文書(限定公開)
単語のベクトル化(word2vec)
このカテゴリーのブロックは限定公開です。利用にあたってはライセンス購入申請が必要です。このカテゴリーのブロックを使用したい場合は、MAGELLAN BLOCKSのお問い合わせ機能からライセンス購入申請をお願いします。
概要
このブロックは、文書内の単語をword2vec方式でベクトル化します。ここで言う文書とは、単語列に変換されたデータを指します。
対応する言語は、日本語と英語のみです。
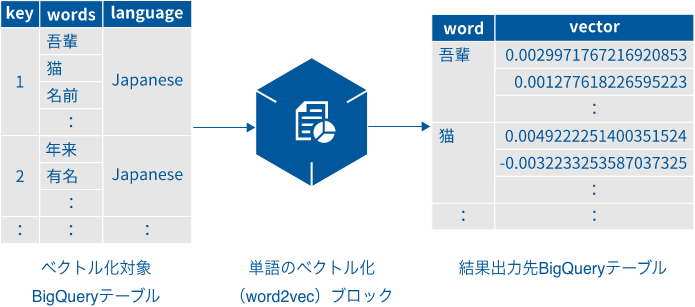
- 「ベクトル化対象BigQueryテーブル」には、文書を特定するキーを持つkey列と文書の単語列を持つwords列(STRING型のREPEATEDモード)が必要です。
備考
「Janomeで日本語を単語に分割」ブロックの出力が指定可能です。 -
「結果出力先BigQueryテーブル」は、word列とvector列(FLOAT型のREPEATEDモード)で構成されます。
- word列:単語
- vector列:単語のベクトル値
出力結果のベクトル値は、ログに出力されるURLをクリックすることで、下図のように視覚的な確認ができます(画面は別タブに表示されます)。
警告
出力結果のベクトル値を視覚的に確認する機能は、単語数が10,000以下でないと利用できません。
注記
セルフサービスプランの場合は、このブロックを使用する前に、Dataflow APIを有効にしてください。詳しくは、「基本操作ガイド>ヒント> Google APIを有効にする」を参照してください。
プロパティ
| プロパティ名 | 説明 |
|---|---|
| ブロック名 |
編集パネルに配置した当該ブロックの表示名が変更できます。 ブロックリストパネル中のブロック名は変更されません。 |
| GCPサービスアカウント | このブロックで使用するGCPサービスアカウントを選択します。 |
| ベクトル化対象BigQueryデータセット |
「ベクトル化対象BigQueryテーブル」プロパティで指定するBigQueryテーブルが属するBigQueryデータセットのIDを指定します。 警告 |
| ベクトル化対象BigQueryテーブル |
ベクトル化したい文書(単語列)が格納されているBigQueryテーブルのIDを指定します。 |
| 結果出力先BigQueryデータセット |
「結果出力先BigQueryテーブル」プロパティで指定するBigQueryテーブルが属するBigQueryデータセットのIDを指定します。 警告 |
| 結果出力先BigQueryテーブル |
単語ごとのベクトル値を出力するBigQueryテーブルのIDを指定します。 空でないテーブルが存在する場合は、空にして上書きします。 |
| 一時フォルダーGCS URL |
このブロックの内部処理で一時的に使用するGCS上のフォルダーへのGCS URL(gs://my-bucket/my-folder/のような形式、ただしgs://は入力不要)を指定します。 このGCS URLは、GCS Explorerのパスをコピー機能を使うと、簡単に取得できます。 内部処理中に、このフォルダーに一時的なファイルが作成されますが、処理終了後は削除されます。 警告 |
| ブロックメモ | このブロックに関するメモが記載できます。このブロックの処理に影響しません。 |