最適化
割当て最適化(分量固定タイプ)【ベータ版】
このブロックはベータ版です。機能改善や不具合などの情報提供は、MAGELLAN BLOCKSのお問い合わせ機能からお願いします。
概要
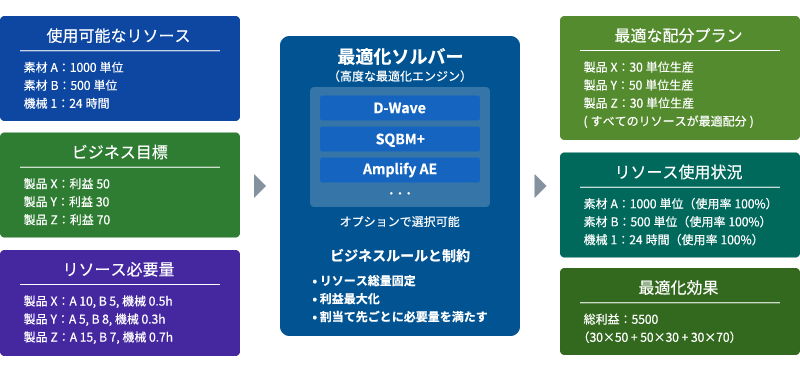
このブロックは、限られた資源(リソース)を最も効率的に配分するための計画を自動で作成します。これにより、コスト削減や生産性の向上が期待できます。例えば、生産ラインにおける原材料の配分、プロジェクトへの人員配置、配送車両への荷物の割り当てなど、様々なビジネスシーンで活用できます。
「分量固定タイプ」では、あらかじめ設定したリソースの総量(在庫数、機械の稼働可能な時間など)と、各配分先で必要となる量に基づいて、最も効率的な配分パターンを自動的に計算します。これにより、人手では対応が難しい複雑な条件のもとでも、最適な配分計画が立てられます。
内部では、状況に応じて最適な計算エンジン(専門的にはソルバーと呼ばれ、D-Wave、SQBM+、Amplify AEなどが該当)が自動的に選択され、量子コンピューティング技術(量子アニーリングなど)をはじめとする先進技術を用いて高速に計算処理を行います。利用者は技術的な詳細を意識することなく、最適な配分結果のみが簡単に得られます。
プロパティ
| プロパティ名 | 説明 |
|---|---|
| ブロック名 |
フローの中で、このブロックを識別するための表示名を設定します。例えば、「 |
| GCPサービスアカウント |
最適化処理を実行するために、Google Cloud Platform(GCP)のサービスアカウントを選択します。処理に必要な権限を持つアカウントを設定してください。 |
| データセット |
BigQueryのデータセットを指定します。(必須) このデータセットには、最適化計算に使用する入力データテーブルと、計算結果を保存する出力データテーブルが含まれます。 具体的には、リソース情報や配分先の情報などが格納されたテーブルをこのデータセット内に準備する必要があります。 |
| リソースが保存されているテーブル |
リソースに関する情報(種類、総量など)が格納されたテーブル名を指定します。(必須) このテーブルには、「 |
| 割当て先が保存されているテーブル |
リソースの配分先に関する情報(配分先名、利益など)が格納されたテーブル名を指定します。(必須) このテーブルには、「 |
| 割当て先へのリソースが保存されているテーブル |
各配分先で必要となるリソースの量を定義した情報が格納されたテーブル名を指定します。(必須) このテーブルには、「 |
| パラメータが保存されているテーブル |
最適化計算の挙動や優先順位を調整するためのパラメータが格納されたテーブル名を指定します。(必須) このテーブルには、「 |
| 最適化実行に関する情報を格納する変数 |
最適化処理を実行した際のジョブID(処理識別子)などを格納する変数名を指定します。(必須) この変数には、実行結果に関する基本的な情報(ジョブIDなど)が格納され、後続の処理ブロックで参照できます。具体的には、以下のような構造のJSONオブジェクトが格納されます。 主なキーの説明は以下の通りです。
|
| 実行に関する情報を格納するテーブル |
最適化計算の実行に関する詳細な情報(メタデータ)を格納するテーブル名を指定します。 指定しない場合、これらのメタデータは保存されません。実行にかかった時間や計算の評価値(エネルギー値)など、処理の詳細情報を記録・分析したい場合に設定します。事前に作成する必要はなく、指定したテーブルがなければ、自動作成されます。既に存在する場合は、追加されます。 |
| 実行結果を格納するテーブル |
最適化計算の結果(具体的な配分計画)を格納するテーブル名を指定します。 指定しない場合、計算結果は保存されません。最適化結果を保存し、他の処理ブロックから参照したり、後で分析したりする場合は必ず設定してください。事前に作成する必要はなく、指定したテーブルがなければ、自動作成されます。既に存在する場合は、追加されます。 |
| ジョブのラベル名 |
実行する最適化ジョブに付与するラベル名(識別名)を指定します。 複数の最適化処理を区別するために使用します。特に、複数のジョブを同時に実行する場合や、後で特定のジョブの結果を確認する際に役立ちます。 |
| ブロックメモ |
このブロックに関するメモを自由に記述できます。 フローの管理やメンテナンス時の情報共有に役立ちます。このメモの内容は、ブロックの実行には影響しません。 |
テーブルスキーマ
このブロックでは、4つの入力情報(テーブル形式)と、結果を格納する出力情報(テーブル形式)を使用します。それぞれのテーブルがどのような構造を持ち、どのようなデータを含める必要があるかを理解しておくことが重要です。
注:「必須」列の「✓」マークは、その項目が必須であることを示します。「*」付きのものは条件付き必須を示します(詳細は各テーブルの説明を参照)。
1. リソースが保存されているテーブル
利用可能なリソースの基本情報と総量を定義するテーブルです。例えば、人員、原材料、機械の稼働時間などをリソースとして登録します。
JSONスキーマを表示
[
{ "name": "resource_id", "type": "STRING", "mode": "NULLABLE", "description": "" },
{ "name": "resource_name", "type": "STRING", "mode": "NULLABLE", "description": ""},
{ "name": "amount", "type": "INTEGER", "mode": "NULLABLE", "description": "" }
]
| カラム名 | データ型 | 必須/条件付き | 説明 |
