機械学習
AutoML(回帰)モデルの作成
概要
このブロックは、GoogleのAutoMLテーブルopen_in_newを使い、BigQueryopen_in_new上のトレーニングデータで回帰モデルを作成します。作成したモデルは、BigQueryとDataEditorに登録されます。
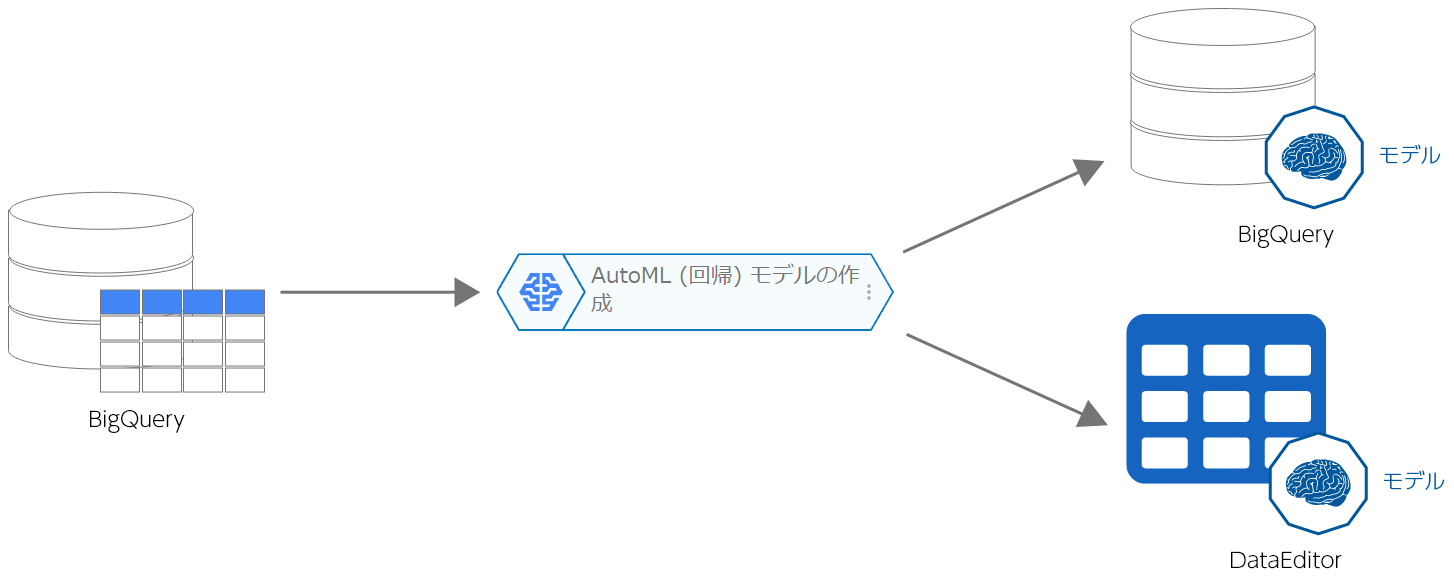
(図をクリックすると拡大表示されます。)
トレーニングデータは、以下の要件を満たす必要があります。
- 100 GB以下
- 推論/予測する値(カラム)が含まれている
- 列数は2から1,000列の範囲内
- 行数は1,000から200,000,000行の範囲内
1,000行では予測精度の高いモデルをトレーニングするには不十分な場合があります。回帰モデルでは、カラム数の少なくとも50倍の行数を準備する必要があります。
このブロックを利用することで、以下のようなユースケースに対応できます。
- 蓄積されていくデータを用いた再学習
- モデル作成の試行錯誤
プロパティ
| プロパティ名 | 説明 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ブロック名 |
編集パネルに配置した当該ブロックの表示名が変更できます。 ブロックリストパネル中のブロック名は変更されません。 |
||||||||||
| GCPサービスアカウント |
このブロックで使用するBigQueryテーブルにアクセス可能なGCPサービスアカウントを指定します。 |
||||||||||
| 入力BigQueryデータセット |
トレーニングデータを格納したBigQueryテーブルが属するBigQueryデータセットを指定します。 |
||||||||||
| 入力BigQueryテーブル |
トレーニングデータを格納したBigQueryテーブルを指定します。 |
||||||||||
| モデル名 |
DataEditorで参照する際の名前を指定します。 |
||||||||||
| トレーニング完了時に付加するタグ名 |
トレーニングが完了した際に、タグも同時に付けたい場合に指定します。 タグは、別途「推論/予測に使用するタグの設定」ブロックを使って、後付けできます。 |
||||||||||
| 推論/予測の対象に使用するカラム名 |
トレーニングデータの推論/予測の対象に使用するカラム名を指定します。 |
||||||||||
| ブロックメモ | このブロックに関するメモが記載できます。このブロックの処理に影響しません。 | ||||||||||
| トレーニング完了時からのモデル保持日数(0は制限なし) |
トレーニング完了時点からモデルを保持する日数を指定します。指定した日数を経過するとモデルは自動で削除されます。0日を指定すると、自動削除されません。 初期値は、0日です。 |
||||||||||
| データ分割に使用するカラム名(タイムスタンプまたは文字列のカラム) |
