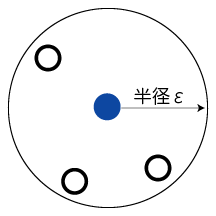
このコアとなる点から到達可能なすべての点をひとつにまとめて、クラスターと判断します。
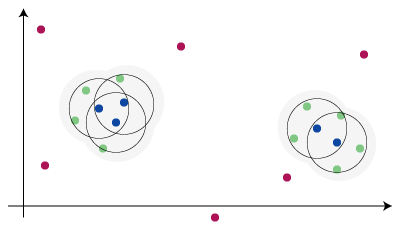
上図例ではクラスターが2つあり、青い点がクラスターのコアとなる点で緑色がクラスターに属する点、赤い点がクラスターに属さない「ノイズ」と呼ばれる点です。