|---|---|---|---|
| resource_id | 文字列(STRING) | ✓ | リソースを一意に識別するためのID(例:material_X、staff_A) |
| resource_name | 文字列(STRING) | リソースの表示名(例:「素材X」、「スタッフA」)。省略可能です。 |
|
| amount | 整数(INTEGER) | ✓ | リソースの総量(例:在庫数、総労働時間など) |
各リソースには必ず総量(amount)を指定します。この値が、配分可能なリソースの上限となります。例えば、作業者のシフトであれば総労働可能時間、材料であれば在庫数などを設定します。
2. 割当て先が保存されているテーブル
リソースを配分する対象(例:製品、プロジェクト、タスクなど)を定義するテーブルです。各配分先には、任意で利益や優先度を示す値(profit)を設定できます。
JSONスキーマを表示
[
{ "name": "target_id", "type": "STRING", "mode": "NULLABLE", "description": "" },
{ "name": "target_name", "type": "STRING", "mode": "NULLABLE", "description": "" },
{ "name": "profit", "type": "INTEGER", "mode": "NULLABLE", "description": "" }
]
| カラム名 | データ型 | 必須/条件付き | 説明 |
|---|---|---|---|
| target_id | 文字列(STRING) | ✓ | 配分先を一意に識別するためのID(例:product_A, project_X) |
| target_name | 文字列(STRING) | 配分先の表示名(例:「製品A」、「プロジェクトX」)。省略可能です。 |
|
| profit | 整数(INTEGER) | この配分先にリソースを配分した場合に得られる利益や価値の指標。省略可能です。 |
profit は、その配分先の優先度や価値を表す数値です。値が大きいほど、最適化計算において優先的にリソースが配分される傾向にあります。例えば、製品ごとの利益率やプロジェクトの重要度などを数値化して設定します。
3. 割当て先へのリソースが保存されているテーブル
どの配分先が、どのリソースを、どれだけ必要とするか(消費するか)を定義する関連情報テーブルです。
JSONスキーマを表示
[
{ "name": "target_id", "type": "STRING", "mode": "NULLABLE", "description": "" },
{ "name": "resource_id", "type": "STRING", "mode": "NULLABLE", "description": "" },
{ "name": "consume_amount", "type": "INTEGER", "mode": "NULLABLE", "description": "" }
]
| カラム名 | データ型 | 必須/条件付き | 説明 |
|---|---|---|---|
| target_id | 文字列(STRING) | ✓ | 配分先ID(上記「2. 割当て先が保存されているテーブル」の target_id と対応) |
| resource_id | 文字列(STRING) | ✓ | リソースID(上記「1. リソースが保存されているテーブル」の resource_id と対応) |
| consume_amount | 整数(INTEGER) | ✓ | その配分先で、指定したリソースを1単位生産(または実行)する際に必要となる量 |
このテーブルは、配分先とリソースの間の「多対多」の関係(1つの配分先が複数のリソースを必要とし、1つのリソースが複数の配分先で使用される関係)を表現します。consume_amountは、その配分先に対してリソースを1単位配分したときに消費される量です。例えば、製品Aを1つ作るのに素材Xが2個、作業時間Bが0.5時間必要、といった情報を定義します。
4. パラメータが保存されているテーブル
最適化計算の挙動をより細かく制御するためのパラメータを設定するテーブルです。
JSONスキーマを表示
[
{"name":"label","type":"STRING","mode":"NULLABLE"},
{ "name": "assign_all_resource", "type": "RECORD", "mode": "NULLABLE", "description": "", "fields": [
{ "name": "type", "type": "STRING", "mode": "NULLABLE" },
{ "name": "coeff", "type": "FLOAT", "mode": "NULLABLE" }
]
},
{ "name": "target_profit_coeff", "type": "FLOAT", "mode": "NULLABLE", "description": ""},
{"name":"solver_options","type":"RECORD","mode":"NULLABLE",
"fields":[
{ "name": "normalize", "type": "BOOLEAN", "mode": "NULLABLE" },
{ "name": "backend", "type": "STRING", "mode": "NULLABLE" },
{"name": "dwave", "type": "RECORD", "mode": "NULLABLE", "fields": [