AutoMLテーブルでは、教師付きトレーニングデータをトレーニング用・検証用・テスト用に分割して利用します。 デフォルトでは、データ行の80%をトレーニング用、10%を検証用、10%をテスト用としてランダムに選択します。 分割比率やデータのどの行をトレーニング用・検証用・テスト用に適用するかをコントロールしたい場合は、特定のカラムを追加して行います。
info_outlineこのデータ分割の詳細については、Googleのドキュメントの「データ分割の用途open_in_new」を参照願います。 |
||||||||||
| トレーニングの最大時間(時間) |
モデルの最大トレーニング時間数を時間単位で指定します。 推奨されるトレーニング時間は、教師付きトレーニングデータのサイズに応じて変わります。以下に、行数別の推奨トレーニング時間を示します。
モデルの作成は、トレーニング以外の処理も含まれます。このため、モデル作成全体にかかる合計時間は、トレーニング時間より長くなります。 トレーニングの最大時間を満たす前にモデルの改善がみられなくなると、トレーニングは停止されます。 |
||||||||||
| トレーニングに使用する最適化目的関数 |
トレーニングに使用する最適化の目的関数を指定します。この関数は、モデルをどのようにトレーニングするかと、モデルを使った予測精度に影響します。 以下に、目的関数ごとに、どのような問題に適しているかを示します。
|
||||||||||
| Slack通知設定(省略可) |
モデル作成完了時に、Slackへその旨のテキストメッセージを送信したい場合に、プロジェクト設定の通知設定で設定したSlack通知の名称を指定します。 Slack通知のイメージ: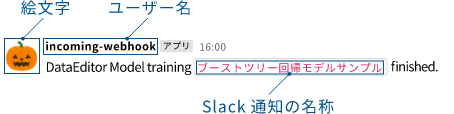
notificationsモデルの作成が完了したにも関わらずSlackに通知が来ない場合は、何らかの原因(指定したチャンネルがないなど)でSlackの通知に失敗している可能性があります。その場合は、プロジェクト設定の通知設定を確認してください。Slackの通知に失敗している場合は、失敗に関するメッセージが確認できます。 |
||||||||||
| Slack通知チャンネル設定(省略可) |
通知先のSlackチャンネルを指定します。 チャンネルを指定した場合は、プロジェクト設定の通知設定のチャンネルは無視されます。 省略した場合は、通知設定で指定されたチャンネルへ通知されます。 |
||||||||||
| Slack通知ユーザー名設定(省略可) |
通知する際のユーザー名を指定します。 ユーザー名を指定した場合は、プロジェクト設定の通知設定のユーザー名は無視されます。 省略した場合は、プロジェクト設定の通知設定で指定されたユーザー名が使われます。 |
||||||||||
| Slack通知アイコン絵文字設定(省略可) |
通知する際の絵文字を指定します。 絵文字を指定した場合は、プロジェクト設定の通知設定の絵文字は無視されます。 省略した場合は、プロジェクト設定の通知設定で指定された絵文字が使われます。 |