Google Drive
スプレッドシートのデータ取得
概要
このブロックは、Googleドライブのスプレッドシートの内容を変数に格納します。

変数に格納されるデータの形式は、「スプレッドシートを作成」ブロックで、スプレッドシートを作成するときに準備するデータの形式と同じです。詳しくは、「スプレッドシートを作成」ブロックを参照してください。
取得するセルの値はセルの表示形式にかかわらずすべて文字列となります。
既存のGoogleドライブ上のファイル(Google Driveカテゴリーのブロック以外で作成・保存したファイル)も対象とする場合は、GCPサービスアカウントのメールアドレスでそのファイルを共有しておく必要があります。GCPサービスアカウントのメールアドレスは、フローデザイナーの設定のGCPサービスアカウントで確認できます。
セルフサービスプランの場合は、このブロックを使用する前に、Google Sheets APIを有効にしてください。詳しくは、「基本操作ガイド>ヒント > Google APIを有効にする」を参照してください。
プロパティ
| プロパティ名 | 説明 |
|---|---|
| ブロック名 |
編集パネルに配置した当該ブロックの表示名が変更できます。 ブロックリストパネル中のブロック名は変更されません。 |
| GCPサービスアカウント | このブロックで使用するGCPサービスアカウントを選択します。 |
| ファイル名 |
データを取得するスプレッドシートのファイル名を指定します。 同名の複数のファイルが見つかった場合は、最初に見つけたファイルが対象となります。 ファイルへのURLも指定可能です。URLは、共有リンクおよびファイルのURL(ウェブブラウザーのアドレス欄に表示)のどちらも指定可能です。
[変数展開の指定が可能]
|
| 結果を格納する変数 | スプレッドシートの内容を格納する変数を指定します。 |
| ブロックメモ | このブロックに関するメモが記載できます。このブロックの処理に影響しません。 |
| 親フォルダ名 | データを取得するスプレッドシートが存在するフォルダーを特定したいときに指定します。同名のスプレッドシートが複数のフォルダーに存在するときに使用します。 |
| ワークシート名 |
データを取得するスプレッドシートのシート名を指定します。空欄の場合は、先頭のシートがデータを取得する対象のシートになります。 |