{ "name": "params_type", "type": "STRING", "mode": "NULLABLE" },
{ "name": "params_version", "type": "STRING", "mode": "NULLABLE" },
{ "name": "params_time_limit", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "info_qubit_info", "type": "STRING", "mode": "NULLABLE" },
{ "name": "info_timing", "type": "STRING", "mode": "NULLABLE" },
{ "name": "info_debug_level", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "info_response", "type": "STRING", "mode": "NULLABLE" }
]},
{ "name": "sbm", "type": "RECORD", "mode": "NULLABLE", "fields": [
{ "name": "params_type", "type": "STRING", "mode": "NULLABLE" },
{ "name": "params_version", "type": "STRING", "mode": "NULLABLE" },
{ "name": "params_algo", "type": "STRING", "mode": "NULLABLE" },
{ "name": "params_steps", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "params_loops", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "params_timeout", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "params_maxwait", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "params_target", "type": "FLOAT", "mode": "NULLABLE" },
{ "name": "params_dt", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "params_C", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "info_qubit_info", "type": "STRING", "mode": "NULLABLE" },
{ "name": "info_response", "type": "STRING", "mode": "NULLABLE" }
]}
]
}
]
| カラム名 | データ型 | 必須/条件付き | 説明 |
|---|---|---|---|
| label | 文字列(STRING) | 複数の最適化処理を実行する際のジョブラベル(識別名)。省略可能です。 | |
| assign_all_resource | 複合型(RECORD) | 「すべてのリソースを可能な限り使い切る」という制約に関する設定。省略可能です。 | |
| assign_all_resource.type | 文字列(STRING) | ✓* | 制約のタイプ。現状は「strict(厳密)」のみ指定可能です。 |
| assign_all_resource.coeff | 数値(FLOAT) | ✓* | 上記制約の強さ(重み係数)。値が大きいほど、リソースを使い切ろうとする傾向が強まります。 |
| target_profit_coeff | 数値(FLOAT) | 利益(profit)を最大化しようとする度合い(重み係数)。値が大きいほど、利益の高い配分先を優先する傾向が強まります。省略可能です。 |
|
| solver_options | 複合型(RECORD) |
使用する計算エンジン(ソルバー)固有の詳細な設定。通常は設定不要です。省略可能です。
|
* assign_all_resource の設定項目(type, coeff)は、assign_all_resource自体を定義する場合に必須となります。
各パラメータの値は、一般的に以下のように設定します。
- 制約を使用しない場合: そのカラム自体をテーブルに含めない(
null扱い)。 - 自動パラメータ設定を利用する場合:
0を設定(一部パラメータ)。 - 特定の値を指定する場合:
0以外の数値を設定。
例えば、初めて利用する場合は、assign_all_resource.type = "strict"、assign_all_resource.coeff = 100(リソースをしっかり使う)、target_profit_coeff = 1.0(利益も考慮する)といった設定から試してみると良いでしょう。
5. 実行に関する情報を格納するテーブル
最適化処理の実行結果に関するメタデータを保存するテーブルです。処理のパフォーマンスや解の品質に関する詳細情報を記録します。
JSONスキーマを表示
[
{ "name": "job_id", "type": "STRING", "mode": "NULLABLE", "description": "" },
{ "name": "optimization_type", "type": "STRING", "mode": "NULLABLE", "description": "" },
{ "name": "solver_type", "type": "INTEGER", "mode": "NULLABLE", "description": "" },
{ "name": "solutions", "type": "RECORD", "mode": "REPEATED", "fields": [
{ "name": "solution_index", "type": "INTEGER", "mode": "NULLABLE", "description": "" },
{ "name": "energy", "type": "FLOAT", "mode": "NULLABLE", "description": "" }
], "description": "" },
{ "name": "total_qubit_num", "type": "INTEGER", "mode": "NULLABLE", "description": "" },
{ "name": "qubo", "type": "RECORD", "mode": "NULLABLE", "fields": [
{ "name": "maximum_coeff_ratio", "type": "FLOAT", "mode": "NULLABLE", "description": "" },
{ "name": "max", "type": "FLOAT", "mode": "NULLABLE", "description": "" },
{ "name": "min", "type": "FLOAT", "mode": "NULLABLE", "description": "" },
{ "name": "max_positive", "type": "FLOAT", "mode": "NULLABLE", "description": "" },
{ "name": "min_positive", "type": "FLOAT", "mode": "NULLABLE", "description": "" },
{ "name": "max_negative", "type": "FLOAT", "mode": "NULLABLE", "description": "" },
{ "name": "min_negative", "type": "FLOAT", "mode": "NULLABLE", "description": "" },
{ "name": "nonzero_num", "type": "INTEGER", "mode": "NULLABLE", "description": "" },
{ "name": "density", "type": "FLOAT", "mode": "NULLABLE", "description": "" }
], "description": "" },
{ "name": "problem", "type": "RECORD", "mode": "REPEATED", "fields":[
{ "name": "id", "type": "STRING", "mode": "NULLABLE" },
{ "name": "qpu_sampling_time", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "qpu_anneal_time_per_sample", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "qpu_readout_time_per_sample", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "qpu_access_time", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "qpu_access_overhead_time", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "qpu_programming_time", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "qpu_delay_time_per_sample", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "total_post_processing_time", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "post_processing_overhead_time", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "charge_time", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "run_time", "type": "INTEGER", "mode": "NULLABLE" }
], "description": "" },
{ "name": "solver_response", "type": "RECORD", "mode": "REPEATED", "fields":[
{ "name": "id", "type": "STRING", "mode": "NULLABLE" },