| 開始セル(A1形式) |
データを読み出すセルの位置をA1表記法で指定します。空欄の場合は、A1となります。 以下のような範囲指定も可能です。この場合は、指定した範囲のデータを読み出します。
|
| ヘッダをスキップする(データは配列で展開されます) |
ヘッダーを読み取りたくないときに指定します。 このプロパティにチェックを付けると、変数にはオブジェクトの配列ではなく、配列の配列(2次元配列)でデータが格納されます。 |
使用例
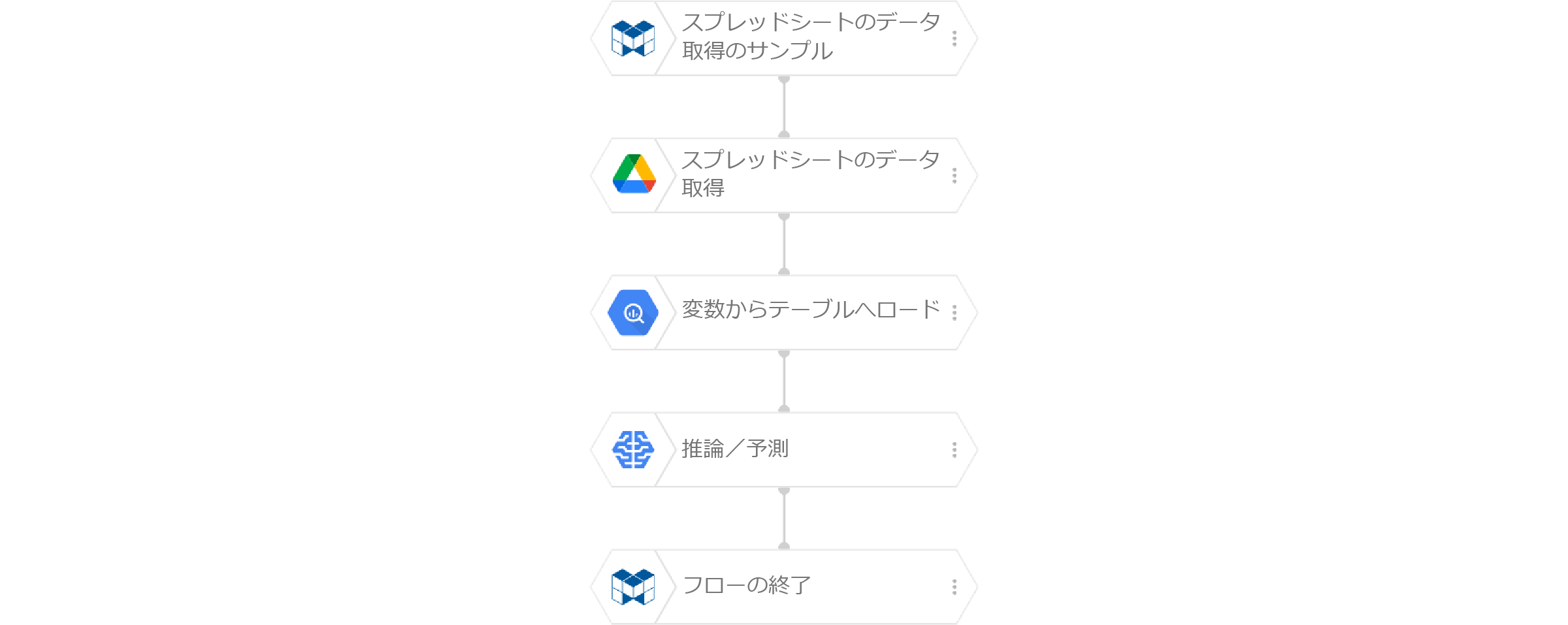
ここでは、Googleスプレッドシートのデータを使って、あやめの分類を行う例を紹介します。なお、ここではDataEditorのモデル作成機能を使って、あやめの分類用モデルが作成済みであることを前提としています。
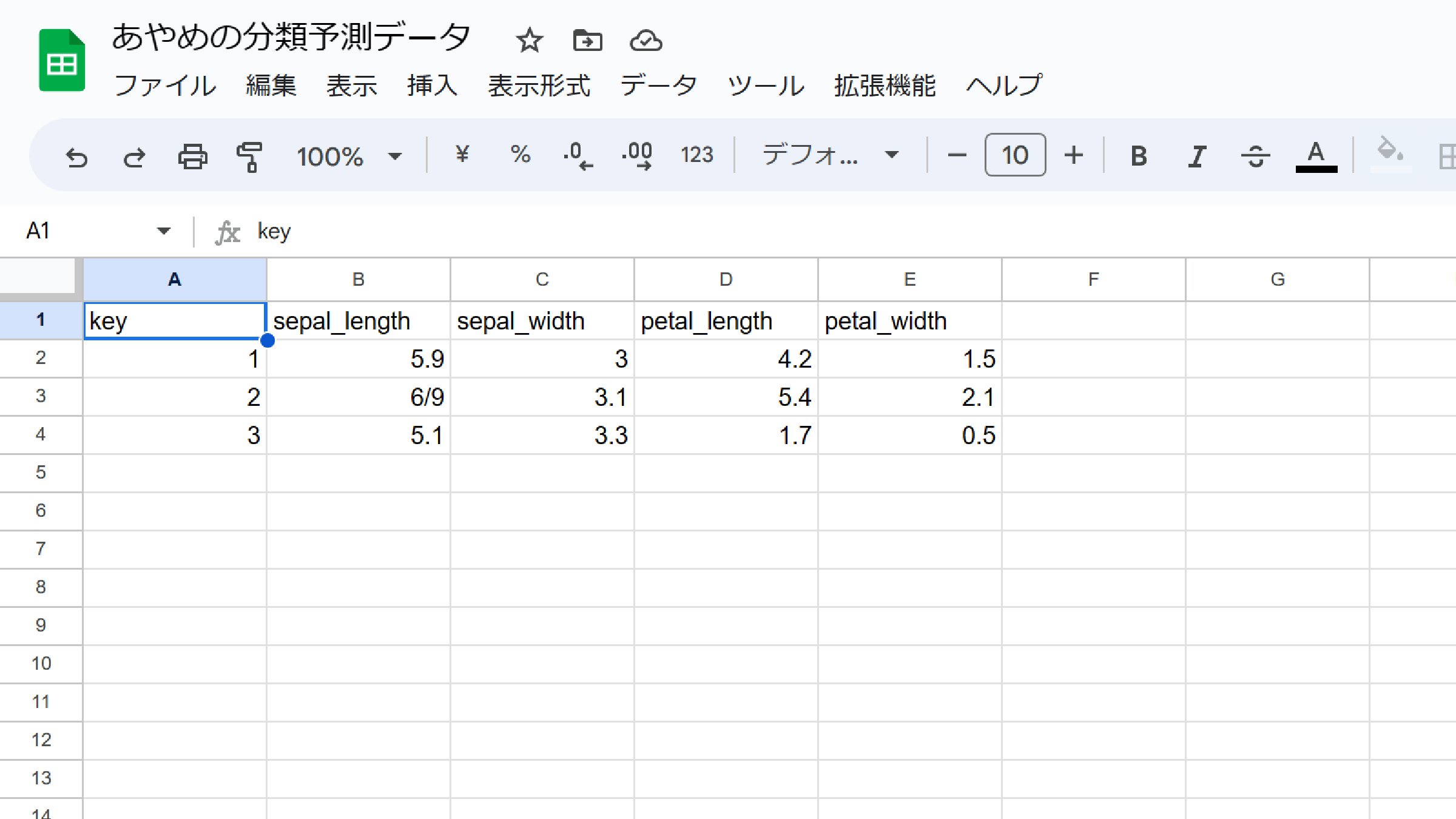
まず、Googleスプレッドシートに、推論/予測用のデータを準備します。
続いて、「スプレッドシートのデータ取得」ブロックを配置し、以下のように設定します。
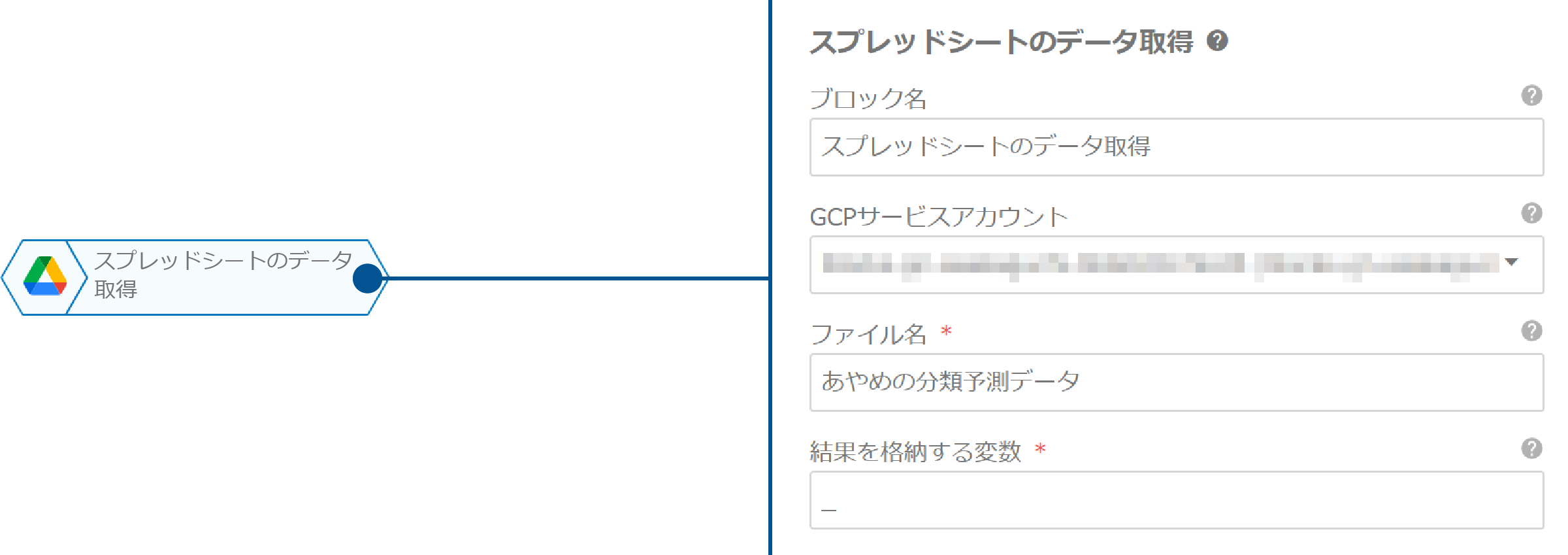