{ "name": "qpu_sampling_time", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "qpu_anneal_time_per_sample", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "qpu_readout_time_per_sample", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "qpu_access_time", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "qpu_access_overhead_time", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "qpu_programming_time", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "qpu_delay_time_per_sample", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "total_post_processing_time", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "post_processing_overhead_time", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "charge_time", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "run_time", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "calculation_time", "type": "FLOAT", "mode": "NULLABLE" },
{ "name": "wait_time", "type": "FLOAT", "mode": "NULLABLE" },
{ "name": "num_runs", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "message", "type": "STRING", "mode": "NULLABLE" }
], "description": "" },
{ "name": "constraints", "type": "RECORD", "mode": "REPEATED", "fields":[
{ "name": "solution_index", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "name", "type": "STRING", "mode": "NULLABLE" },
{ "name": "energy", "type": "FLOAT", "mode": "NULLABLE" },
{ "name": "coeff", "type": "STRING", "mode": "NULLABLE" }
], "description": "" },
{ "name": "created_at", "type": "TIMESTAMP", "mode": "NULLABLE", "description": "" }
]
| カラム名 | データ型 | 必須 | 説明 |
|---|---|---|---|
| job_id | 文字列(STRING) | ✓ | 最適化処理を実行した際のジョブID |
| optimization_type | 文字列(STRING) | ✓ | 実行された最適化のタイプ(この場合は"strict_allocation"など) |
| solutions | 複合型(RECORD)、 繰り返し(REPEATED) |
得られた解のリスト(複数の解とその評価値が含まれます) | |
| solutions.solution_index | 整数(INTEGER) | ✓ | 解のインデックス番号 |
| solutions.energy | 数値(FLOAT) | ✓ | 各解に対応する評価値(エネルギー値) |
| total_qubit_num | 整数(INTEGER) | 計算に使用された論理的な変数(qubit)の総数。問題の複雑さの目安となります。 | |
| qubo | 複合型(RECORD) | 最適化問題を数式で表現したQUBO(Quadratic Unconstrained Binary Optimization)モデルに関する情報。専門的な分析に用います。 | |
| qubo.maximum_coeff_ratio | 数値(FLOAT) | QUBOモデル内の係数の最大値と最小値の比率。解の精度に関わる指標です。 | |
| qubo.max | 数値(FLOAT) | QUBOモデル内の係数の最大値。 | |
| qubo.min | 数値(FLOAT) | QUBOモデル内の係数の最小値。 | |
| qubo.nonzero_num | 整数(INTEGER) | QUBOモデル内でゼロではない係数の数。 | |
| qubo.density | 数値(FLOAT) | QUBOモデル内でゼロではない係数の数の割合。 | |
| solver_type | 整数(INTEGER) | ✓ | 実際に計算に使用された計算エンジン(ソルバー)の種類を示すコード。 |
| solver_response | 複合型(RECORD)、 繰り返し(REPEATED) |
計算エンジンからの応答データ。専門的な分析に用います。 | |
| constraints | 複合型(RECORD)、 繰り返し(REPEATED) |
設定された各制約条件がどの程度満たされたかなどの詳細情報。 | |
| created_at | タイムスタンプ(TIMESTAMP) | ✓ | この実行データが作成された日時。 |