| プロパティ | 値 | 説明 |
|---|---|---|
| ファイル名 | あやめの分類予測データ |
Googleスプレッドシートのファイル名 |
| 結果を格納する変数 | _ |
初期値のまま |
次に、「変数からテーブルへロード」ブロックを配置し、以下のように設定します。これで、変数の内容をBigQueryテーブルへ登録します。
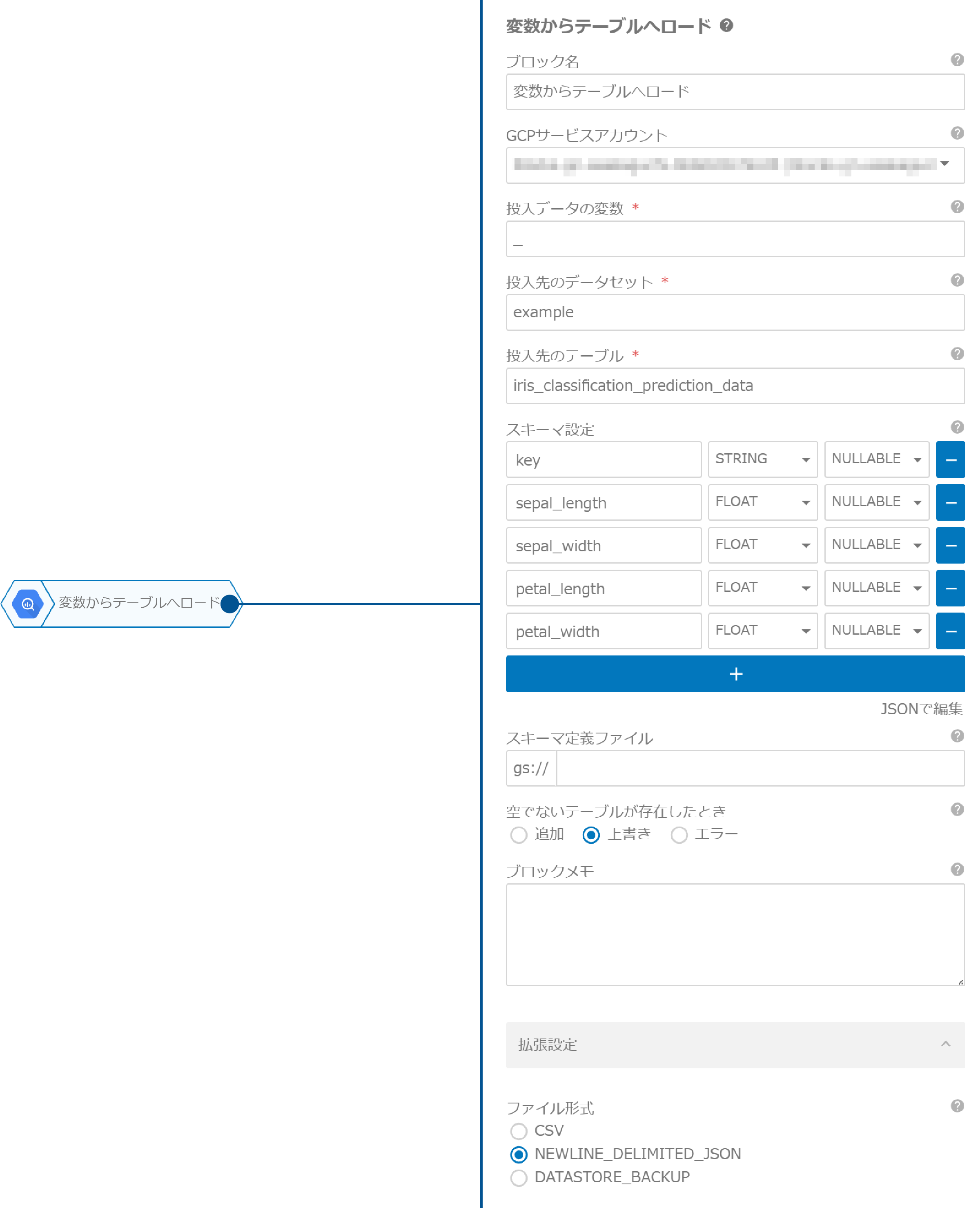
| プロパティ | 値 | 説明 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 投入データの変数 | _ |
「スプレッドシートのデータ取得」ブロックの「結果を格納する変数」の値と合わせます。 | ||||||||||||||||||
| 投入先のデータセット | example |
|||||||||||||||||||
| 投入先のテーブル | iris_classification_prediction_data |
|||||||||||||||||||
| スキーマ設定 |
|
JSONで編集する場合は、以下を貼り付けてください。
[
{