このテーブルから得られる情報の中で、特に注目すべき点をいくつか紹介します。
total_qubit_num: これは、最適化問題を解くために内部的に使用された変数(論理qubit)の数を示します。この数値が大きいほど、問題が複雑であることを意味します。qubo.maximum_coeff_ratio:QUBOモデルにおける係数の最大値と最小値(絶対値)の比率です。一般的に、この値が小さい(例えば、103~105程度)ほど、計算精度が良くなり、解が安定する傾向があります。qubo.density:QUBOモデルの密度、つまりゼロではない係数の割合を示します。この値が大きい(密な問題である)ほど、一般的に計算精度が出にくく、計算時間が増加する傾向があります。solver_type:どの種類の計算エンジン(ソルバー)が使用されたかを示します。- 1:D-Wave社の量子コンピュータ(dwave)
- 2:シミュレーテッドバイナリマシン(SQBM+) - 古典コンピュータ上のシミュレーション
- 3:SQBM+(パラメータ自動調整タイプ)
- 4:SQBM+(QP)
- 5:D-Wave社の制約付き量子モデル(dwave_CQM)
- 6:FDA
- 7:Amplify社の提供する計算エンジン(amplify)
これらのメタデータを分析することで、最適化計算のパフォーマンスや結果の品質を客観的に評価できます。また、問題の定式化(リソースや制約の与え方)が適切であったかどうかの判断材料にもなり、設定の調整や改善する際に役立ちます。
6. 実行結果を格納するテーブル
最適化計算の実行後に生成される結果が格納されるテーブルです。具体的に、どのリソースがどの配分先にどれだけ配分されたかが記録されます。
JSONスキーマを表示
[
{ "name": "job_id", "type": "STRING", "mode": "NULLABLE", "description": "" },
{ "name": "energy", "type": "FLOAT", "mode": "NULLABLE", "description": "" },
{ "name": "solution_index", "type": "INTEGER", "mode": "NULLABLE", "description": "" },
{ "name": "resources", "type": "RECORD", "mode": "REPEATED", "fields": [
{ "name": "resource_id", "type": "STRING", "mode": "NULLABLE" },
{ "name": "resource_name", "type": "STRING", "mode": "NULLABLE" },
{ "name": "resource_index", "type": "INTEGER", "mode": "NULLABLE" },
{ "name": "amount", "type": "INTEGER", "mode": "NULLABLE", "description": "" }
], "description": "" },
{ "name": "target_id", "type": "STRING", "mode": "NULLABLE", "description": "" },
{ "name": "target_name", "type": "STRING", "mode": "NULLABLE", "description": "" },
{ "name": "target_index", "type": "INTEGER", "mode": "NULLABLE", "description": "" }
]
| カラム名 | データ型 | 出力有無 | 説明 |
|---|---|---|---|
| job_id | 文字列(STRING) | 必須 | 実行された最適化ジョブのID |
| energy | 数値(FLOAT) | 必須 | 計算結果の評価値(エネルギー値)。値が小さいほど、制約条件をよく満たした良い解であることを示します。 |
| solution_index | 整数(INTEGER) | 必須 | 複数の解が得られた場合の、解のインデックス番号 |
| resources | 複合型(RECORD)、 繰り返し(REPEATED) |
配分されたリソースに関する情報(複数のリソース情報が含まれる場合があります) | |
| resources.resource_id | 文字列(STRING) | 条件付き | 配分されたリソースのID |
| resources.resource_name | 文字列(STRING) | 条件付き | 配分されたリソースの名称。仕様により、このフィールドには常にNULLが出力されます。 |
| resources.resource_index | 整数(INTEGER) | 必須 | システム内部で使用されるリソースのインデックス番号 |
| resources.amount | 整数(INTEGER) | 必須 | その配分先に配分されたリソースの量 |
| target_id | 文字列(STRING) | 条件付き | リソースが配分された先のID |
| target_name | 文字列(STRING) | 条件付き | リソースが配分された先の名称。仕様により、このフィールドには常にNULLが出力されます。 |
| target_index | 整数(INTEGER) | 必須 | システム内部で使用される配分先のインデックス番号 |
「エネルギー値(energy)」は、最適化計算の「良さ」を示す数値です。この値が小さいほど、設定した制約条件(例:リソースの上限を超えない、利益を最大化する等)をより良く満たしている「良い解」であると解釈できます。