"name": "key",
"type": "STRING",
"mode": "NULLABLE",
"description": ""
},
{
"name": "sepal_length",
"type": "FLOAT",
"mode": "NULLABLE",
"description": ""
},
{
"name": "sepal_width",
"type": "FLOAT",
"mode": "NULLABLE",
"description": ""
},
{
"name": "petal_length",
"type": "FLOAT",
"mode": "NULLABLE",
"description": ""
},
{
"name": "petal_width",
"type": "FLOAT",
"mode": "NULLABLE",
"description": ""
}
]
|
||||||||||||||||||
| ファイル形式 | NEWLINE_DELIMITED_JSON |
「スプレッドシートのデータ取得」ブロックの出力結果を扱う場合は、NEWLINE_DELIMITED_JSON選択します。 |
最後に、「推論/予測」ブロックを配置し、以下のように設定します。
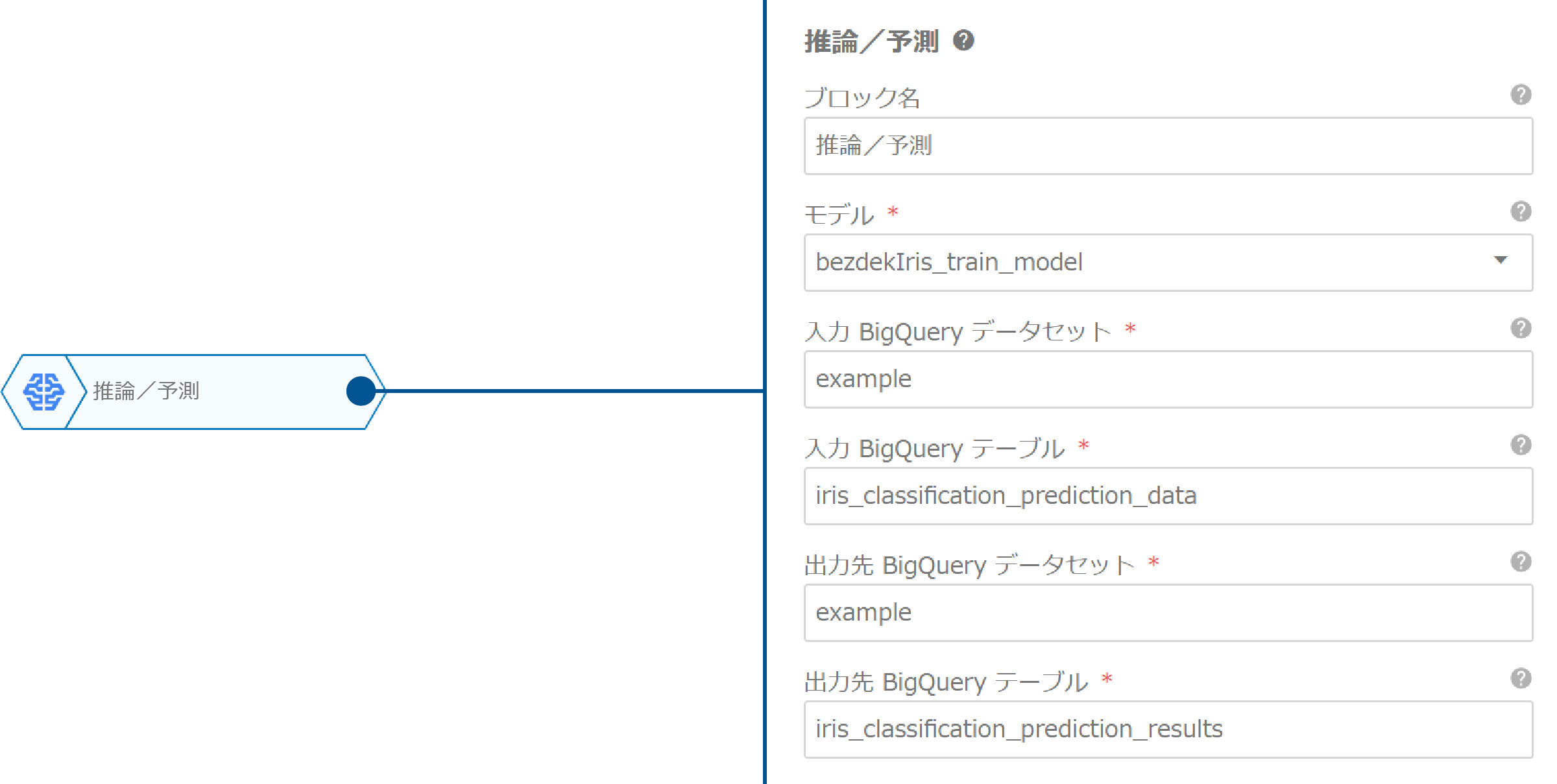
| プロパティ | 値 | 説明 |
|---|---|---|
| モデル | bezdekIris_train_model |
予測データに則したトレーニング済みのモデルを選択します。 |
| 入力BigQueryデータセット | example |
「変数からテーブルへロード」ブロックで指定したデータセットに合わせます。 |
| 入力BigQueryテーブル | iris_classification_prediction_data |
「変数からテーブルへロード」ブロックで指定したテーブルに合わせます。 |
| 出力先BigQueryデータセット | example |
推論/予測結果を格納するBigQueryデータセットを指定します。 |
| 出力先BigQueryテーブル | example |
推論/予測結果を格納するBigQueryテーブルを指定します。 |
以上でフローの完成です。
このフローを実行すると、Googleスプレッドシートのデータを使って、推論/予測ができます。